
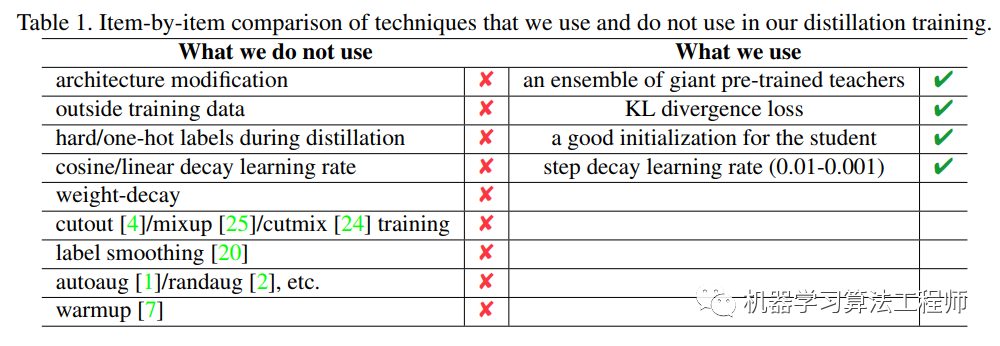
無需tricks,知識(shí)蒸餾提升ResNet50在ImageNet上準(zhǔn)確度至80%+
知識(shí)蒸餾是將一個(gè)已經(jīng)訓(xùn)練好的網(wǎng)絡(luò)遷移到另外一個(gè)新網(wǎng)絡(luò),常采用teacher-student學(xué)習(xí)策略,已經(jīng)被廣泛應(yīng)用在模型壓縮和遷移學(xué)習(xí)中。這里要介紹的MEAL V2是通過知識(shí)蒸餾提升ResNet50在ImageNet上的分類準(zhǔn)確度,MEAL V2不需要修改網(wǎng)絡(luò)結(jié)構(gòu),也不需要其他特殊的訓(xùn)練策略和數(shù)據(jù)增強(qiáng)就可以使原始ResNet50的Top-1準(zhǔn)確度提升至80%+,這是一個(gè)非常nice的work。
MEAL V2主要的思路是將多個(gè)模型的集成效果通過知識(shí)蒸餾遷移到一個(gè)單一網(wǎng)絡(luò)中,整個(gè)設(shè)計(jì)非常簡(jiǎn)單,只包括三個(gè)重要的部分:teacher模型集成,KL散度loss以及一個(gè)判別器。相比其它方法,不需要特殊的trick:
MEAL V2是MEAL方法的升級(jí)版,相比之下V2版本設(shè)計(jì)上更簡(jiǎn)單,效果也更好:
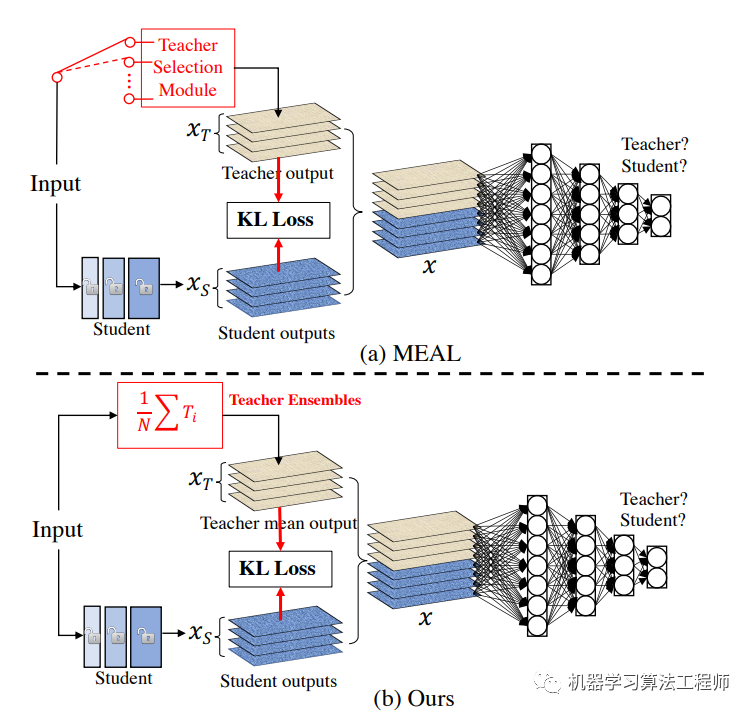
Teacher模型集成
采用多個(gè)teacher模型進(jìn)行集成可以產(chǎn)生更準(zhǔn)確的預(yù)測(cè)以更好地指導(dǎo)student模型訓(xùn)練。原始的MEAL從多個(gè)teacher中隨機(jī)選擇一個(gè)teacher進(jìn)行蒸餾,這里是將多個(gè)teacher模型的預(yù)測(cè)概率(softmax后輸出)求平均值來進(jìn)行蒸餾,這實(shí)際上是一種模型集成。記teacher模型為,共有K個(gè)teacher,那么對(duì)輸入,模型集成后的概率輸出為;
KL散度
KL散度可以用來衡量兩個(gè)概率分布的差異,在訓(xùn)練過程中通過最小化student的概率輸出和teacher模型集成后概率的KL散度來完成知識(shí)蒸餾。這里的損失函數(shù)如下:
由于上述公式展開后的第二項(xiàng)是teacher模型集成后概率的熵,對(duì)于訓(xùn)練student是一個(gè)常量,所以可以忽略,最后就剩下了交叉熵:
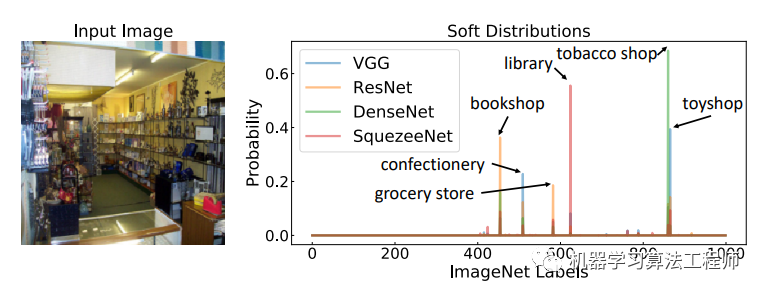
這里交叉熵的label是teacher模型集成后的平均概率,而不是傳統(tǒng)訓(xùn)練中的one-hot/hard標(biāo)簽,這對(duì)于知識(shí)蒸餾是至關(guān)重要的。原始的知識(shí)蒸餾方法是只有一個(gè)teacher,但是采用的是smooth后的概率(帶有溫度的softmax概率)來進(jìn)行訓(xùn)練,這里采用多模型集成更進(jìn)一步。相比hard label,soft label其實(shí)信息更強(qiáng),比如下圖label為tobacco shop的輸入圖片,不同模型的輸出概率其實(shí)比hard label包含了更多信息,如果訓(xùn)練數(shù)據(jù)有噪音,采用soft label意義就更大了。
判別器
MEAL V2采用對(duì)抗學(xué)習(xí)來防止student在訓(xùn)練數(shù)據(jù)上過擬合,即不讓student過分學(xué)習(xí)teacher的輸出,這其實(shí)是一種正則化手段。具體做法是加入一個(gè)判別器來區(qū)分student的輸出和teacher的輸出,這是一個(gè)二分器。二分器采用一個(gè)3層FC的子網(wǎng)絡(luò),其輸入是softmax前的logits。這里的student網(wǎng)絡(luò)其實(shí)充當(dāng)了生成器的角色,與傳統(tǒng)的GAN訓(xùn)練方式不同,這里直接把判別器loss和前面所述的CE loss直接加起來一起訓(xùn)練,具體做法是每個(gè)batch中,teacher的輸出其GT是[0, 1],而student的輸出其GT是[1,0]:
class?discriminatorLoss(nn.Module):
????def?__init__(self,?models,?loss=nn.BCEWithLogitsLoss()):
????????super(discriminatorLoss,?self).__init__()
????????self.models?=?models?#?3層FC網(wǎng)絡(luò)
????????self.loss?=?loss
????def?forward(self,?outputs,?targets):
????????"""
????????outputs和targets分別是student和teacher的logits
????????"""
????????inputs?=?[torch.cat((i,j),0)?for?i,?j?in?zip(outputs,?targets)]
????????inputs?=?torch.cat(inputs,?1)
????????batch_size?=?inputs.size(0)
????????target?=?torch.FloatTensor([[1,?0]?for?_?in?range(batch_size//2)]?+?[[0,?1]?for?_?in?range(batch_size//2)])
????????target?=?target.to(inputs[0].device)
????????output?=?self.models(inputs)
????????res?=?self.loss(output,?target)
????????return?res
這里的判別器其實(shí)只是充當(dāng)一種正則化策略,對(duì)訓(xùn)練效果有少量提升,這是因?yàn)橹R(shí)蒸餾中,一般teacher比student強(qiáng)大,就算強(qiáng)制學(xué)習(xí),student的teacher也會(huì)有一定的差距。
論文中的teacher設(shè)置為2個(gè),如果輸入size為224,那么teacher為senet154和resnet152_v1s,如果輸入size為380,那么teacher為efficientnet_b4_ns和efficientnet_b4,論文中對(duì)ResNet50做了實(shí)驗(yàn),最終在ImageNet上Top-1準(zhǔn)確度可以達(dá)到80%+:

有一點(diǎn)需要注意,在蒸餾時(shí),ResNet50不是隨機(jī)初始化的,而是從預(yù)訓(xùn)練好的ImageNet模型進(jìn)行初始化,就是說student也需要一個(gè)好的初始化,如果是隨機(jī)初始化可能需要更長的訓(xùn)練時(shí)長。
我個(gè)人覺得知識(shí)蒸餾的應(yīng)用會(huì)越來越多,不管是在CV領(lǐng)域還是NLP領(lǐng)域。在最新的無監(jiān)督方法研究如谷歌的SimCLRv2和Noisy Student均有知識(shí)蒸餾的身影。
參考
MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks? MEAL: Multi-Model Ensemble via Adversarial Learning Distilling the Knowledge in a Neural Network szq0214/MEAL-V2
推薦閱讀
帶你捋一捋anchor-free的檢測(cè)模型:FCOS
mmdetection最小復(fù)刻版(三):數(shù)據(jù)分析神兵利器
mmdetection最小復(fù)刻版(四):獨(dú)家yolo轉(zhuǎn)化內(nèi)幕
機(jī)器學(xué)習(xí)算法工程師
? ??? ? ? ? ? ? ? ? ? ? ? ??????????????????一個(gè)用心的公眾號(hào)
?
