
TPU新秘密武器!谷歌Jeff Dean團隊推「AI造芯」,自主設計芯片僅需6小時

新智元報道
新智元報道
來源:nature等
編輯:yaxin, LQ
【新智元導讀】Jeff Dean帶隊更新AI芯片設計,這次還帶上了谷歌秘密武器TPU,利用深度強化學習設計下一代AI加速芯片,6個小時內(nèi)搞定芯片設計。
有了AI設計芯片,我再也不相信「摩爾定律」了!

近日,由Jeff Dean領銜的谷歌大腦團隊以及斯坦福大學的科學家們,在一項研究中證明:
「一種基于深度強化學習(DL)的芯片布局規(guī)劃方法,能夠生成可行的芯片設計方案。」

AI能設計芯片,這還不夠震撼。
只用不到 6 小時的時間設計出芯片才驚人!

Jeff Dean:我們用AI,6小時就能設計一款芯片,敢信?
Jeff Dean:我們用AI,6小時就能設計一款芯片,敢信?
為了訓練AI干活兒,谷歌研究員可真花了不少心思。
與棋盤游戲,如象棋或圍棋,的解決方案相比較,芯片布局問題更為復雜。
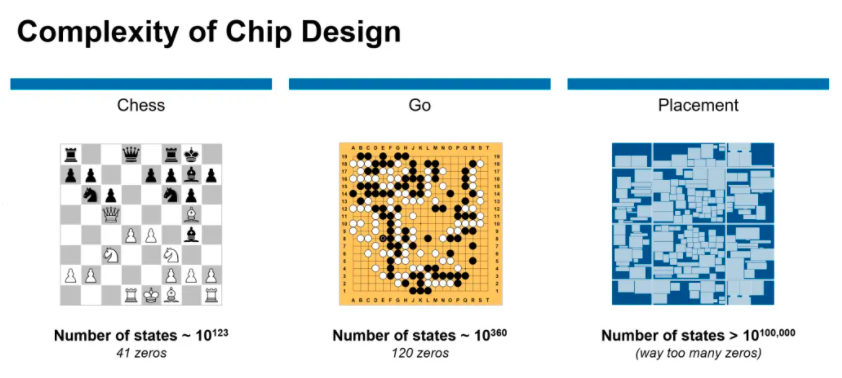
在不到6小時的時間內(nèi),谷歌研究人員利用「基于深度強化學習的芯片布局規(guī)劃方法」生成芯片平面圖,且所有關鍵指標(包括功耗、性能和芯片面積等參數(shù))都優(yōu)于或與人類專家的設計圖效果相當。
要知道,我們?nèi)祟惞こ處熗枰笖?shù)月的努力」才能達到如此效果。
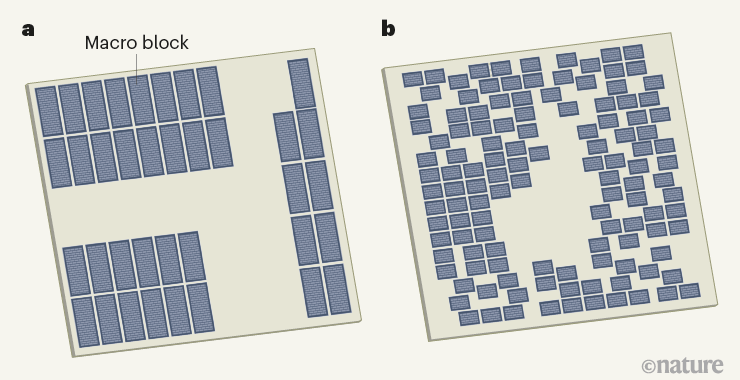
人類設計的微芯片平面圖與機器學習系統(tǒng)設計
具體是什么方法呢?
在nature的介紹中,谷歌研究人員將芯片布局規(guī)劃方法當做一個「學習問題」。
潛在問題設計高維contextual bandits problem,結合谷歌此前的研究,研究人員選擇將其重新制定為一個順序馬可夫決策過程(MDP) ,這樣就能更容易包含以下幾個約束條件:

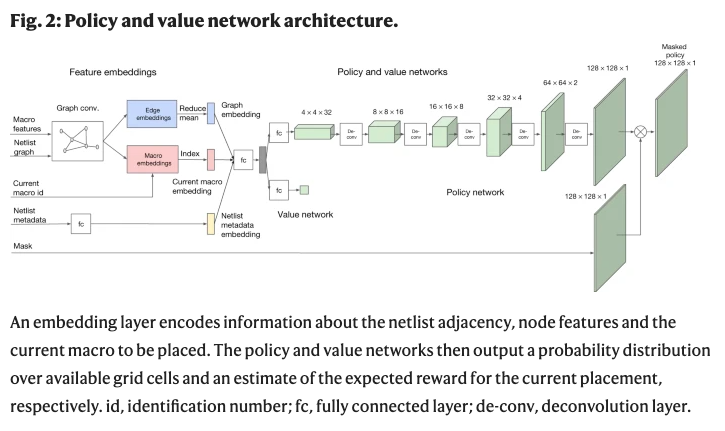
(1)狀態(tài)編碼關于部分放置的信息,包括 netlist (鄰接矩陣)、節(jié)點特征(寬度、高度、類型)、邊緣特征(連接數(shù))、當前節(jié)點(宏)以及 netlist 圖的元數(shù)據(jù)(路由分配、總線數(shù)、宏和標準單元簇)。
(2)動作是所有可能的位置(芯片畫布的網(wǎng)格單元) ,當前宏可以放置在不違反任何硬約束的密度或阻塞。
(3)給定一個狀態(tài)和一個動作,「狀態(tài)轉(zhuǎn)換」定義下一個狀態(tài)的概率分布。
(4)獎勵:除最后一個動作外,所有動作的獎勵為0,其中獎勵是代理線長、擁塞和密度的負加權,如下所述。
研究人員訓練一個由神經(jīng)網(wǎng)絡建模的策略(一個RL代理) ,通過重復的事件(狀態(tài)、動作和獎勵的順序) ,學會采取將「累積獎勵最大化」的動作(見Fig. 1)。該項目使用鄰近策略優(yōu)化(PPO)來更新策略網(wǎng)絡的參數(shù),給定每個放置的累積獎勵。
通過訓練一個智能體,用累計獎勵最大化,讓AI優(yōu)化芯片布局的能力持續(xù)增強。
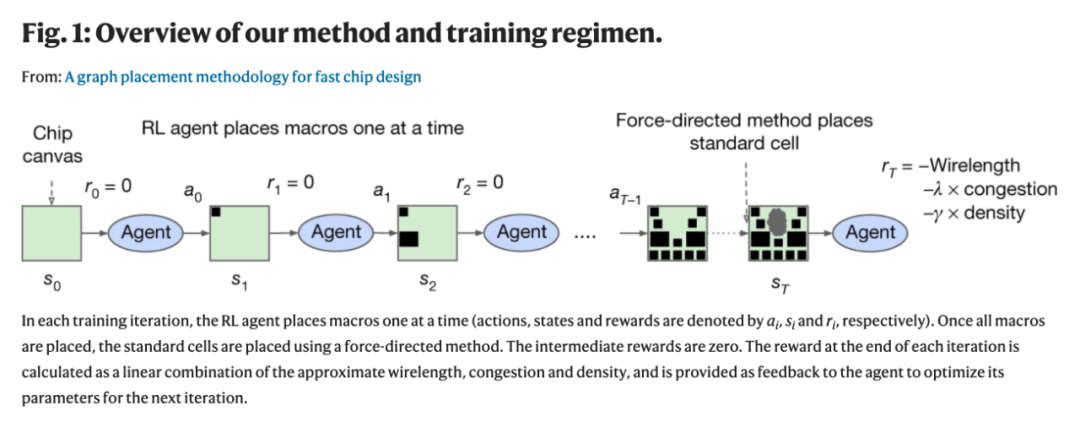
在每個訓練迭代中,RL 代理一次放置一個宏(動作、狀態(tài)和獎勵分別由 ai、 si 和ri表示)。一旦所有的宏被放置,標準單元格被放置使用一個力定向的方法。中間獎勵為零。每次迭代結束時的獎勵計算為近似線長、阻塞和密度的線性組合,并作為反饋給代理以優(yōu)化下一次迭代的參數(shù)。
研究人員將目標函數(shù)定義如下:
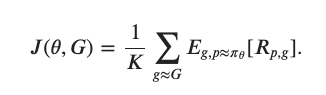
如前所述,針對芯片布局規(guī)劃問題開發(fā)領域自適應策略極具挑戰(zhàn)性,因為這個問題類似于一個具有不同棋子、棋盤和贏條件的博弈,并且具有巨大的狀態(tài)動作空間。
為了應對這個挑戰(zhàn),研究人員首先集中學習狀態(tài)空間的豐富表示。
谷歌研究人員表示,我們的直覺是,能夠處理芯片放置的一般任務的策略也應該能夠在推理時將與新的未見芯片相關的狀態(tài)編碼為有意義的信號。
因此,研究人員訓練了一個「神經(jīng)網(wǎng)絡架構」,能夠預測新的netlist位置的獎勵,最終目標是使用這個架構作為策略的編碼層。

為了訓練這個有監(jiān)督的模型,就需要一個大型的芯片放置數(shù)據(jù)集以及相應的獎勵標簽。
因此,研究人員創(chuàng)建了一個包含10000個芯片位置的數(shù)據(jù)集,其中輸入是與給定位置相關聯(lián)的狀態(tài),標簽是該位置的獎勵。
為了準確地預測獎勵標簽并將其推廣到未知數(shù)據(jù),研究人員提出了一種基于邊的圖形神經(jīng)網(wǎng)絡結構,稱之為Edge-GNN (Edge-Based Graph Neural Network)。
在Edge-GNN中,研究人員通過連接每個節(jié)點的特征(包括節(jié)點類型、寬度、高度、 x 和 y 坐標以及它與其他節(jié)點的連通性)來創(chuàng)建每個節(jié)點的初始表示。
然后再迭代執(zhí)行以下更新: (1)每個邊通過應用一個完全連通的網(wǎng)絡連接它連接的兩個節(jié)點更新其表示,(2)每個節(jié)點通過傳遞所有的平均進出邊到另一個完全連通的網(wǎng)絡更新其表示。節(jié)點和邊的更新如下面方程所示。

Edge-GNN的作用是嵌入netlist,提取有關節(jié)點類型和連通性的信息到一個低維向量表示,可用于下游任務。基于邊緣的神經(jīng)結構對泛化的影響如Fig. 2所示。
研究人員首先選擇了5個不同的芯片凈網(wǎng)表,并用AI算法為每個網(wǎng)表創(chuàng)建2000個不同的布局位置。
該系統(tǒng)花了48個小時在「英偉達Volta顯卡」和10個CPU上「預訓練」,每個CPU都有2GB的RAM。
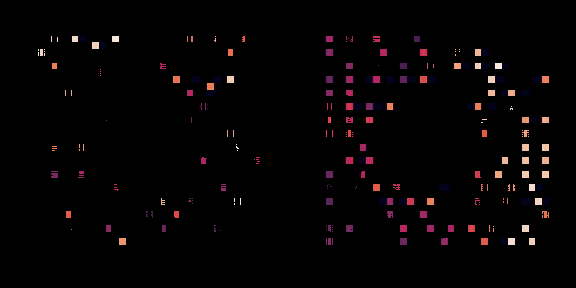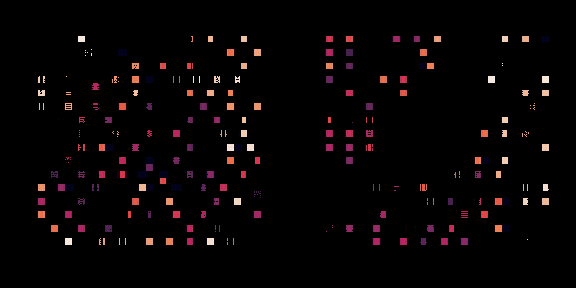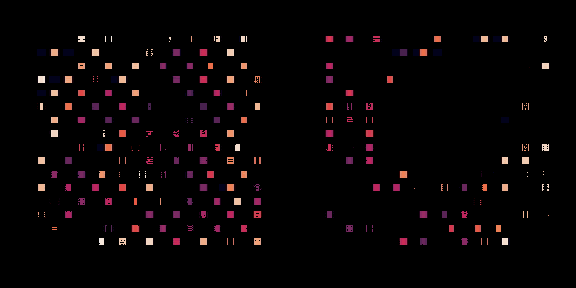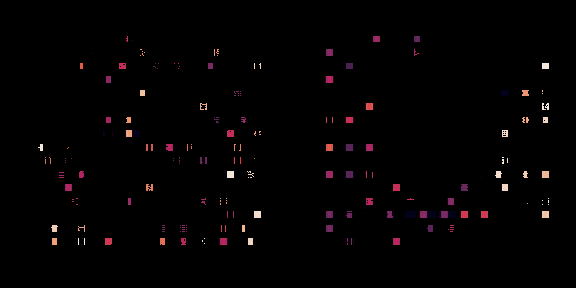
左邊,策略正在從頭開始訓練,右邊,一個預訓練的策略正在為這個芯片進行微調(diào)。每個矩形代表一個單獨的宏放置
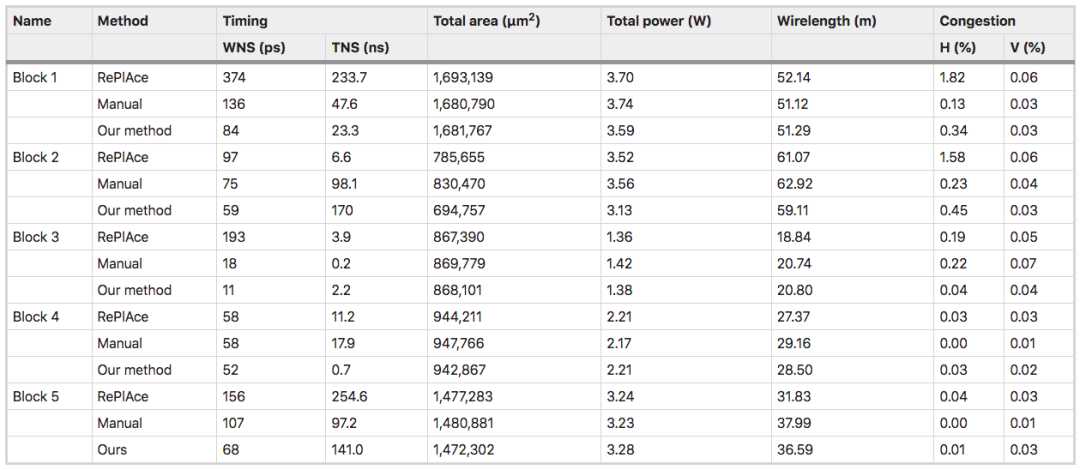
在一項測試中,研究人員將他們的系統(tǒng)建議與手動基線——谷歌TPU物理設計團隊創(chuàng)建的上一代TPU芯片設計——進行比較。
結果顯示,系統(tǒng)和人類專家均生成符合時間和阻塞要求的可行位置,而AI系統(tǒng)在面積、功率和電線長度方面優(yōu)于或媲美手動布局,同時滿足設計標準所需的時間要少得多。
TPU 秘密武器
TPU 秘密武器
最新的「微調(diào)技術」將用來設計即將推出的,以前未宣布的谷歌張量處理單元(TPU)的生成。
也就是未來的第五代芯片TPU v5。
不久前的谷歌IO大會上,谷歌推出了最新的AI定制第四代芯片TPU v4 ,速度是v3的兩倍。

v4的性能相比前一代提升了10倍多,專門用于加速人工智能。
一個TPU pod的計算能力達到了每秒百億億次浮點計算的級別,相當于一千萬臺筆記本電腦之和。

以前要想獲得1個exaflop(每秒 10 的 18 次方浮點運算)的算力,通常需要建立一個定制的超級計算機。
TPU是谷歌的第一批定制芯片之一,當包括微軟在內(nèi)的其他公司決定為其機器學習服務采用更靈活的FPGA時,谷歌很早就在這些定制芯片上下了賭注。

雖然谷歌團隊的系統(tǒng)被用于設計下一代谷歌TPU,但研究人員認為,它可以應用于芯片設計以外的有影響力的放置規(guī)劃問題,包括城市規(guī)劃、疫苗測試分發(fā)和大腦皮層映射等一系列應用。
芯片設計也能「遷移學習」?還可大幅縮短訓練時間
如果能利用先前的設計經(jīng)驗,實現(xiàn)遷移學習,將大大縮短訓練時間和成本。
如果在芯片設計中使用「預訓練」策略能否產(chǎn)生更好的結果?
后續(xù)實驗中,研究人員使用預訓練策略生成的放置位置質(zhì)量,與從頭訓練策略網(wǎng)絡生成的放置位置質(zhì)量進行比較。
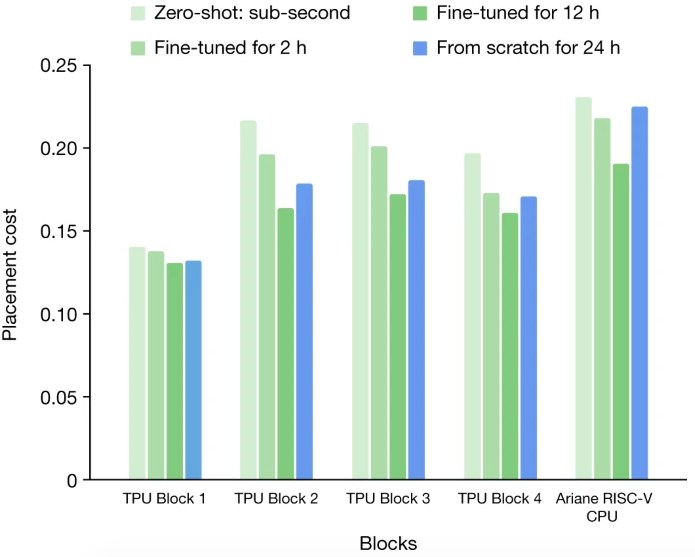
從無到有的訓練與不同時間量的微調(diào)
訓練的數(shù)據(jù)集由 TPU Block 和 開源 Ariane RISC-V CPU 組成。在每一個實驗中,都對除目標塊外的所有塊預先訓練策略。
研究人員使用Zero-Shot在不到 1 秒鐘的時間內(nèi)就生成了放置位置。如果根據(jù)特定設計的細節(jié)對預訓練的策略網(wǎng)絡進行2-12個小時的微調(diào)。
結果發(fā)現(xiàn),從零開始訓練的策略需要更長的時間才能收斂,即使在 24 小時之后,結果(由獎勵函數(shù)評估)也比微調(diào)策略在 12 小時內(nèi)達到的效果差。
這說明預訓練所學到的權重和專家的設計經(jīng)驗起了很關鍵的作用——為新的看不見的塊生成更高質(zhì)量的放置方案。
最終結果顯示,經(jīng)過預訓練的策略網(wǎng)絡在微調(diào)過程開始時就獲得了較低的布置成本,并且比從頭開始訓練的策略網(wǎng)絡要快30個小時以上。
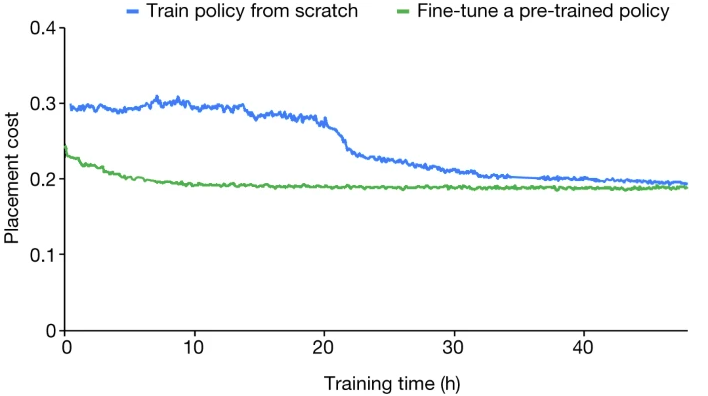
Ariane RISC-V CPU30 從零開始訓練與從預先訓練的策略網(wǎng)絡開始訓練的收斂圖
接下來,研究人員在三個不同的訓練數(shù)據(jù)集上對策略網(wǎng)絡進行了預訓練(小數(shù)據(jù)集是中型數(shù)據(jù)集的一個子集,而中型數(shù)據(jù)集是大型數(shù)據(jù)集的一個子集)。
然后在相同的測試塊上微調(diào)預訓練的策略網(wǎng)絡,并對比不同訓練時間下的成本。隨著數(shù)據(jù)集的增大,生成的布置質(zhì)量和在測試塊上收斂的時間都會提高。
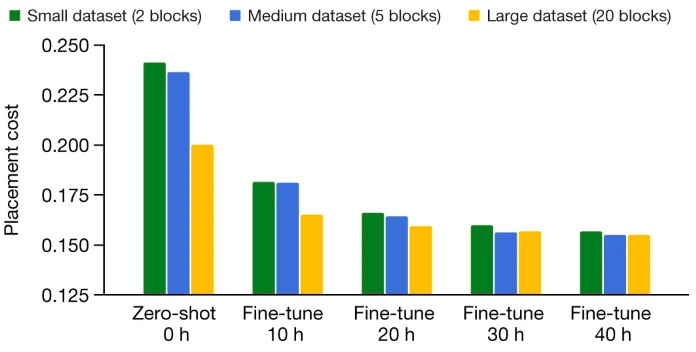
訓練前數(shù)據(jù)集大小的影響
「我們的方法和人類專家都能產(chǎn)生可行的布局,而且符合芯片的時序和阻塞設計標準。我們在WNS、面積,功率和線長方面也優(yōu)于或相當于人類專家的設計。但是,我們端到端的學習方法耗時僅6個小時,而手動布置需要一個緩慢的迭代優(yōu)化過程,還需要專家干預,導致整個周期可能持續(xù)數(shù)周」。
AI設計芯片會搶走我們的飯碗嗎?
AI設計芯片會搶走我們的飯碗嗎?
21世紀最貴的是什么?人工。最便宜的是什么?人工智能。
芯片研發(fā)周期長、成本高,重度依賴設計。優(yōu)秀的芯片設計師非常稀缺,基本都被幾家老牌芯片大廠壟斷,后起之秀很難在短期內(nèi)挖到足夠的資深設計師。
從零培養(yǎng)一個人類設計師很難,利用已有的數(shù)據(jù)從零訓練一個AI設計師相比就簡單多了。況且,AI不要工錢,不貪福利,不會罷工,永不疲憊。更重要的是,它隨叫隨到。

讀者朋友們,你看好AI設計芯片嗎?你認為如果AI連芯片都能設計,是否會威脅到芯片從業(yè)人員的工作崗位呢?是否意味著未來將可能出現(xiàn)AI制造AI?歡迎留言討論。
參考資料:
https://www.nature.com/articles/s41586-021-03544-w#Fig1
https://venturebeat.com/2021/06/09/google-used-reinforcement-learning-to-design-next-gen-ai-accelerator-chips/
