
我用Python展示Excel中常用的20個(gè)操作
前言
Excel與Python都是數(shù)據(jù)分析中常用的工具,本文將使用動(dòng)態(tài)圖(Excel)+代碼(Python)的方式來(lái)演示這兩種工具是如何實(shí)現(xiàn)數(shù)據(jù)的讀取、生成、計(jì)算、修改、統(tǒng)計(jì)、抽樣、查找、可視化、存儲(chǔ)等數(shù)據(jù)處理中的常用操作!
數(shù)據(jù)讀取
說(shuō)明:讀取本地Excel數(shù)據(jù)
Excel
Pandas
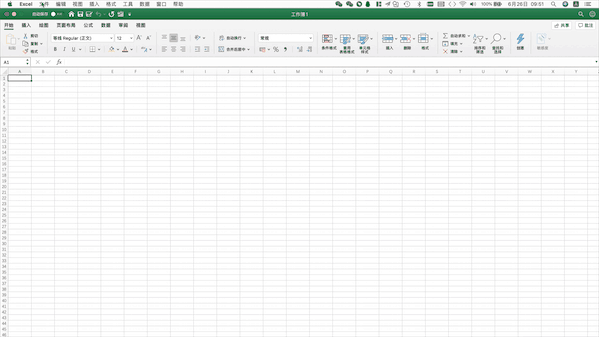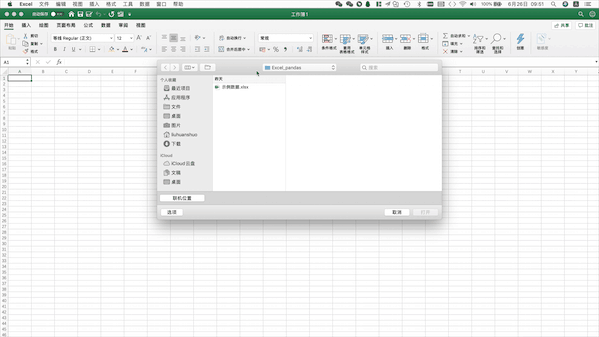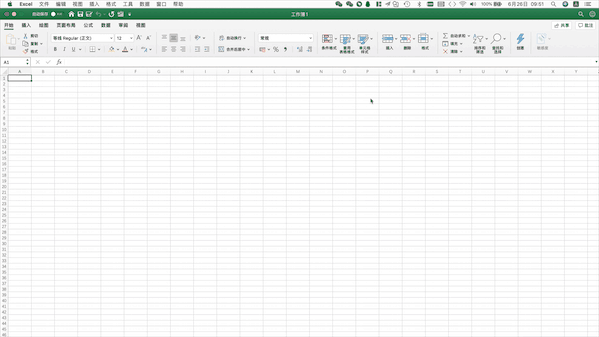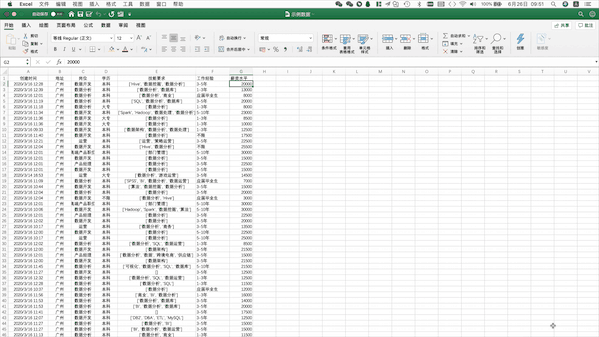
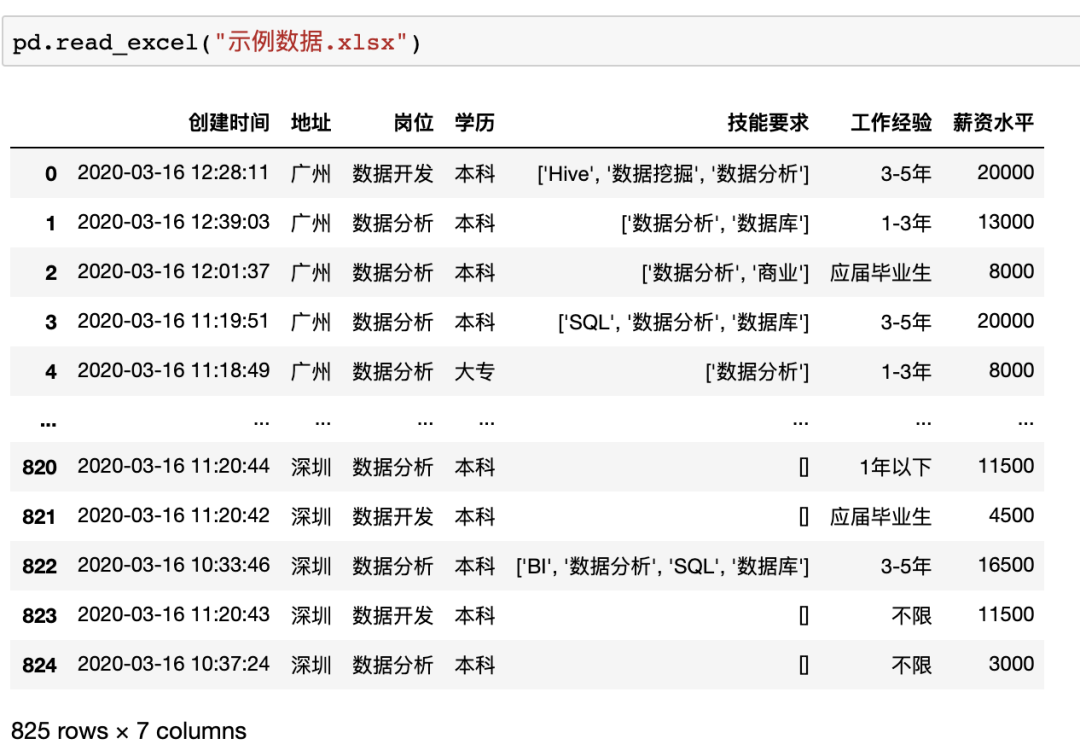
Pandas支持讀取本地Excel、txt文件,也支持從網(wǎng)頁(yè)直接讀取表格數(shù)據(jù),只用一行代碼即可,例如讀取上述本地Excel數(shù)據(jù)可以使用pd.read_excel("示例數(shù)據(jù).xlsx")
數(shù)據(jù)生成
說(shuō)明:生成指定格式/數(shù)量的數(shù)據(jù)
Excel
rand()函數(shù)生成隨機(jī)數(shù),并手動(dòng)拉取指定范圍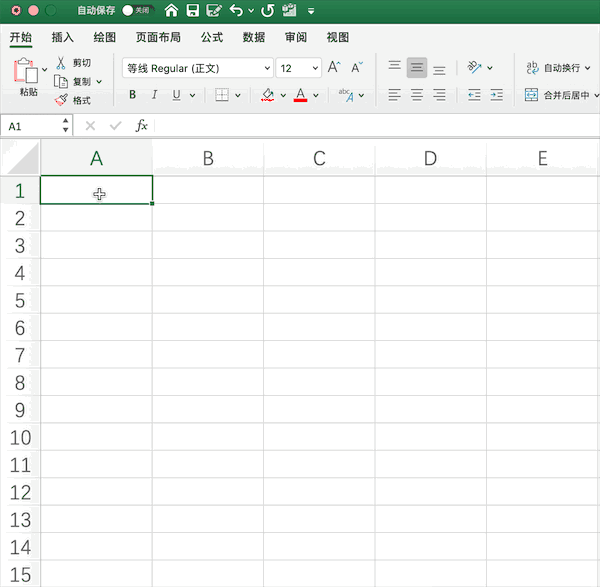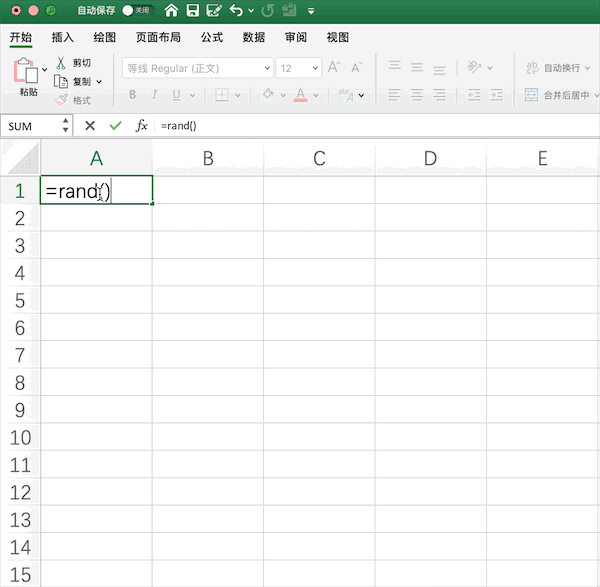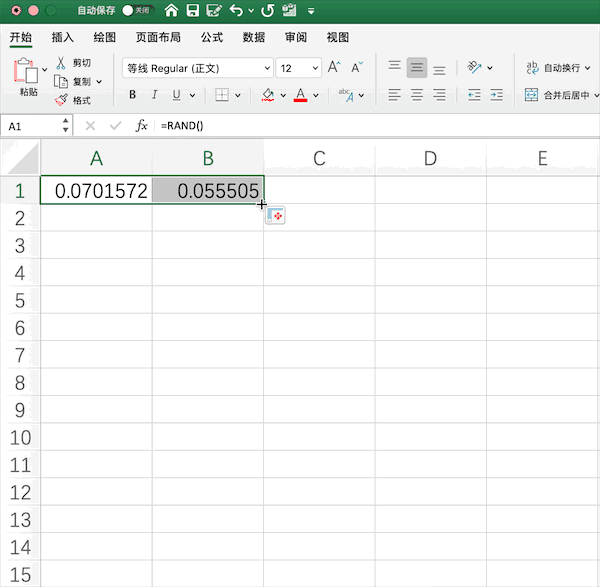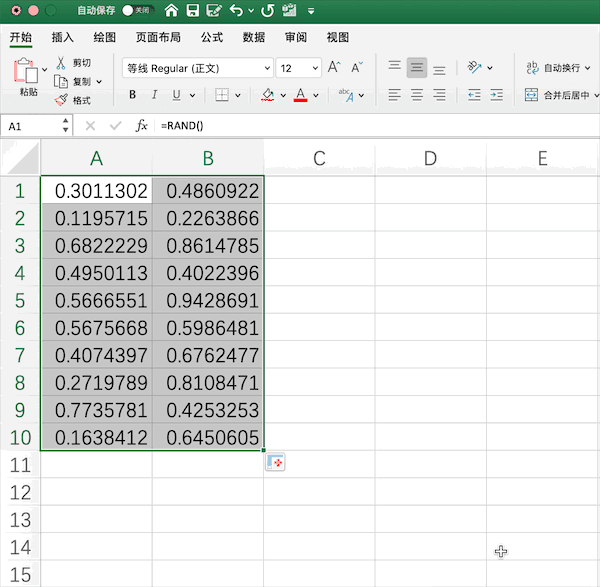
Pandas
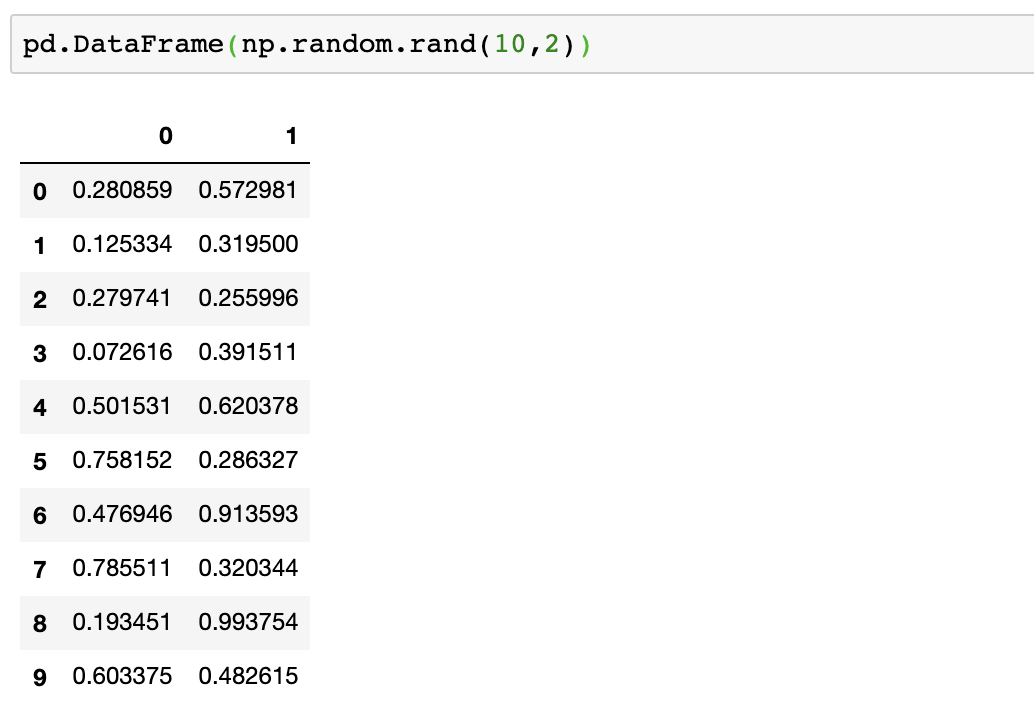
在Pandas中可以結(jié)合NumPy生成由指定隨機(jī)數(shù)(均勻分布、正態(tài)分布等)生成的矩陣,例如同樣生成10*2的0—1均勻分布隨機(jī)數(shù)矩陣為,使用一行代碼即可:pd.DataFrame(np.random.rand(10,2))
數(shù)據(jù)存儲(chǔ)
說(shuō)明:將表格中的數(shù)據(jù)存儲(chǔ)至本地
Excel
在Excel中需要點(diǎn)擊保存并設(shè)置格式/文件名
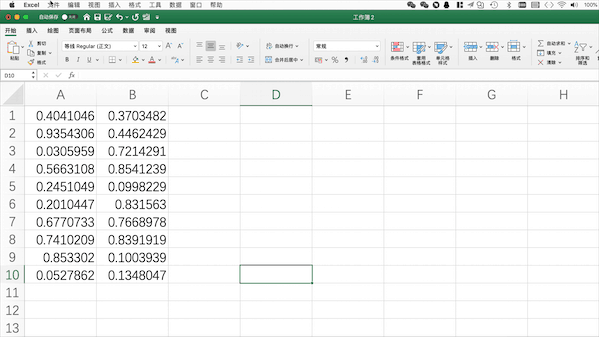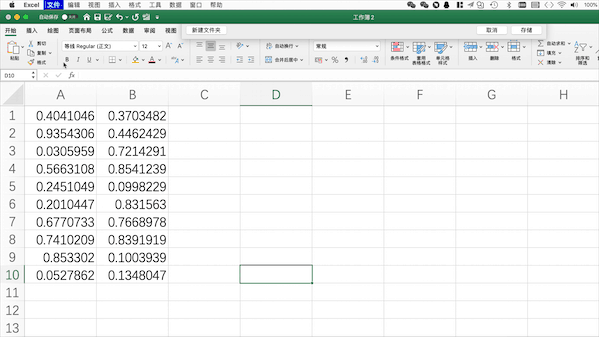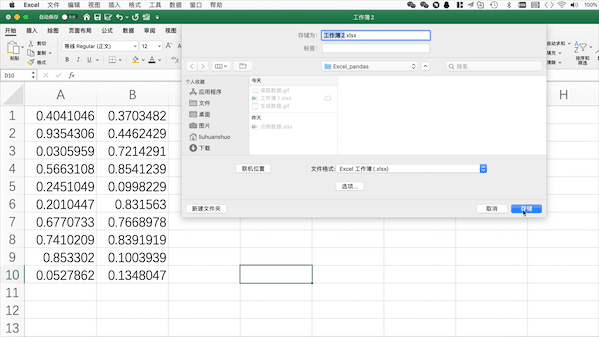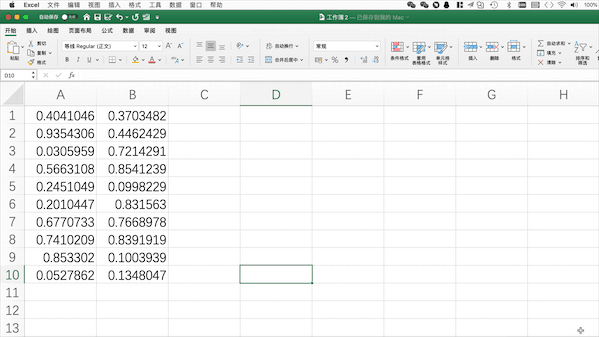
Pandas
在Pandas中可以使用pd.to_excel("filename.xlsx")來(lái)將當(dāng)前工作表格保存至當(dāng)前目錄下,當(dāng)然也可以使用to_csv保存為csv等其他格式,也可以使用絕對(duì)路徑來(lái)指定保存位置

數(shù)據(jù)篩選
說(shuō)明:按照指定要求篩選數(shù)據(jù)
Excel
使用我們之前的示例數(shù)據(jù),在Excel中篩選出薪資大于5000的數(shù)據(jù)步驟如下
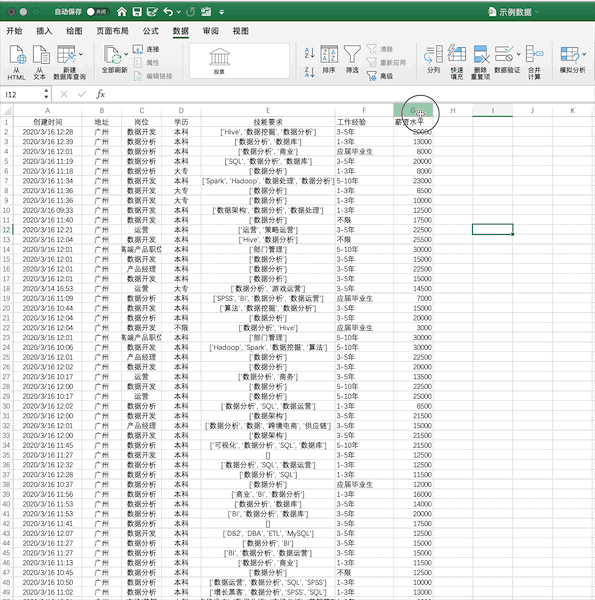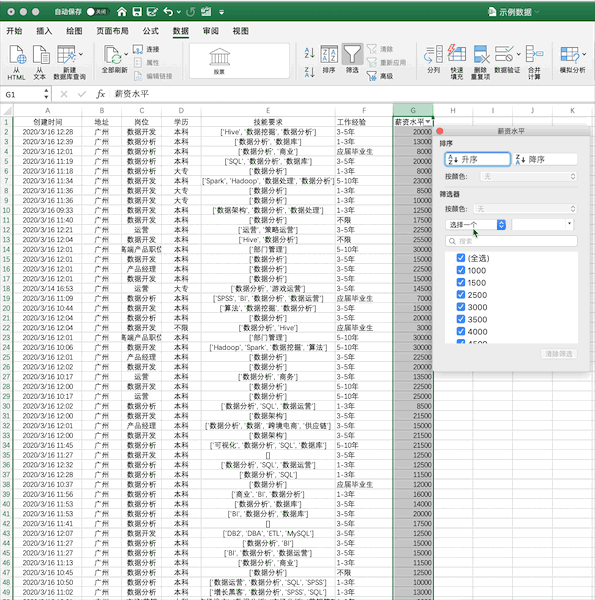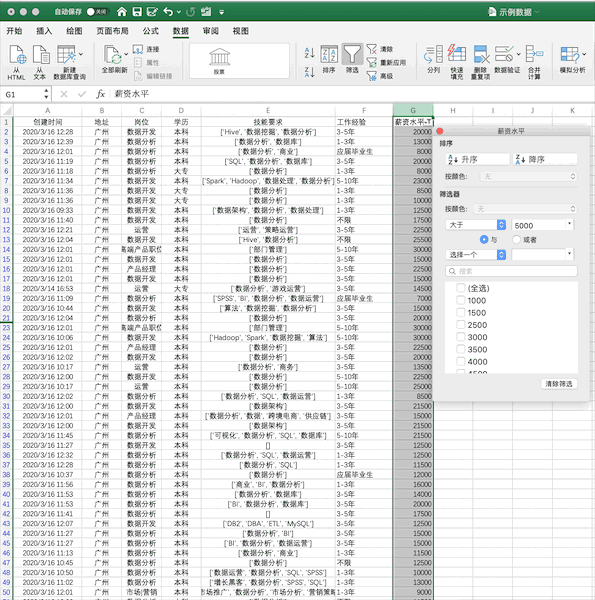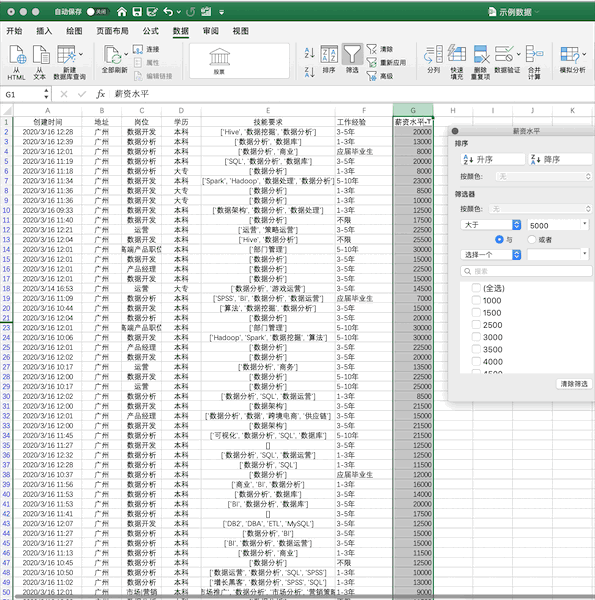
Pandas
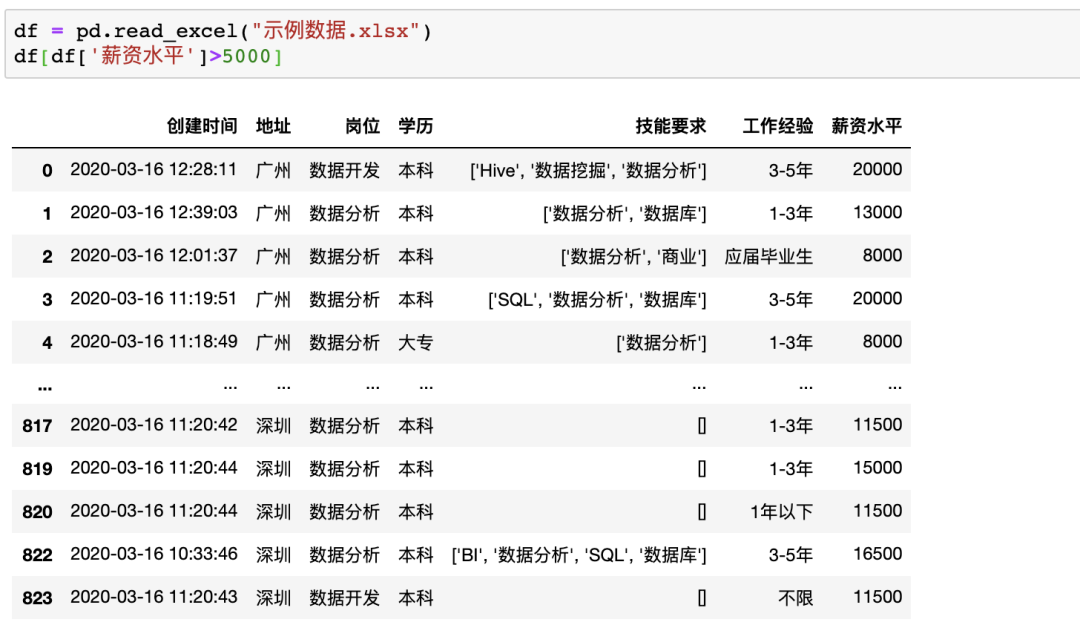
在Pandas中,可直接對(duì)數(shù)據(jù)框進(jìn)行條件篩選,例如同樣進(jìn)行單個(gè)條件(薪資大于5000)的篩選可以使用df[df['薪資水平']>5000],如果使用多個(gè)條件的篩選只需要使用&(并)與|(或)操作符實(shí)現(xiàn)
數(shù)據(jù)插入
說(shuō)明:在指定位置插入指定數(shù)據(jù)
Excel
在Excel中我們可以將光標(biāo)放在指定位置并右鍵增加一行/列,當(dāng)然也可以在添加時(shí)對(duì)數(shù)據(jù)進(jìn)行一些計(jì)算,比如我們就可以使用IF函數(shù)(=IF(G2>10000,"高","低")),將薪資大于10000的設(shè)為高,低于10000的設(shè)為低,添加一列在最后

Pandas
在pandas中,如果不借助自定義函數(shù)的話,我們可以使用cut方法來(lái)實(shí)現(xiàn)同樣操作
bins?=?[0,10000,max(df['薪資水平'])]
group_names?=?['低','高']
df['new_col']?=?pd.cut(df['薪資水平'],?bins,?labels=group_names)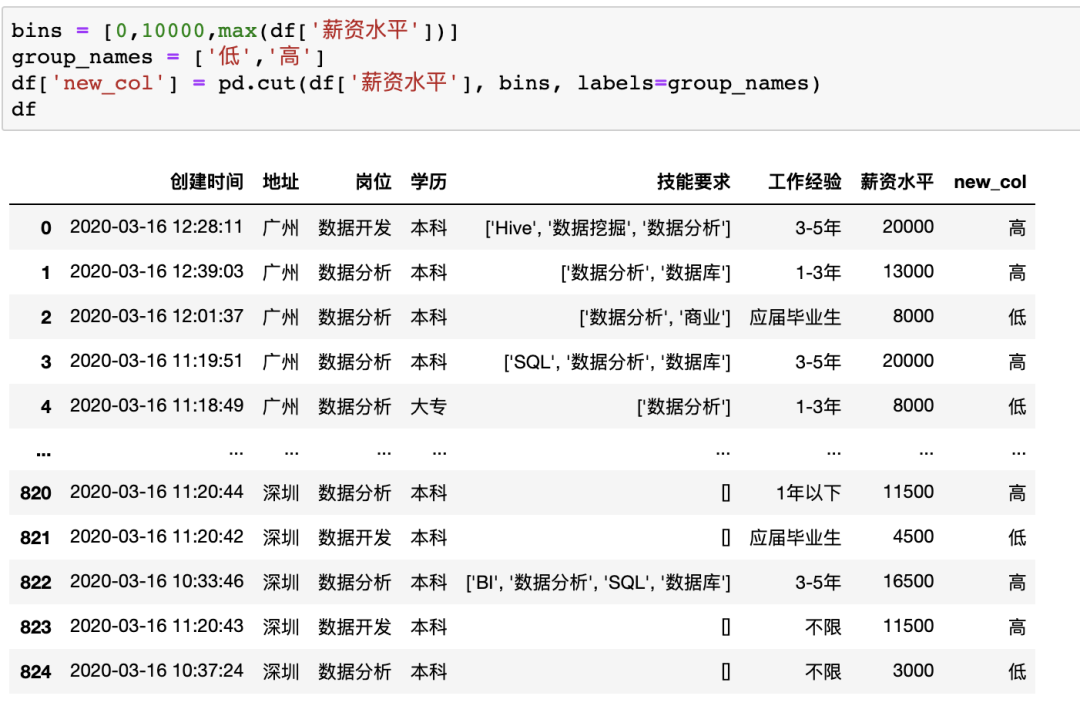
數(shù)據(jù)刪除
說(shuō)明:刪除指定行/列/單元格
Excel

Pandas
在pandas中刪除數(shù)據(jù)也很簡(jiǎn)單,比如刪除最后一列使用del df['new_col']即可
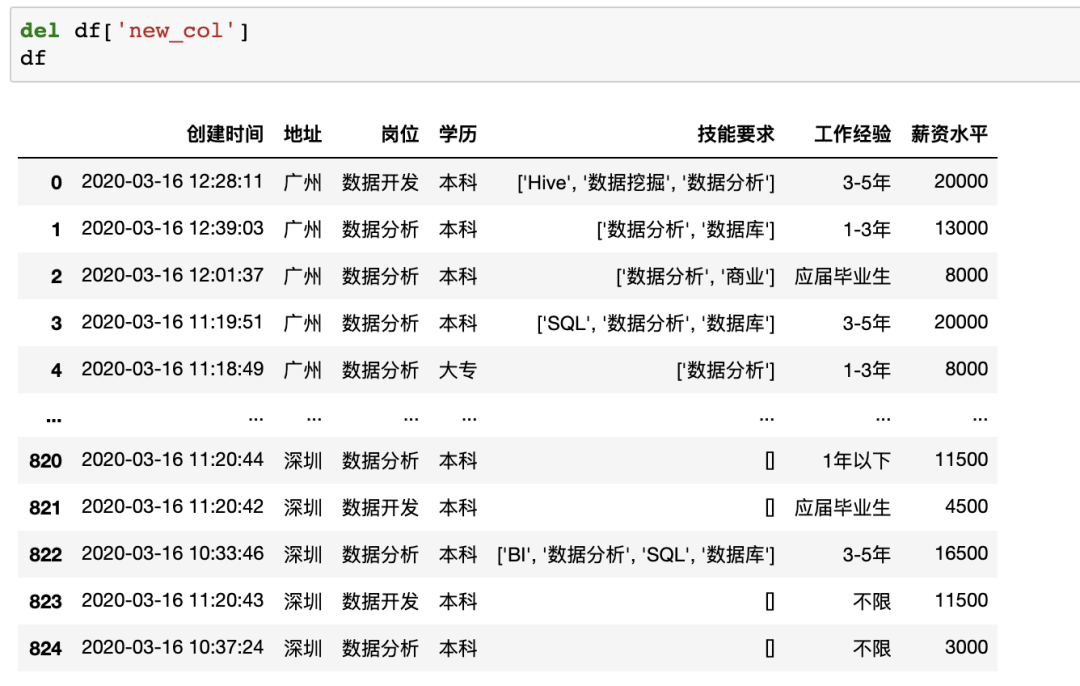
數(shù)據(jù)排序
說(shuō)明:按照指定要求對(duì)數(shù)據(jù)排序
Excel
在Excel中可以點(diǎn)擊排序按鈕進(jìn)行排序,例如將示例數(shù)據(jù)按照薪資從高到低進(jìn)行排序可以按照下面的步驟進(jìn)行
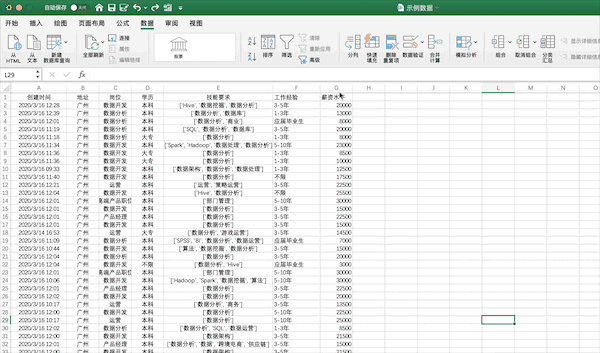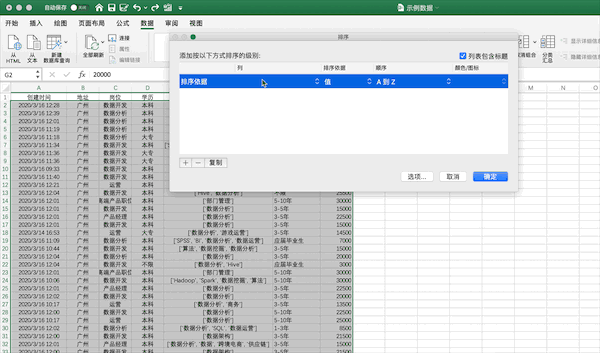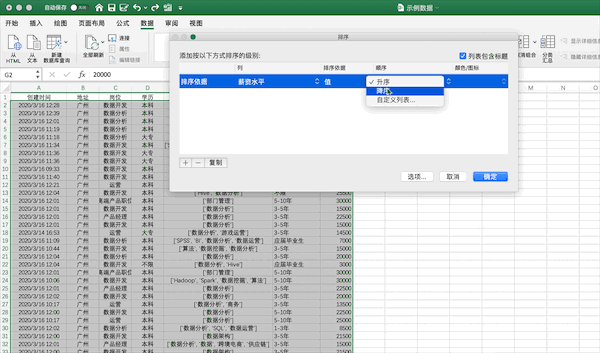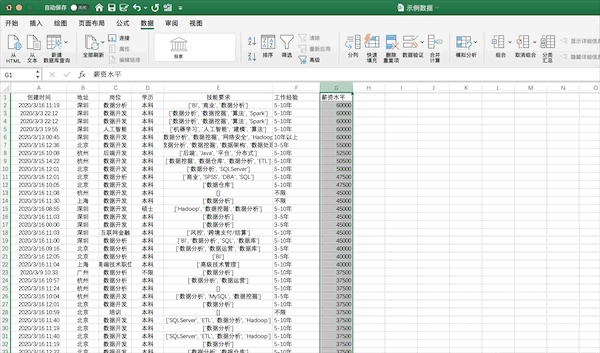
Pandas
在pandas中可以使用sort_values進(jìn)行排序,使用ascending來(lái)控制升降序,例如將示例數(shù)據(jù)按照薪資從高到低進(jìn)行排序可以使用df.sort_values("薪資水平",ascending=False,inplace=True)

缺失值處理
說(shuō)明:對(duì)缺失值(空值)按照指定要求處理
Excel
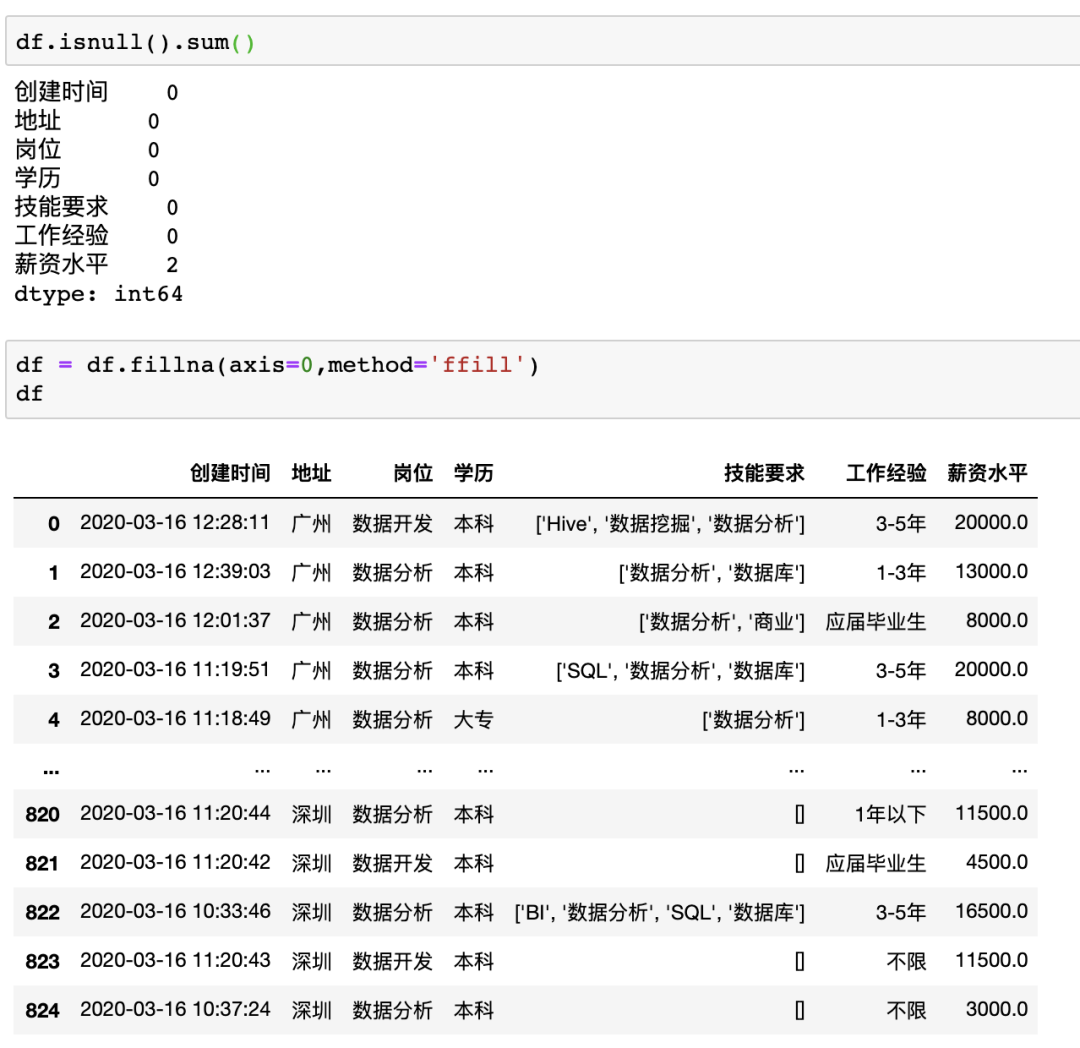
在Excel中可以按照查找—>定位條件—>空值來(lái)快速定位數(shù)據(jù)中的空值,接著可以自己定義缺失值的填充方式,比如將缺失值用上一個(gè)數(shù)據(jù)進(jìn)行填充
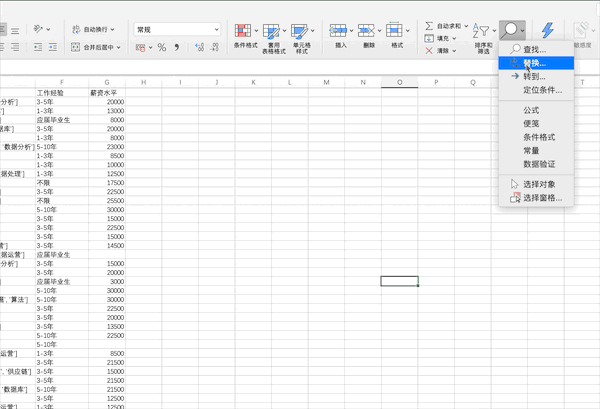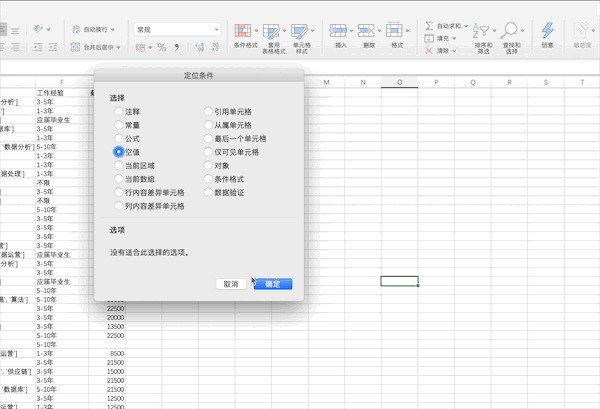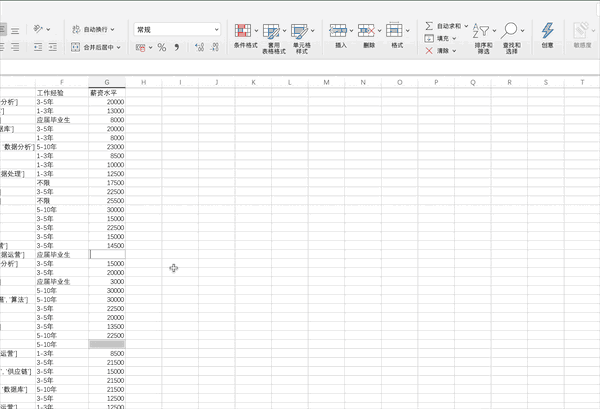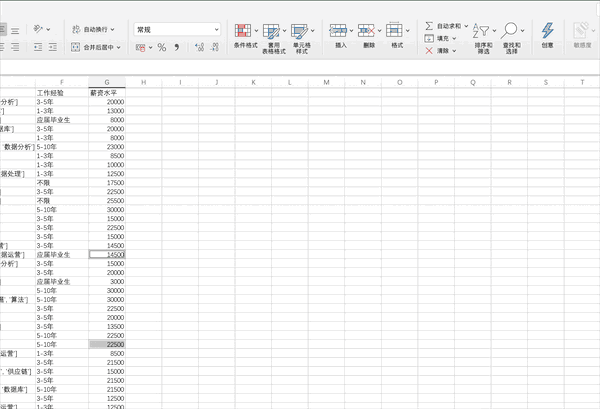
Pandas
在pandas中可以使用data.isnull().sum()來(lái)檢查缺失值,之后可以使用多種方法來(lái)填充或者刪除缺失值,比如我們可以使用df = df.fillna(axis=0,method='ffill')來(lái)橫向/縱向用缺失值前面的值替換缺失值
數(shù)據(jù)去重
說(shuō)明:對(duì)重復(fù)值按照指定要求處理
Excel
在Excel中可以通過(guò)點(diǎn)擊數(shù)據(jù)—>刪除重復(fù)值按鈕并選擇需要去重的列即可,例如對(duì)示例數(shù)據(jù)按照創(chuàng)建時(shí)間列進(jìn)行去重,可以發(fā)現(xiàn)去掉了196 個(gè)重復(fù)值,保留了 629 個(gè)唯一值。
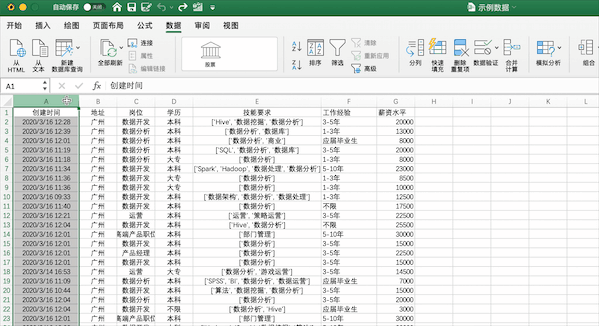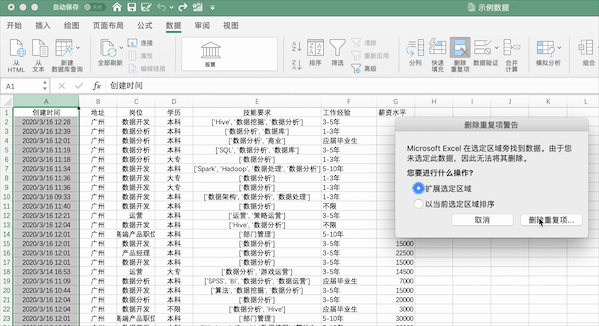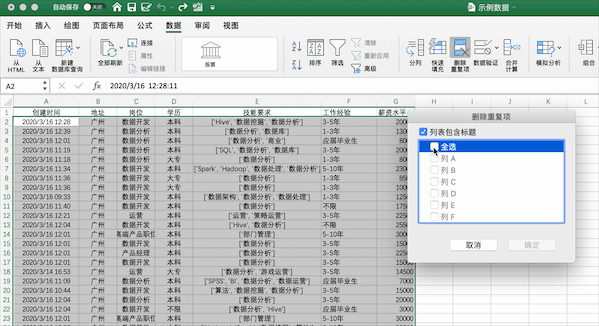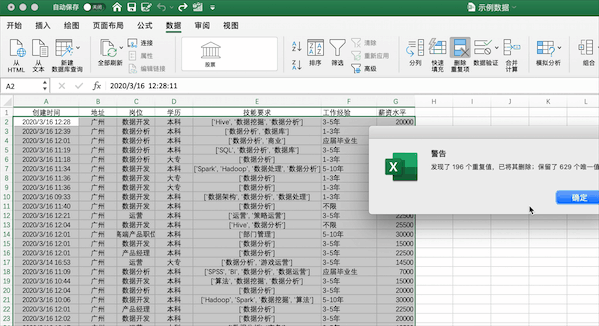
Pandas
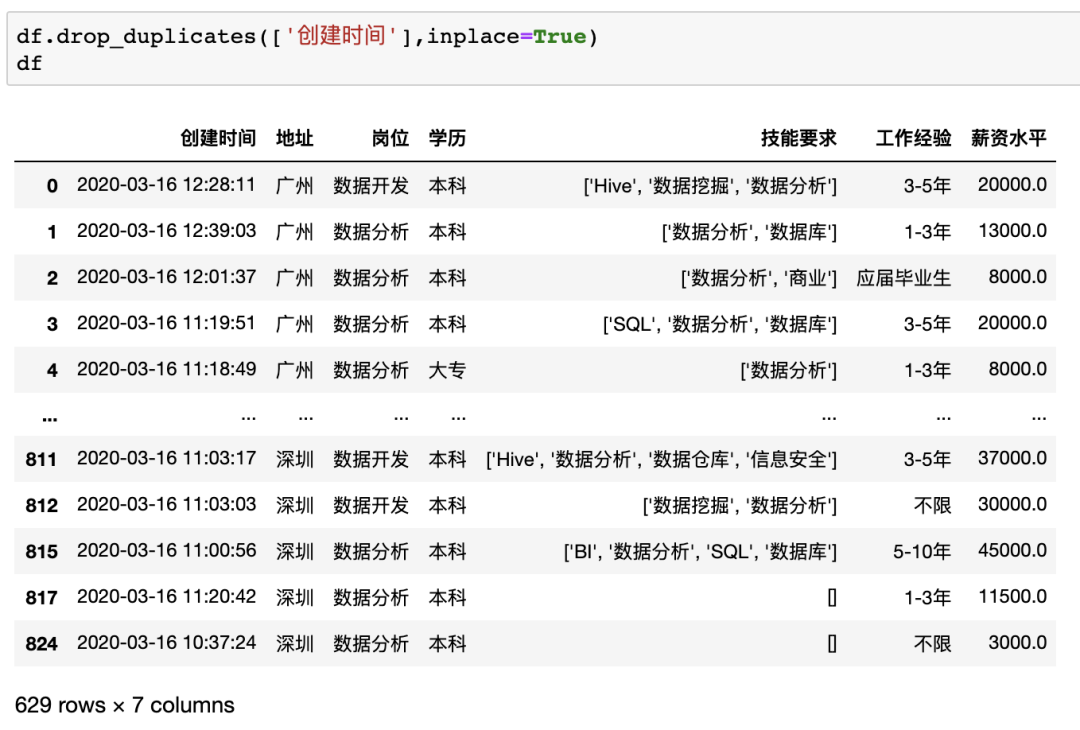
在pandas中可以使用drop_duplicates來(lái)對(duì)數(shù)據(jù)進(jìn)行去重,并且可以指定列以及保留順序,例如對(duì)示例數(shù)據(jù)按照創(chuàng)建時(shí)間列進(jìn)行去重df.drop_duplicates(['創(chuàng)建時(shí)間'],inplace=True),可以發(fā)現(xiàn)和Excel處理的結(jié)果一致,保留了?629?個(gè)唯一值。
格式修改
說(shuō)明:修改指定數(shù)據(jù)的格式
Excel
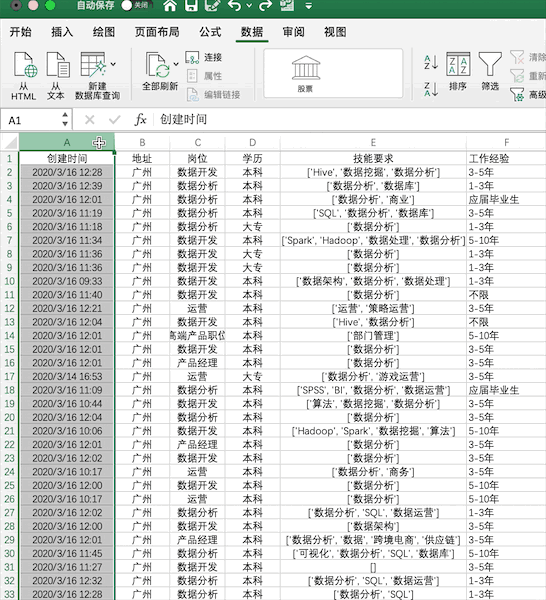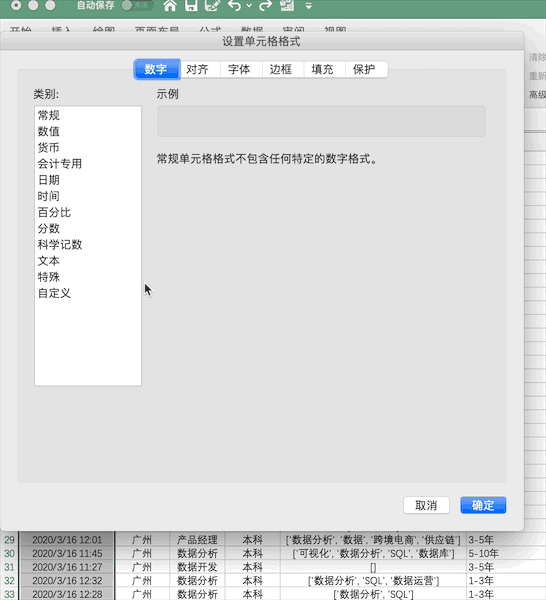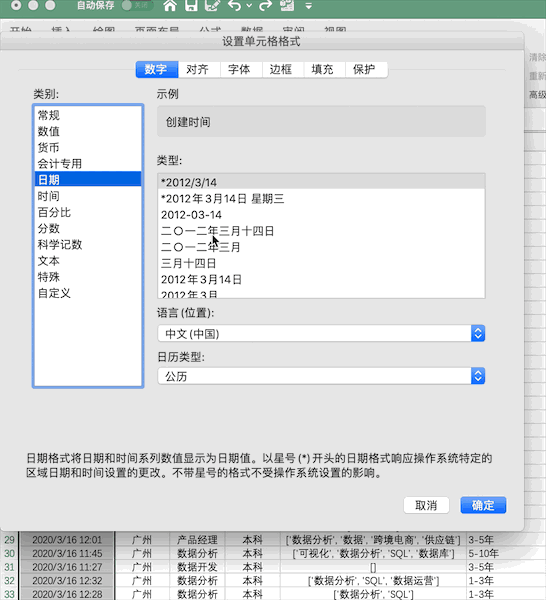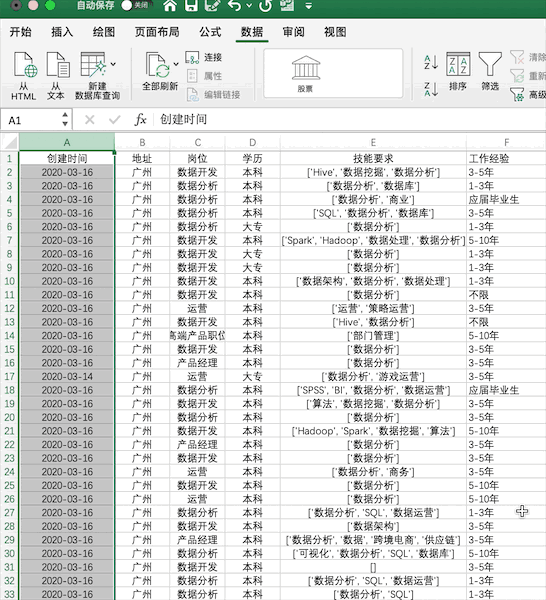
Pandas
在Pandas中沒(méi)有一個(gè)固定修改格式的方法,不同的數(shù)據(jù)格式有著不同的修改方法,比如類似Excel中將創(chuàng)建時(shí)間修改為年-月-日可以使用df['創(chuàng)建時(shí)間'] = df['創(chuàng)建時(shí)間'].dt.strftime('%Y-%m-%d')

數(shù)據(jù)交換
說(shuō)明:交換指定數(shù)據(jù)
Excel
在Excel中交換數(shù)據(jù)是很常用的操作,以交換示例數(shù)據(jù)中地址與崗位兩列為例,可以選中地址列,按住shift鍵并拖動(dòng)邊緣至下一列松開(kāi)即可
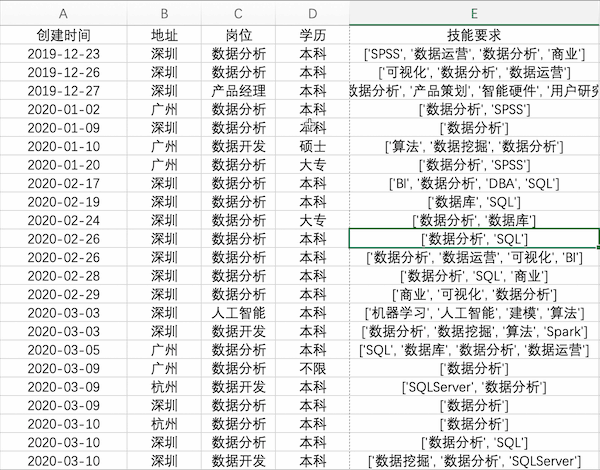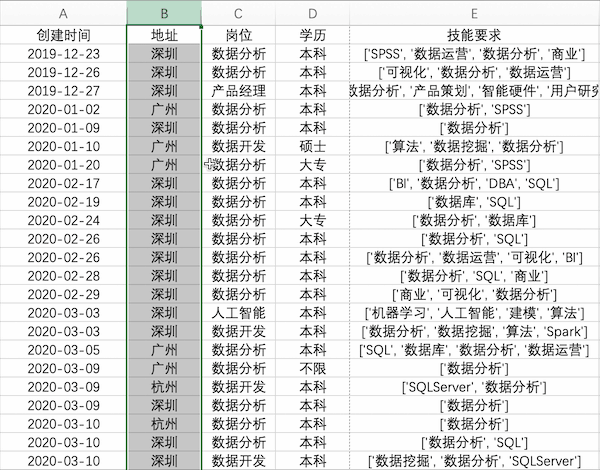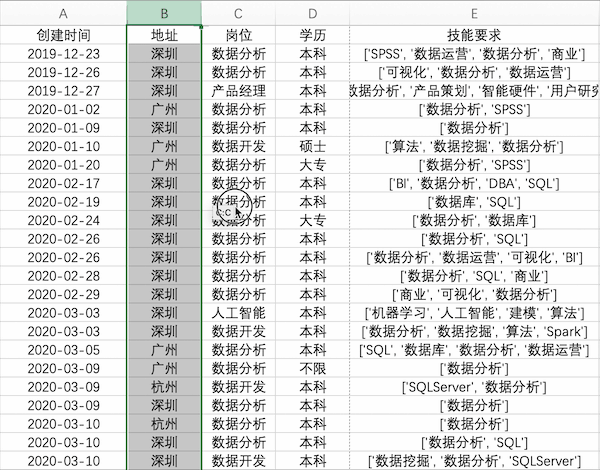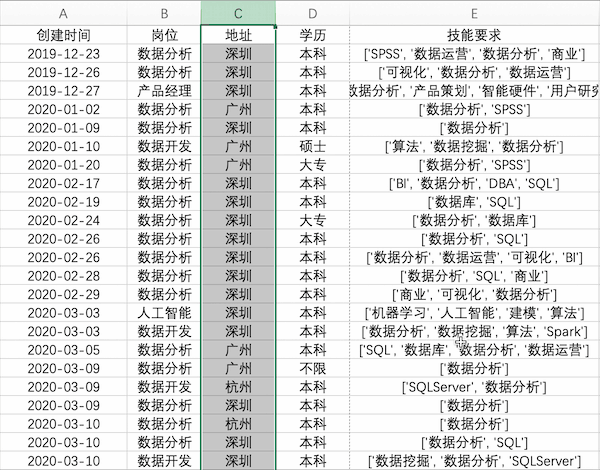
Pandas
在pandas中交換兩列也有很多方法,以交換示例數(shù)據(jù)中地址與崗位兩列為例,可以通過(guò)修改列號(hào)來(lái)實(shí)現(xiàn)
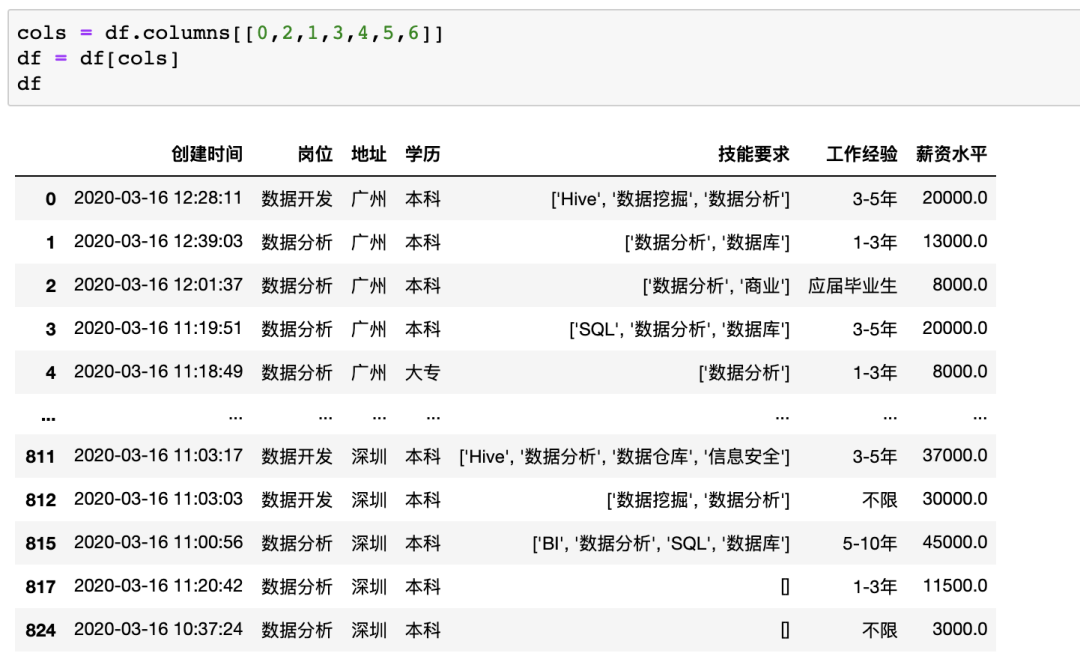
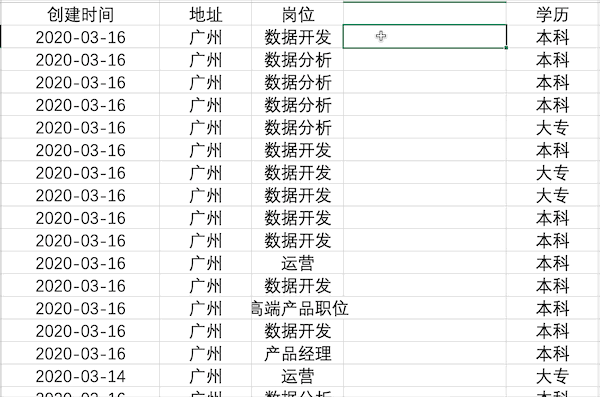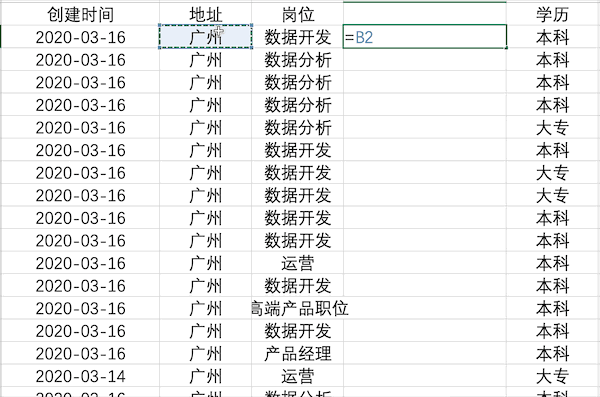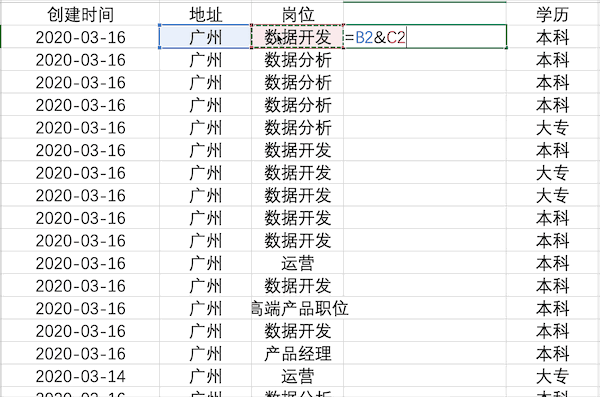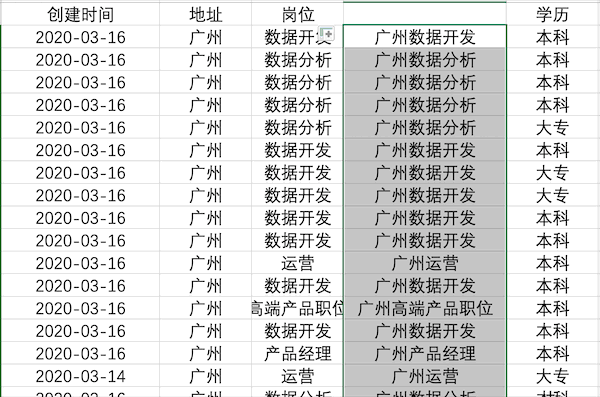
數(shù)據(jù)合并
說(shuō)明:將兩列或多列數(shù)據(jù)合并成一列
Excel
Pandas
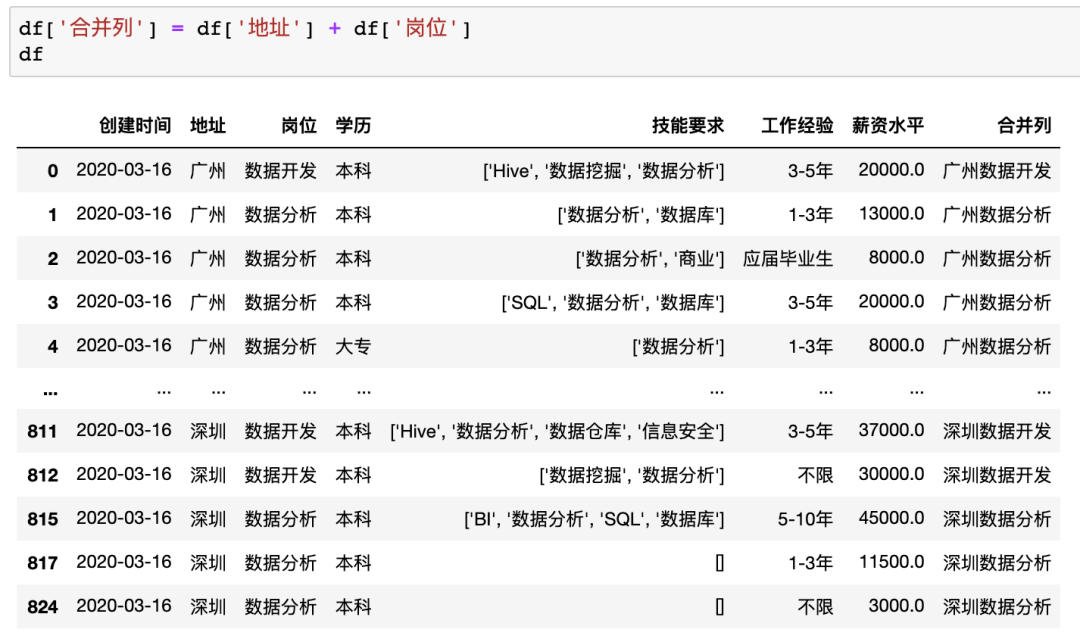
在Pandas中合并多列比較簡(jiǎn)單,類似于之前的數(shù)據(jù)插入操作,例如合并示例數(shù)據(jù)中的地址+崗位列使用df['合并列'] = df['地址'] + df['崗位']
數(shù)據(jù)拆分
說(shuō)明:將一列按照規(guī)則拆分為多列
Excel
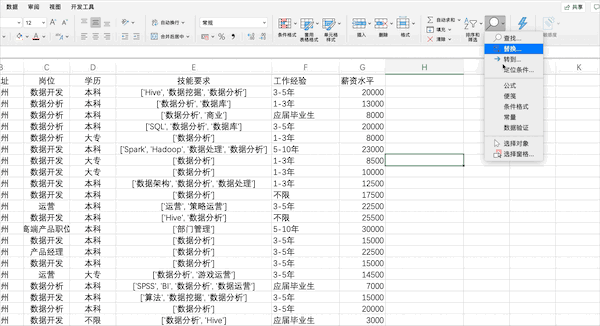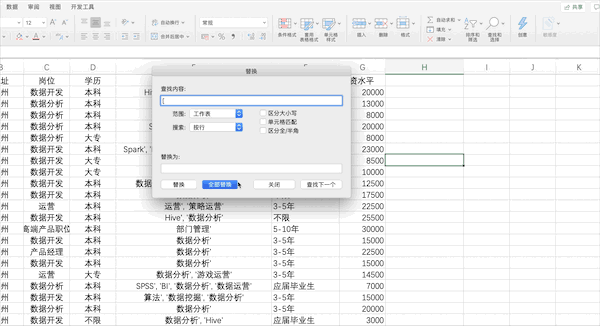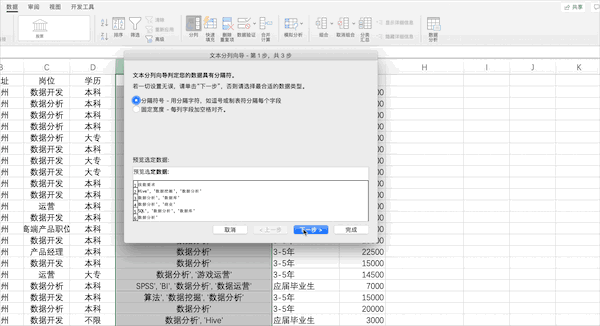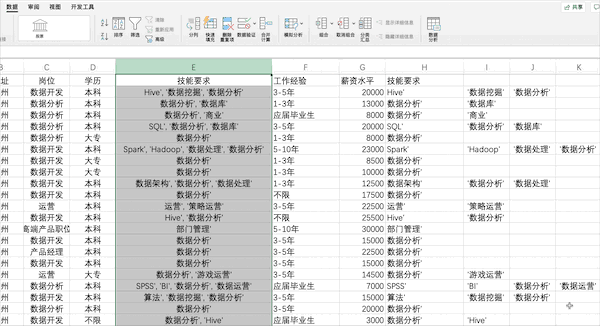
在Excel中可以通過(guò)點(diǎn)擊數(shù)據(jù)—>分列并按照提示的選項(xiàng)設(shè)置相關(guān)參數(shù)完成分列,但是由于該列含有[]等特殊字符,所以需要先使用查找替換去掉
Pandas
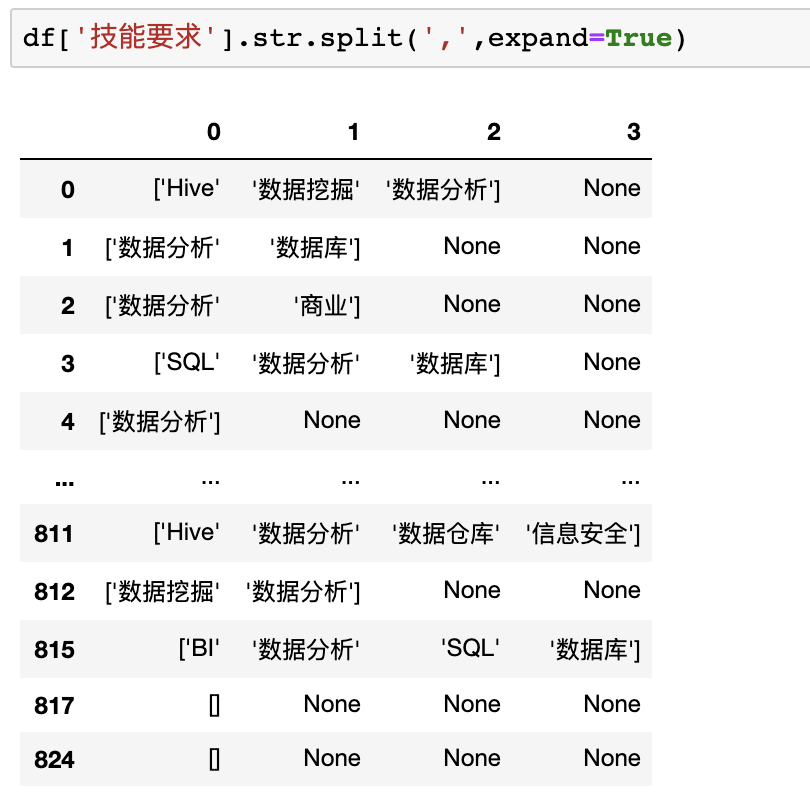
在Pandas中可以使用.split來(lái)完成分列,但是在分列完畢后需要使用merge來(lái)將分列完的數(shù)據(jù)添加至原DataFrame,對(duì)于分列完的數(shù)據(jù)含有[]字符,我們可以使用正則或者字符串lstrip方法進(jìn)行處理,但因不是pandas特性,此處不再展開(kāi)。
數(shù)據(jù)分組
說(shuō)明:對(duì)數(shù)據(jù)進(jìn)行分組計(jì)算
Excel
在Excel中對(duì)數(shù)據(jù)進(jìn)行分組計(jì)算需要先對(duì)需要分組的字段進(jìn)行排序,之后可以通過(guò)點(diǎn)擊分類匯總并設(shè)置相關(guān)參數(shù)完成,比如對(duì)示例數(shù)據(jù)的學(xué)歷進(jìn)行分組并求不同學(xué)歷的平均薪資
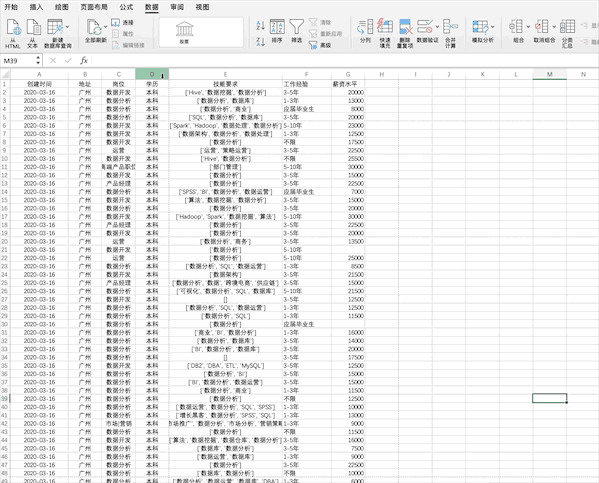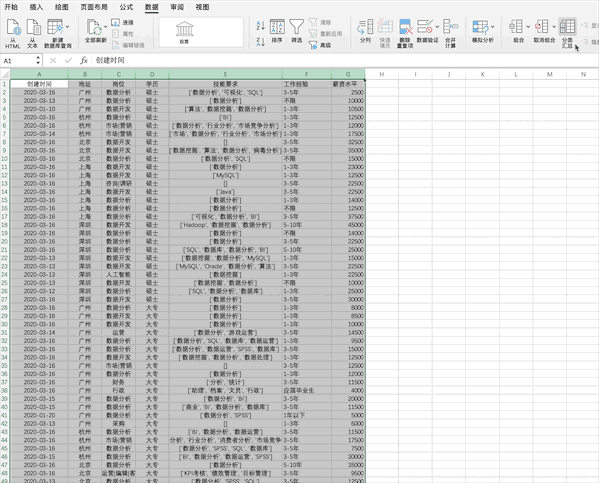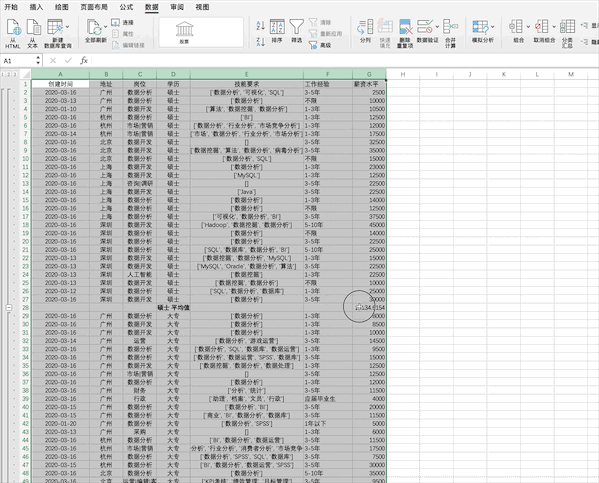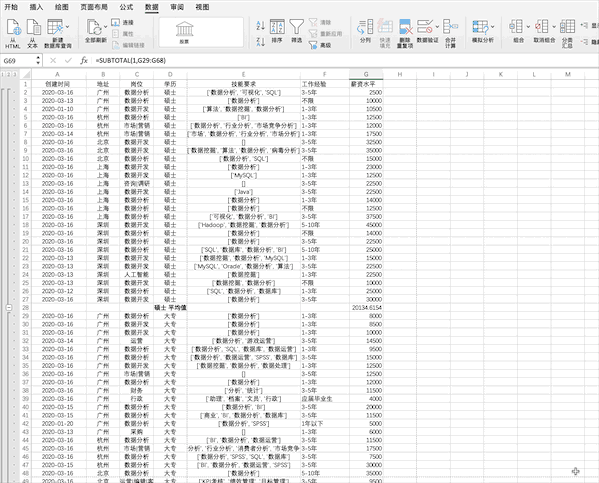
Pandas
在Pandas中對(duì)數(shù)據(jù)進(jìn)行分組計(jì)算可以使用groupby輕松搞定,比如使用df.groupby("學(xué)歷").mean()一行代碼即可對(duì)示例數(shù)據(jù)的學(xué)歷進(jìn)行分組并求不同學(xué)歷的平均薪資,結(jié)果與Excel一致

數(shù)據(jù)計(jì)算
說(shuō)明:對(duì)數(shù)據(jù)進(jìn)行一些計(jì)算
Excel
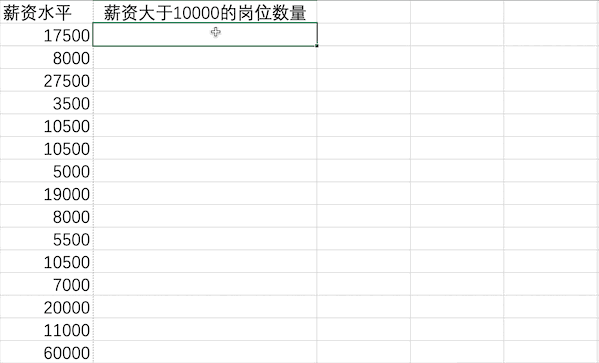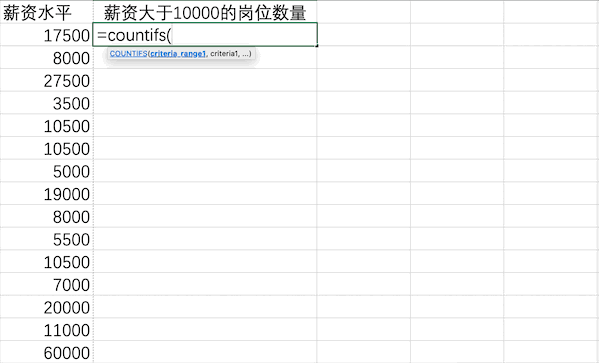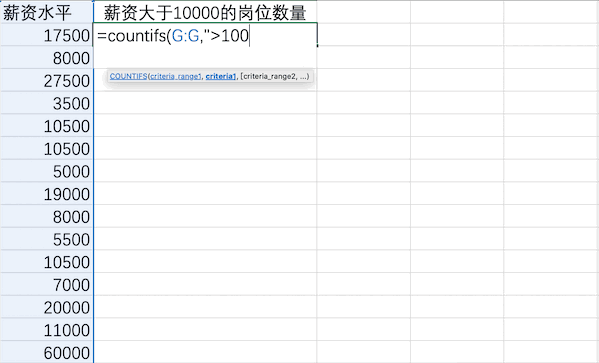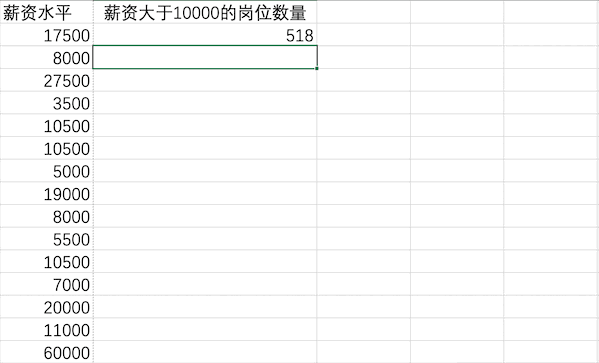
Pandas
在Pandas中可以直接使用類似數(shù)據(jù)篩選的方法來(lái)統(tǒng)計(jì)薪資大于10000的崗位數(shù)量len(df[df["薪資水平"]>10000])

數(shù)據(jù)統(tǒng)計(jì)
說(shuō)明:對(duì)數(shù)據(jù)進(jìn)行一些統(tǒng)計(jì)計(jì)算
Excel
在Excel中有很多統(tǒng)計(jì)相關(guān)的公式,也有現(xiàn)成的分析工具,比如對(duì)薪資水平列進(jìn)行描述性統(tǒng)計(jì)分析,可以通過(guò)添加工具庫(kù)之后點(diǎn)擊數(shù)據(jù)分析按鈕并設(shè)置相關(guān)參數(shù)
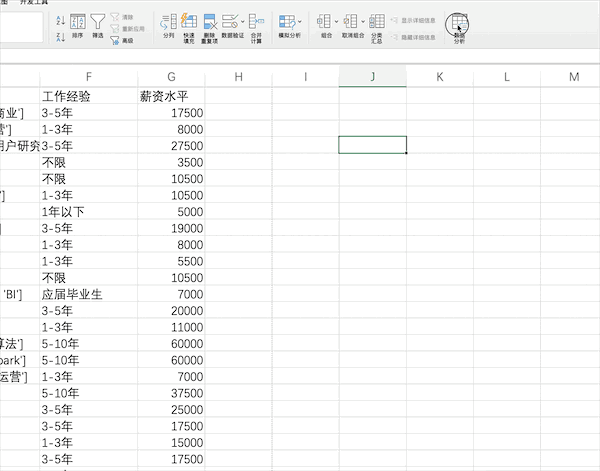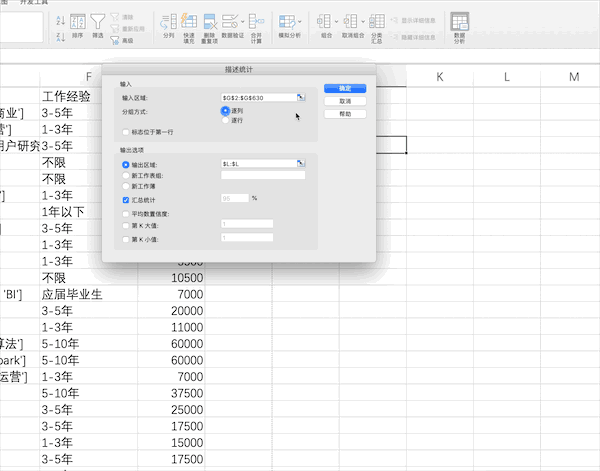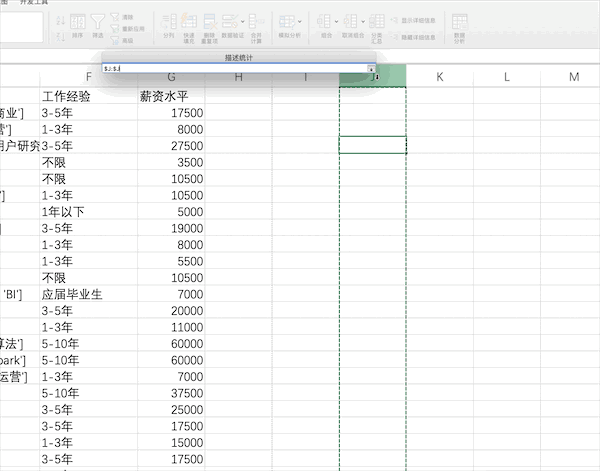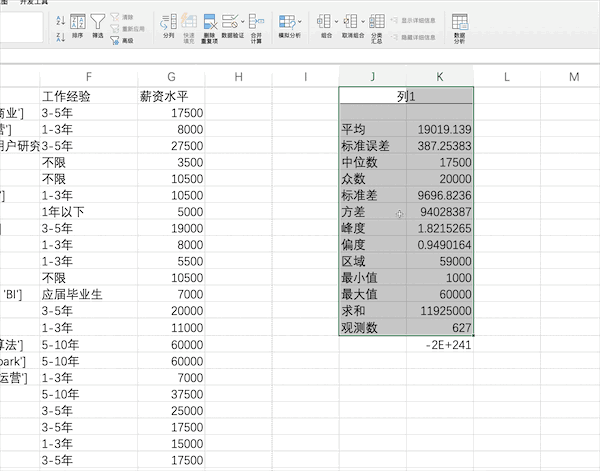
Pandas
在pandas中也有現(xiàn)成的函數(shù)describe快速完成對(duì)數(shù)據(jù)的描述性統(tǒng)計(jì),比如使用df["薪資水平"].describe()即可得到薪資列的描述性統(tǒng)計(jì)結(jié)果
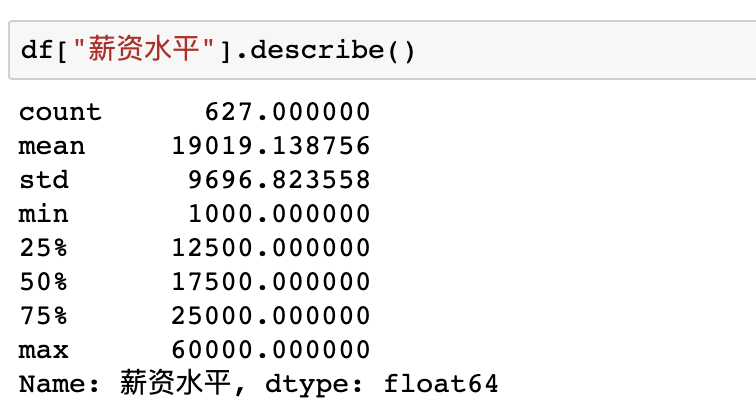
數(shù)據(jù)可視化
說(shuō)明:對(duì)數(shù)據(jù)進(jìn)行可視化
Excel
在Excel中可以通過(guò)點(diǎn)擊插入并選擇圖表來(lái)快速完成對(duì)數(shù)據(jù)的可視化,比如制作薪資的直方圖,并且有很多樣式可以直接使用
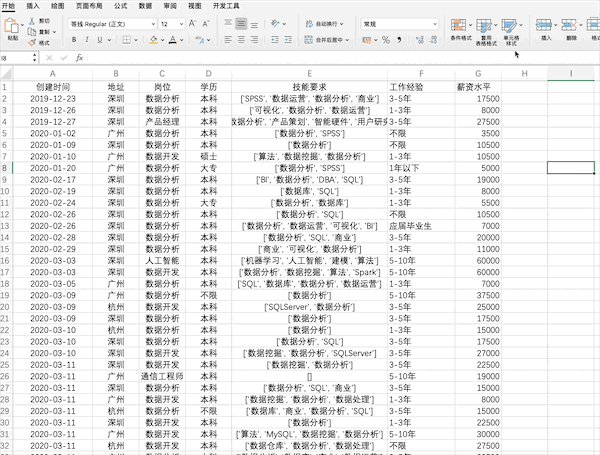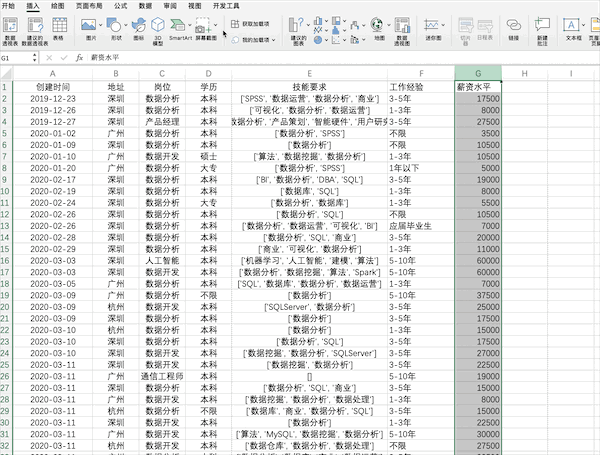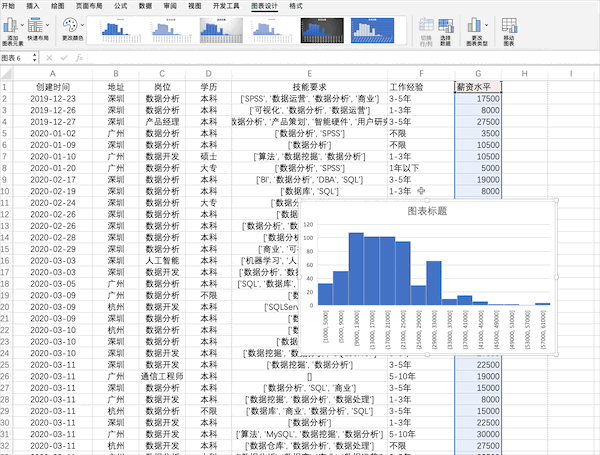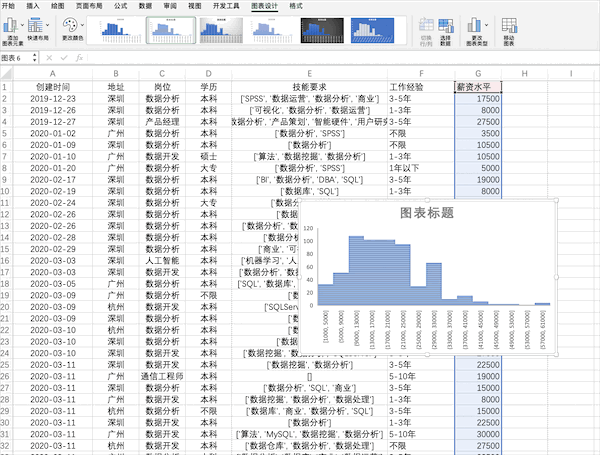
Pandas
在Pandas中也支持直接對(duì)數(shù)據(jù)繪制不同可視化圖表,例如直方圖,可以使用plot或者直接使用hist來(lái)制作df["薪資水平"].hist()
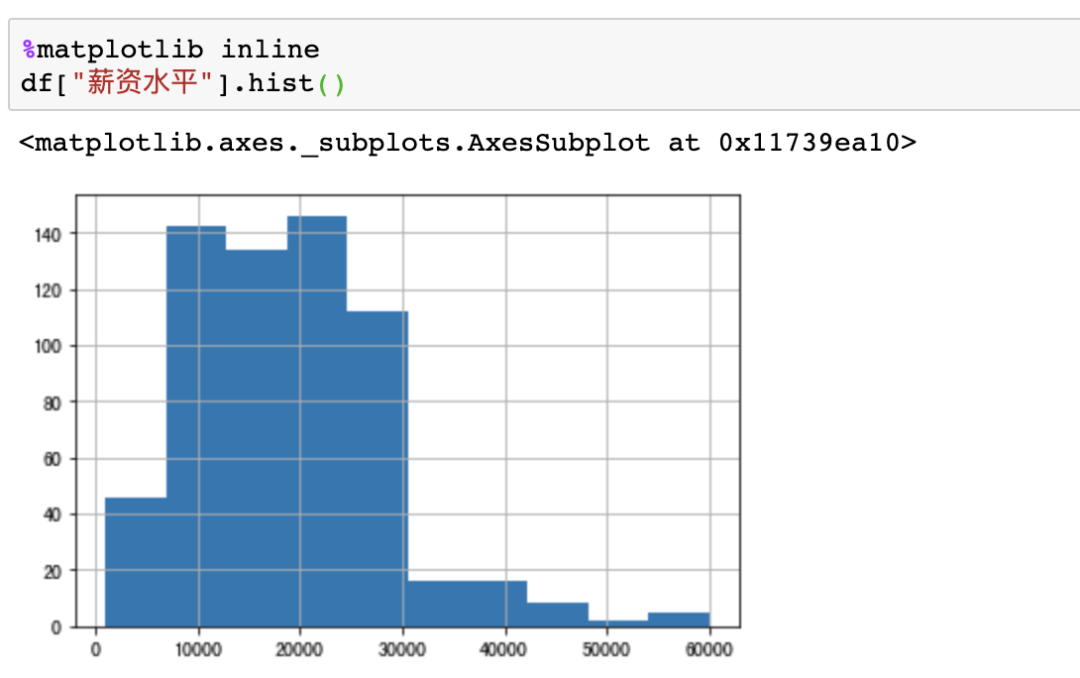
數(shù)據(jù)抽樣
說(shuō)明:對(duì)數(shù)據(jù)按要求采樣
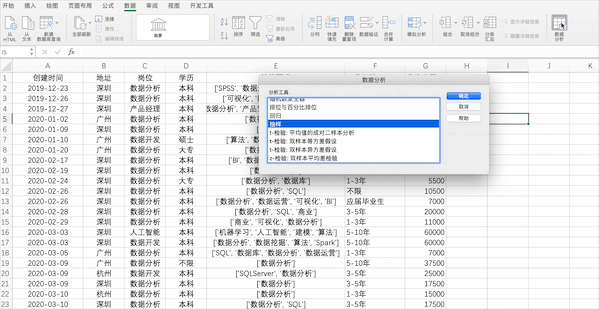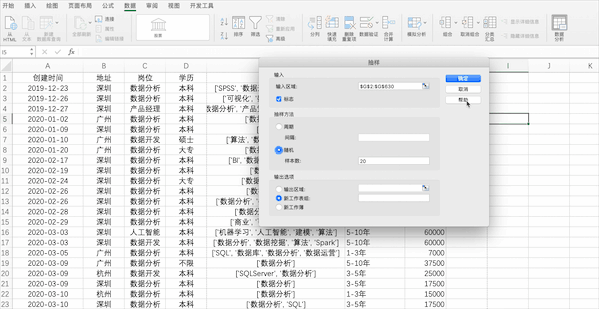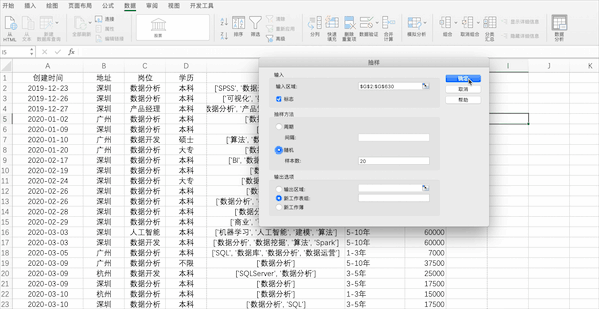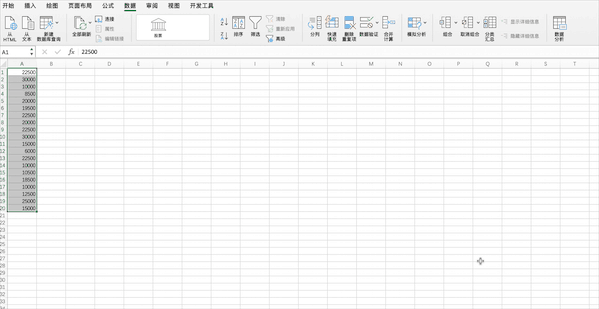
Excel
在Excel中抽樣可以使用公式也可以使用分析工具庫(kù)中的抽樣,但是僅支持對(duì)數(shù)值型的列抽樣,比如隨機(jī)抽20個(gè)示例數(shù)據(jù)中薪資的樣本
Pandas
在pandas中有抽樣函數(shù)sample可以直接抽樣,并且支持任意格式的數(shù)據(jù)抽樣,可以按照數(shù)量/比例抽樣,比如隨機(jī)抽20個(gè)示例數(shù)據(jù)中的樣本
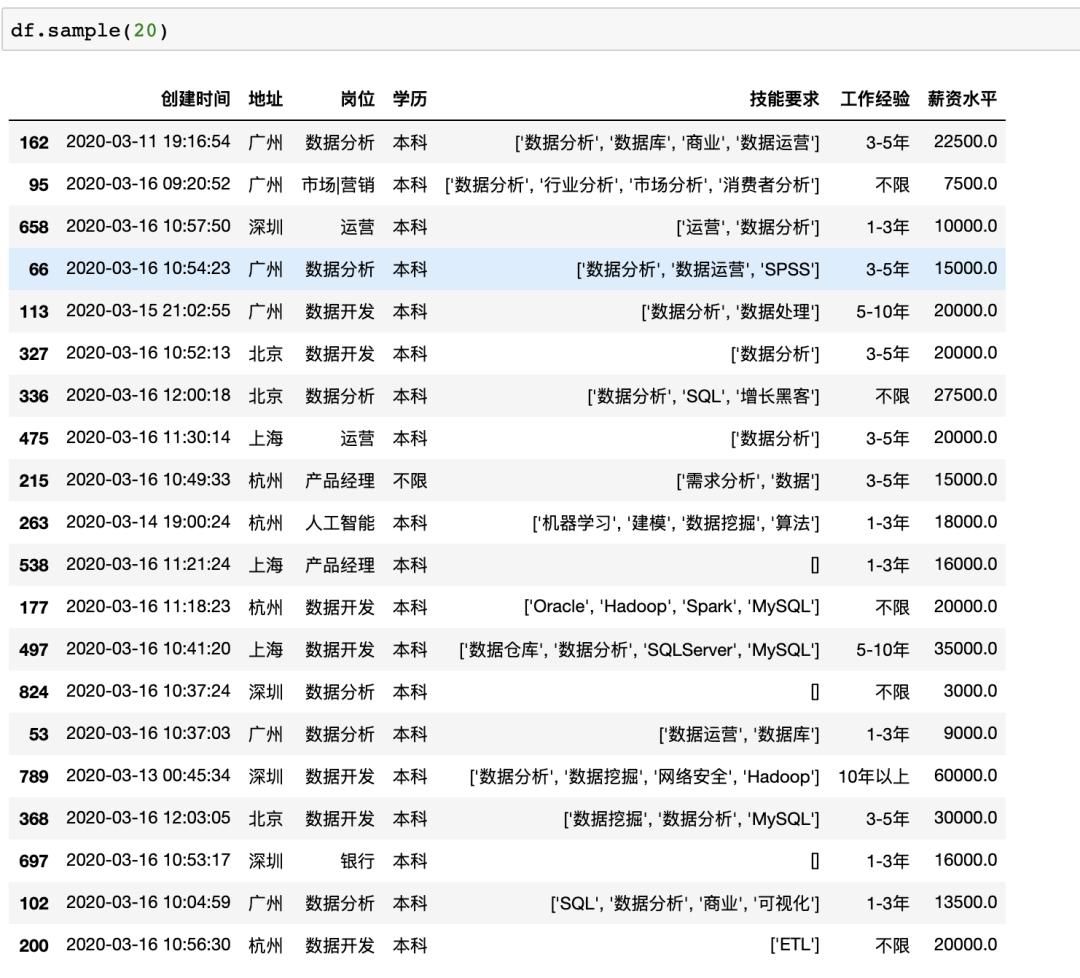
數(shù)據(jù)透視表
說(shuō)明:制作數(shù)據(jù)透視表
Excel
數(shù)據(jù)透視表是一個(gè)非常強(qiáng)大的工具,在Excel中有現(xiàn)成的工具,只需要選中數(shù)據(jù)—>點(diǎn)擊插入—>數(shù)據(jù)透視表即可生成,并且支持字段的拖取實(shí)現(xiàn)不同的透視表,非常方便,比如制作地址、學(xué)歷、薪資的透視表
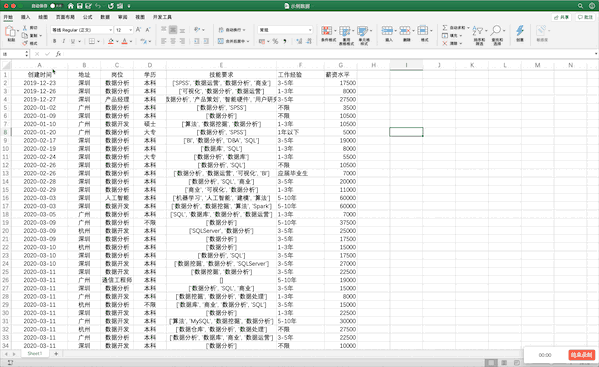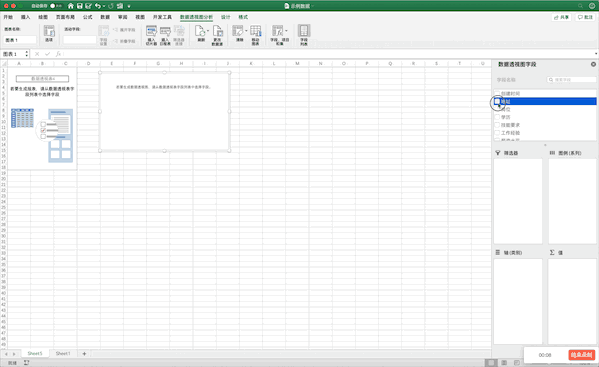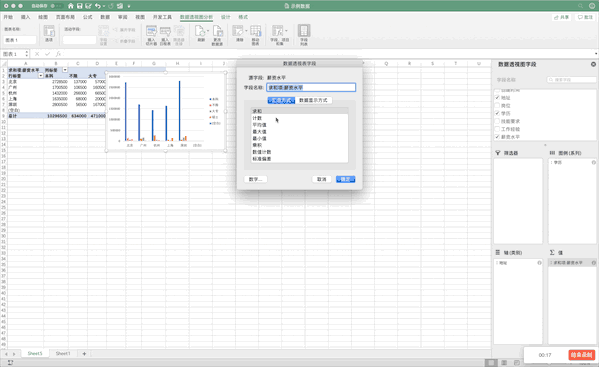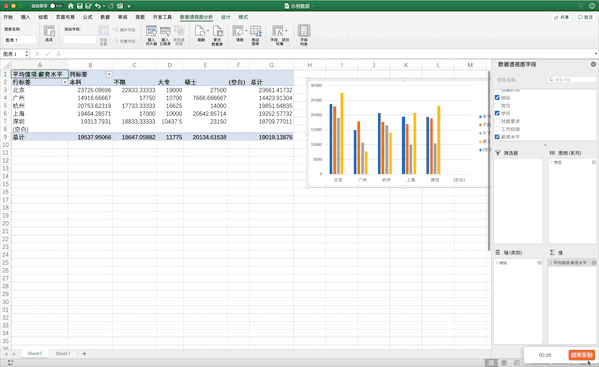
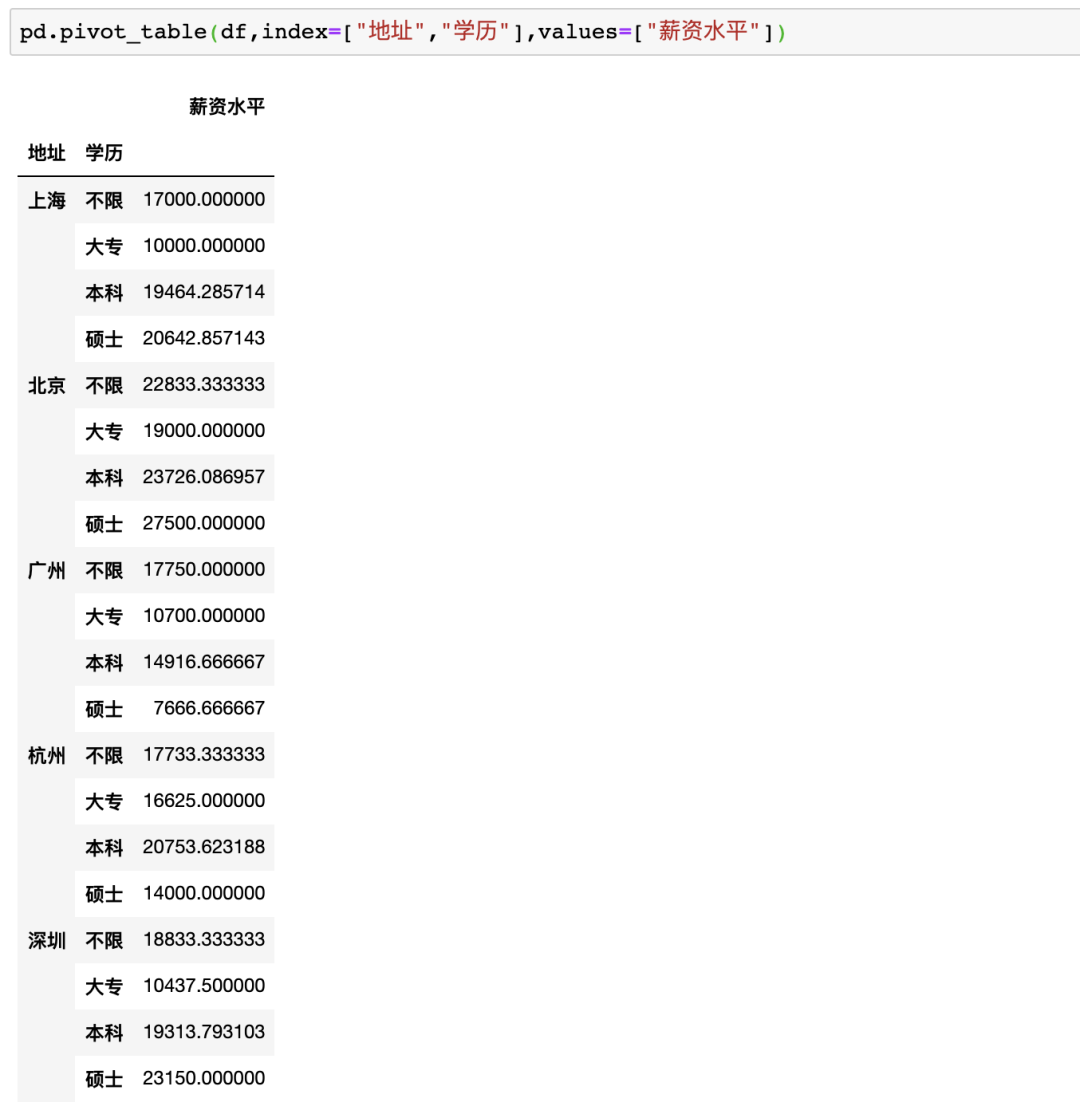
Pandas
在Pandas中制作數(shù)據(jù)透視表可以使用pivot_table函數(shù),例如制作地址、學(xué)歷、薪資的透視表pd.pivot_table(df,index=["地址","學(xué)歷"],values=["薪資水平"]),雖然結(jié)果一樣,但是并沒(méi)有Excel一樣方便調(diào)整與多樣
vlookup
說(shuō)明:利用VLOOKUP查找數(shù)據(jù)
Excel
VLOOKUP算是EXCEL中最核心的功能之一了,我們用一個(gè)簡(jiǎn)單的數(shù)據(jù)來(lái)進(jìn)行示例

Pandas
在Pandas中沒(méi)有現(xiàn)成的vlookup函數(shù),所以實(shí)現(xiàn)匹配查找需要一些步驟,首先我們讀取該表格
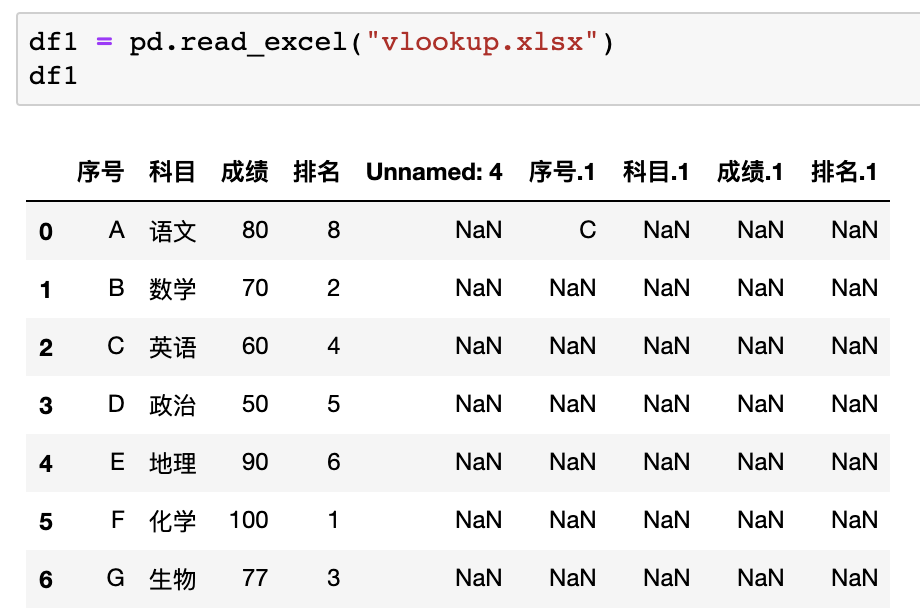

最后修改索引并使用update進(jìn)行兩表的匹配

結(jié)束語(yǔ)
以上就是使用Pandas來(lái)演示如何實(shí)現(xiàn)Excel中的常用操作的全部過(guò)程,其實(shí)可以發(fā)現(xiàn)Excel的優(yōu)點(diǎn)就是大多由交互式的點(diǎn)擊完成數(shù)據(jù)處理,而Pandas則完全依賴于代碼,對(duì)于有些操作比如數(shù)據(jù)透視表,用Excel制作更加方便,而有些操作比如數(shù)據(jù)的分組、計(jì)算等,因Pandas可以與NumPy等其他優(yōu)秀的Python庫(kù)結(jié)合而顯得更加強(qiáng)大,所以我們?cè)谔幚頂?shù)據(jù)時(shí)也需要正確選擇使用的工具!
python爬蟲(chóng)人工智能大數(shù)據(jù)公眾號(hào)
