
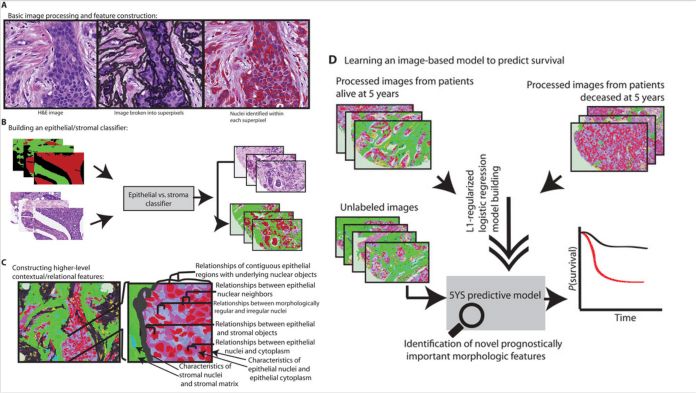
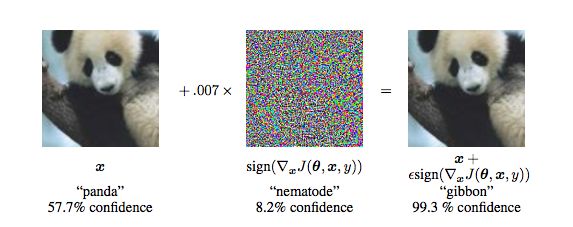
理解卷積神經(jīng)網(wǎng)絡的局限
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

URL:?https://bdtechtalks.com/2020/03/02/geoffrey-hinton-convnets-cnn-limits/? ???2020 AAAI中的keynote,Hinton



交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~
評論
圖片
表情