Python副業(yè)500元,爬取美團(tuán)外賣
500元爬取美團(tuán)外賣
??標(biāo)題黨了一下,實(shí)際上并沒有完整爬取,只是實(shí)現(xiàn)了部分爬取。具體情況是螞蟻老師的學(xué)習(xí)群中發(fā)了一個500元的爬取美團(tuán)店鋪信息的爬蟲單子,先是被人接單了,但沒過多久,因?yàn)殡y度太大,而退單了。有難度的事情,咱們頭鐵,試試看能不能搞得定。
任務(wù)要求與難度評估
任務(wù)要求:
目標(biāo)網(wǎng)站是美團(tuán)外賣的H5頁面https://h5.waimai.meituan.com 具體任務(wù)是爬取目標(biāo)店鋪的菜品、價格、圖片等 目標(biāo)店鋪可以自定義
難度評估:
??先嘗試找了一下目標(biāo)數(shù)據(jù),發(fā)現(xiàn)數(shù)據(jù)還是相對容易查到并解析的,整個任務(wù)難點(diǎn)不在數(shù)據(jù),而在于以下3處:
登錄需要手機(jī)號、短信驗(yàn)證碼,且有請求發(fā)送短信,需要通過滑動條驗(yàn)證碼的驗(yàn)證; 登錄后需要設(shè)置所在地,因?yàn)椋诘厥怯绊懰阉鹘Y(jié)果的,而如何設(shè)置所在地,有相當(dāng)復(fù)雜的邏輯(并沒有深入研究); 使用關(guān)鍵詞搜索目標(biāo)店鋪、進(jìn)入目標(biāo)店鋪、請求獲取數(shù)據(jù),等等有非常復(fù)雜的邏輯、參數(shù)極多,解析有大量的工作量。
方案確定
??綜合上述難點(diǎn),坦率而言,500元的標(biāo)價是不匹配的,且時效要求只有1天,幾乎是不可能的任務(wù)(大神除外)。于是先找甲方溝通了一下,發(fā)現(xiàn)甲方的實(shí)際需求極為簡單,時效緊是因?yàn)槎虝r間內(nèi)有5家店鋪信息需要獲取上線。
??而后續(xù)即使有新增目標(biāo),也是少量的,陸陸續(xù)續(xù)產(chǎn)生的需求。其實(shí)只需要解決獲取數(shù)據(jù),下載圖片(每個店鋪可能對應(yīng)100多個菜品,此處是繁瑣的工作量),且不出錯即可。
??對于甲方來說,其需求量少,不可能投入大量的資源解決這么一個小問題,對于接單人來說,又不可能為了這么一點(diǎn)收獲,投入大量精力,二者存在偏差。那么如何使二者達(dá)成一致呢?
??于是,我提出了半自動爬蟲的方案解決問題,也征得了甲方的同意。何謂半自動爬蟲呢?即在需求的店鋪數(shù)量有限的前提下,在部分獲取數(shù)據(jù)環(huán)節(jié)上通過人工操作的方式解決,回避前面的3個難點(diǎn);而爬蟲專注于解決數(shù)據(jù)解析,以及下載圖片的繁瑣步驟。
??達(dá)成一致后,那么就開始代碼吧~~~
頁面分析
登錄、設(shè)置地址、查找目標(biāo)店鋪
??這些步驟都人工操作了,就不需要分析頁面了。唯一碰到的問題是,使用PC瀏覽器登錄時,發(fā)送驗(yàn)證碼的滾動條驗(yàn)證步驟無法通過,需要使用手機(jī)瀏覽器成功發(fā)送驗(yàn)證碼后,將驗(yàn)證碼填入PC端登錄。
巨坑注意:雖然PC端無法通過滾動條驗(yàn)證步驟,但是該動作還是要做的,否則即使填入了手機(jī)獲取到的驗(yàn)證碼,是無法提交登錄的。(與甲方共同測試時,在這個環(huán)節(jié)卡了好久)
目標(biāo)店鋪數(shù)據(jù)分析
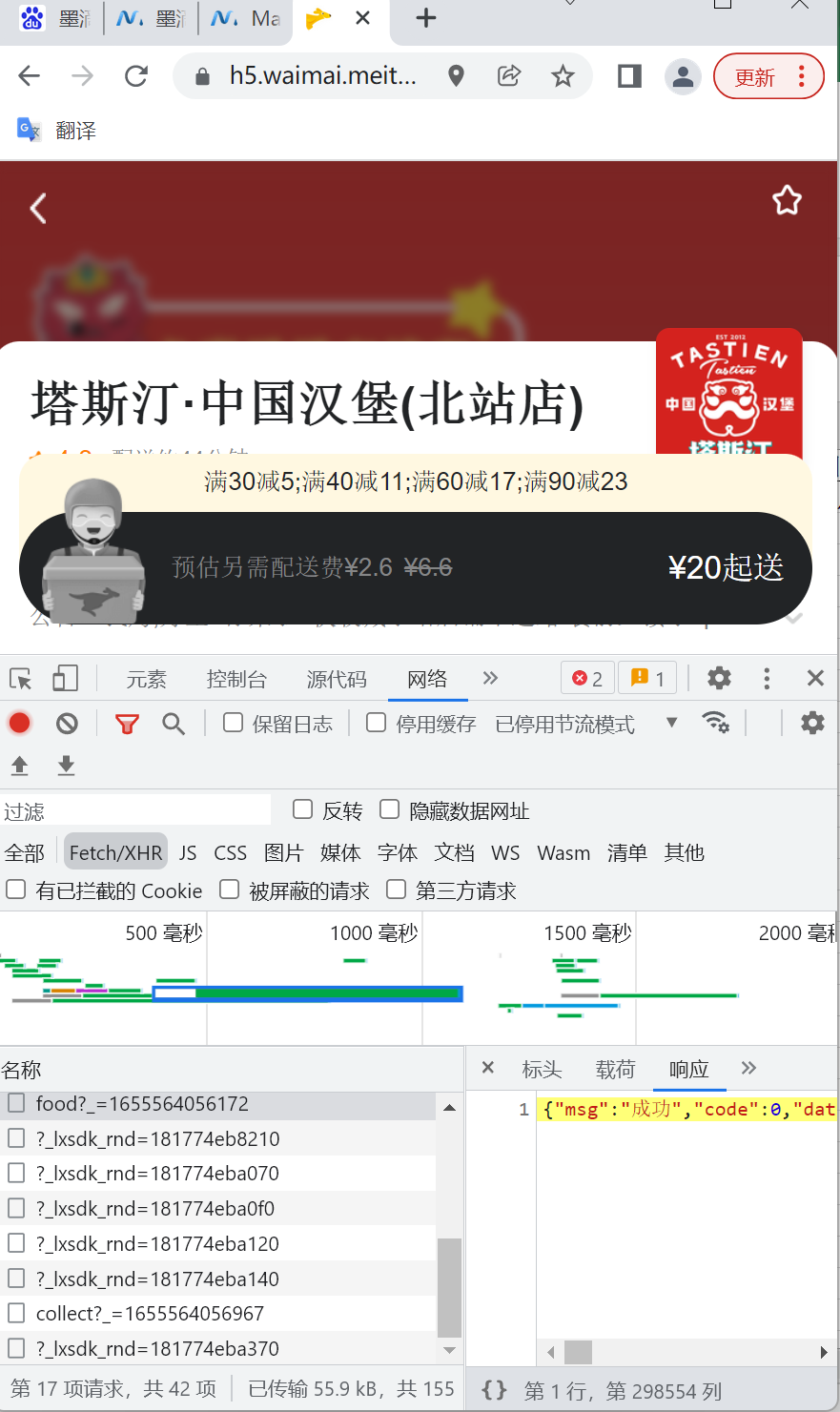
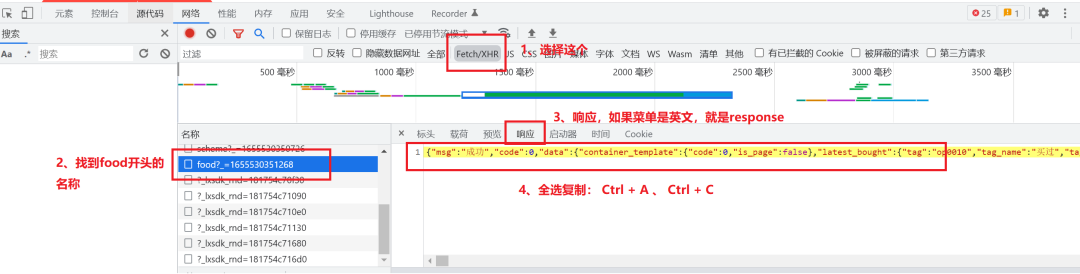
??該步驟不難,F(xiàn)12打開chrome的開發(fā)者模式,進(jìn)入店鋪后,使用關(guān)鍵詞搜索一下,就能發(fā)現(xiàn),所有的菜品,都在一個food的response中
圖片目標(biāo)分析
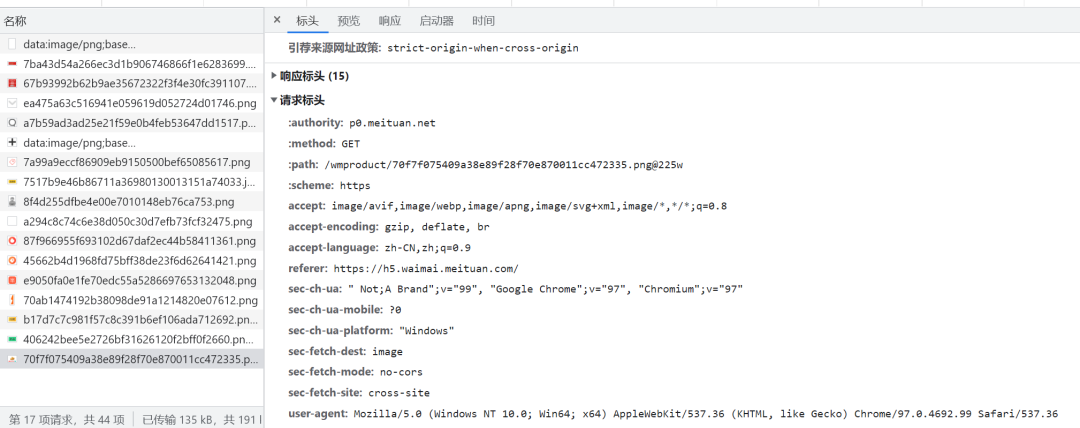
??圖片的請求則相當(dāng)簡單,只需要設(shè)置請求頭,再使用GET請求圖片網(wǎng)址即可,而圖片網(wǎng)址在目標(biāo)店鋪的數(shù)據(jù)中,每個菜品都有對應(yīng)的圖片網(wǎng)址。
解決步驟與代碼
將人工獲取的店鋪數(shù)據(jù)存入TXT文件,放在一個目錄下,如下圖:

有了數(shù)據(jù)之后,遍歷、讀取、加工數(shù)據(jù)、下載圖片就都是基礎(chǔ)的json、pandas與requests的操作了,具體詳見代碼注釋吧。
# -*- coding: utf-8 -*-
# @author: Lin Wei
# @contact: [email protected]
# @time: 2022/6/18 9:24
"""
本程序用于分析爬取美團(tuán)外賣的店鋪商品信息及圖片
1、本程序不考慮登錄美團(tuán)、定位、查找店鋪等操作,直接使用人工查找獲得的信息進(jìn)行解析,獲取店鋪信息
2、根據(jù)店鋪信息中的圖片地址,下載對應(yīng)圖片
"""
import time
import requests
import pandas as pd
import json
import pathlib as pl
from random import randint
class SpiderObj:
"""
爬蟲對象
"""
def __init__(self):
"""
初始化對象
"""
self.file_path = pl.Path(input('請已保存的店鋪數(shù)據(jù)文件路徑:\n'))
def create_dir(self, shop_name: str) -> tuple:
"""
檢查并創(chuàng)建文件夾
:param shop_name: 店鋪名
:return:
"""
shop_dir = self.file_path / shop_name
pic_dir = shop_dir / '圖片'
if not shop_dir.is_dir(): # 如果店鋪文件夾不存在,則創(chuàng)建
shop_dir.mkdir()
if not pic_dir.is_dir(): # 如果圖片文件夾不存在,則創(chuàng)建
pic_dir.mkdir()
return shop_dir, pic_dir
@classmethod
def get_origin_price(cls, ser: pd.Series) -> float:
"""
解析skus中的原價origin_price
:param ser: 數(shù)據(jù)行
:return:
"""
skus = ser['skus'][0]
origin_price = skus['origin_price']
return origin_price
@classmethod
def parse_data(cls, filename: pl.Path) -> tuple:
"""
解析獲取到的美團(tuán)店鋪數(shù)據(jù)
:param filename: 存儲數(shù)據(jù)的文件路徑
:return:
"""
with open(filename, 'r', encoding='utf-8') as fin:
data = fin.read()
data = json.loads(data)
# 解析數(shù)據(jù)步驟
shop_name = data['data']['poi_info']['name']
data = data['data']['food_spu_tags']
df = pd.DataFrame()
for tag in data:
dfx = pd.DataFrame(tag['spus'])
dfx['分類'] = tag['name']
df = pd.concat([df, dfx])
df = df.loc[df['分類'].map(lambda x: x not in ['折扣', '熱銷', '推薦'])]
df['原價'] = df.apply(cls.get_origin_price, axis=1)
df.reset_index(inplace=True, drop=True)
return shop_name, df
@classmethod
def download_picture(cls, url: str, filename: pl.Path):
"""
下載圖片的方法
:param url: 圖片的地址
:param filename: 輸出圖片的路徑(含文件名)
:return:
"""
# 初始化請求頭
headers = {
"accept": "image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"referer": "https://h5.waimai.meituan.com/",
"sec-ch-ua": "\" Not;A Brand\";v=\"99\", \"Google Chrome\";v=\"97\", \"Chromium\";v=\"97\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "image",
"sec-fetch-mode": "no-cors",
"sec-fetch-site": "cross-site",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"
}
# 下載文件
file = requests.get(url, headers, stream=True)
with open(filename, "wb") as code:
for chunk in file.iter_content(chunk_size=1024): # 邊下載邊存硬盤
if chunk:
code.write(chunk)
@classmethod
def get_pictures(cls, shop_name: str, data: pd.DataFrame, pic_dir: pl.Path):
"""
批量獲取圖片數(shù)據(jù)的方法
:param shop_name: 店鋪名
:param data: 數(shù)據(jù)
:param pic_dir: 圖片存放的目錄
:return:
"""
print(f'開始下載店鋪:{shop_name} 的圖片')
# 下載前按照菜品名稱與圖片地址進(jìn)行去重處理,減少請求數(shù)量
download_data = data.copy()
download_data = download_data.drop_duplicates(['name', 'picture'], keep='last')
# 篩選去除圖片地址為空的
download_data = download_data.loc[
(download_data['picture'].map(lambda x: pd.notnull(x))) |
(download_data['picture'] != '')
]
max_len = len(download_data)
for idx, food in enumerate(download_data.to_dict(orient='records')): # 遍歷數(shù)據(jù)
pic_url = food['picture']
# 拆分獲取圖片擴(kuò)展名
suffix = pl.Path(pic_url.split('/')[-1]).suffix
# 加工出圖片的路徑(包含名稱)
name = food['name'].replace('\\', '_').replace('/', '_')
filename = pic_dir / f"{name}{suffix}"
# 使用下載方法下載
try:
cls.download_picture(pic_url, filename)
print(f'({idx+1}/{max_len})菜品:{food["name"]} 圖片下載完成')
except Exception as e:
print(f'!!!({idx+1}/{max_len})菜品:{food["name"]} 圖片下載失敗,錯誤提示是: {e}')
# 隨機(jī)暫停
time.sleep(randint(1, 3) / 10)
@classmethod
def write_data(cls, shop_name, data, shop_dir):
"""
將數(shù)據(jù)輸出至excel文件
:param shop_name: 店鋪名
:param data: 數(shù)據(jù)
:param shop_dir: 店鋪存放的文件夾
:return:
"""
data.to_excel(shop_dir / f'{shop_name}.xlsx', index=False)
def run(self):
"""
運(yùn)行程序
:return:
"""
try:
for filename in self.file_path.iterdir():
# 先解析人工取得的數(shù)據(jù)
shop_name, data = self.parse_data(filename)
# 再創(chuàng)建文件夾
shop_dir, pic_dir = self.create_dir(shop_name)
# 寫入Excel文件
self.write_data(shop_name, data, shop_dir)
# 獲取圖片
self.get_pictures(shop_name, data, pic_dir)
print(f'店鋪:{shop_name}的數(shù)據(jù)已解析下載完畢,數(shù)據(jù)存儲在:“{shop_dir.absolute()}”路徑下')
return True, None
except Exception as e:
return False, e
if __name__ == '__main__':
spider = SpiderObj()
res, err = spider.run()
if res:
input('程序已運(yùn)行完畢,按回車鍵退出')
else:
input(f'程序運(yùn)行出錯,錯誤提示是: {err}')
程序運(yùn)行

總結(jié)
??不管全自動還是半自動,能解決問題的都是好爬蟲。最后實(shí)現(xiàn)的爬蟲實(shí)際上使用到的知識點(diǎn)都不是困難的:
讀取文件,使用json、pandas解析數(shù)據(jù)輸出Excel表格; 使用for循環(huán),requests的get請求下載圖片 創(chuàng)建文件夾,去重、try-except等
因此需求是要進(jìn)行多溝通的,說不定溝通后有難度的會變成沒有難度的...
至于回避的那三個難點(diǎn)留給某位大老板用Money激發(fā)我去攻克吧^_^
今晚來螞蟻老師抖音直播間,Python帶副業(yè)全套餐有優(yōu)惠!!!