
來自Facebook AI的多任務(wù)多模態(tài)的統(tǒng)一Transformer:向更通用的智能邁出了一步
點(diǎn)擊上方“AI算法與圖像處理”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達(dá)
作者:Synced
編譯:ronghuaiyang 來源 AI公園
一個模型完成了CV,NLP方向的7個任務(wù),每個任務(wù)上表現(xiàn)都非常好。
論文鏈接:https://arxiv.org/pdf/2102.10772.pdf
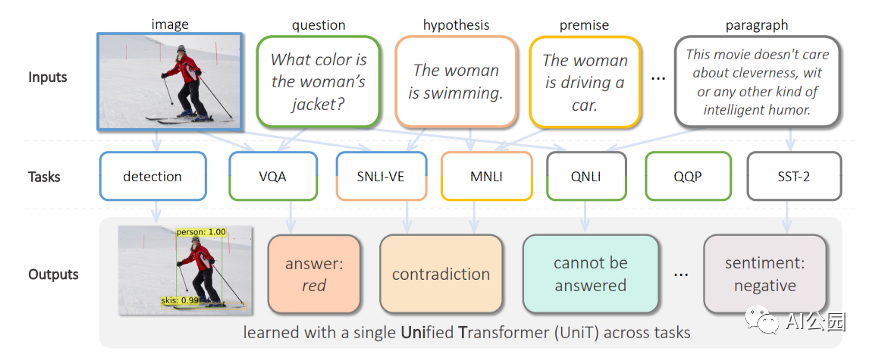
Transformer架構(gòu)在自然語言處理和其他領(lǐng)域的機(jī)器學(xué)習(xí)(ML)任務(wù)中表現(xiàn)出了巨大的成功,但大多僅限于單個領(lǐng)域或特定的多模態(tài)領(lǐng)域的任務(wù)。例如,ViT專門用于視覺相關(guān)的任務(wù),BERT專注于語言任務(wù),而VILBERT-MT只用于相關(guān)的視覺和語言任務(wù)。
一個自然產(chǎn)生的問題是:我們能否建立一個單一的Transformer,能夠在多種模態(tài)下處理不同領(lǐng)域的廣泛應(yīng)用?最近,F(xiàn)acebook的一個人工智能研究團(tuán)隊進(jìn)行了一個新的統(tǒng)一Transformer(UniT) encoder-decoder模型的挑戰(zhàn),該模型在不同的模態(tài)下聯(lián)合訓(xùn)練多個任務(wù),并通過一組統(tǒng)一的模型參數(shù)在這些不同的任務(wù)上都實現(xiàn)了強(qiáng)大的性能。

Transformer首先應(yīng)用于sequence-to-sequence模型的語言領(lǐng)域。它們已經(jīng)擴(kuò)展到視覺領(lǐng)域,甚至被應(yīng)用于視覺和語言的聯(lián)合推理任務(wù)。盡管可以針對各種下游任務(wù)中的應(yīng)用對預(yù)先訓(xùn)練好的Transformer進(jìn)行微調(diào),并獲得良好的結(jié)果,但這種模型微調(diào)方法會導(dǎo)致為每個下游任務(wù)創(chuàng)建不同的參數(shù)集。
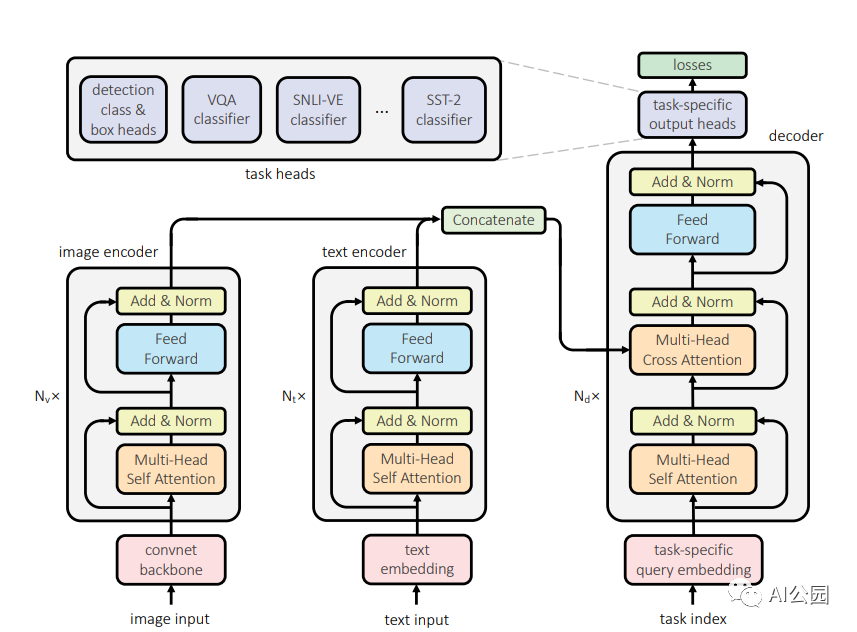
Facebook的人工智能研究人員提出,一個Transformer可能就是我們真正需要的。他們的UniT是建立在傳統(tǒng)的Transformer編碼器-解碼器架構(gòu)上,包括每個輸入模態(tài)類型的獨(dú)立編碼器,后面跟一個具有簡單的每個任務(wù)特定的頭的解碼器。輸入有兩種形式:圖像和文本。首先,卷積神經(jīng)網(wǎng)絡(luò)骨干網(wǎng)提取視覺特征,然后BERT將語言輸入編碼成隱藏狀態(tài)序列。然后,Transformer解碼器應(yīng)用于編碼的單個模態(tài)或兩個編碼模態(tài)的連接序列(取決于任務(wù)是單模態(tài)還是多模態(tài))。最后,Transformer解碼器的表示將被傳遞到特定任務(wù)的頭,該頭將輸出最終的預(yù)測。
評估UniT的性能,研究人員進(jìn)行了實驗,需要共同學(xué)習(xí)來自不同領(lǐng)域的許多流行的任務(wù):COCO目標(biāo)檢測和 Visual Genome數(shù)據(jù)集,語言理解任務(wù)的GLUE基準(zhǔn)(QNLI, QQP、MNLI-mismatched SST-2),以及視覺推理任務(wù)VQAv2 SNLI-VE數(shù)據(jù)集。
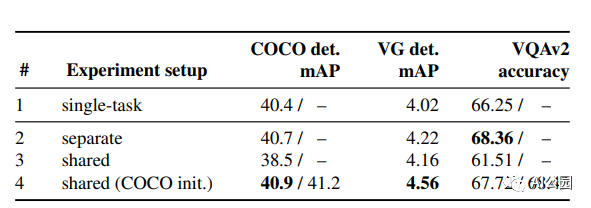
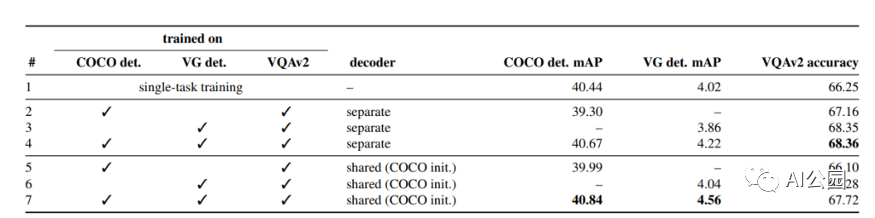
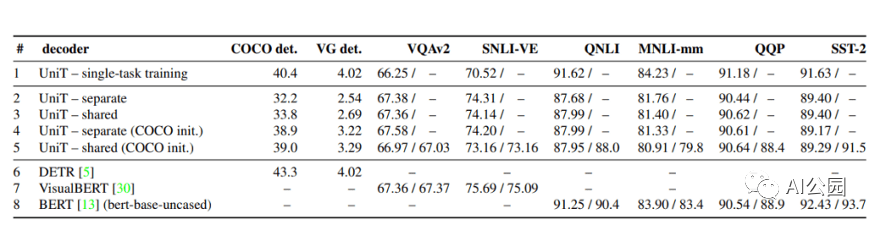

結(jié)果表明,所提出的UniT 模型同時處理8個數(shù)據(jù)集上的7個任務(wù),在統(tǒng)一的模型參數(shù)集下,每個任務(wù)都有較強(qiáng)的性能。強(qiáng)大的性能表明UniT有潛力成為一種領(lǐng)域未知的transformer 架構(gòu),向更通用的智能的目標(biāo)邁進(jìn)了一步。

英文原文:https://medium.com/syncedreview/facebook-ais-multitask-multimodal-unified-transformer-a-step-toward-general-purpose-98db2c858603
個人微信(如果沒有備注不拉群!) 請注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會分享
在「AI算法與圖像處理」公眾號后臺回復(fù):何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風(fēng)格指南
在「AI算法與圖像處理」公眾號后臺回復(fù):c++,即可下載。歷經(jīng)十年考驗,最權(quán)威的編程規(guī)范!
下載3 CVPR2020 在「AI算法與圖像處理」公眾號后臺回復(fù):CVPR2020,即可下載1467篇CVPR 2020論文
覺得不錯就點(diǎn)亮在看吧
