
多媒體領(lǐng)域頂會ACM MM 2023 閉幕,獲獎?wù)撐囊挥[!

多媒體領(lǐng)域頂會
國際多媒體會議(The 31th ACM International Conference on Multimedia,ACM MM)于2023年10月28日至11月3日在加拿大渥太華舉行,該會議是計(jì)算機(jī)圖形學(xué)與多媒體領(lǐng)域頂級會議,被中國計(jì)算機(jī)學(xué)會列為A類會議。
ACM MM 研究內(nèi)容廣泛,涵蓋圖像、視頻、語音、文本等內(nèi)容的分析、檢索、編碼、通信、交互、隱私保護(hù)等眾多主題。
在今天這個多媒體數(shù)據(jù)爆炸式產(chǎn)生的時代,相關(guān)技術(shù)的創(chuàng)新引起了企業(yè)和學(xué)術(shù)界越來越多的關(guān)注,ACM MM 2023 共收到3072篇有效投稿(相比去年激增24%),接收論文902篇。
趨動云的眾多客戶正在從事相關(guān)技術(shù)研究與業(yè)務(wù)創(chuàng)新,本文將帶領(lǐng)大家一覽ACM MM 上的獲獎?wù)撐模?xiàng)目)。
獲獎?wù)撐模?xiàng)目)一覽
最佳論文獎
CATR: Combinatorial-Dependence Audio-Queried Transformer for Audio-Visual Video Segmentation
-
論文鏈接:https://arxiv.org/abs/2309.09709 -
開源地址:https://github.com/aspirinone/CATR.github.io -
作者單位:Zhejiang University;Finvolution Group;
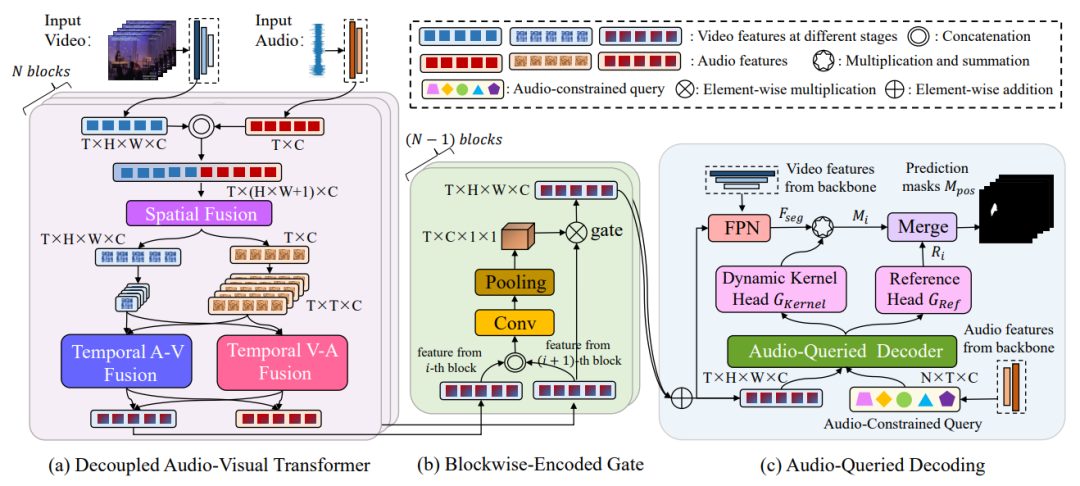
研究領(lǐng)域:最佳論文研究內(nèi)容為Audio-visual video segmentation ,旨在生成圖像內(nèi)產(chǎn)生聲音的對象的像素級掩碼標(biāo)注,不僅如此還要將聲音與發(fā)出聲音的對象關(guān)聯(lián)起來,比如在視頻中識別和分割唱歌的人。
方法創(chuàng)新:提出的方法 CATR 采用編碼器-解碼器結(jié)構(gòu)。
-
在編碼過程中,合并音頻和視頻特征,并捕獲它們的時空依賴關(guān)系。 -
設(shè)計(jì)了一個基于塊的門控方法,以此平衡多個編碼器塊的貢獻(xiàn)。 -
在解碼過程中,引入音頻約束查詢,利用音頻特征來提取對象級信息,引導(dǎo)目標(biāo)對象的分割,確保解碼后的掩碼與聲音保持一致。
結(jié)果:作者使用兩種骨干網(wǎng)絡(luò)在三個數(shù)據(jù)集上的實(shí)驗(yàn)證明該方法性能達(dá)到了 SOTA 。作者稱代碼將開源,期待類似新技術(shù)能催生更多創(chuàng)新應(yīng)用。
榮譽(yù)提名獎
RefineTAD: Learning Proposal-free Refinement for Temporal Action Detection
-
論文鏈接:https://dl.acm.org/doi/pdf/10.1145/3581783.3611872 -
作者單位:Nanjing University of Aeronautics and Astronautics;Nanjing University
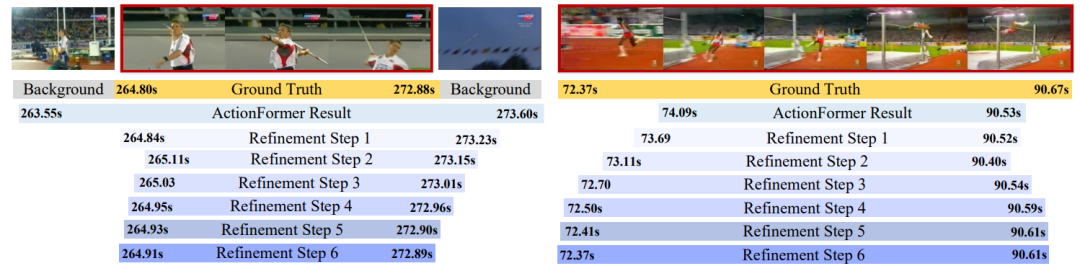
研究領(lǐng)域:時間動作檢測(TAD),旨在定位視頻中動作的起始幀和結(jié)束幀。
方法創(chuàng)新:提出了一種更具普適性和易用性的定位優(yōu)化框架,將定位細(xì)化過程與傳統(tǒng)動作檢測方法進(jìn)行解耦,在每個時間點(diǎn)生成多尺度的定位細(xì)化信息;同時提出一種偏移聚焦策略,以由粗到精的方式逐步增強(qiáng)模型的檢測效果。
結(jié)果:在三個具有挑戰(zhàn)性的數(shù)據(jù)集上進(jìn)行了廣泛的實(shí)驗(yàn),結(jié)果表明 RefineTAD 能在保持較低計(jì)算開銷的情況下顯著提升動作邊界定位的精度。
最佳學(xué)生論文獎
Cal-SFDA: Source-Free Domain-adaptive Semantic Segmentation with Differentiable Expected Calibration Error
-
論文鏈接:https://arxiv.org/abs/2308.03003 -
作者單位:The University of Queensland

研究內(nèi)容:語義分割在圖像視頻理解任務(wù)中具有基礎(chǔ)的作用,這篇論文關(guān)注的是域自適應(yīng)語義分割(domain adaptive semantic segmentation)問題,涉及到將一個域中訓(xùn)練的語義分割模型應(yīng)用到另一個域中,在進(jìn)行域適應(yīng)時不依賴于源域的數(shù)據(jù)。
創(chuàng)新方法:研究者在這個背景下提出了一種 "Cal-SFDA" 框架,借助源端和目標(biāo)端的模型校準(zhǔn),有效地解決了無源域語義分割域適應(yīng)的難題。
結(jié)果:在兩個廣泛使用的合成數(shù)據(jù)到真實(shí)數(shù)據(jù)的語義分割遷移實(shí)驗(yàn)中,該文提出的新方法均取得了顯著的性能提升。
勇敢創(chuàng)新獎
Semantics2Hands: Transferring Hand Motion Semantics between Avatars
-
論文鏈接:https://arxiv.org/abs/2308.05920 -
開源地址:https://github.com/abcyzj/Semantics2Hands -
作者單位:Tsinghua University;Tsinghua University Beijing National Research Center for Information Science and Technology
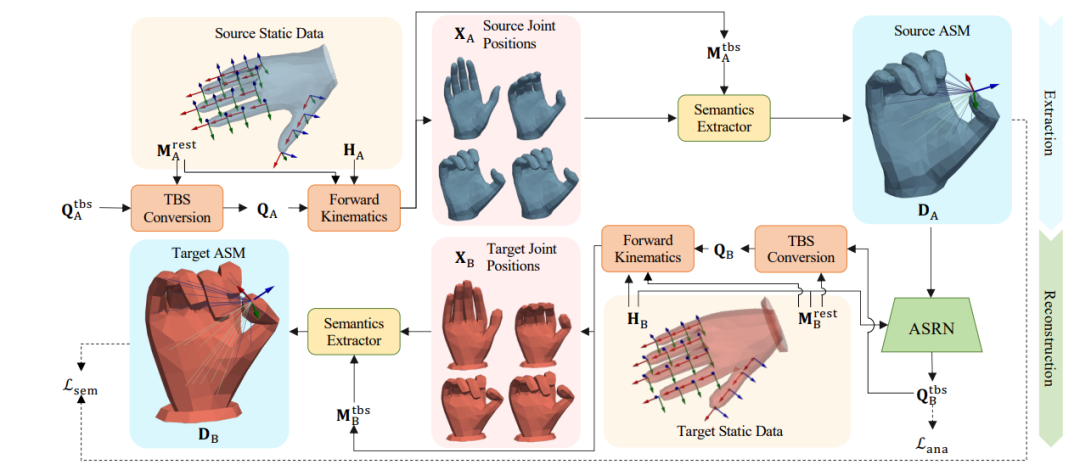
研究內(nèi)容:在動畫制作和人機(jī)交互中,保持虛擬人物的手部動作語義前提下進(jìn)行手部動作遷移。
創(chuàng)新方法:研究者引入了一種新的基于解剖學(xué)的語義矩陣(Anatomy-based Semantic Matrix,ASM),用于編碼手部動作的語義信息。基于此的語義重建網(wǎng)絡(luò)實(shí)現(xiàn)從源ASM到目標(biāo)手部關(guān)節(jié)旋轉(zhuǎn)的映射函數(shù)。作者使用半監(jiān)督學(xué)習(xí)策略來訓(xùn)練該模型。
結(jié)果:在同域和不同域的數(shù)據(jù)實(shí)驗(yàn)中,新方法在維護(hù)手部動作語義的同時,均可以有效地實(shí)現(xiàn)虛擬人物模型之間的手部動作遷移,提高了用戶體驗(yàn)。作者已將代碼開源。
開源獎
Emotion Recognition ToolKit (ERTK): Standardising Tools For Emotion Recognition Research
-
論文鏈接:https://dl.acm.org/doi/pdf/10.1145/3581783.3613459 -
開源地址:https://github.com/Strong-AI-Lab/emotion -
作者單位:University of Auckland
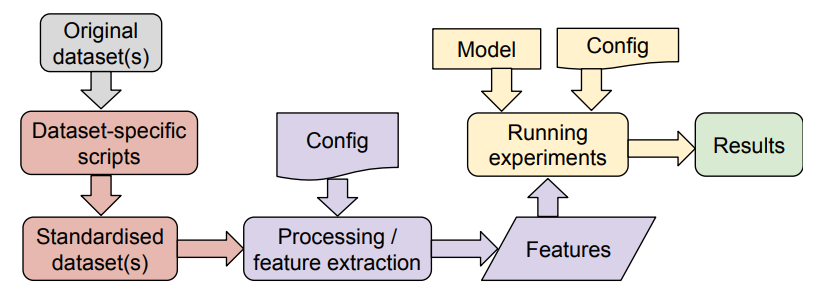
開源獎頒發(fā)給了ERTK,這是一個基于語音數(shù)據(jù),用于情感識別的 Python 庫。其包括完善的數(shù)據(jù)集處理腳本、特征提取器的標(biāo)準(zhǔn)接口以及使用配置文件定義實(shí)驗(yàn)的框架,具有模塊化和可擴(kuò)展性的特點(diǎn)。
開發(fā)者可以很方便使用這個庫進(jìn)行語音情感識別,還可以很方便地將其引入自己的開發(fā)項(xiàng)目或者接入其他平臺。
最佳演示獎
Open-RoadAtlas: Leveraging VLMs for Road Condition Survey with Real-Time Mobile Auditing
-
論文鏈接:https://dl.acm.org/doi/pdf/10.1145/3581783.3612668 -
作者單位:The University of Queensland;
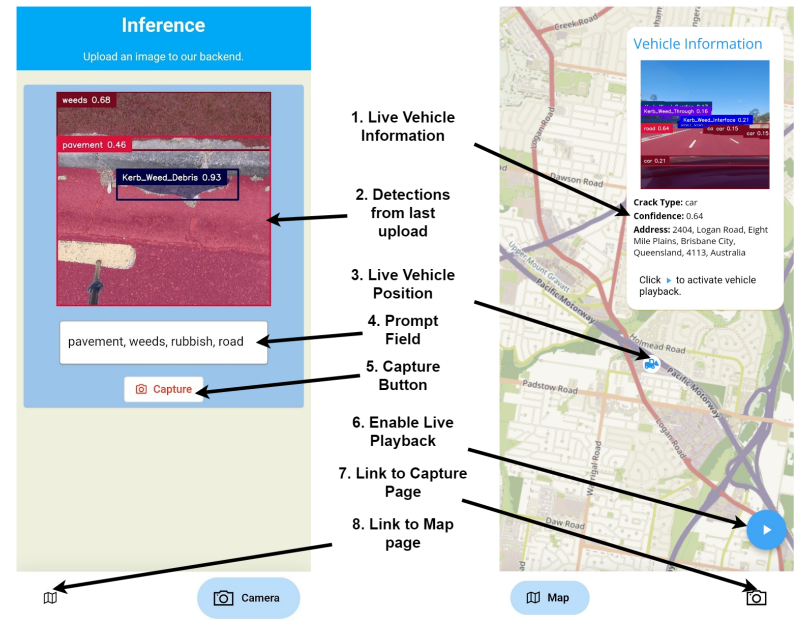
最佳演示獎頒發(fā)給了一個道路檢測管理系統(tǒng)應(yīng)用Open-RoadAtlas,比較有意思的是,它不是一套常規(guī)的僅基于視覺的道路缺陷檢測系統(tǒng),由于結(jié)合了最新的視覺語言模型VLM,還可以通過拒絕VLM識別的興趣區(qū)域之外的預(yù)測來減少假陽性。