
有幸去華為面試數(shù)據(jù)分析崗,看到SQL后我拒絕了
關(guān)注")
◆?◆?◆ ?◆?◆
今年8月,有幸參加了華為的面試,雖然是外包身份,但是大家都知道,大公司對(duì)于外包的面試其實(shí)就是華為內(nèi)部人員來(lái)進(jìn)行。騰訊也是如此!崗位是數(shù)據(jù)分析,記憶最深刻的就是考察了SQL行轉(zhuǎn)列。SQL,無(wú)疑是在數(shù)據(jù)分析面試過(guò)程中的重頭戲。很多人說(shuō),SQL不重要,不能只做提數(shù)機(jī)器;還有人說(shuō),面試不需要準(zhǔn)備SQL,只要你懂方法就足夠了。呵呵一笑置之!如果你真的懂?dāng)?shù)據(jù)分析的方法與思路,還愁找不到工作嗎?還會(huì)整天迷茫?所以沉下心來(lái),好好練習(xí)SQL吧。即使做個(gè)提數(shù)機(jī)器,也要做到提數(shù)又快又準(zhǔn)確,否則和咸魚(yú)有什么區(qū)別?!
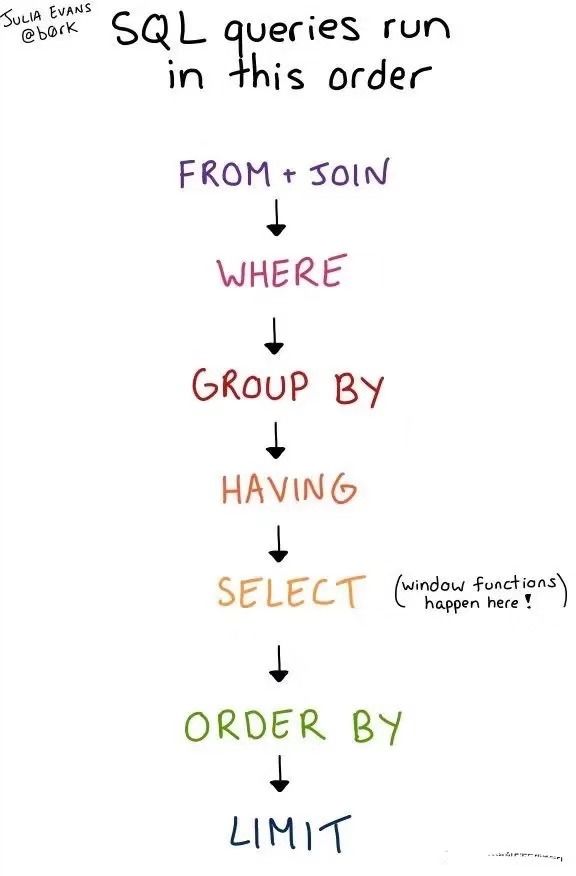
SQL提數(shù),準(zhǔn)確性是第一位的。準(zhǔn)確性如何把握?關(guān)鍵在于你的理解需求能力、邏輯思維能力、執(zhí)行原理掌握的程度。需求理解出錯(cuò),從根上就是不可能提取到需要的數(shù)據(jù)。SQL執(zhí)行原理中,我認(rèn)為一定要把SQL子句的執(zhí)行順序搞清楚。
在日常工作中,或者面試過(guò)程中,常常會(huì)碰到要求用SQL語(yǔ)句實(shí)現(xiàn)行轉(zhuǎn)列。形式如下:
?
select * from test ;
而面試官要求查詢結(jié)果如下展示:
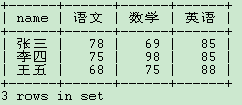
或者這樣:

其實(shí)很簡(jiǎn)單~我們可以使用case when語(yǔ)句進(jìn)行行轉(zhuǎn)列操作。代碼如下:
case 1
select name ,max(case when subject='語(yǔ)文' then score else 0 end) as 語(yǔ)文 ,max(case when subject='數(shù)學(xué)' then score else 0 end) as 數(shù)學(xué) ,max(case when subject='英語(yǔ)' then score else 0 end) as 英語(yǔ)from?test?group?by?name ;
case 2
select name ,sum(case when subject='語(yǔ)文' then score else 0 end) as 語(yǔ)文 ,sum(case when subject='數(shù)學(xué)' then score else 0 end) as 數(shù)學(xué) ,sum(case when subject='英語(yǔ)' then score else 0 end) as 英語(yǔ)from?test?group?by?name ;
以上兩種代碼都可以實(shí)現(xiàn)行轉(zhuǎn)列,細(xì)心的同學(xué)可能會(huì)發(fā)現(xiàn)其實(shí)只有max和sum的區(qū)別。其實(shí),max、sum最主要的用途就是聚合作用——以name分組聚合。為了讓大家更好的理解sum或max的作用,我們先展現(xiàn)一下不加聚合函數(shù)的效果。
select name ,case when subject='語(yǔ)文' then score else 0 end as 語(yǔ)文 ,case when subject='數(shù)學(xué)' then score else 0 end as 數(shù)學(xué) ,case when subject='英語(yǔ)' then score else 0 end as 英語(yǔ)from?test ;

很明顯,我們需要以name進(jìn)行分組聚合,這樣才能得到滿足條件格式的輸出。而用max還是sum進(jìn)行聚合,沒(méi)有任何區(qū)別。
求總分
select name ,max(case when subject='語(yǔ)文' then score else 0 end) as 語(yǔ)文 ,max(case when subject='數(shù)學(xué)' then score else 0 end) as 數(shù)學(xué) ,max(case when subject='英語(yǔ)' then score else 0 end) as 英語(yǔ) ,sum(score) as 總分from?test?group?by?name ;
同時(shí),再給大家介紹一下以窗口函數(shù)進(jìn)行聚合的案例。代碼如下:
select name ,???????max(case?when?subject='語(yǔ)文'?then?score?else?0?end)?over(?partition?by?name )?語(yǔ)文 ,???????max(case?when?subject='數(shù)學(xué)'?then?score?else?0?end)?over( partition?by?name )?數(shù)學(xué) ,???????max(case?when?subject='英語(yǔ)'?then?score?else?0?end)?over( partition?by?name )?英語(yǔ)?from?test ;
同理,上面的聚合函數(shù)max也可以用sum替換,不再贅述!
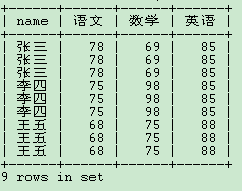
很明顯,結(jié)果需要去重!但是,在實(shí)際的生產(chǎn)過(guò)程中可能不需要去重,而且不是重復(fù)的,這個(gè)謎題留給大家思考!
select?distinct name ,???????sum(case?when?subject='語(yǔ)文'?then?score?else?0?end)?over(?partition?by?name )?語(yǔ)文 ,???????sum(case?when?subject='數(shù)學(xué)'?then?score?else?0?end)?over( partition?by?name )?數(shù)學(xué) ,???????sum(case?when?subject='英語(yǔ)'?then?score?else?0?end)?over( partition?by?name )?英語(yǔ)?from?test ;
通過(guò)上面的比較發(fā)現(xiàn),不同情況使用不同的語(yǔ)句為好。如果你想查詢更多字段,那么窗口函數(shù)不失為一種選擇;如果只需要查詢一個(gè)字段,如name,那么建議大家還是使用groupby為好。在實(shí)際生產(chǎn)中,查詢字段遠(yuǎn)遠(yuǎn)不止一個(gè),一般不會(huì)重復(fù),所以也就不需要去重了。
結(jié)束語(yǔ)
在一面后,我當(dāng)面果斷拒絕了華為負(fù)責(zé)人。沒(méi)有職業(yè)規(guī)劃,只會(huì)越工作越窮。對(duì)于數(shù)據(jù)分析師,SQL最起碼需要掌握兩方面內(nèi)容:查詢+優(yōu)化。查詢,需要多多練習(xí),可以去力扣做題;優(yōu)化,需要一定的經(jīng)驗(yàn),以及對(duì)數(shù)據(jù)庫(kù)原理的充分掌握。轉(zhuǎn)行面試,其實(shí)不容易。如果你沒(méi)有思路,面試時(shí)兩眼一抹黑,請(qǐng)參考(點(diǎn)擊鏈接跳轉(zhuǎn))《轉(zhuǎn)行的你,如何成功面試數(shù)據(jù)分析》。上一次文章中提到了Python做聚類分析,其實(shí)這就是一種分析思路與方法,建議大家好好研究一下(點(diǎn)擊鏈接跳轉(zhuǎn))《鏈接:Python使用RMF聚類分析客戶價(jià)值》。關(guān)注公眾號(hào),回復(fù)“微信”,添加作者微信索要數(shù)據(jù)集,練習(xí)起來(lái)。

<b id="afajh"><abbr id="afajh"></abbr></b>