
車牌識(shí)別綜述閱讀筆記
車牌識(shí)別綜述閱讀筆記
目前車牌識(shí)別所遇到的難點(diǎn)主要體現(xiàn)在三個(gè)方面,主要體現(xiàn)在:車牌傾斜,圖像噪聲,還有車牌模糊。
目前對(duì)車牌識(shí)別的方法大致可以分為三類,模板匹配,SVM,和深度學(xué)習(xí)的方法,其中,深度學(xué)習(xí)的方法用的更加廣泛,深度學(xué)習(xí)上采用車牌識(shí)別的方法可分為直接檢測(cè)算法和間接檢測(cè)算法。對(duì)于車牌識(shí)別,有著不同的數(shù)據(jù)集,我們需要對(duì)不同公共數(shù)據(jù)集進(jìn)行比較和說明,然后對(duì)針對(duì)不同的數(shù)據(jù)集,工作站,精度和時(shí)間進(jìn)行比較,這樣才能全面的衡量算法的優(yōu)勢(shì)和劣勢(shì),然后再對(duì)未來研究方向進(jìn)行展望。
模板匹配:基于matlab+模板匹配的車牌識(shí)別
SVM:畢業(yè)設(shè)計(jì) python opencv實(shí)現(xiàn)車牌識(shí)別 界面
深度學(xué)習(xí)方法基于u-net,cv2以及cnn的中文車牌定位,矯正和端到端識(shí)別軟件
一、車牌識(shí)別技術(shù)的介紹
車牌識(shí)別是一項(xiàng)成熟但不完善的技術(shù),在現(xiàn)階段,車牌識(shí)別已經(jīng)有很多產(chǎn)品出來了,比如說停車場(chǎng)車牌自動(dòng)識(shí)別,這些大多數(shù)都是針對(duì)固定角度,目前針對(duì)復(fù)雜環(huán)境下的車牌識(shí)別,識(shí)別還有待提高,這些復(fù)雜環(huán)境主要是指:燈光條件,扭曲的車牌,還有泥土遮擋的車牌。車牌識(shí)別技術(shù)可以分類三個(gè)部分,車牌定位, 字符分割 ,車牌識(shí)別。由于字符分割在一定程度下會(huì)影響識(shí)別率,最近就有一些人提出免分割的車牌識(shí)別,將車牌識(shí)別分割成兩個(gè)部分,車牌定位,車牌識(shí)別。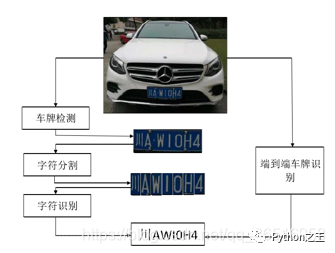
車牌識(shí)別的研究?jī)?nèi)容已經(jīng)從傳統(tǒng)的圖像轉(zhuǎn)向復(fù)雜的環(huán)境。主要的挑戰(zhàn)分為三個(gè)方面
1:有挑戰(zhàn)的數(shù)據(jù)集:比如說像Caltech car 還有English LP 數(shù)據(jù)集,圖像比較簡(jiǎn)單,而像LP和UFPR-ALPR數(shù)據(jù)集,在一些圖片中存在很多輛車,而且車輛位置不一定在圖像的中間。
2:噪聲污染,在現(xiàn)實(shí)生活中,往往會(huì)受到天氣因素的影響,這些成像的圖片的背景不再是間的的停車場(chǎng),而是有可能有一些在斑馬線上面來來往往的行人。
3:模糊圖像:主要是產(chǎn)生在高速公路監(jiān)控上面。由于車輛行駛速度快,所以攝像機(jī)有可能會(huì)拍攝到模糊的圖片,比如說,在15971197的圖片中,車輛可能只有533522,其中截取的圖片可能只有123*96,相當(dāng)于只占到了圖片中的0.2%,在這樣一個(gè)小尺寸的圖片上檢測(cè)會(huì)有一定的難度。
基于深度學(xué)習(xí)的車牌定位可分為直接定位和間接定位,直接定位把車牌識(shí)別當(dāng)成一個(gè)目標(biāo)檢測(cè)模型,比如像SSD還有YOLO等等,只需要改變最后一層的卷積層就可以了,把它定成所需要識(shí)別的類別。基于一個(gè)車輛只有一個(gè)車牌的情形,間接定位首先定位到車牌的相關(guān)物體,然后再定位到車牌。定位到車牌之后,就需要對(duì)車牌進(jìn)行字符分割,基于字符分割的方法有連接成分分析,投影分析,字符先驗(yàn)知識(shí),字符輪廓等等 。在沒有得到高精度分類器下面的分割結(jié)果,是很難得到準(zhǔn)確的字符分類的,
二、車牌識(shí)別的難點(diǎn)
1.傾斜車牌(傾斜矯正)
車牌傾斜所帶來的挑戰(zhàn),車牌傾斜分為垂直傾斜和水平傾斜,這些傾斜會(huì)導(dǎo)致字符變形,從而影響識(shí)別率,如果可以將物體的姿態(tài)和部分變形從紋理和形狀中解脫出來,會(huì)有利于后面的預(yù)測(cè),比如說車牌的矯正可以看作是仿射變換的過程。那么,如何找到這個(gè)變換矩陣也是一個(gè)難點(diǎn)所在。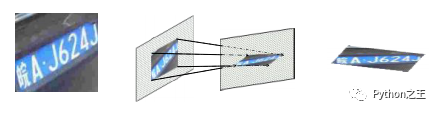
J提出了一種STN計(jì)算仿射變換矩陣。由于一個(gè)圖像只需要6個(gè)參數(shù)矩陣就可以變換成任意的圖像,比如旋轉(zhuǎn),縮小,放大等等,具體可以參考博客:STN:空間變換網(wǎng)絡(luò)(Spatial Transformer Network)
2.圖像噪聲(圖像去噪)
在自然環(huán)境下面,采集到的圖片往往有很多噪聲,下表是一些文獻(xiàn)對(duì)噪聲的處理方法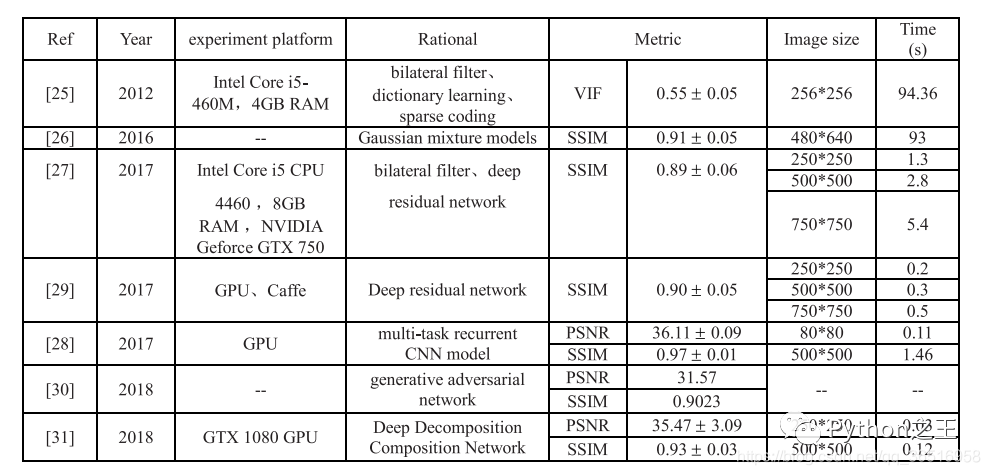
其中[25]和[26]因?yàn)椴粷M足實(shí)時(shí)性要求,所以不可取,在表格中,SSIM為結(jié)構(gòu)相似度指標(biāo),VIF為視覺信息保真度,PSNR為峰值信噪比。SSIM越高,說明去噪算法在圖像結(jié)構(gòu)上的效果越接近真實(shí)的標(biāo)簽值。VIF和SSIM的取值范圍均為[0,1]。數(shù)值越大,越接近干凈的圖像。
[27]Fu等人使用了名為DerainNet的深層網(wǎng)絡(luò)架構(gòu)來從單一圖像中去除雨痕。
X. Fu, J. Huang, X. Ding, Y. Liao, and J. Paisley, ‘‘Clearing the skies: A deep network architecture for single-image rain removal,’’ IEEE Trans. Image Process., vol. 26, no. 6, pp. 2944–2956, Jun. 2017
[28] Yang等人提出了一種利用深度聯(lián)合雨點(diǎn)檢測(cè)和去除單一圖像的方法。
W. Yang, R. T. Tan, J. Feng, J. Liu, Z. Guo, and S. Yan, ‘‘Deep joint rain detection and removal from a single image,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 1685–1694.
[29] X. Fu, J. Huang, D. Zeng, Y. Huang, X. Ding, and J. Paisley, ‘‘Removing rain from single images via a deep detail network,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 1715–1723.
[30] R. Qian, R. T. Tan, W. Yang, J. Su, and J. Liu, ‘‘Attentive generative adversarial network for raindrop removal from a single image,’’ in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 2482–2491.
[31] S. Li, W. Ren, J. Zhang, J. Yu, and X. Guo, ‘‘Fast single image rain removal via a deep omposition-composition network,’’ 2018, arXiv:1804.02688. [Online]. Available: https://arxiv.org/abs/1804.02688dec
3.模糊車牌(提高分辨率)
在目標(biāo)檢測(cè)領(lǐng)域,小目標(biāo)的車牌識(shí)別是很難的,由于車牌在整幅圖片中占比很小,所以很容易出現(xiàn)低分辨率和噪聲,給我們的檢測(cè)帶來了一些困難。通過插值直接上采樣可以作為低分辨率識(shí)別的一種可能的解決方案,但這對(duì)后續(xù)的字符識(shí)別是不利的,或者通過學(xué)習(xí)小目標(biāo)在多個(gè)尺度上的表示來檢測(cè)小目標(biāo)是很耗時(shí)的。因此,有必要尋找一種有效提高小目標(biāo)車牌分辨率的方法。
Li等人使用[32]感知GAN進(jìn)行內(nèi)部提升,從小物體到“超分辨”物體的表現(xiàn),實(shí)現(xiàn)與大型物體相似的特征更具鑒別性的檢測(cè),由于GANS訓(xùn)練很困難、Tolstikhin等人[33]研究了cascade的使用生成模型來解決模型缺失的訓(xùn)練問題。Radford等人[34]和Salimans等人[35]的目的是使計(jì)數(shù)器生成網(wǎng)絡(luò)更穩(wěn)定、更容易微調(diào)。Singh等人[36]提出了一種名為DirectCapsNet的雙定向膠囊網(wǎng)絡(luò),用于識(shí)別非常低分辨率的圖像。其中文獻(xiàn)[47]在限速90km/h的道路上拍攝數(shù)據(jù)集,利用盲反卷積算法反求模糊圖像的清晰圖像,字符錯(cuò)誤率從23%降低到9%,提高了2.5倍。處理時(shí)間約0.5秒,在實(shí)時(shí)性上有一定差距。生成對(duì)抗網(wǎng)絡(luò)也可以提高小目標(biāo)識(shí)別的準(zhǔn)確性,但由于網(wǎng)絡(luò)的復(fù)雜性,訓(xùn)練起來比較困難,因此如何結(jié)合生成對(duì)抗網(wǎng)絡(luò)進(jìn)行端到端識(shí)別還需要進(jìn)一步研究
[32] J. Li, X. Liang, Y. Wei, T. Xu, J. Feng, and S. Yan, ‘‘Perceptual generative adversarial networks for small object detection,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 1951–1959.
[33] I. O. Tolstikhin, S. Gelly, O. Bousquet, C.-J. Simon-Gabriel, and B. Sch?lkopf, ‘‘AdaGAN: Boosting generative models,’’ in Proc. Adv. Neural Inf. Process. Syst., 2017, pp. 5424–5433. [34] A. Radford, L. Metz, and S. Chintala, ‘‘Unsupervised representation learning with deep convolutional generative adversarial networks,’’ 2016, arXiv:1511.06434v2. [Online]. Available: https://arxiv. org/abs/1511.06434
[35] T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford, X. Chen, and X. Chen, ‘‘Improved techniques for training GANs,’’ Proc. Adv. Neural Inf. Process. Syst., 2016, pp. 2234–2242.
[36]M. Singh, S. Nagpal, R. Singh, and M. Vatsa, ‘‘Dual directed capsule network for very low resolution image recognition,’’ in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2019, pp. 340–349.
[47]P. Svoboda, M. Hradis, L. Marsik, and P. Zemcik, ‘‘CNN for license plate motion deblurring,’’ in Proc. IEEE Int. Conf. Image Process. (ICIP), Sep. 2016, pp. 3832–3836
三、車牌定位
車牌定位就是提取輸入圖片的一部分區(qū)域。這部分區(qū)域的內(nèi)容是漢字+字母+數(shù)字,傳統(tǒng)的車牌定位算法根據(jù)直觀的特征可以分為四類:基于文本的檢測(cè)、基于顏色的檢測(cè)、基于字符的檢測(cè)和連接分量的檢測(cè)。這些直觀的特征容易受到環(huán)境的影響,而深度學(xué)習(xí)可以通過像素信息提取出更深層的特征。定位算法分為直接定位和間接定位兩種。直接定位指的是回歸網(wǎng)絡(luò)直接預(yù)測(cè)車牌的坐標(biāo),以及長(zhǎng)度和寬度,而間接定位指間接獲取車牌的信息通過其他指標(biāo),很容易找到車輛,例如,檢測(cè)汽車或汽車的尾燈首先然后計(jì)算板坐標(biāo)。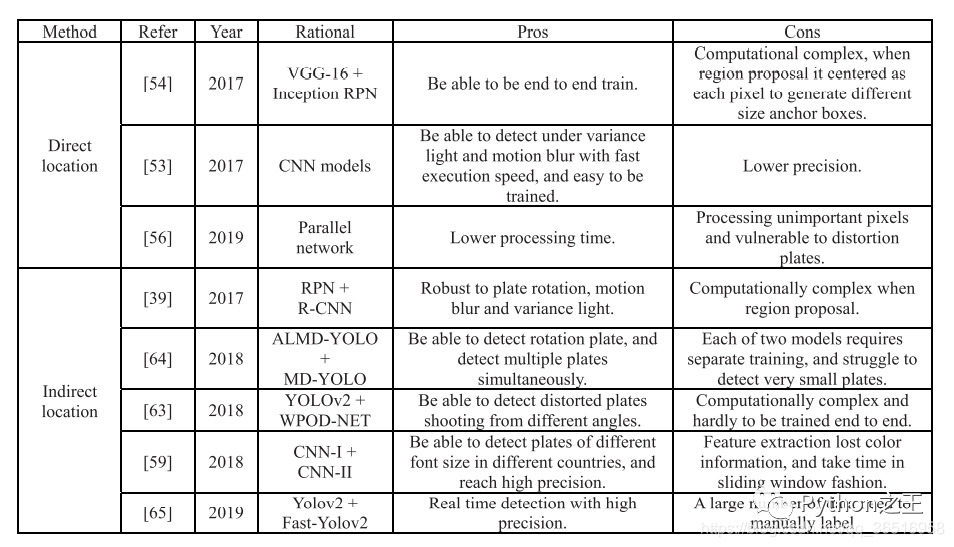
1)直接檢測(cè)
直接檢測(cè)車牌就是輸入一張圖片直接得到車牌圖片的高寬和位置信息。訓(xùn)練的時(shí)候,采用歐氏距離等損失函數(shù)計(jì)算參數(shù)梯度,直接檢測(cè)可以節(jié)約時(shí)間成本,但不如間接檢測(cè)準(zhǔn)確。
Kurpiel等[53]將輸入圖像分割成120像素寬180像素高的子區(qū)域,形成重疊的網(wǎng)格。然后將每個(gè)子區(qū)域發(fā)送給9層的CNN,得到一個(gè)置信值,輸出值為[0,1]。車牌中心越向外移動(dòng),得分越低,由1降為0。最后,結(jié)合所有圖像子區(qū)域的輸出值來估計(jì)車牌的位置,使車牌中心更接近得分最高的左或右子區(qū)域。其檢測(cè)準(zhǔn)確率達(dá)到0.87,召回率為0.83,處理時(shí)間為0.23秒。
Li等人[54]提出了一種端到端訓(xùn)練的統(tǒng)一深度神經(jīng)網(wǎng)絡(luò)(網(wǎng)絡(luò)結(jié)構(gòu)和Faster RCNN相似),用于同時(shí)定位和識(shí)別車牌。在定位到車牌后,使用RNNs+CTC進(jìn)行免分割的車牌識(shí)別。
Xiang等人[56]提出了一種用于復(fù)雜場(chǎng)景車牌檢測(cè)的高效輕量化全卷積網(wǎng)絡(luò), 這個(gè)網(wǎng)絡(luò)由兩個(gè)平行的分支組成。前景分支將圖像采樣到原圖像的1/8,背景分支的主要部分用密集塊[57]構(gòu)建,每個(gè)塊包含一系列相連的卷積層。采用帶stride 2的3 3卷積,而不是在每個(gè)塊中對(duì)子樣本特征映射進(jìn)行池化處理,在不影響精度的前提下降低了計(jì)算成本.
[53] F. Delmar Kurpiel, R. Minetto, and B. T. Nassu, ‘‘Convolutional neural networks for license plate detection in images,’’ in Proc. IEEE Int. Conf. Image Process. (ICIP), Sep. 2017, pp. 3395–3399.
[54] H. Li, P. Wang, and C. Shen, ‘‘Towards End-to-End car license plates detection and recognition with deep neural networks,’’ 2017, arXiv:1709.08828. [Online]. Available: http://arxiv.org/abs/1709.08828
[56] H. Xiang, Y. Zhao, Y. Yuan, G. Zhang, and X. Hu, ‘‘Lightweight fully convolutional network for license plate detection,’’ Optik, vol. 178, pp. 1185–1194, Feb. 2019.
[57] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, ‘‘Densely connected convolutional networks,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 2261–2269
2)間接定位
在大多數(shù)情況下,直接定位算法的精度低于間接定位算法,而且,大多數(shù)文獻(xiàn)使用YOLO等版本進(jìn)行車牌檢測(cè),間接檢測(cè)算法由兩種不同的網(wǎng)絡(luò)組成,可以接受一定程度的光變化、畸變和模糊。
一些研究者利用車牌與車體之間的先驗(yàn)知識(shí),如后燈與車牌[58]的位置關(guān)系,將問題轉(zhuǎn)化為更容易檢測(cè)的目標(biāo)。Li等人[59]采用級(jí)聯(lián)框架讀取車牌,首先檢測(cè)字符區(qū)域,然后提取車牌圖片。該檢測(cè)模型的準(zhǔn)確率達(dá)到97%左右,召回率達(dá)到95%以上。Dong等人[39]使用由快速區(qū)域建議網(wǎng)絡(luò)和R-CNN網(wǎng)絡(luò)組成的級(jí)聯(lián)結(jié)構(gòu)提取車牌,首先,一個(gè)輕量級(jí)的RPN網(wǎng)絡(luò)[17]以下采樣圖像作為輸入,生成候選車牌。然后,采樣器從原始高分辨率圖像中提取感興趣區(qū)域(region of interest, roi)。提取的小塊輸入R-CNN網(wǎng)絡(luò)對(duì)候選車牌進(jìn)行分類,回歸車牌的四角。該車牌檢測(cè)器比faster R-CNN速度快1.5倍,體積小57倍,準(zhǔn)確率達(dá)到96%以上。Silva等人[62]使用YOLOv2網(wǎng)絡(luò)檢測(cè)車輛,不做任何修改和細(xì)化,只是將網(wǎng)絡(luò)作為一個(gè)黑盒,在PASCAL-VOC數(shù)據(jù)集上合并cars和buses這兩類,忽略其他類。根據(jù)YOLO、SSD和STN的見解,WPOD-NET被提出用于檢測(cè)各種不同扭曲的車牌,并回歸仿射變換的系數(shù),將扭曲的車牌解扭曲為類似正面視圖的矩形。Xie等[63]受到Y(jié)OLO框架的啟發(fā),提出了一種基于cnn的MDYOLO方法來實(shí)現(xiàn)多向車牌檢測(cè)。與YOLO類似,每個(gè)輸入圖像被劃分為規(guī)則的7 7個(gè)網(wǎng)格單元,使用車牌中心所在的單元檢測(cè)車牌,并預(yù)測(cè)每個(gè)單元的2個(gè)邊框和一個(gè)置信度分?jǐn)?shù)。與YOLO不同的是,MD-YOLO引入角度信息,引導(dǎo)模型回歸并確定給定車牌圖像的旋轉(zhuǎn)角度。提出了角偏差懲罰因子(ADPF)來近似預(yù)測(cè)值與標(biāo)簽值的交點(diǎn)比例。為了識(shí)別負(fù)旋轉(zhuǎn)角值,激活函數(shù)選擇了泄漏函數(shù)和恒等函數(shù),而不是ReLU函數(shù)。考慮到車牌通常很小,在實(shí)施MDYOLO之前,我們使用了一個(gè)前置CNN注意模型ALMDYOLO。該檢測(cè)模型在GPU GTX980上的處理時(shí)間為5ms,準(zhǔn)確率達(dá)到99%以上。Laroca等人[64]通過評(píng)估和優(yōu)化不同的Yolo模型,并進(jìn)行各種修改,實(shí)現(xiàn)了該系統(tǒng),旨在在每個(gè)階段實(shí)現(xiàn)最佳的速度/精度權(quán)衡。車牌檢測(cè)階段,考慮到車牌可能只占很小的部分圖片,和其他文本塊像交通標(biāo)志可能會(huì)混淆牌照,相同的檢測(cè)過程采用[62],首次檢測(cè)到的車輛,然后檢測(cè)牌照。該系統(tǒng)在8個(gè)不同的數(shù)據(jù)集上平均查準(zhǔn)率為98.37%,平均查全率為99.92%
[58]M. R. Asif, Q. Chun, S. Hussain, M. S. Fareed, and S. Khan, ‘‘Multinational vehicle license plate detection in complex backgrounds,’’ J. Vis. Commun. Image Represent., vol. 46, pp. 176–186, Jul. 2017
[59]H. Li, P. Wang, M. You, and C. Shen, ‘‘Reading car license plates using deep neural networks,’’ Image Vis. Comput., vol. 72, pp. 14–23, Apr. 2018.
[39] M. Dong, D. He, C. Luo, D. Liu, and W. Zeng, ‘‘A CNN-based approach for automatic license plate recognition in the wild,’’ in Proc. Brit. Mach. Vis. Conf., 2017, pp. 1–12
[62]S. M. Silva and C. R. Jung, ‘‘License plate detection and recognition in
unconstrained scenarios,’’ in Proc. Eur. Conf. Comput. Vis., Sep. 2018,
pp. 593–609.
[63] L. Xie, T. Ahmad, L. Jin, Y. Liu, and S. Zhang, ‘‘A new CNN-based method for multi-directional car license plate detection,’’ IEEE Trans. Intell. Transp. Syst., vol. 19, no. 2, pp. 507–517, Feb. 2018.
[64] R. Laroca, L. A. Zanlorensi, G. R. Gon?alves, E. Todt, W. R. Schwartz, and D. Menotti, ‘‘An efficient and layout-independent automatic license plate recognition system based on the YOLO detector,’’ 2019, arXiv:1909.01754. [Online]. Available: https://arxiv.org/abs/1909.01754
四、車牌識(shí)別
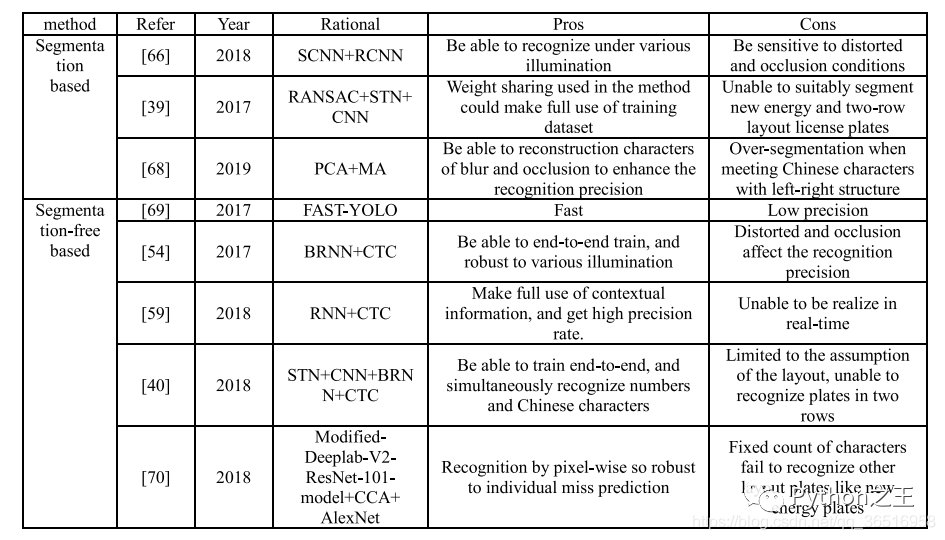
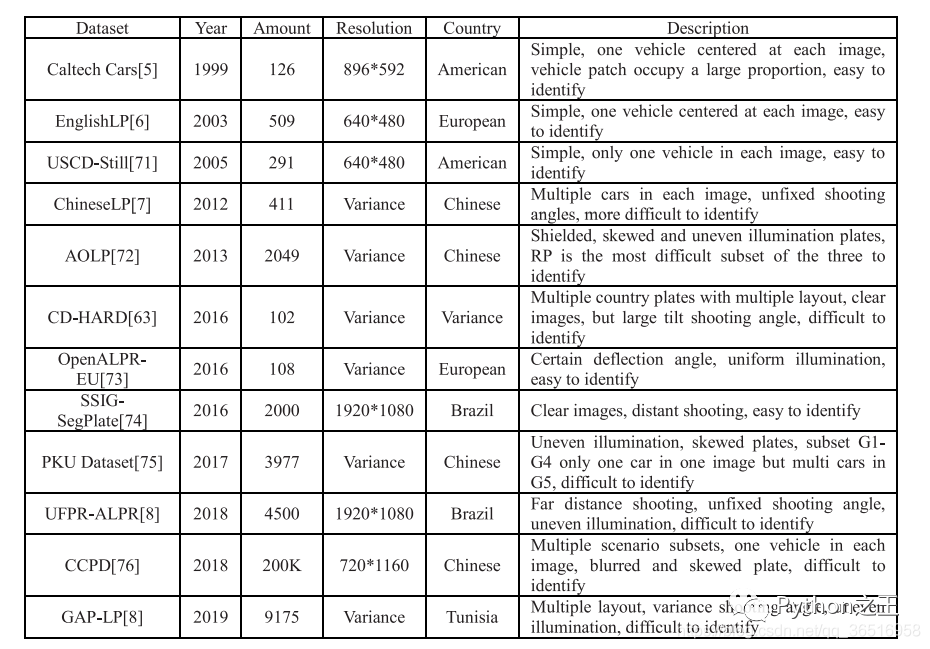
這張表比較了現(xiàn)有公共車牌數(shù)據(jù)集的數(shù)量和分辨率,并描述了遮擋和模糊等其他情況。其中,CD-HARD是從汽車數(shù)據(jù)集中挑選出來的具有挑戰(zhàn)性的圖像。此外,常見的目標(biāo)檢測(cè)數(shù)據(jù)集如PASAL-VOC、ImageNet和COCO也包含了一些車輛類,但由于這些數(shù)據(jù)集不是專用的車牌數(shù)據(jù)集,所以在表中沒有進(jìn)行比較。像SSIG這樣的數(shù)據(jù)集,大量使用了車輛的前視圖,沒有大角度偏轉(zhuǎn)的居中圖像,在大多數(shù)算法中都可以達(dá)到較高的精度。但是AOLP等數(shù)據(jù)集包含大量的車牌圖像,如光照不均勻、傾斜等,會(huì)增加識(shí)別的難度。
1)基于分割的車牌識(shí)別
首先來說,分割的方法有:連接成分分析,投影分析,字符的先驗(yàn)知識(shí),字符輪廓及其組合。
Liu等[65]采用連通成分分析與項(xiàng)目分析相結(jié)合的方法進(jìn)行分割。設(shè)計(jì)了兩種簡(jiǎn)單、循環(huán)的cnn用于字符識(shí)別,分別是SCNN和RCNN,一種用于漢字識(shí)別,另一種用于數(shù)字和字母識(shí)別。在2189幅圖像中,分割率為96.58%,識(shí)別率為98.09%。
Dong等人[39]提出了一種由并行空間變換網(wǎng)絡(luò)和共享權(quán)重識(shí)別器組成的創(chuàng)新結(jié)構(gòu)。將校正后的車牌輸入7個(gè)并行的無監(jiān)督STNs[24]中,每個(gè)STNs都進(jìn)行隱式字符分割。最后,由7個(gè)識(shí)別器分別對(duì)每個(gè)片段進(jìn)行識(shí)別,第一個(gè)識(shí)別器分別對(duì)漢字進(jìn)行訓(xùn)練,其余6個(gè)識(shí)別器共享權(quán)重。對(duì)于權(quán)值共享識(shí)別器,將其先驗(yàn)概率與識(shí)別子網(wǎng)絡(luò)估計(jì)的似然概率相乘得到得分,其中第二個(gè)字符的阿拉伯?dāng)?shù)字?jǐn)?shù)字的先驗(yàn)概率為0。最終模型的識(shí)別準(zhǔn)確率為89.05%。
kare等人[66]提出了一個(gè)新的概念,稱為部分字符重構(gòu),摘要針對(duì)主成分分析(PCA)和長(zhǎng)軸分析(MA)可以在沒有完整字符形狀的情況下估計(jì)字符成分方向的問題,提出了一種基于角度信息的字符分割方法,如果PCA和MA給出的角度幾乎相同并且都接近90度,則該分量被認(rèn)為是一個(gè)完整的特征。如果兩個(gè)軸之間的差值超過26度,并且給出的值幾乎為0,那么該組件就被認(rèn)為是分割不足。否則,該組成部分被認(rèn)為是一個(gè)過度細(xì)分的情況。對(duì)于分割不足或過分割的字符,使用了迭代收縮或迭代擴(kuò)展算法,該模型的分割率為82.6%,識(shí)別精度為87.3%。
[65]Y. Liu, H. Huang, J. Cao, and T. Huang, ‘‘Convolutional neural networksbased intelligent recognition of chinese license plates,’’ Soft Comput., vol. 22, no. 7, pp. 2403–2419, Apr. 2018.
[39]M. Dong, D. He, C. Luo, D. Liu, and W. Zeng, ‘‘A CNN-based approach for automatic license plate recognition in the wild,’’ in Proc. Brit. Mach. Vis. Conf., 2017, pp. 1–12.
[66] V. Khare, P. Shivakumara, C. S. Chan, T. Lu, L. K. Meng, H. H. Woon, and M. Blumenstein, ‘‘A novel character segmentation-reconstruction approach for license plate recognition,’’ Expert Syst. Appl., vol. 131, pp. 219–239, Oct. 2019
2)基于無分割的車牌識(shí)別
基于無分割的算法將車牌識(shí)別問題轉(zhuǎn)化為字符序列標(biāo)記問題,現(xiàn)階段,無分割的車牌識(shí)別主要是通過RNN+CTC來進(jìn)行實(shí)現(xiàn)。
Li等人[54]使用帶有CTC損耗的雙向RNNs (BRNN)來標(biāo)記序列特征,在AOLP數(shù)據(jù)集上,平均識(shí)別率為91.83%,執(zhí)行速度為400ms。
莊等[68]轉(zhuǎn)移了YOLO-VOC網(wǎng)絡(luò)進(jìn)行車牌分割和字符識(shí)別,由于巴西車牌的特點(diǎn),前3個(gè)字符是字母,后4個(gè)字符是數(shù)字,因此所有檢測(cè)到的字符都由兩個(gè)啟發(fā)式規(guī)則過濾,該模型能夠正確分割99%的字符,識(shí)別率為93%,在GPU上的執(zhí)行時(shí)間僅為2.2ms。
Li等[59]在[54]文獻(xiàn)的基礎(chǔ)上,利用LSTM對(duì)遞歸神經(jīng)網(wǎng)絡(luò)(RNNs)進(jìn)行訓(xùn)練,通過CNNs對(duì)整個(gè)車牌提取的序列特征進(jìn)行識(shí)別。每個(gè)檢測(cè)到的車牌都被轉(zhuǎn)換為灰度圖像,并調(diào)整到2494像素。一個(gè)24個(gè)24像素的子窗口,步長(zhǎng)為1,以滑動(dòng)窗口的方式分割填充圖像。每個(gè)分割后的圖像patch被送入36類CNN分類器中提取序列特征。將第四卷積層與第一全連通層連接成一個(gè)長(zhǎng)度為5096的特征向量。然后利用主成分分析將特征維數(shù)降至256維,進(jìn)行特征歸一化處理。最后,設(shè)計(jì)CTC將預(yù)測(cè)的概率序列直接解碼為輸出標(biāo)簽,平均識(shí)別率約為92.47%。
Wang等[40]使用BRNN和CTC進(jìn)行車牌識(shí)別,識(shí)別率為96.62%處理時(shí)間為17.53毫秒。首先,利用空間變壓器網(wǎng)絡(luò)(STN)對(duì)斜度和變形的車牌進(jìn)行調(diào)整,車牌上有將統(tǒng)一的方向信息輸入到改進(jìn)的卷積神經(jīng)網(wǎng)絡(luò)(CNN)中提取序列特征,然后得到修正后的車牌,將這些不同卷積層的特征作為輸入集成到BRNN中,最后用CTC實(shí)現(xiàn)序列標(biāo)記。
Silva等人[69]提出了一種新的車牌識(shí)別系統(tǒng),包括語(yǔ)義分割和字符計(jì)數(shù),對(duì)輸入圖像進(jìn)行簡(jiǎn)單投影預(yù)處理,使圖像適合于語(yǔ)義分割
[54] H. Li, P. Wang, and C. Shen, ‘‘Towards End-to-End car license plates detection and recognition with deep neural networks,’’ 2017, arXiv:1709.08828. [Online]. Available: http://arxiv.org/abs/1709.08828
[68] J. Zhuang, S. Hou, Z. Wang, and Z.-J. Zha, ‘‘Towards human-level license plate recognition,’’ in Proc. Eur. Conf. Comput. Vis., Sep. 2018, pp. 314–329
[59] H. Li, P. Wang, M. You, and C. Shen, ‘‘Reading car license plates using deep neural networks,’’ Image Vis. Comput., vol. 72, pp. 14–23, Apr. 2018
[40] J. Wang, H. Huang, X. Qian, J. Cao, and Y. Dai, ‘‘Sequence recognition of chinese license plates,’’ Neurocomputing, vol. 317, pp. 149–158, Nov. 2018
[69] S. Montazzolli and C. Jung, ‘‘Real-time brazilian license plate detection and recognition using deep convolutional neural networks,’’ in Proc. 30th SIBGRAPI Conf. Graph., Patterns Images (SIBGRAPI), Oct. 2017, pp. 55–62.
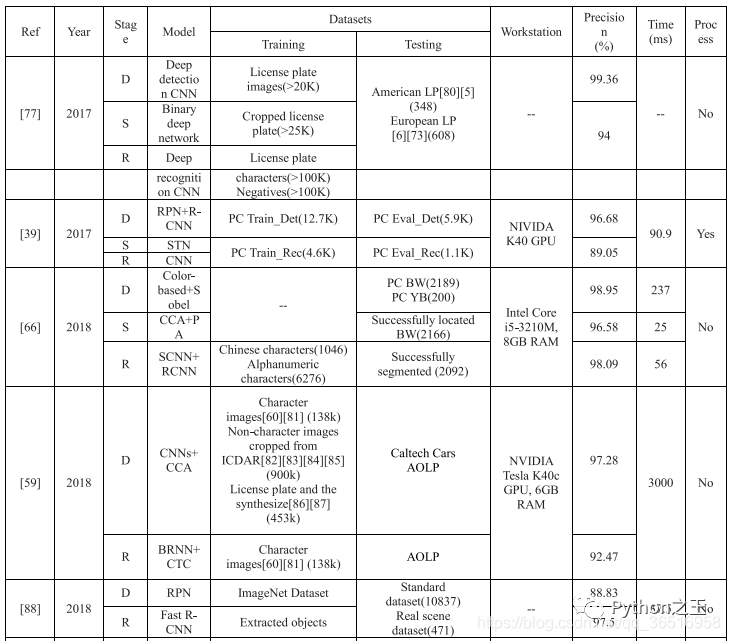
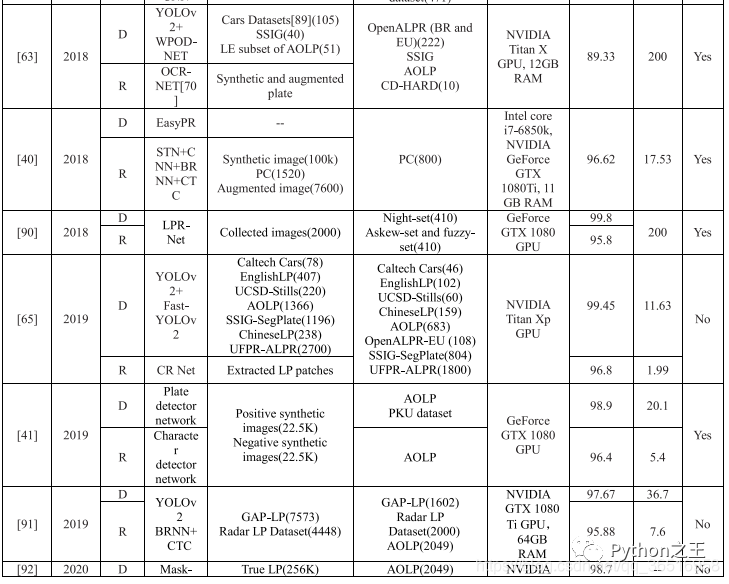
在表中,BW表示藍(lán)色背景的白色字符車牌,YB表示黃色背景的黑色字符車牌。
在階段列表中,D表示檢測(cè),S表示分割,R表示識(shí)別。在表中,也列出了各階段的數(shù)據(jù)集、精度和處理時(shí)間。使用的圖像數(shù)量列在數(shù)據(jù)集末尾的括號(hào)中,最后的處理是是否使用車牌校正、去噪、分辨率增強(qiáng)來提高識(shí)別精度。其中,只有LPR-Net[88]是統(tǒng)一的端到端模型,對(duì)于其他的算法,有6種算法采用了特殊的處理方法,大部分算法對(duì)車牌進(jìn)行了校正,其中一種算法對(duì)圖像進(jìn)行去噪處理。與漢字和阿拉伯語(yǔ)相比,數(shù)字和字母有著更復(fù)雜的結(jié)構(gòu),他們更敏感,在現(xiàn)實(shí)場(chǎng)景中各種因素的影響,這些扭曲的變態(tài)和模糊字符也更難被肉眼識(shí)別的,所以調(diào)整和復(fù)原是需要的。
五、總結(jié)
從表6的數(shù)據(jù)可以看出,目前最先進(jìn)的識(shí)別算法是[64]提出的基于YOLO的改進(jìn)模型,對(duì)于多個(gè)國(guó)家的多個(gè)場(chǎng)景,識(shí)別準(zhǔn)確率達(dá)到96.8%,而處理每幅圖像只需要13.62ms。在今后車牌識(shí)別的研究工作中,可以從一下三個(gè)方面進(jìn)行提升:
未來的算法可以結(jié)合圖像去模糊和車牌校正或提高小目標(biāo)的分辨率
客觀評(píng)價(jià),使用多套數(shù)據(jù)集進(jìn)行算法測(cè)試,比如說,如第五張表所示,Caltech Cars只有126張,USCDStill只有291張,UFPR-ALPR最多為4500張。然而,太少的數(shù)據(jù)集不利于深度學(xué)習(xí)訓(xùn)練和測(cè)試評(píng)估。我們應(yīng)該尋找一些像CCPD這樣的數(shù)據(jù)集,里面包含了20萬張圖片。
現(xiàn)有的系統(tǒng)大多采用2 - 3個(gè)模型進(jìn)行訓(xùn)練,即訓(xùn)練前需要收集相應(yīng)的數(shù)據(jù)集并進(jìn)行標(biāo)記,測(cè)試前需要下載相應(yīng)模型的矩陣參數(shù),這無疑會(huì)給系統(tǒng)部署帶來一定的人工成本和計(jì)算機(jī)存儲(chǔ)成本。因此,迫切需要找到一個(gè)可以用統(tǒng)一模型進(jìn)行端到端訓(xùn)練和測(cè)試的系統(tǒng)。
最后,在車牌識(shí)別方面,應(yīng)該集中在解決復(fù)雜場(chǎng)景的三個(gè)方面,即車牌校正、去噪和高分辨率的表征,以及多元化的評(píng)價(jià)體系和建設(shè)一個(gè)統(tǒng)一的端到端訓(xùn)練和測(cè)試的模型。
本文來源
《Research on License Plate Recognition Algorithms Based on Deep Learning in Complex Environment》
下載地址
https://ieeexplore.ieee.org/document/9092977


Python“寶藏級(jí)”公眾號(hào)【Python之王】專注于Python領(lǐng)域,會(huì)爬蟲,數(shù)分,C++,tensorflow和Pytorch等等。
近 2年共原創(chuàng) 100+ 篇技術(shù)文章。創(chuàng)作的精品文章系列有:
日常收集整理了一批不錯(cuò)的?Python?學(xué)習(xí)資料,有需要的小伙可以自行免費(fèi)領(lǐng)取。
獲取方式如下:公眾號(hào)回復(fù)資料。領(lǐng)取Python等系列筆記,項(xiàng)目,書籍,直接套上模板就可以用了。資料包含算法、python、算法小抄、力扣刷題手冊(cè)和 C++ 等學(xué)習(xí)資料!