
如何排查系統(tǒng)的性能瓶頸點(diǎn)?

作者 |?朱小廝的博客
梳理系統(tǒng)的性能瓶頸點(diǎn)這件事應(yīng)該不是一件簡(jiǎn)單的事情,需要針對(duì)不同設(shè)計(jì)的系統(tǒng)來(lái)進(jìn)行單獨(dú)分析。
首先一套完整可用的系統(tǒng)應(yīng)該是有ui界面的(這里強(qiáng)調(diào)的是一套完整的,可用的系統(tǒng),而并不是指單獨(dú)的一個(gè)中臺(tái)系統(tǒng)),系統(tǒng)分為了前端模塊和后端模塊。
這里由于我個(gè)人的擅長(zhǎng)領(lǐng)域更多是處于后端模塊,所以對(duì)于系統(tǒng)的瓶頸點(diǎn)梳理我會(huì)從后端進(jìn)行分析。
這里我結(jié)合常用的nginx+tomcat+redis+mysql這類常見(jiàn)架構(gòu)進(jìn)行分析:
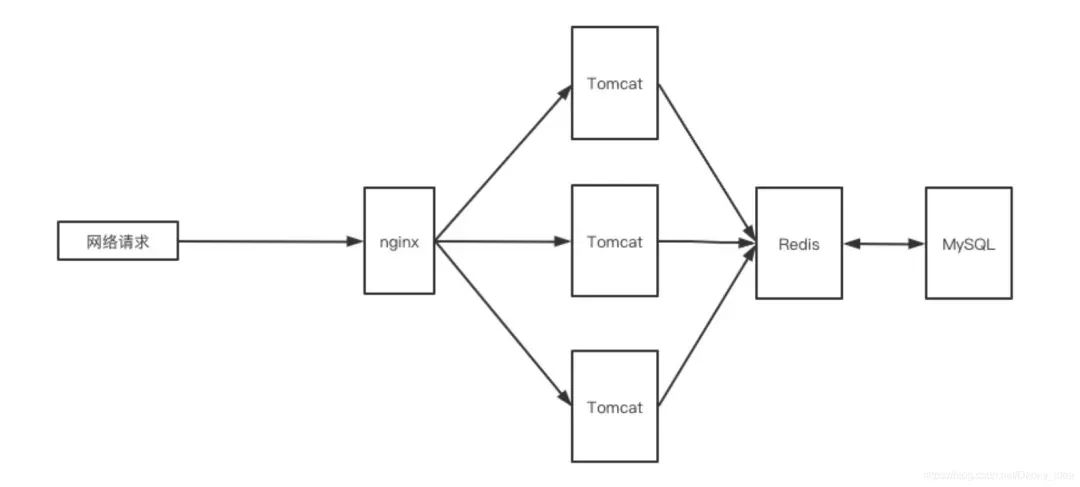
請(qǐng)求入口 所有的請(qǐng)求打入到后臺(tái)的服務(wù)當(dāng)中,首先需要考慮的一個(gè)點(diǎn)就是:
帶寬因素:
假設(shè)有200m的流量同時(shí)請(qǐng)求進(jìn)入服務(wù)器,但是帶寬只有1m,這么來(lái)算光是接收這批數(shù)據(jù)量信息也要消耗大約200s的時(shí)間。帶寬可以理解為在指定時(shí)間內(nèi)從一端請(qǐng)求到另一端的流量總量。而且局域網(wǎng)和廣域網(wǎng)的帶寬計(jì)算其實(shí)也是不一樣的,
服務(wù)器的ulimit
通常我們使用的線上服務(wù)器都是centos系列,這里我列舉centos7相關(guān)的系統(tǒng)配置:ulimit配置 查看服務(wù)器允許的最大打開(kāi)文件數(shù)目(linux系統(tǒng)中設(shè)計(jì)概念為一切皆文件) 通常如果我們的java程序需要增大一些socket的鏈接數(shù)目,可以通過(guò)調(diào)整ulimit 里面的open參數(shù)進(jìn)行配置。
?[root@izwz9ic9ggky8kub9x1ptuz?~]#?ulimit?-a?|?grep?open
open?files??????????????????????(-n)?1000
查看用戶的最大進(jìn)程數(shù)目
[root@izwz9ic9ggky8kub9x1ptuz?~]#?ulimit?-a?|?grep?user
max?user?processes??????????????(-u)?7284
相關(guān)的配置存放在了/etc/security/limits.conf文件中。
系統(tǒng)的一些內(nèi)核參數(shù)配置
如果是在一些壓力測(cè)試場(chǎng)景中,我們通常會(huì)預(yù)見(jiàn)到這種報(bào)錯(cuò):
apr_socket_recv:?Connection?reset?by?peer?(54)
通常這種情況是因?yàn)橄到y(tǒng)內(nèi)部的一些防范參數(shù)設(shè)置導(dǎo)致的,需要調(diào)整/etc/sysctl.conf 文件中的相關(guān)參數(shù):
net.ipv4.tcp_syncookies?=?0
#當(dāng)并發(fā)請(qǐng)求數(shù)目超過(guò)了1000之后,服務(wù)器自身可能會(huì)認(rèn)為是收到了syn泛洪攻擊,但對(duì)于高并發(fā)系統(tǒng),要禁用此設(shè)置
?
net.ipv4.tcp_max_syn_backlog
#參數(shù)決定了SYN_RECV狀態(tài)隊(duì)列的數(shù)量,一般默認(rèn)值為512或者1024,即超過(guò)這個(gè)數(shù)量,系統(tǒng)將不再接受新的TCP連接請(qǐng)求,一定程度上可以防止系統(tǒng)資源耗盡。可根據(jù)情況增加該值以接受更多的連接請(qǐng)求。
?
net.ipv4.tcp_tw_recycle
#參數(shù)決定是否加速TIME_WAIT的sockets的回收,默認(rèn)為0。
?
net.ipv4.tcp_tw_reuse
#參數(shù)決定是否可將TIME_WAIT狀態(tài)的sockets用于新的TCP連接,默認(rèn)為0。
??
net.ipv4.tcp_max_tw_buckets
#參數(shù)決定TIME_WAIT狀態(tài)的sockets總數(shù)量,可根據(jù)連接數(shù)和系統(tǒng)資源需要進(jìn)行設(shè)置。
對(duì)于防范參數(shù)還可以如下修改查看:
cd?/proc/sys/net/ipv4
echo?"0"?>?tcp_syncookie
通常企業(yè)中使用的都是nginx進(jìn)行接收請(qǐng)求,然后進(jìn)行負(fù)載均衡轉(zhuǎn)發(fā)。在nginx層里面會(huì)有幾個(gè)核心參數(shù)配置:最大連接數(shù),最大并發(fā)訪問(wèn)數(shù)
#指定同一個(gè)ip的每次請(qǐng)求數(shù)量都限制為10次
limit_conn_zone?$binary_remote_addr?zone=perip:10m;
limit_conn?perip?10
Tomcat部分分析
Tomcat支持三種接收請(qǐng)求的處理方式:BIO、NIO、APR 。
1、Bio方式,阻塞式I/O操作即使用的是傳統(tǒng)Java I/O操作,Tomcat7以下版本默認(rèn)情況下是以bio模式運(yùn)行的,由于每個(gè)請(qǐng)求都要?jiǎng)?chuàng)建一個(gè)線程來(lái)處理,線程開(kāi)銷較大,不能處理高并發(fā)的場(chǎng)景,在三種模式中性能也最低
2、Nio方式,是Java SE 1.4及后續(xù)版本提供的一種新的I/O操作方式(即java.nio包及其子包),是一個(gè)基于緩沖區(qū)、并能提供非阻塞I/O操作的Java API,它擁有比傳統(tǒng)I/O操作(bio)更好的并發(fā)運(yùn)行性能。tomcat 8版本及以上默認(rèn)nio模式
3、apr模式,簡(jiǎn)單理解,就是從操作系統(tǒng)級(jí)別解決異步IO問(wèn)題,大幅度的提高服務(wù)器的處理和響應(yīng)性能, 也是Tomcat運(yùn)行高并發(fā)應(yīng)用的首選模式。啟用這種模式稍微麻煩一些,需要安裝一些依賴庫(kù), 而apr的本質(zhì)就是使用jni技術(shù)調(diào)用操作系統(tǒng)底層的IO接口,所以需要提前安裝所需要的依賴,首先是需要安裝openssl和apr
tomcat連接參數(shù)調(diào)整
在tomcat中有這么一段經(jīng)典的配置參數(shù):
"80"?maxHttpHeaderSize="8192"
????maxThreads="4000"?minSpareThreads="1000"?maxSpareThreads="2000"
????enableLookups="false"?redirectPort="8443"?acceptCount="2000"
????connectionTimeout="20000"?disableUploadTimeout="true"?/
maxThreads表示tomcat最多可以創(chuàng)建多少個(gè)線程來(lái)處理請(qǐng)求。
minSpareThread表示tomcat一開(kāi)始啟動(dòng)的時(shí)候會(huì)創(chuàng)建多少個(gè)線程,即使是閑著也會(huì)創(chuàng)建。
maxSpareThread表示tomcat創(chuàng)建的最大閑置線程數(shù)目。一旦tomcat創(chuàng)建的線程數(shù)目達(dá)到這個(gè)瓶頸,那么就需要進(jìn)行線程的回收了。
connectionTimeout表示連接的超時(shí)時(shí)長(zhǎng)。
假設(shè)我們同時(shí)有1000個(gè)請(qǐng)求并發(fā)訪問(wèn),但是一臺(tái)tomcat的maxThreads只設(shè)置為了500,那么此時(shí)就會(huì)出現(xiàn)請(qǐng)求擁塞的情況,也就是瓶頸點(diǎn)之一。
Redis部分性能瓶頸分析
一些大key的查詢,導(dǎo)致網(wǎng)絡(luò)出現(xiàn)擁塞情況
例如說(shuō)往一個(gè)list集合中存儲(chǔ)了50m的數(shù)據(jù),一旦發(fā)生list全量查詢,同時(shí)又有其他指令在進(jìn)行訪問(wèn)的時(shí)候,就容易會(huì)導(dǎo)致網(wǎng)絡(luò)堵塞。因?yàn)閞edis的設(shè)計(jì)為單線程處理請(qǐng)求,所以其他指令發(fā)送到redis服務(wù)端的時(shí)候,都需要等待redis將之前的任務(wù)處理完畢之后才能繼續(xù)執(zhí)行。
線上環(huán)境出現(xiàn)了一些”違規(guī)操作“
比較常見(jiàn)的違規(guī)操作:批量執(zhí)行keys指令
在redis處于高qps的狀態(tài)下,隨意一個(gè)keys指令都可能是致命的。keys指令的時(shí)間復(fù)雜度是O(n)級(jí)別,容易導(dǎo)致一時(shí)間系統(tǒng)的卡頓。
內(nèi)存空間不足
當(dāng)redis處于內(nèi)存空間不足的時(shí)候,基本就是整個(gè)系統(tǒng)處于癱瘓作用。因此我們?cè)趯?duì)每個(gè)存儲(chǔ)在redis中的數(shù)值都需要設(shè)置一個(gè)合理的過(guò)期時(shí)間,以及需要思考存儲(chǔ)數(shù)據(jù)的體積大小。
MySQL部分性能瓶頸分析
通常我們?cè)诜治鰏ql查詢方面都容易出現(xiàn)一個(gè)誤區(qū),就是上來(lái)直接進(jìn)行explian分析,但是卻忽略了系統(tǒng)的運(yùn)作上下文環(huán)境。
假設(shè)有一張t_user表,已經(jīng)存儲(chǔ)了幾千萬(wàn)的數(shù)據(jù),并且也對(duì)用戶的id進(jìn)行了索引建立,但是sql執(zhí)行速度依舊是超過(guò)1s時(shí)長(zhǎng),這個(gè)時(shí)候就需要換一種思路進(jìn)行分析了。
例如從表的拆分方面進(jìn)行思考,是否該對(duì)表進(jìn)行橫向拆分,拆解為t_user_01,t_user_02......
以下是我總結(jié)的一些對(duì)于數(shù)據(jù)庫(kù)層面可能出現(xiàn)性能瓶頸的幾點(diǎn)總結(jié):
1.鎖
排查是否會(huì)存在鎖表的情況導(dǎo)致數(shù)據(jù)庫(kù)響應(yīng)緩慢。
2.sql查詢還有優(yōu)化空間,有待完善
通常我們對(duì)于sql的執(zhí)行分析都會(huì)使用explain命令進(jìn)行查看:
這里我貼出了一張關(guān)于explain的常用參數(shù)含義表供大家參考:

3.查詢出的數(shù)據(jù)量過(guò)大
例如說(shuō)一條sql直接查詢了全表的數(shù)據(jù)信息量,直接占滿了網(wǎng)絡(luò)帶寬,因此訪問(wèn)時(shí)候出現(xiàn)了網(wǎng)絡(luò)擁塞。
4.硬件設(shè)備不足
例如在面對(duì)一些高qps的查詢時(shí)候,數(shù)據(jù)庫(kù)本身的機(jī)器硬件配置較低,自然處理速度會(huì)比較慢。
5.自適應(yīng)hash出現(xiàn)鎖沖突
AHI是innodb存儲(chǔ)引擎特有的屬性,innodb存儲(chǔ)引擎會(huì)針對(duì)索引數(shù)據(jù)的查詢結(jié)果做自適應(yīng)的優(yōu)化,當(dāng)某些特定的索引查詢頻率特別高的時(shí)候會(huì)自動(dòng)為其建立hash索引,從而提升查詢的效率。相比于B+Tree索引來(lái)說(shuō),hash索引能夠大大減少對(duì)于io的訪問(wèn)次數(shù),“一擊命中” 查詢數(shù)據(jù),具備更加高效的性能,而且hash索引是由mysql內(nèi)部自動(dòng)適配的,無(wú)需dba在外部做過(guò)多的干預(yù)。
早期版本的hash索引是采用了單鎖模式來(lái)防范并發(fā)訪問(wèn)問(wèn)題,這對(duì)于程序自身的一個(gè)運(yùn)作高效性有一定的”折扣“,后期通過(guò)對(duì)hash索引進(jìn)行了分區(qū),不同頁(yè)的數(shù)據(jù)用不同的hashtable,每個(gè)分區(qū)有對(duì)應(yīng)的鎖來(lái)做并發(fā)訪問(wèn)的預(yù)防。
如果某天你發(fā)現(xiàn)了有很多線程都被堵塞在了RW-latches的時(shí)候,有可能就是因?yàn)閔ash索引的并發(fā)訪問(wèn)負(fù)載過(guò)高導(dǎo)致的堵塞,這個(gè)時(shí)候可以通過(guò)增大hash索引的分區(qū)參數(shù),或者關(guān)閉自適應(yīng)hash索引特性來(lái)進(jìn)行處理。
往期推薦
