
基于Flink+ClickHouse打造輕量級(jí)點(diǎn)擊流實(shí)時(shí)數(shù)倉(cāng)
前言
Flink和ClickHouse分別是實(shí)時(shí)計(jì)算和(近實(shí)時(shí))OLAP領(lǐng)域的翹楚,也是近些年非常火爆的開(kāi)源框架,很多大廠都在將兩者結(jié)合使用來(lái)構(gòu)建各種用途的實(shí)時(shí)平臺(tái),效果很好。關(guān)于兩者的優(yōu)點(diǎn)就不再贅述,本文來(lái)簡(jiǎn)單介紹筆者團(tuán)隊(duì)在點(diǎn)擊流實(shí)時(shí)數(shù)倉(cāng)方面的一點(diǎn)實(shí)踐經(jīng)驗(yàn)。
點(diǎn)擊流及其維度建模
所謂點(diǎn)擊流(click stream),就是指用戶(hù)訪(fǎng)問(wèn)網(wǎng)站、App等Web前端時(shí)在后端留下的軌跡數(shù)據(jù),也是流量分析(traffic analysis)和用戶(hù)行為分析(user behavior analysis)的基礎(chǔ)。點(diǎn)擊流數(shù)據(jù)一般以訪(fǎng)問(wèn)日志和埋點(diǎn)日志的形式存儲(chǔ),其特點(diǎn)是量大、維度豐富。以我們一個(gè)中等體量的普通電商平臺(tái)為例,每天產(chǎn)生200+GB、十億條左右的原始日志,埋點(diǎn)事件100+個(gè),涉及50+個(gè)維度。
按照Kimball的維度建模理論,點(diǎn)擊流數(shù)倉(cāng)遵循典型的星形模型,簡(jiǎn)圖如下。
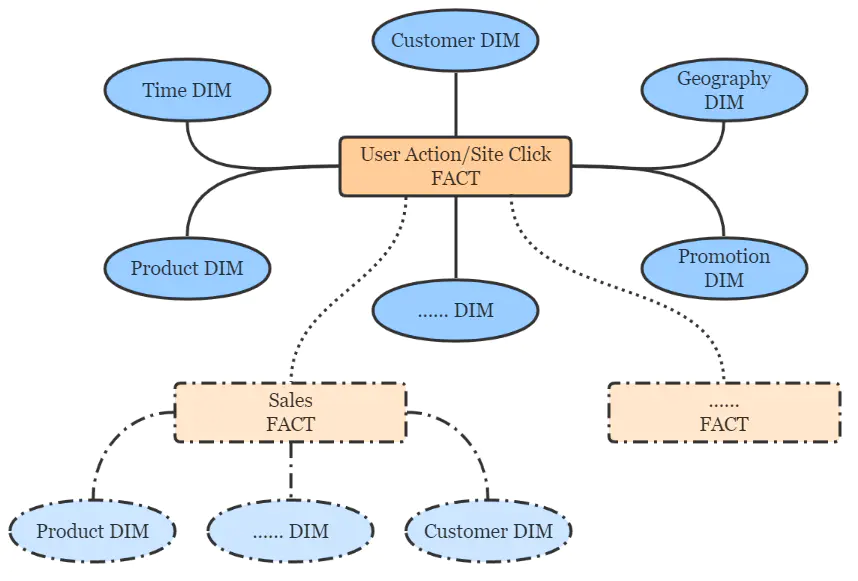
點(diǎn)擊流數(shù)倉(cāng)分層設(shè)計(jì)
點(diǎn)擊流實(shí)時(shí)數(shù)倉(cāng)的分層設(shè)計(jì)仍然可以借鑒傳統(tǒng)數(shù)倉(cāng)的方案,以扁平為上策,盡量減少數(shù)據(jù)傳輸中途的延遲。簡(jiǎn)圖如下。
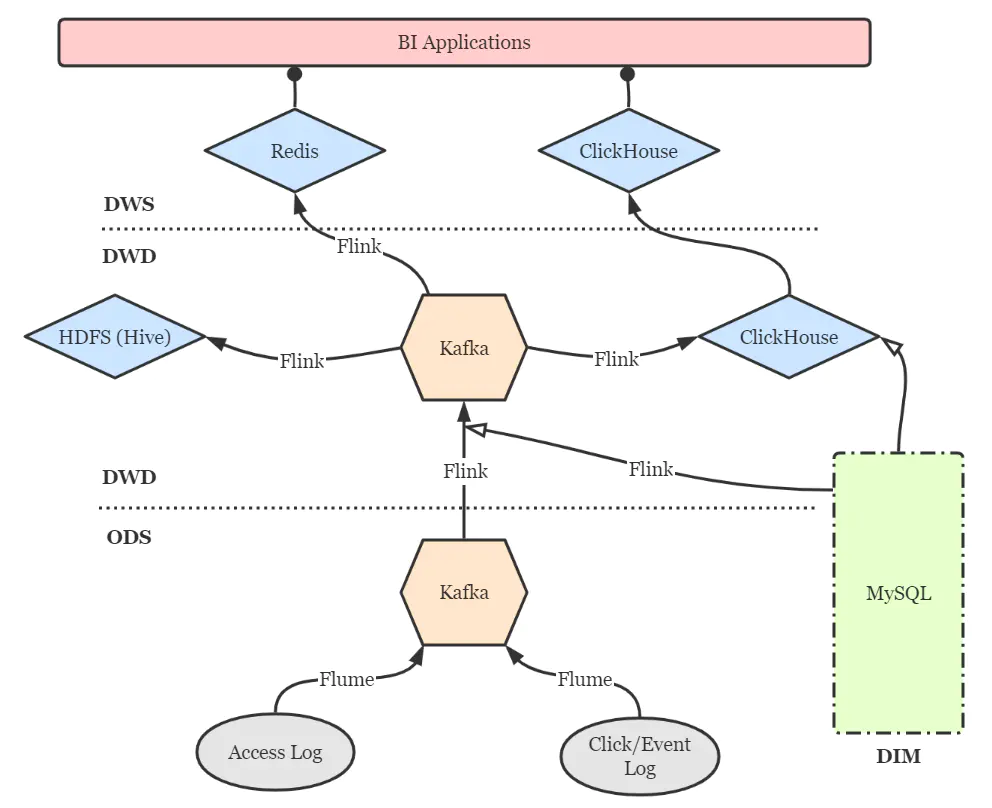
DIM層:維度層,MySQL鏡像庫(kù),存儲(chǔ)所有維度數(shù)據(jù)。 ODS層:貼源層,原始數(shù)據(jù)由Flume直接進(jìn)入Kafka的對(duì)應(yīng)topic。 DWD層:明細(xì)層,通過(guò)Flink將Kafka中數(shù)據(jù)進(jìn)行必要的ETL與實(shí)時(shí)維度join操作,形成規(guī)范的明細(xì)數(shù)據(jù),并寫(xiě)回Kafka以便下游與其他業(yè)務(wù)使用。再通過(guò)Flink將明細(xì)數(shù)據(jù)分別寫(xiě)入ClickHouse和Hive打成大寬表,前者作為查詢(xún)與分析的核心,后者作為備份和數(shù)據(jù)質(zhì)量保證(對(duì)數(shù)、補(bǔ)數(shù)等)。 DWS層:服務(wù)層,部分指標(biāo)通過(guò)Flink實(shí)時(shí)匯總至Redis,供大屏類(lèi)業(yè)務(wù)使用。更多的指標(biāo)則通過(guò)ClickHouse物化視圖等機(jī)制周期性匯總,形成報(bào)表與頁(yè)面熱力圖。特別地,部分明細(xì)數(shù)據(jù)也在此層開(kāi)放,方便高級(jí)BI人員進(jìn)行漏斗、留存、用戶(hù)路徑等靈活的ad-hoc查詢(xún),這些也是ClickHouse遠(yuǎn)超過(guò)其他OLAP引擎的強(qiáng)大之處。
要點(diǎn)與注意事項(xiàng)
Flink實(shí)時(shí)維度關(guān)聯(lián)
Flink框架的異步I/O機(jī)制為用戶(hù)在流式作業(yè)中訪(fǎng)問(wèn)外部存儲(chǔ)提供了很大的便利。針對(duì)我們的情況,有以下三點(diǎn)需要注意:
使用異步MySQL客戶(hù)端,如Vert.x MySQL Client。AsyncFunction內(nèi)添加內(nèi)存緩存(如Guava Cache、Caffeine等),并設(shè)定合理的緩存驅(qū)逐機(jī)制,避免頻繁請(qǐng)求MySQL庫(kù)。實(shí)時(shí)維度關(guān)聯(lián)僅適用于緩慢變化維度,如地理位置信息、商品及分類(lèi)信息等。快速變化維度(如用戶(hù)信息)則不太適合打進(jìn)寬表,我們采用MySQL表引擎將快變維度表直接映射到ClickHouse中,而ClickHouse支持異構(gòu)查詢(xún),也能夠支撐規(guī)模較小的維表join場(chǎng)景。未來(lái)則考慮使用MaterializedMySQL引擎(當(dāng)前仍未正式發(fā)布)將部分維度表通過(guò)binlog鏡像到ClickHouse。
Flink-ClickHouse Sink設(shè)計(jì)
可以通過(guò)JDBC(flink-connector-jdbc)方式來(lái)直接寫(xiě)入ClickHouse,但靈活性欠佳。好在clickhouse-jdbc項(xiàng)目提供了適配ClickHouse集群的BalancedClickhouseDataSource組件,我們基于它設(shè)計(jì)了Flink-ClickHouse Sink,要點(diǎn)有三:
寫(xiě)入本地表,而非分布式表,老生常談了。 按數(shù)據(jù)批次大小以及批次間隔兩個(gè)條件控制寫(xiě)入頻率,在part merge壓力和數(shù)據(jù)實(shí)時(shí)性?xún)煞矫嫒〉闷胶狻D壳拔覀儾捎?0000條的批次大小與15秒的間隔,只要滿(mǎn)足其一則觸發(fā)寫(xiě)入。 BalancedClickhouseDataSource通過(guò)隨機(jī)路由保證了各ClickHouse實(shí)例的負(fù)載均衡,但是只是通過(guò)周期性ping來(lái)探活,并屏蔽掉當(dāng)前不能訪(fǎng)問(wèn)的實(shí)例,而沒(méi)有故障轉(zhuǎn)移——亦即一旦試圖寫(xiě)入已經(jīng)失敗的節(jié)點(diǎn),就會(huì)丟失數(shù)據(jù)。為此我們?cè)O(shè)計(jì)了重試機(jī)制,重試次數(shù)和間隔均可配置,如果當(dāng)重試機(jī)會(huì)耗盡后仍然無(wú)法成功寫(xiě)入,就將該批次數(shù)據(jù)轉(zhuǎn)存至配置好的路徑下,并報(bào)警要求及時(shí)檢查與回填。
當(dāng)前我們僅實(shí)現(xiàn)了DataStream API風(fēng)格的Flink-ClickHouse Sink,隨著Flink作業(yè)SQL化的大潮,在未來(lái)還計(jì)劃實(shí)現(xiàn)SQL風(fēng)格的ClickHouse Sink,打磨健壯后會(huì)適時(shí)回饋給社區(qū)。另外,除了隨機(jī)路由,我們也計(jì)劃加入輪詢(xún)和sharding key hash等更靈活的路由方式。
還有一點(diǎn)就是,ClickHouse并不支持事務(wù),所以也不必費(fèi)心考慮2PC Sink等保證exactly once語(yǔ)義的操作。如果Flink到ClickHouse的鏈路出現(xiàn)問(wèn)題導(dǎo)致作業(yè)重啟,作業(yè)會(huì)直接從最新的位點(diǎn)(即Kafka的latest offset)開(kāi)始消費(fèi),丟失的數(shù)據(jù)再經(jīng)由Hive進(jìn)行回填即可。
ClickHouse數(shù)據(jù)重平衡
ClickHouse集群擴(kuò)容之后,數(shù)據(jù)的重平衡(reshard)是一件麻煩事,因?yàn)椴淮嬖陬?lèi)似HDFS Balancer這種開(kāi)箱即用的工具。一種比較簡(jiǎn)單粗暴的思路是修改ClickHouse配置文件中的shard weight,使新加入的shard多寫(xiě)入數(shù)據(jù),直到所有節(jié)點(diǎn)近似平衡之后再調(diào)整回來(lái)。但是這會(huì)造成明顯的熱點(diǎn)問(wèn)題,并且僅對(duì)直接寫(xiě)入分布式表才有效,并不可取。
因此,我們采用了一種比較曲折的方法:將原表重命名,在所有節(jié)點(diǎn)上建立與原表schema相同的新表,將實(shí)時(shí)數(shù)據(jù)寫(xiě)入新表,同時(shí)用clickhouse-copier工具將歷史數(shù)據(jù)整體遷移到新表上來(lái),再刪除原表。當(dāng)然在遷移期間,被重平衡的表是無(wú)法提供服務(wù)的,仍然不那么優(yōu)雅。
猜你喜歡
Hive計(jì)算最大連續(xù)登陸天數(shù)
Hadoop 數(shù)據(jù)遷移用法詳解
Hbase修復(fù)工具Hbck
數(shù)倉(cāng)建模分層理論
一文搞懂Hive的數(shù)據(jù)存儲(chǔ)與壓縮
大數(shù)據(jù)組件重點(diǎn)學(xué)習(xí)這幾個(gè)