
Hudi 原理 | Apache Hudi 如何加速傳統(tǒng)批處理模式?
1. 現(xiàn)狀說明
1.1 數(shù)據(jù)湖攝取和計(jì)算過程 - 處理更新
在我們的用例中1-10% 是對歷史記錄的更新。當(dāng)記錄更新時(shí),我們需要從之前的 updated_date 分區(qū)中刪除之前的條目,并將條目添加到最新的分區(qū)中,在沒有刪除和更新功能的情況下,我們必須重新讀取整個(gè)歷史表分區(qū) -> 去重?cái)?shù)據(jù) -> 用新的去重?cái)?shù)據(jù)覆蓋整個(gè)表分區(qū)
1.2 當(dāng)前批處理過程中的挑戰(zhàn)
這個(gè)過程有效,但也有其自身的缺陷:
1.?時(shí)間和成本——每天都需要覆蓋整個(gè)歷史表
2.?數(shù)據(jù)版本控制——沒有開箱即用的數(shù)據(jù)和清單版本控制(回滾、并發(fā)讀取和寫入、時(shí)間點(diǎn)查詢、時(shí)間旅行以及相關(guān)功能不存在)
3.?寫入放大——日常歷史數(shù)據(jù)覆蓋場景中的外部(或自我管理)數(shù)據(jù)版本控制增加了寫入放大,從而占用更多的 S3 存儲(chǔ)
借助Apache Hudi,我們希望在將數(shù)據(jù)攝取到數(shù)據(jù)湖中的同時(shí),找到更好的重復(fù)數(shù)據(jù)刪除和數(shù)據(jù)版本控制優(yōu)化解決方案。
2. Hudi 數(shù)據(jù)湖 — 查詢模式
當(dāng)我們開始在我們的數(shù)據(jù)湖上實(shí)現(xiàn) Apache Hudi 的旅程時(shí),我們根據(jù)表的主要用戶的查詢模式將表分為 2 類。
??面向ETL :這是指我們從各種生產(chǎn)系統(tǒng)攝取到數(shù)據(jù)湖中的大多數(shù)原始/基本快照表。如果這些表被 ETL 作業(yè)廣泛使用,那么我們將每日數(shù)據(jù)分區(qū)保持在 updated_date,這樣下游作業(yè)可以簡單地讀取最新的 updated_at 分區(qū)并(重新)處理數(shù)據(jù)。
??面向分析師:通常包括維度表和業(yè)務(wù)分析師查詢的大部分計(jì)算 OLAP,分析師通常需要查看基于事務(wù)(或事件)created_date 的數(shù)據(jù),而不太關(guān)心 updated_date。
這是一個(gè)示例電子商務(wù)訂單數(shù)據(jù)流,從攝取到數(shù)據(jù)湖到創(chuàng)建 OLAP,最后到業(yè)務(wù)分析師查詢它
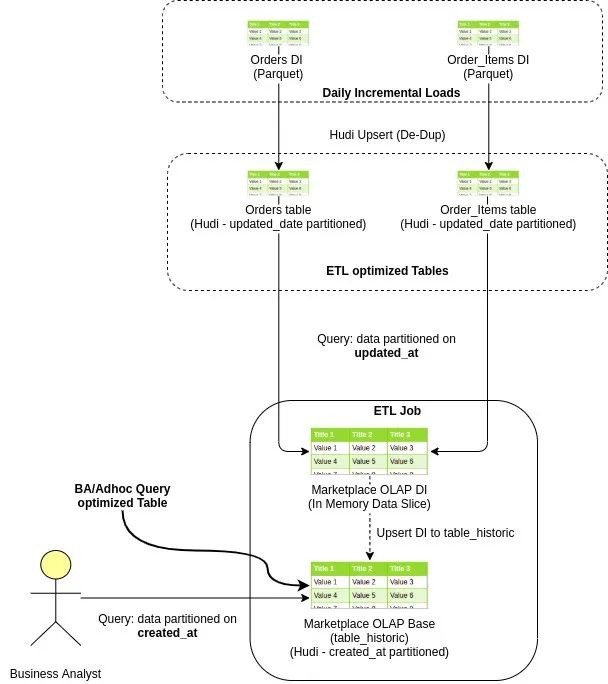
由于兩種類型的表的日期分區(qū)列不同,我們采用不同的策略來解決這兩個(gè)用例。
2.1 面向分析師的表/OLAP(按 created_date 分區(qū))
在 Hudi 中,我們需要指定分區(qū)列和主鍵列,以便 Hudi 可以為我們處理更新和刪除。以下是我們?nèi)绾翁幚砻嫦蚍治鰩煹谋碇械母潞蛣h除的邏輯:
??讀取上游數(shù)據(jù)的 D-n 個(gè) updated_date 分區(qū)。
??應(yīng)用數(shù)據(jù)轉(zhuǎn)換。現(xiàn)在這個(gè)數(shù)據(jù)將只有新的插入和很少的更新記錄。
??發(fā)出 hudi upsert 操作,將處理后的數(shù)據(jù) upsert 到目標(biāo) Hudi 表。
由于主鍵和 created_date 對于退出和傳入記錄保持相同,Hudi 通過使用來自傳入記錄 created_date 和 primary_key 列的此信息獲取現(xiàn)有記錄的分區(qū)和分區(qū)文件路徑。
2.2 面向ETL(按更新日期分區(qū))
當(dāng)我們開始使用 Hudi 時(shí),在閱讀了許多博客和文檔之后,在 created_date 上對面向 ETL 的表進(jìn)行分區(qū)似乎是合乎邏輯的。此外 Hudi 提供增量消費(fèi)功能,允許我們在 created_date 上對表進(jìn)行分區(qū),并僅獲取在 D-1 或 D-n 上插入(插入或更新)的那些記錄。
1. “created_date”分區(qū)的挑戰(zhàn)
這種方法在理論上效果很好,但在改造傳統(tǒng)的日常批處理過程中的增量消費(fèi)時(shí),它帶來了其他一系列挑戰(zhàn):Hudi 維護(hù)了在不同時(shí)刻在表上執(zhí)行的所有操作的時(shí)間表,這些提交包含有關(guān)作為 upsert 的一部分插入或重寫的部分文件的信息,我們將此 Hudi 表稱為 Commit Timeline。這里要注意的重要信息是增量查詢基于提交時(shí)間線,而不依賴于數(shù)據(jù)記錄中存在的實(shí)際更新/創(chuàng)建日期信息。
??冷啟動(dòng):當(dāng)我們將現(xiàn)有的上游表遷移到 Hudi 時(shí),D-1 Hudi 增量查詢將獲取完整的表,而不僅僅是 D-1 更新。發(fā)生這種情況是因?yàn)樵陂_始時(shí),整個(gè)表是通過在 D-1 提交時(shí)間線內(nèi)發(fā)生的單個(gè)初始提交或多個(gè)提交創(chuàng)建的,并且缺少真正的增量提交信息。
??歷史數(shù)據(jù)重新攝取:在每個(gè)常規(guī)增量 D-1 拉取中,我們期望僅在 D-1 上更新的記錄作為輸出。但是在重新攝取歷史數(shù)據(jù)的情況下,會(huì)再次出現(xiàn)類似于前面描述的冷啟動(dòng)問題的問題,并且下游作業(yè)也會(huì)出現(xiàn) OOM。
作為面向 ETL 的作業(yè)的解決方法,我們嘗試將數(shù)據(jù)分區(qū)保持在 updated_date 本身,然而這種方法也有其自身的挑戰(zhàn)。
2. “updated_date”分區(qū)的挑戰(zhàn)
我們知道 Hudi 表的本地索引,Hudi 依靠索引來獲取存儲(chǔ)在數(shù)據(jù)分區(qū)本地目錄中的 Row-to-Part_file 映射。因此,如果我們的表在 updated_date 進(jìn)行分區(qū),Hudi 無法跨分區(qū)自動(dòng)刪除重復(fù)記錄。Hudi 的全局索引策略要求我們保留一個(gè)內(nèi)部或外部索引來維護(hù)跨分區(qū)的數(shù)據(jù)去重。對于大數(shù)據(jù)量,每天大約 2 億條記錄,這種方法要么運(yùn)行緩慢,要么因 OOM 而失敗。因此,為了解決更新日期分區(qū)的數(shù)據(jù)重復(fù)挑戰(zhàn),我們提出了一種全新的重復(fù)數(shù)據(jù)刪除策略,該策略也具有很高的性能。
3. “新”重復(fù)數(shù)據(jù)刪除策略
??查找更新 - 從每日增量負(fù)載中,僅過濾掉更新(1-10% 的 DI 數(shù)據(jù))(其中 updated_date> created_date)(快速,僅映射操作)
??找到過時(shí)更新 - 將這些“更新”與下游 Hudi 基表廣播連接。由于我們只獲取更新的記錄(僅占每日增量的 1-10%),因此可以實(shí)現(xiàn)高性能的廣播連接。這為我們提供了與更新記錄相對應(yīng)的基礎(chǔ) Hudi 表中的所有現(xiàn)有記錄
??刪除過時(shí)更新——在基本 Hudi 表路徑上的這些“過時(shí)更新”上發(fā)出 Hudi 刪除命令
??插入 - 在基本 hudi 表路徑上的完整每日增量負(fù)載上發(fā)出 hudi insert 命令
進(jìn)一步優(yōu)化用 true 填充陳舊更新中的 _hoodie_is_deleted 列,并將其與每日增量負(fù)載結(jié)合。通過基本 hudi 表路徑發(fā)出此數(shù)據(jù)的 upsert 命令。它將在單個(gè)操作(和單個(gè)提交)中執(zhí)行插入和刪除。
4. Apache Hudi 的優(yōu)勢
1. 時(shí)間和成本——Hudi 在重復(fù)數(shù)據(jù)刪除時(shí)不會(huì)覆蓋整個(gè)表。它只是重寫接收更新的部分文件。因此較小的 upsert 工作
2. 數(shù)據(jù)版本控制——Hudi 保留表版本(提交歷史),因此提供實(shí)時(shí)查詢(時(shí)間旅行)和表版本回滾功能。
3. 寫入放大——由于只有部分文件被更改并保留用于數(shù)據(jù)清單版本控制,我們不需要保留完整數(shù)據(jù)的版本。因此整體寫入放大是最小的。
作為數(shù)據(jù)版本控制的另一個(gè)好處,它解決了并發(fā)讀取和寫入問題,因?yàn)閿?shù)據(jù)版本控制使并發(fā)讀取器可以讀取數(shù)據(jù)文件的版本控制副本,并且當(dāng)并發(fā)寫入器用新數(shù)據(jù)覆蓋同一分區(qū)時(shí)不會(huì)拋出 FileNotFoundException 文件。