
Meta發(fā)布大規(guī)模視覺模型評估基準(zhǔn)FACET!開源視覺模型DINOv2允許商用

作者 | 謝年年
近日,Meta宣布開源計(jì)算機(jī)視覺模型DINOv2現(xiàn)在可商業(yè)化應(yīng)用了,并發(fā)布了全新的視覺模型評估新基準(zhǔn)FACET。
DINOv2是Meta AI繼「分割一切」SAM模型之后發(fā)布的一重磅視覺基礎(chǔ)模型,在今年4月份宣布開源,但之前只能用于技術(shù)研究,這次Meta宣布其可在 Apache 2.0 許可證下進(jìn)行商業(yè)化。意味著開發(fā)者、研究人員可以靈活地探索其在業(yè)務(wù)中的應(yīng)用,給實(shí)際業(yè)務(wù)提供解決方案。
DINOv2是高性能計(jì)算機(jī)視覺基礎(chǔ)模型,能產(chǎn)生高性能的視覺表征,具備自我監(jiān)督學(xué)習(xí),無需微調(diào)就能用于分類、分割、圖像檢索、深度估計(jì)等下游任務(wù)。 該模型的應(yīng)用范圍非常廣泛,例如,世界資源研究所通過DINOv2繪制虛擬森林地圖。
相較于其他模型,DINOv2在執(zhí)行視覺任務(wù)時(shí)能夠更準(zhǔn)確地處理人物的年齡、性別、膚色等特征,提供更一致的結(jié)果。
體驗(yàn)demo:
https://dinov2.metademolab.com/
論文地址:
https://arxiv.org/abs/2304.07193
GitHub地址:
https://github.com/facebookresearch/dinov2
讓我們通過一些例子來看看DINOv2的表現(xiàn)吧!
深度估計(jì)(Depth Estimation)
一般很少有預(yù)訓(xùn)練模型展示自己在深度估計(jì)方面的能力,DINOv2 模型表現(xiàn)出強(qiáng)大的分布外泛化能力(strong out-of-distribution performance)。
語義分割(Semantic Segmentation)
DINOv2 的凍結(jié)特征(frozen features)可以很容易地用于語義分割任務(wù)。
實(shí)例檢索(Instance Retrieval)
給定目標(biāo)圖像,從大量的藝術(shù)圖像中找到與給定圖像相似的藝術(shù)作品。
原圖:
檢索結(jié)果:

稠密匹配(Dense Matching)
在檢索到與目標(biāo)圖像相似的多個(gè)圖像后,可從中選擇一張圖片進(jìn)行像素點(diǎn)到像素點(diǎn)更細(xì)粒度的匹配。在兩張圖像中找到最相似的對應(yīng)點(diǎn)。

稀疏匹配(Sparse Matching)
稀疏匹配相對于稠密匹配,其匹配的單位更大一些。
視覺模型評估基準(zhǔn)——FACET
雖然DINOv2等計(jì)算機(jī)視覺模型在分類、檢測、分割等任務(wù)中展現(xiàn)出令人印象深刻的能力。然而,由于訓(xùn)練數(shù)據(jù)的限制,這些模型可能會(huì)學(xué)習(xí)到社會(huì)偏見,并在下游任務(wù)中傳遞這些有害的刻板印象。
以往的研究表明,計(jì)算機(jī)視覺公平性評估非常具有挑戰(zhàn)性,并且可能存在誤差。為了應(yīng)對這個(gè)問題,Meta發(fā)布了一項(xiàng)全新的綜合基準(zhǔn)測試工具——FACET。
FACET提供了一種新的方法來評估計(jì)算機(jī)視覺模型的公平性。它不僅考慮了人口統(tǒng)計(jì)和物理屬性,還考慮了與人類相關(guān)的類別,例如評估圖片人物的性別、膚色、光線等,從而能夠進(jìn)行更深入的評估,揭示模型中存在的偏見。
通過引入FACET,我們能夠更全面地評估計(jì)算機(jī)視覺模型的公平性,打破刻板印象,推動(dòng)公正和包容的計(jì)算機(jī)視覺技術(shù)發(fā)展。
FACET論文鏈接:
https://ai.meta.com/research/publications/facet-fairness-in-computer-vision-evaluation-benchmark/
FACET數(shù)據(jù)集下載地址:
https://ai.meta.com/datasets/facet-downloads/
FACET數(shù)據(jù)集
該數(shù)據(jù)集包含32,000張圖像,涵蓋了50,000個(gè)人的信息。這些圖像由專家進(jìn)行標(biāo)注,包括人口統(tǒng)計(jì)屬性(如性別、年齡)、額外的身體屬性(如膚色、發(fā)型)以及與職業(yè)和活動(dòng)相關(guān)的細(xì)粒度類別,如醫(yī)生、唱片騎師或吉他手等。FACET還包含了SA-1B數(shù)據(jù)集中69,000個(gè)戴口罩的人的頭發(fā)和服裝標(biāo)簽。

通過使用FACET初步評估發(fā)現(xiàn),目前最先進(jìn)的模型在展示不同人口群體之間的性能差異方面存在一些傾向。例如,對于膚色較深的人,識別他們的照片可能更具挑戰(zhàn)性,而對于卷發(fā)而非直發(fā)的人來說,這種挑戰(zhàn)可能會(huì)更加顯著。
通過發(fā)布FACET,研究人員和從業(yè)人員執(zhí)行此基準(zhǔn)測試以更好地了解其模型存在的差異,并幫助他們更好地理解和處理模型中的偏見和不公平現(xiàn)象。這為研究人員提供了一個(gè)有力的工具,使他們能夠更深入地探索和解決計(jì)算機(jī)視覺模型中的公平性問題。
在FACET上評估DINOv2
為了驗(yàn)證DINOv2模型的公平性,研究人員運(yùn)用FACET評估了DINOv2在不同屬性上的性能差異,并將其與SEERv2模型和OpenCLIP視覺編碼器進(jìn)行了比較,這些屬性包括分類、年齡組和膚色等。
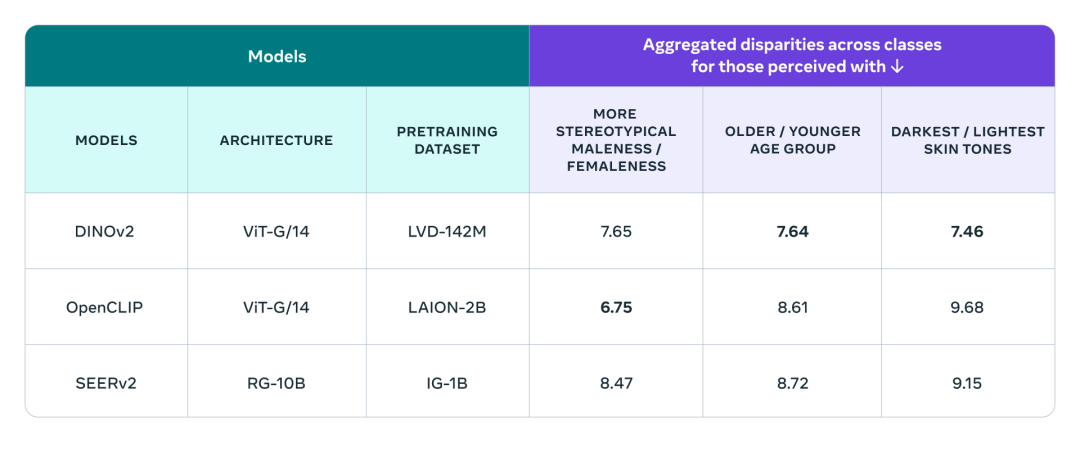
研究結(jié)果顯示,DINOv2在性能上與其他模型相當(dāng):在感知性別方面略遜于OpenCLIP,但在感知年齡組和膚色方面優(yōu)于其他模型。
FACET評估能夠更深入地研究模型的潛在偏見,這是FACET相對于以往的公平性評估基準(zhǔn)的優(yōu)勢所在。
盡管SEERv2、OpenCLIP和DINOv2在大多數(shù)屬性上表現(xiàn)良好,但在某些特定屬性上仍存在性別、年齡和膚色方面的偏見。例如,在性別偏見最嚴(yán)重的職業(yè)中,如"護(hù)士",這三種模型都表現(xiàn)出不同程度的偏見,其中SEERv2和OpenCLIP的偏見更為顯著。
這可能是因?yàn)镾EERv2是在未經(jīng)篩選的社交媒體內(nèi)容上進(jìn)行預(yù)訓(xùn)練,導(dǎo)致數(shù)據(jù)源缺乏多樣性。而OpenCLIP使用CLIP視覺語言模型進(jìn)行數(shù)據(jù)過濾,但這可能會(huì)放大已存在于圖像、文本訓(xùn)練數(shù)據(jù)和模型中的職業(yè)和性別之間的關(guān)聯(lián)。
而DINOv2的預(yù)訓(xùn)練數(shù)據(jù)集可能無意中復(fù)制了參考數(shù)據(jù)集中的偏見。例如,如果一個(gè)數(shù)據(jù)集的圖像分布不足以代表某些群體,那么會(huì)從ImageNet中選擇一部分?jǐn)?shù)據(jù)作為主要參考,從而導(dǎo)致偏見的產(chǎn)生。
由此可見,計(jì)算機(jī)視覺模型在某種程度上存在偏見,這對下游任務(wù)將會(huì)造成了巨大的危害。因此,我們?nèi)匀恍枰M(jìn)一步改進(jìn)模型,以確保計(jì)算機(jī)視覺模型的公平性和公正性。
One More thing
Meta在2021年開源DINO模型,2023年4月開源了DINOV2版本,本次宣布可商用化足以看出Meta在開源上的決心,希望越來越多的優(yōu)秀模型可以引入到開源社區(qū),開發(fā)者一起推進(jìn)AI技術(shù)進(jìn)步和應(yīng)用。
