導語 | We 分析是微信小程序官方推出的、面向小程序服務商的數(shù)據(jù)分析平臺,其中畫像洞察是一個非常重要的功能模塊。微信開發(fā)工程師鐘文波將描述 We 分析畫像系統(tǒng)各模塊是如何設計,在介紹基礎標簽模塊之后,重點講解用戶分群模塊設計。希望相關的技術實現(xiàn)思路,能夠對你有所啟發(fā)。
1.1 畫像系統(tǒng)簡述
We 分析是小程序官方推出的、面向小程序服務商的數(shù)據(jù)分析平臺,其中畫像洞察是一個重要的功能模塊。該功能將為使用者提供基礎的畫像標簽分析能力,提供自定義的用戶分群功能,從而滿足更多個性化的分析需求及支撐更多的畫像應用場景。在此之前,原有 MP 的畫像分析僅有基礎畫像,相當于只能分析小程序大盤固定周期的基礎屬性,而無法針對特定人群或自定義人群進行分析及應用。平臺頭部的使用者均希望平臺提供完善的畫像分析能力。除最基礎的畫像屬性之外,也為使用者提供更豐富的標簽及更靈活的用戶分群應用能力。因此, We 分析在相關能力上計劃進行優(yōu)化。 1.2 畫像系統(tǒng)設計目標
- 易用性:易用性主要指使用者在體驗畫像洞察功能的時候,不需要學習成本就能直接上手使用。使用者可以結合自身業(yè)務場景解決問題,做到開箱即用 0 門檻。
- 穩(wěn)定性:穩(wěn)定性指系統(tǒng)穩(wěn)定可靠體驗好。例如畫像標簽數(shù)據(jù)、人群包按時穩(wěn)定產(chǎn)出,在交互使用過程中查詢速度快,做到如絲般順滑的手感。
- 完備性:指數(shù)據(jù)豐富、規(guī)則靈活、功能完善;支持豐富的人群圈選數(shù)據(jù),預置標簽、人群標簽、平臺行為、自定義上報行為等。做到在不違反隱私的情況下平臺基本提供使用者想要的數(shù)據(jù)。
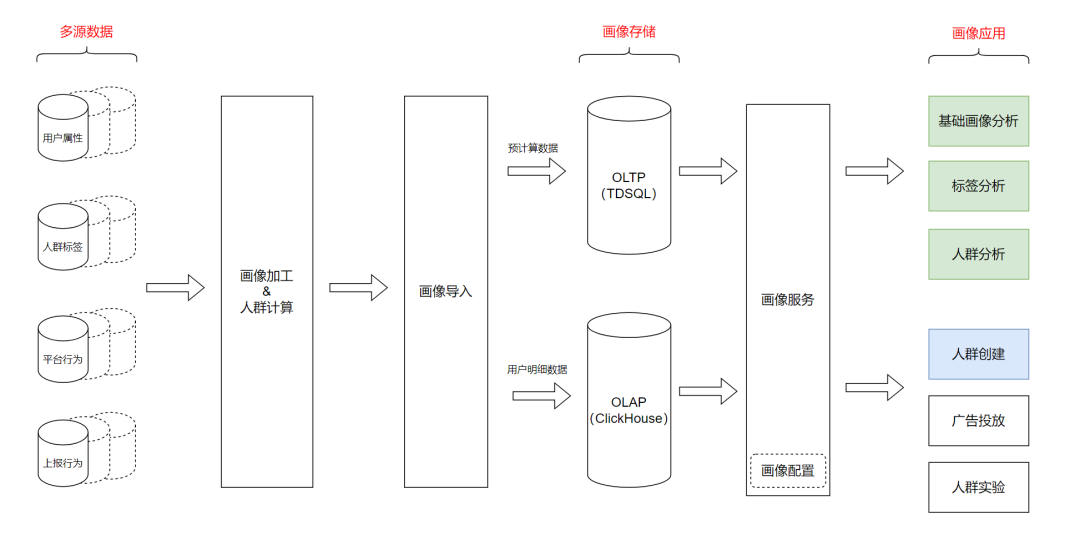
整體來看,平臺支持靈活的標簽及人群創(chuàng)建方式,使用者按照自己的想法任意圈選出想要的人群,按不同周期手動或自動選出人群包。此外也支持人群的跟蹤分析,人群在多場景的應用等。系統(tǒng)從產(chǎn)品形態(tài)的角度出發(fā),在下文分成2個模塊進行闡述——分別是基礎標簽模塊及用戶分群模塊。- 多源數(shù)據(jù):數(shù)據(jù)源包括用戶屬性、人群標簽、平臺行為數(shù)據(jù)、自定義上報數(shù)據(jù)。
- 畫像加工:主要是對用戶屬性、人群標簽、平臺行為,進行相應的 ETL(Extract Transform Load ,提取轉換加載)及預計算。
- 人群計算:根據(jù)使用者定義的用戶分群規(guī)則,從多源數(shù)據(jù)中計算出對應的人群。
- 畫像導入:畫像及人群數(shù)據(jù)在 TWD 加工好后,從 TWD 分布式 HDFS 集群導入到線上的 TDSQL 、 ClickHouse 存儲;其中,預計算的數(shù)據(jù)導入到線上 TDSQL 存儲,用戶行為等明細數(shù)據(jù)導入到線上 ClickHouse 集群中。
- 畫像服務:提供在線的畫像服務接口。其中標簽管理使用通用配置系統(tǒng),數(shù)據(jù)服務采用 RPC 框架開發(fā),在上一層是平臺的數(shù)據(jù)中間件。此處也統(tǒng)一做了流量控制、異步調(diào)用、調(diào)用監(jiān)控、及參數(shù)安全校驗。
- 畫像應用:提供基礎標簽分析及針對特定人群的標簽分析,另外還提供人群圈選跟蹤分析及線上應用等。
3.1 功能描述
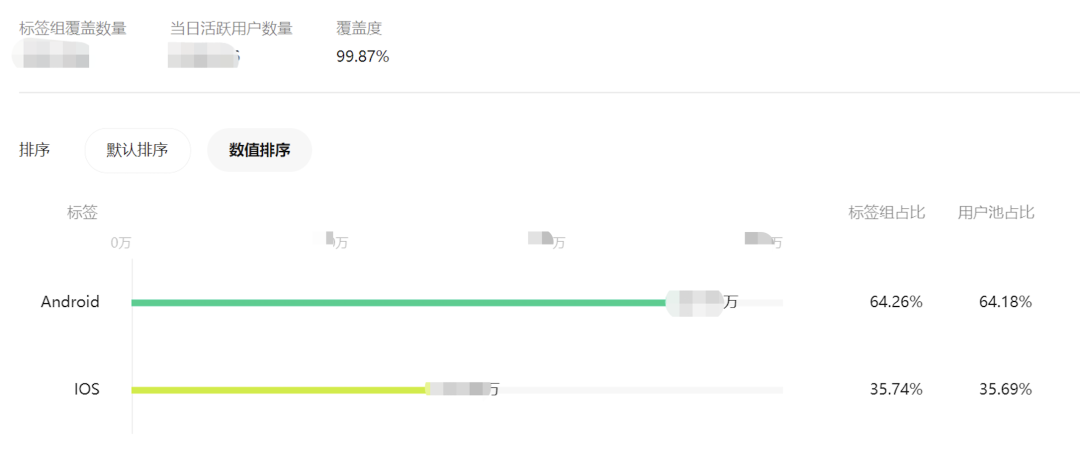
該模塊主要滿足使用者對畫像的基礎分析需求,預期能滿足絕大部分中長尾使用者對畫像的使用深度要求。主要提供的是針對小程序大盤的基礎標簽分析,及針對特定人群(如活躍:1天活躍、7天活躍、30天活躍、180天活躍)的特定標簽分析。如下所示: 3.2 技術實現(xiàn)
3.2.1 數(shù)據(jù)計算
從上述功能的描述,可以看出功能的特點是官方定義數(shù)據(jù)范圍可控,支持的是針對特定人群的特定標簽分析。針對特定人群的特定標簽分析數(shù)據(jù)是用離線 T + 1 的 hive 任務進行計算。流程如下。分別計算官方特定標簽的統(tǒng)計數(shù)據(jù)、特定人群的統(tǒng)計數(shù)據(jù),以及計算特定人群交叉特定標簽的數(shù)據(jù)。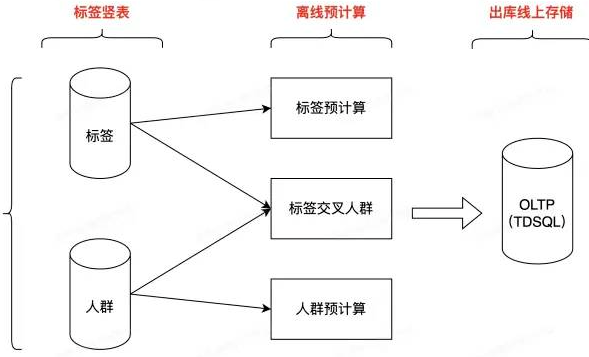
3.2.2 數(shù)據(jù)存儲
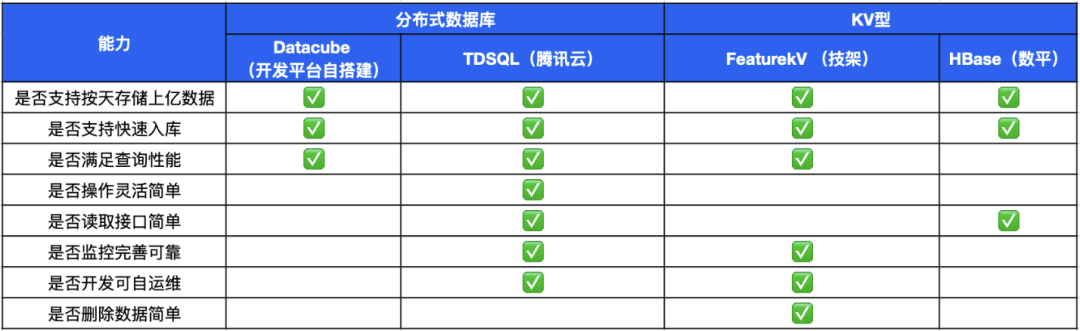
不同存儲對比存在差異。在上述分析之后,需要存儲的是預計算好的結果數(shù)據(jù)。此外,業(yè)務的特點是按照小程序進行多個數(shù)據(jù)主題統(tǒng)計的存儲,所以第一直覺是適合用分布式 OLTP 存儲。團隊也對比了不同的數(shù)據(jù)庫,在選型過程中,主要考慮對比的點包括數(shù)據(jù)的寫入、讀取性能。
- 寫入:包括是否可以支持快速的建表等 DDL 操作。平臺數(shù)據(jù)指標多,例如 We 分析平臺數(shù)據(jù)指標近千個。不同的場景主題指標一般會分別進行計算,寫入到不同的在線存儲數(shù)據(jù)表中,所以這需要具備快速 DDL 及高效出庫數(shù)據(jù)的能力。
- 讀取:包括查詢性能、讀取接口是否簡單靈活、開發(fā)是否簡單;以及相關運維配套設施是否完善,如監(jiān)控告警、擴容、權限、輔助優(yōu)化等。
從上圖和 Datacube / FeatureKV / HBase 的對比可以發(fā)現(xiàn) TDSQL 更符合此業(yè)務訴求、更具備優(yōu)勢。
因此 We 分析平臺基本所有的預計算結果數(shù)據(jù),最終選用 TDSQL 來存儲離線預計算結果數(shù)據(jù),關于 TDSQL 的幾個關鍵點如下:
- 存儲容量:We 畫像分析系統(tǒng)采用的 TDSQL 服務中,當前支持最大 64 個分片,每個分片最大 3 T ,單個實例最大能支持存儲 192 T 的數(shù)據(jù)。
- 數(shù)據(jù)出庫:通過數(shù)平 US 上的出庫組件可以完成數(shù)據(jù)從 TDW 直接出庫到 TDSQL ,近 1 億數(shù)據(jù)量可以在 40 min + 完成出庫,出庫組件的監(jiān)控及日志完善。
- 查詢性能:2 個分片,8 核 32 G 進行測試,查詢某小程序一段時間數(shù)據(jù),查詢 QPS 5 W。
- 讀取方式:通過 jdbc 連接查詢,拼接不同 sql 進行查詢,查詢方式簡單靈活。
- 運維方面:實例申請 、 賬號設置 、 監(jiān)控告警 、 擴容和慢查詢分析等能力,都可以開發(fā)自助在云控制臺完成。
- 開發(fā)效率:DDL 操作簡單,數(shù)據(jù)開發(fā)從建表到出庫基本沒有學習成本,問題定位簡單高效。
當前整個平臺的預計算數(shù)據(jù)出庫到 TDSQL 的數(shù)據(jù)達到十億級別,數(shù)據(jù)表超百張,實際使用存儲上百 T 。TDSQL 整體功能較為全面,開發(fā)者僅需要補充開發(fā)數(shù)據(jù)生命周期管理工具,刪除方式的注意點跟 MySQL 一樣。如果采用 KV 類型的引擎進行存儲,需要根據(jù) KV 的特性合理設計存儲 Key 。在查詢端對 Key 進行拼接組裝,發(fā)送 BatchGet 請求進行查詢。整個過程開發(fā)邏輯會相對繁復些, 需要更加注重 Key 的設計。若要實現(xiàn)一個只有概要數(shù)據(jù)的趨勢圖,那么存儲的 Key 需要設計成類似格式:{日期} # {小程序} # {指標類型} 。
4.1 功能描述
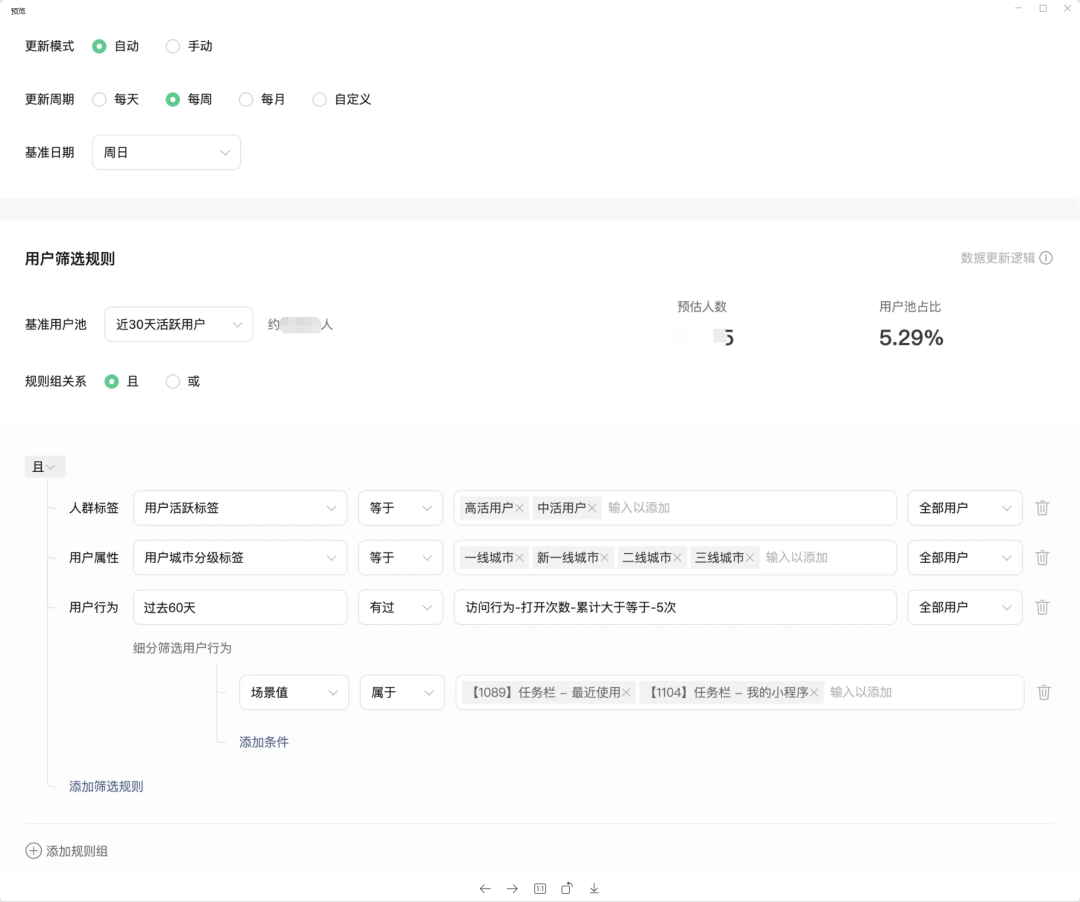
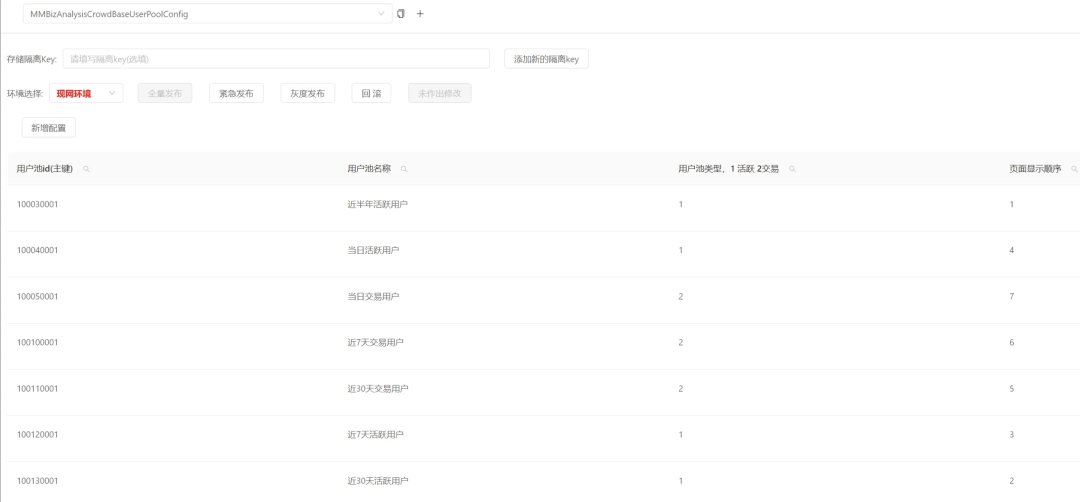
該模塊主要提供自定義的用戶分群能力。用戶分群依據(jù)用戶的屬性及行為特征將用戶群體進行分類,以便使用者對其進行觀察分析及應用。自定義的用戶分群能夠滿足中頭部客戶的個性化分析運營需求,例如客戶想看上次 618 參加了某活動的用戶人群,在接下來的活躍交易趨勢跟大盤的差異對比;或者客戶想驗證對比某些人群對優(yōu)惠券的敏感程度、圈選人群后通過 AB 實驗進行驗證。上述類似的應用會非常多。在功能設計上,平臺需要做到數(shù)據(jù)豐富、規(guī)則靈活、查詢快速,需要支持豐富的人群圈選數(shù)據(jù),并且預置標簽、人群標簽、平臺行為、自定義上報行為等。支持靈活的標簽及人群創(chuàng)建方式,讓客戶能按照自己的想法任意圈選出想要的人群,按不同周期手動或自動選出人群包,支持人群的跟蹤分析、人群在多場景的應用能力。 4.2 人群包實時預估
人群包實時預估是根據(jù)使用者客戶定義的規(guī)則,計算出當前規(guī)則下有多少用戶命中了該規(guī)則。產(chǎn)品交互通常如下所示: 4.2.1 數(shù)據(jù)加工
為了滿足客戶能隨意根據(jù)自己的想法圈出想要的人群,平臺支持豐富的數(shù)據(jù)源。整體畫像的數(shù)據(jù)量較大,其中預置的標簽畫像在離線 HDFS 上的豎表存儲達近萬億/天,平臺行為百億級/天,且維度細,自定義上報行為百億級/天。怎么設計能節(jié)省存儲同時加速查詢是重點考慮的問題之一。大體的思路是:對預置標簽畫像轉成 Bitmap 進行壓縮存儲,對平臺行為明細進行預聚合及對維度枚舉值進行 ID 自增編碼,字符串轉成數(shù)據(jù)整型節(jié)省存儲空間。同時在產(chǎn)品層面增加啟用按鈕,開通后導入近期數(shù)據(jù),從而控制存儲消耗,具體細節(jié)如下。屬性標簽數(shù)據(jù)通常建設用戶畫像的核心工作就是給用戶打標簽,標簽是人為規(guī)定的高度精煉的特征標識,如性別、年齡、地域、興趣,也可以是用戶的一些行為集合。這些標簽集合抽象出一個用戶的信息全貌,每個標簽分別描述該用戶的一個維度,各標簽維度間相互聯(lián)系,構成對用戶的整體描述。當前的用戶屬性及人群標簽是由平臺方提供,由平臺每天進行統(tǒng)一的加工處理生成官方標簽。平臺暫時沒有支持用戶自定義的標簽,因此這里主要說明平臺標簽是如何計算加工管理。
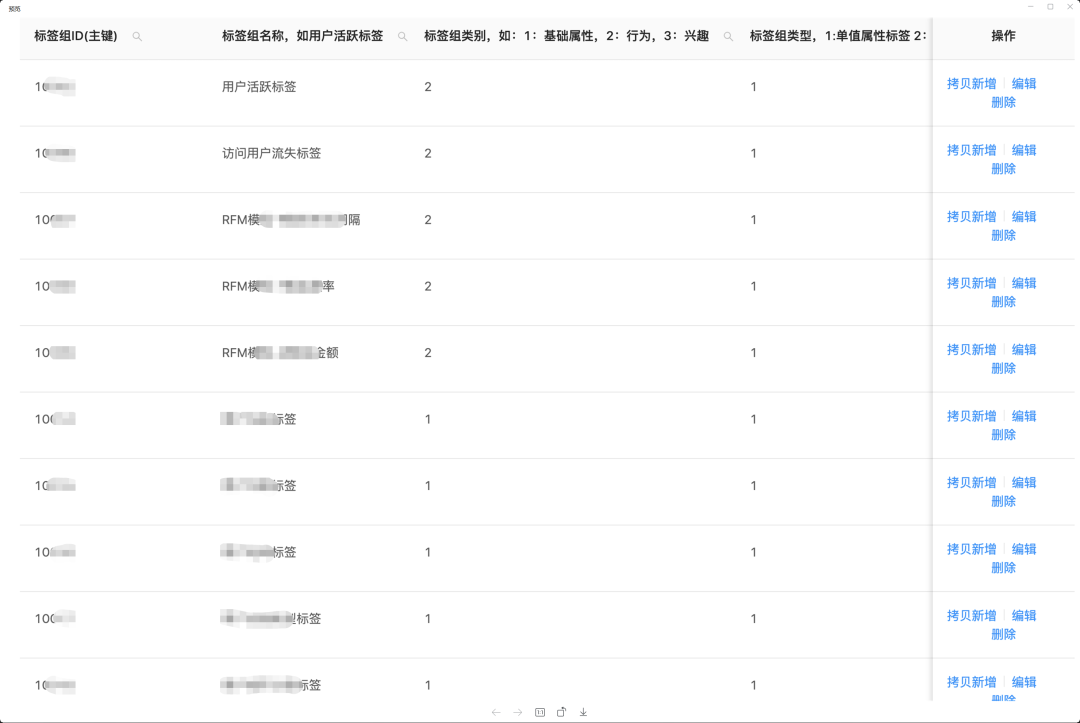
例如活躍標簽 10002 ,對標簽的每個標簽值進行編碼如下:對特定人群進行編碼,基準人群是作為必選的過濾條件,用于限定用戶的范圍:標簽數(shù)據(jù)在離線的存儲上,采用豎表的存儲方式。表結構如下所示,標簽之間可以并行構建相互獨立不影響。采用豎表的結構設計,好處是不需要開發(fā)畫像大寬表,即使任務出現(xiàn)異常延時也不會影響到其它標簽的產(chǎn)出。而畫像大寬表需要等待所有畫像標簽均完成后才能開始執(zhí)行該寬表數(shù)據(jù)的生成,會導致數(shù)據(jù)的延時風險增大。當需要新增或刪除標簽時,需要修改表結構。因此,在線的存儲引擎是否支持與離線豎表模式相匹配的存儲結構,成為很重要的考量點。采用大寬表方式的存儲如 Elasticsearch 和 Hermes 存儲,等待全部需要線上用到的畫像標簽在離線計算環(huán)節(jié)加工完成才能開始入庫。而像 ClickHouse 、Doris 則可以采用與豎表相對應的表結構,標簽加工完成就可以馬上出庫到線上集群,從而減小因為一個標簽的延時而導致整體延時的風險。CREATE TABLE table_xxx(
ds BIGINT COMMENT '數(shù)據(jù)日期',
label_name STRING COMMENT '標簽名稱',
label_id BIGINT COMMENT '標簽id',
appid STRING COMMENT '小程序appid',
useruin BIGINT COMMENT 'useruin',
tag_name STRING COMMENT 'tag名稱',
tag_id BIGINT COMMENT 'tag id',
tag_value BIGINT COMMENT 'tag權重值'
)
PARTITION BY LIST( ds )
SUBPARTITION BY LIST( label_name )(
SUBPARTITION sp_xxx VALUES IN ( 'xxx' ),
SUBPARTITION sp_xxxx VALUES IN ( 'xxxx' )
)
如果把標簽理解成對用戶的分群,那么符合某個標簽的某個取值的所有用戶 ID(UInt類型) 就構成了一個個的人群。Bitmap 是用于存儲標簽-用戶的映射關系的、非常理想的數(shù)據(jù)結構,最終需要的是構建出每個標簽的每個取值所對應的 Bitmap。例如性別這個標簽組,背后對應的是男性用戶群和女性用戶群。性別標簽:男 -> 男性用戶人群包,女 →女性用戶人群包。平臺行為數(shù)據(jù)是指官方進行上報的行為數(shù)據(jù),例如訪問、分享等行為數(shù)據(jù),使用者不需要進行任何埋點等操作。團隊主要是會對平臺行為進行預聚合,計算同一維度下的 PV 數(shù)據(jù),已減少后續(xù)數(shù)據(jù)的存儲及計算量。
同時會對維度枚舉值進行 ID 自增編碼,目的是減少存儲占用,寫入以及讀取性能;從效果來看,團隊對可枚舉類型進行字典 ID 編碼對比原本字符類型能節(jié)省60%的線上存儲空間,同時相同數(shù)據(jù)量條件下帶來 2 倍查詢速度提升。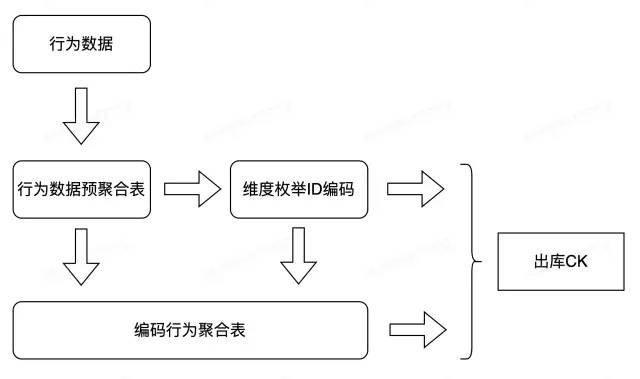
自定義上報數(shù)據(jù)是使用者自己埋點進行數(shù)據(jù)的上報,上報的內(nèi)容包括公共參數(shù)及自定義內(nèi)容,其中自定義內(nèi)容是 key-value 的格式,在 OLAP 引擎中,團隊會將客戶自定義的內(nèi)容轉成 map 結構類型進行存儲。
4.2.2 數(shù)據(jù)寫入存儲
首先講下,在線 OLAP 存儲選型。標簽及行為明細數(shù)據(jù)的存儲引擎選型對于畫像系統(tǒng)至關重要,不同的存儲引擎決定了系統(tǒng)不同的設計方式。業(yè)務團隊調(diào)研了解到,行業(yè)內(nèi)建設畫像系統(tǒng)時有多種不同的存儲方案。團隊對常用的畫像 OLAP 引擎做了對比,如下:
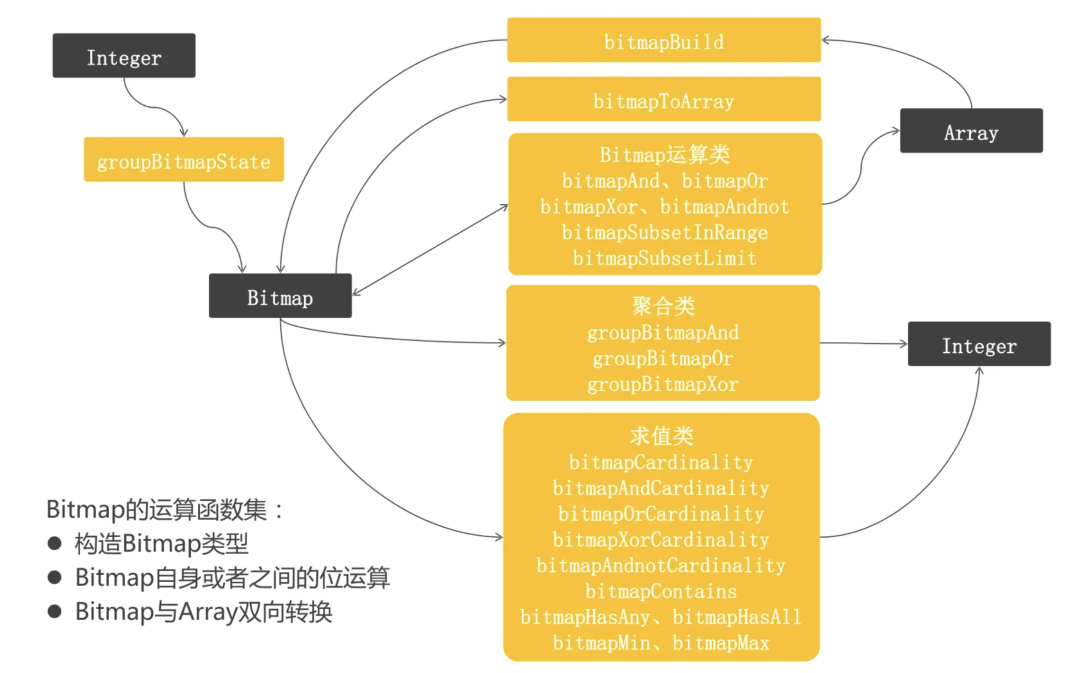
綜合上述調(diào)研,團隊采用 ClickHouse 作為畫像數(shù)據(jù)存儲引擎。在 ClickHouse 中使用 RoaringBitmap 作為 Bitmap 的解決方案。該方案支持豐富的 Bitmap 操作函數(shù),可以十分靈活方便的判重和進行基數(shù)統(tǒng)計操作,如下所示。采用 RoaringBitmap(RBM) 對稀疏位圖進行壓縮,可以減少內(nèi)存占用并提高效率。該方案的核心思路是,將 32 位無符號整數(shù)按照高 16 位分桶,即最多可能有 216=65536 個桶,稱為 container。存儲數(shù)據(jù)時,按照數(shù)據(jù)的高 16 位找到 container (找不到則會新建一個),再將低 16 位放入 container 中。也就是說,一個 RBM 就是很多 container 的集合,具體參考高效壓縮位圖 RoaringBitmap 的原理與應用。接下來講講,數(shù)據(jù)導入線上存儲。在確定了采用什么存儲引擎存儲線上數(shù)據(jù)后,團隊需要將離線集群的數(shù)據(jù)導入到線上存儲。其中對于標簽數(shù)據(jù)通常的做法是將原始明細的 id 數(shù)據(jù)直接導入到 ClickHouse 表中,再通過創(chuàng)建物化視圖的方式構建 RBM 結構進行使用。
然而,業(yè)務明細數(shù)據(jù)非常大,每天近萬億。這樣的導入方式給 ClickHouse 集群帶來了很大資源開銷。而通常業(yè)務團隊處理大規(guī)模數(shù)據(jù)都是用 Spark 這樣的離線計算框架來完成處理。最后團隊把預處理工作全部交給了 Spark 框架,這種方式大大的減少了寫入的數(shù)據(jù)量,同時也減少了 ClickHosue 集群的處理壓力。
具體步驟是 Spark 任務首先會按照 id 進行分片處理,然后對每個分片中標簽的每個標簽值生成一個 Bitmap ,保證定制的序列化方式與 ClickHouse 中的 RBM 兼容。其中通過 Spark 處理后的 Bitmap 轉成 string 類型,然后寫入到線上的標簽表中,在表中業(yè)務團隊定義了一個物化列字段,用于實際存儲 Bitmap。在寫入過程中會將序列化后的 Bitmap 字符串通過 base64Decode 函數(shù)轉成 ClickHouse 中的 AggregateFunction (groupBitmap, UInt32) 數(shù)據(jù)結構。CREATE TABLE xxxxx_table_local on CLUSTER xxx
(
`ds` UInt32,
`appid` String,
`label_group_id` UInt64,
`label_id` UInt64,
`bucket_num` UInt32,
`base64rbm` String,
`rbm` AggregateFunction(groupBitmap, UInt32) MATERIALIZED base64Decode(base64rbm)
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/xxx_table_local', '{replica}')
PARTITION BY toYYYYMMDD(toDateTime(ds))
ORDER BY (appid, label_group_id, label_id)
TTL toDate(ds) + toIntervalDay(5)
SETTINGS index_granularity = 16
值得關注的還有存儲占用問題。標簽類型數(shù)據(jù)用 Bitmap 類型存儲,平臺行為采用編碼方式存儲,存儲占用大幅減少。
4.2.3 數(shù)據(jù)查詢
數(shù)據(jù)查詢方式:人群圈選過程中,如何保障大的APP查詢、在復雜規(guī)則情況下的查詢速度?團隊在導入過程中對預置畫像、平臺行為、自定義上報行為,均按相同分桶規(guī)則導入集群。這保證一個用戶僅會在同一臺機器,查詢時始終進行本地表查詢,避免進行分布式表查詢。
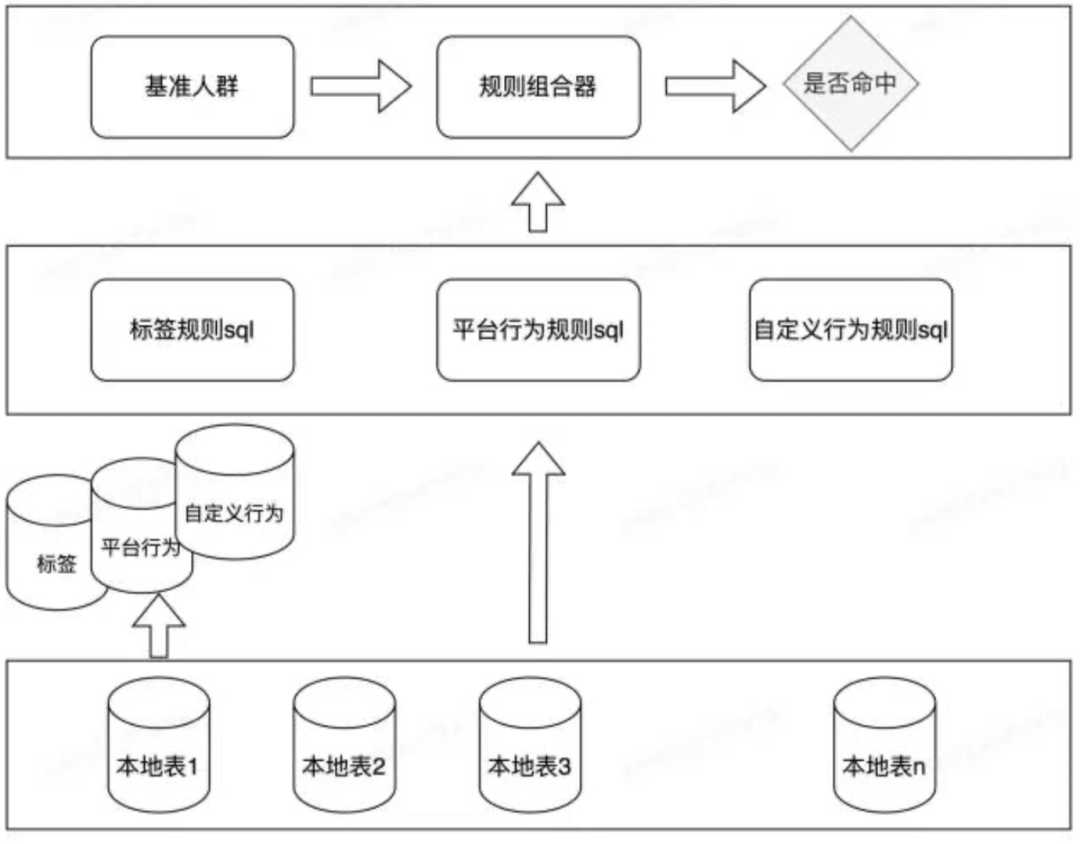
對于查詢性能的保障,團隊始終保證所有查詢均在本地表完成。上面已經(jīng)介紹到數(shù)據(jù)在入庫時,均會按照相同用戶 ID 的 hash 分桶規(guī)則出庫到相應的機器節(jié)點中。使用維度數(shù)字編碼,測試數(shù)字編碼后對比字符方式查詢性能有2倍以上提升。對標簽對應的人群轉成 Bitmap 方式處理,用戶的不同規(guī)則到最后都會轉成針 Bitmap 的交并差補集操作。對于平臺行為,如果在用戶用模糊匹配的情況下,會先查詢維度 ID 映射表,將用戶可見維度轉化成維度編碼 ID,后通過編碼 ID 及規(guī)則構建查詢 SQL。整個查詢的核心邏輯是根據(jù)圈選規(guī)則組合不同查詢語句,然后將不同子查詢通過規(guī)則組合器最終判斷該用戶是否命中人群規(guī)則。基于rpc開發(fā)服務接口:查詢的服務接口采用 rpc 框架進行開發(fā)。在數(shù)據(jù)服務的上一層是團隊的數(shù)據(jù)中間件,統(tǒng)一做了流量控制、異步調(diào)用、調(diào)用監(jiān)控及參數(shù)安全校驗,特別是針對用戶量較大的 app 在多規(guī)則查詢時,耗時較大,因此業(yè)務團隊配置了細粒度的流量控制,保障查詢請求的有序及服務的穩(wěn)定可用。查詢性能數(shù)據(jù):不同 DAU 等級小程序查詢性能。
從性能數(shù)據(jù)看,對用戶量大的 app 來說,在規(guī)則非常多的情況下還是要大幾十秒,等待這么長時間體驗不佳。因此對于這部分用戶量大的 app,業(yè)務團隊采用的策略是抽樣。通過抽樣,速度能得到非常大的提升,并且預估的準確率誤差不大,在可接受的范圍內(nèi)。 4.3 人群創(chuàng)建
4.3.1 人群實時創(chuàng)建
人群包實時創(chuàng)建類似上面描述的人群大小實時預估,區(qū)別是在最后人群創(chuàng)建是需要將圈選的人群包用戶明細寫入到存儲中,然后返回人群包的大小給到用戶。同樣是在本地表執(zhí)行,生成的人群包寫入到同一臺機器中,保持分桶規(guī)則的一致。 4.3.2 人群例行化創(chuàng)建
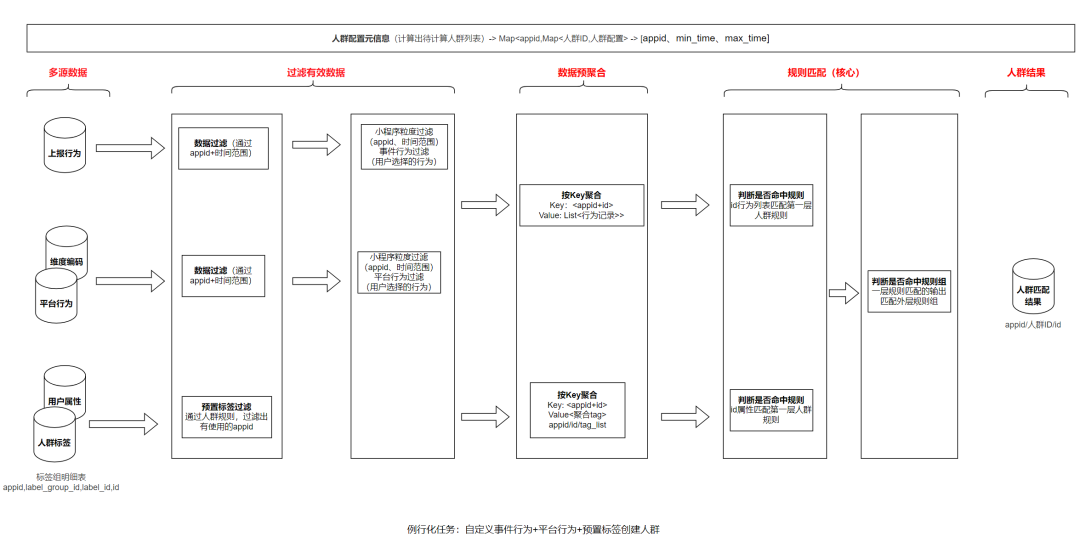
客戶創(chuàng)建的例行化人群包,需要每天計算。如何持續(xù)跟蹤分析趨勢,并且不會對集群造成過大的計算壓力?團隊的做法利用離線超大規(guī)模計算的能力,在凌晨啟動所有人群計算任務,從而減小對線上 ClickHouse 集群的計算壓力。所有小程序客戶創(chuàng)建的例行化人群包計算集中到凌晨的一個任務中進行,做到讀一次數(shù)據(jù),計算完成所有人群包,最大限度節(jié)省計算資源,詳細的設計如下:首先,團隊會先將全量的數(shù)據(jù)(標簽屬性數(shù)據(jù)+行為數(shù)據(jù))按照小程序粒度及選擇的時間范圍進行過濾,保留有效的數(shù)據(jù);其次,對數(shù)據(jù)進行預聚合處理,將用戶在一段時間范圍的行為數(shù)據(jù),標簽屬性鏡像數(shù)據(jù)按照小程序的用戶粒度進行聚合處理,最終的數(shù)據(jù)將會是對于每個小程序的一個用戶僅會有一行數(shù)據(jù);那么人群包計算,實際上就是看這個用戶在某個時間范圍內(nèi)所產(chǎn)生的行為、標簽屬性特征是否滿足客戶定義的人群包規(guī)則;最后,對數(shù)據(jù)按用戶粒度聚合后進行復雜的規(guī)則匹配,核心是拿到一個用戶某段時間的行為及人群標簽屬性,判斷這個用戶滿足了用戶定義的哪幾個人群包規(guī)則,滿足則屬于該人群包的用戶。 4.4 人群跟蹤應用
4.4.1 人群跟蹤分析
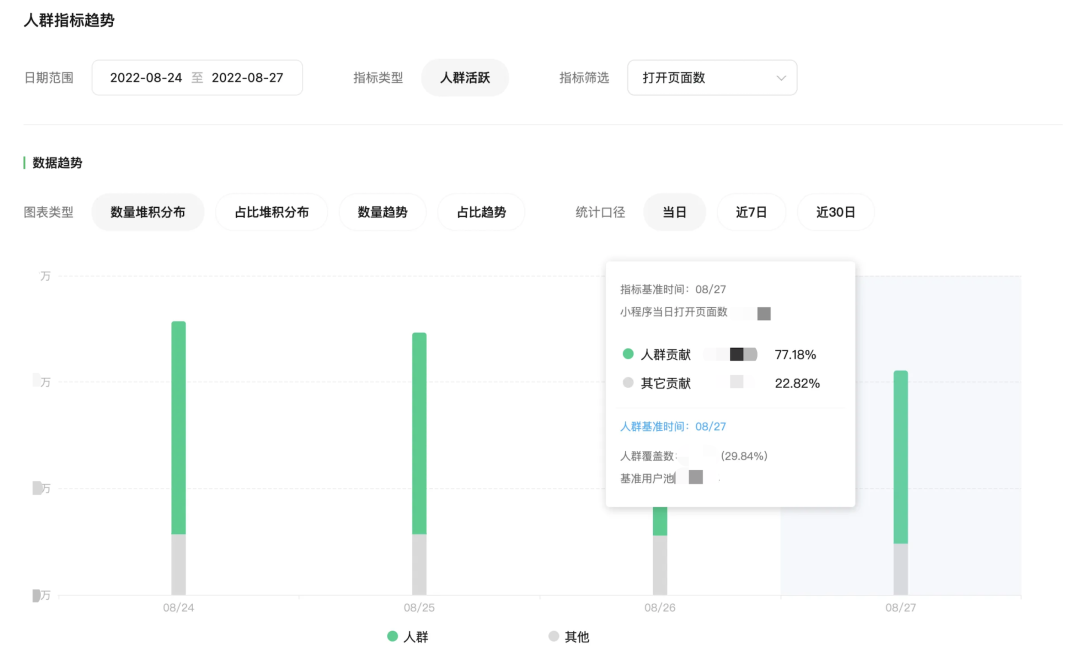
在按照用戶規(guī)則圈選出人群后,統(tǒng)一對人群進行常用指標(如活躍、交易等指標)的跟蹤。整個過程用離線任務進行處理,會從在線存儲中導出實時生成的人群包,以及離線批量生成的定時人群包,匯總一起,后關聯(lián)對應指標表,輸出到線上 OLTP 存儲進行在線的查詢分析。其中,導出在線人群包會在凌晨空閑時間進行,通過將人群 RBM 轉成用戶明細 ID。具體方法為:arrayJoin(bitmapToArray(groupBitmapMergeState(rbm)))。 4.4.2 人群基礎分析
人群基礎分析對一個自定義的用戶分群進行基礎標簽的分析,如該人群的省份、城市、交易等標簽分布。人群行為分析,分析該人群不同的事件行為等。 4.4.3 實驗人群定向
在 AB 實驗中的人群實驗,使用者通過規(guī)則圈選出指定人群作為實驗組(如想驗證某地區(qū)的符合某條件的人群是否更喜歡參與該活動),跟對照組做相應指標的對比,以便驗證假設。本篇回顧了 We 畫像分析系統(tǒng)各模塊的設計思路。在基礎模塊中,業(yè)務團隊根據(jù)功能特性,選用了騰訊云 TDSQL 作為在線數(shù)據(jù)的存儲引擎,將所有預計算數(shù)據(jù)都使用 TDSQL 進行存儲。在人群分析模塊中,為了實現(xiàn)靈活的人群創(chuàng)建、分析及應用,業(yè)務團隊使用 ClickHouse 作為畫像數(shù)據(jù)的存儲引擎,根據(jù)該存儲的特性進行上層服務的開發(fā),以達到最優(yōu)的性能。后續(xù),小程序 We 畫像分析系統(tǒng)在產(chǎn)品能力上會持續(xù)豐富功能及體驗,同時擴展更多的應用場景。以上是 We 畫像分析系統(tǒng)模塊設計與實現(xiàn)思路的全部內(nèi)容,歡迎感興趣的讀者在評論區(qū)交流。