
變分自編碼器(VAEs)在推薦系統(tǒng)中的應(yīng)用
「本文概覽」
今天給大家介紹一篇VAEs用于推薦系統(tǒng)召回側(cè)的文章,論文題目為《Variational Autoencoders for Collaborative Filtering》。VAEs (Variational Autoencoders 變分自編碼器) 是一類基于變分推斷和 Encoder-Decoder 結(jié)構(gòu)的生成式模型。這一類模型具有較強(qiáng)的表征能力,其 latent space 的性質(zhì)也讓 VAEs 在很多下游任務(wù)中有較好的應(yīng)用。本文是VAEs模型在協(xié)同過濾中的使用,非線性的概率模型大大提升生了模型的表征能力。
引用:Liang D, Krishnan R G, Hoffman M D, et al. Variational autoencoders for collaborative filtering[C]//Proceedings of the 2018 world wide web conference. 2018: 689-698. 論文下載地址:https://dl.acm.org/doi/pdf/10.1145/3178876.3186150 論文源碼:https://github.com/dawenl/vae_cf
1. 背景知識(shí)
1.1 AutoEncoder(AE)
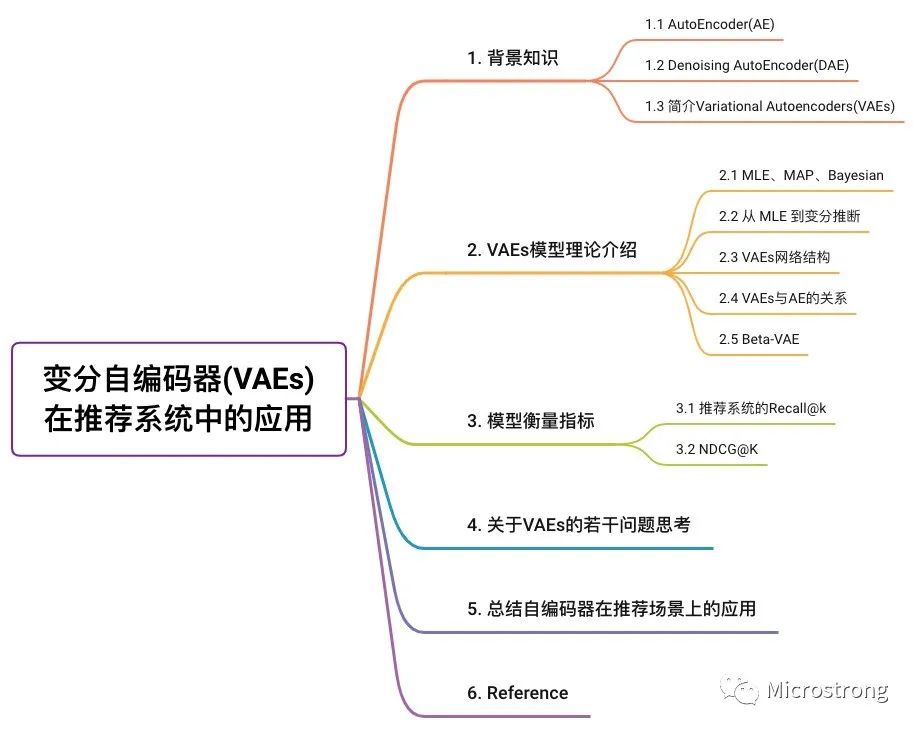
如下圖所示,AutoEncoder框架包含兩大模塊:編碼過程和解碼過程。通過 encoder(g) 將輸入樣本 映射到特征空間 ,即編碼過程;然后再通過 decoder(f) 將抽象特征 映射回原始空間得到重構(gòu)樣本 ,即解碼過程。優(yōu)化目標(biāo)則是通過最小化重構(gòu)誤差來同時(shí)優(yōu)化encoder和decoder,從而學(xué)習(xí)得到針對輸入樣本 的抽象特征表示 。
這里我們可以看到,AutoEncoder在優(yōu)化過程中無需使用樣本的label,本質(zhì)上是把樣本的輸入同時(shí)作為神經(jīng)網(wǎng)絡(luò)的輸入和輸出,通過最小化重構(gòu)誤差希望學(xué)習(xí)到樣本的抽象特征表示 。這種無監(jiān)督的優(yōu)化方式大大提升了模型的通用性。
對于基于神經(jīng)網(wǎng)絡(luò)的AutoEncoder模型來說,則是encoder部分通過逐層降低神經(jīng)元個(gè)數(shù)來對數(shù)據(jù)進(jìn)行壓縮;decoder部分基于數(shù)據(jù)的抽象表示逐層提升神經(jīng)元數(shù)量,最終實(shí)現(xiàn)對輸入樣本的重構(gòu)。
這里值得注意的是,由于AutoEncoder通過神經(jīng)網(wǎng)絡(luò)來學(xué)習(xí)每個(gè)樣本的唯一抽象表示,這會(huì)帶來一個(gè)問題:當(dāng)神經(jīng)網(wǎng)絡(luò)的參數(shù)復(fù)雜到一定程度時(shí)AutoEncoder很容易存在過擬合的風(fēng)險(xiǎn)。
1.2 Denoising AutoEncoder(DAE)
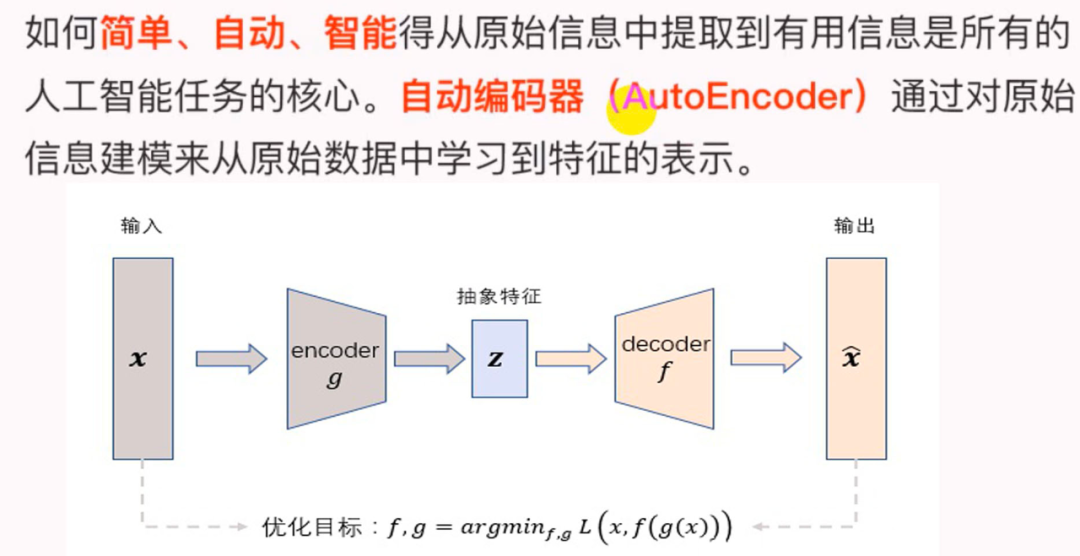
為了緩解經(jīng)典AutoEncoder容易過擬合的問題,一個(gè)辦法是在輸入中加入隨機(jī)噪聲,Vincent等人提出了Denoising AutoEncoder,即在傳統(tǒng)AutoEncoder輸入層加入隨機(jī)噪聲來增強(qiáng)模型的魯棒性;另一個(gè)辦法就是結(jié)合正則化思想,Rifai等人提出了Contractive AutoEncoder,通過在AutoEncoder目標(biāo)函數(shù)中加上Encoder的Jacobian矩陣范式來約束使得Encoder能夠?qū)W到具有抗干擾的抽象特征。
下圖是Denoising AutoEncoder的模型框架。目前添加噪聲的方式大多分為兩種:
添加服從特定分布的隨機(jī)噪聲; 隨機(jī)將輸入 中特定比例的數(shù)值置為0;
DAE模型的優(yōu)勢:
通過與非破損數(shù)據(jù)訓(xùn)練的對比,破損數(shù)據(jù)訓(xùn)練出來的Weight噪聲較小。因?yàn)椴脸龜?shù)據(jù)的時(shí)候不小心把輸入噪聲給擦掉了。 破損數(shù)據(jù)一定程度上減輕了訓(xùn)練數(shù)據(jù)與測試數(shù)據(jù)的代溝。由于數(shù)據(jù)的部分被擦掉了,因而這破損數(shù)據(jù)一定程度上比較接近測試數(shù)據(jù)。
1.3 簡介Variational Autoencoders(VAEs)
變分自編碼器是自動(dòng)編碼器的升級版本,其結(jié)構(gòu)跟自動(dòng)編碼器是類似的,也由編碼器和解碼器構(gòu)成。
在自動(dòng)編碼器中,我們需要輸入一張圖片,然后將一張圖片編碼之后得到一個(gè)隱含向量,這個(gè)隱含向量比我們隨機(jī)取一個(gè)隨機(jī)噪聲更好,因?yàn)樗瓐D片的信息,然后我們把隱含向量解碼得到與原圖片對應(yīng)的照片。
但是這樣我們并不能任意生成圖片,因?yàn)闆]有辦法自己去構(gòu)造隱含向量,需要通過一張圖片輸入編碼,才知道得到的隱含向量是什么。這時(shí)我們就可以通過變分自編碼器來解決這個(gè)問題。
其實(shí)原理特別簡單,只需要在編碼的過程中給它增加一些限制,迫使其生成的隱含向量能夠粗略的遵循一個(gè)標(biāo)準(zhǔn)正態(tài)分布,這就是其與一般的自動(dòng)編碼器最大的不同。
這樣我們生成一張新圖片就很簡單了,只需要給它一個(gè)標(biāo)準(zhǔn)正態(tài)分布的隨機(jī)隱含向量,這樣通過解碼器就能夠生成我們想要的圖片,而不需要給它一張?jiān)紙D片先編碼。
在實(shí)際情況中,我們需要在模型的準(zhǔn)確率上與隱含向量服從標(biāo)準(zhǔn)正態(tài)分布之間做一個(gè)權(quán)衡。所謂模型的準(zhǔn)確率就是指解碼器生成的圖片與原圖片的相似程度。另外要衡量兩種分布的相似程度,有一個(gè)東西叫KL divergence來衡量兩種分布的相似程度,這里我們就是用KL divergence來表示隱含向量與標(biāo)準(zhǔn)正態(tài)分布之間差異的loss。我們讓網(wǎng)絡(luò)自己來做決定如何權(quán)衡,非常簡單,我們只需要將這兩者分別作為loss,然后再將它們求和作為總的loss,這樣網(wǎng)絡(luò)就能夠自己選擇如何才能夠使得這個(gè)總的loss下降。
KL divergence 的公式如下:
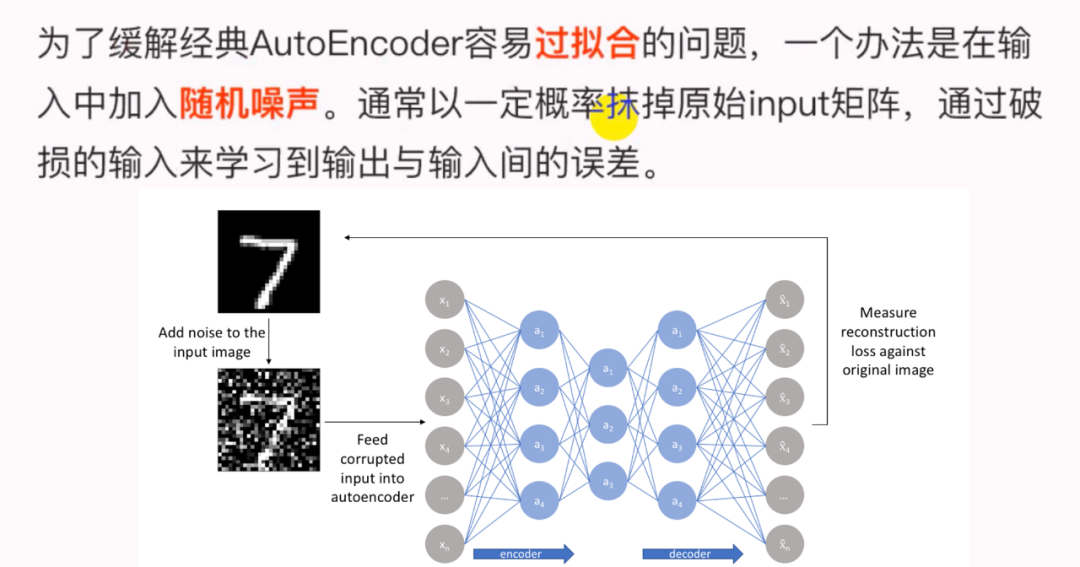
這里變分自編碼器使用了一個(gè)技巧 「“重新參數(shù)化(reparameterization)”」 來解決KL divergence的計(jì)算問題。
這時(shí)不再是每次產(chǎn)生一個(gè)隱含向量,而是生成兩個(gè)向量,一個(gè)表示均值 ,一個(gè)表示標(biāo)準(zhǔn)差 ,然后通過這兩個(gè)統(tǒng)計(jì)量來合成隱含向量 ,這也非常簡單,用一個(gè)標(biāo)準(zhǔn)正態(tài)分布 先乘上標(biāo)準(zhǔn)差再加上均值就行了,這里我們默認(rèn)編碼之后的隱含向量是服從一個(gè)正態(tài)分布的。這個(gè)時(shí)候我們是想讓均值盡可能接近0,標(biāo)準(zhǔn)差盡可能接近1。
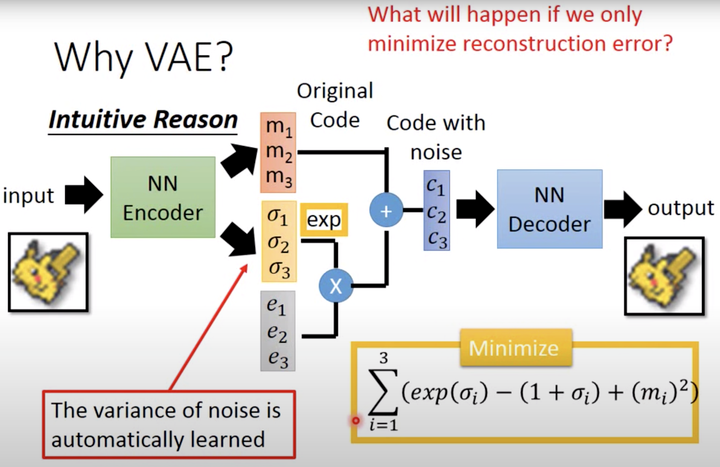
VAE通過Encoder學(xué)習(xí)出均值向量和方差向量(貝葉斯估計(jì))。同時(shí)隨機(jī)采樣一個(gè)正態(tài)分布的向量 。通過 公式重采樣得到 (Sampled Latent Vector),它描述的是一個(gè)潛在多元正態(tài)分布(非高斯)的均值和標(biāo)準(zhǔn)差,這個(gè)正態(tài)分布就是用來生成VAE所訓(xùn)練的數(shù)據(jù)。最后通過Decoder進(jìn)行重建。損失函數(shù)是Decoder后的輸出與初始輸入的差異,以及學(xué)習(xí)后的潛在分布和先驗(yàn)分布之間的KL散度作為正則化, 的重參數(shù)技巧。
「【強(qiáng)烈推薦閱讀】」
關(guān)于VAE的理論推導(dǎo)有點(diǎn)晦澀難懂,推薦大家觀看學(xué)習(xí)李宏毅老師的教程視頻。 關(guān)于李宏毅老師講解的VAE視頻Part1地址:https://www.youtube.com/watch?v=YNUek8ioAJk&ab_channel=Hung-yiLee 關(guān)于李宏毅老師講解的VAE視頻Part2地址:https://www.youtube.com/watch?v=8zomhgKrsmQ&ab_channel=Hung-yiLee 李宏毅老師講解slides地址:http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2017/Lecture/GAN%20(v3).pdf
2. VAEs模型理論介紹
近年的工作,如《Neural collaborative filtering》、《Autorec: Autoencoders meet collaborative filtering》等將神經(jīng)網(wǎng)絡(luò)應(yīng)用于協(xié)同過濾并取得了理想的結(jié)果。該論文將變分自編碼器(Variational Autoencoders,VAEs)擴(kuò)展到協(xié)同過濾。下面我們詳細(xì)介紹一下VAEs模型的原理。
這一部分主要是介紹了變分自編碼器 (VAEs) 的理論基礎(chǔ),以下部分內(nèi)容參考了變分自編碼器 (VAE) Overview - Zhifeng的文章 - 知乎 https://zhuanlan.zhihu.com/p/420419446
2.1 MLE、MAP、Bayesian
首先要明確這三個(gè)概念。
MLE是極大似然估計(jì)Maximum Likelihood Estimation。其目標(biāo)為求解:
MAP是最大后驗(yàn)概率Maximum A Posteriori Estimation。其目標(biāo)是求解:
這兩者的區(qū)別就是在于求解最優(yōu)參數(shù)時(shí),有沒有加入先驗(yàn)知識(shí) 。也就是MAP融入了要估計(jì)量 的先驗(yàn)分布在其中,因此MAP可以看做規(guī)則化的MLE。這也就解釋了,為什么MLE比MAP更容易過擬合。因?yàn)镸LE在求解最優(yōu) 時(shí),沒有對 有先驗(yàn)的指導(dǎo),因此 中包括了一些 的數(shù)據(jù)樣本時(shí),就會(huì)很輕易讓MLE去擬合 樣本。而MAP加入了對 的先驗(yàn)指導(dǎo),例如L2正則化,那么就不易過擬合了。
舉個(gè)例子,同樣的邏輯回歸。
未正則化的邏輯回歸就是MLE。 正則化的邏輯回歸就是MAP。
那么,與上述兩個(gè)概念都不同的是貝葉斯模型(Bayesian Network),也被稱為概率圖模型。這里不是指樸素貝葉斯。而是說下面的這種學(xué)習(xí)思路。
MLE和MAP求解的都是一個(gè)最優(yōu)的 值,在預(yù)測時(shí)只有最優(yōu)的 參與預(yù)測過程。貝葉斯模型求解的是 的后驗(yàn)分布 ,而不是最大化的后驗(yàn)分布。因此貝葉斯模型在某種程度上可以看作是一個(gè)集成模型,在預(yù)測時(shí),讓所有 都參與預(yù)測,并將預(yù)測結(jié)果「以后驗(yàn)概率 作為權(quán)重進(jìn)行加和作為最終預(yù)測值」。
2.2 從 MLE 到變分推斷
假設(shè)數(shù)據(jù)的真實(shí)分布為 。為了訓(xùn)練一個(gè)生成模型,我們往往通過神經(jīng)網(wǎng)絡(luò) 構(gòu)造一個(gè)復(fù)雜分布 (解碼器) , 并最大化數(shù)據(jù)的 likelihood, 也就是:
但是,實(shí)際復(fù)雜的神經(jīng)網(wǎng)絡(luò)往往在數(shù)據(jù)空間進(jìn)行變換,因此 沒有顯示的密度,直接優(yōu)化 MLE 問題是不可行的。變分推斷 (variational inference) 便是解決上述問題的有力工具。首先,我們引入一個(gè)新的變量稱為 latent distribution (下文簡寫為 , 其維度遠(yuǎn)小于數(shù)據(jù)的維度)。接下來,我們定義另一個(gè)分布 , 其可以是任意的分布。由于:
我們可以將 MLE 的優(yōu)化問題寫成
根據(jù) Jensen's inequality, 我們將 和 位置交換,即:
上式即為經(jīng)驗(yàn)下界 (evidence lower bound, or ELBO)。最后,由于 可以是任意的,我們能夠用一個(gè)神經(jīng)網(wǎng)絡(luò) 去逼近使得 ELBO 最大的 , 即:
其中,可以看作VAEs模型的編碼器。
由于取 的過程類似于數(shù)學(xué)中的變分法(在泛函空間中取極值),因此該方法被稱為變分推斷。
2.3 VAEs網(wǎng)絡(luò)結(jié)構(gòu)
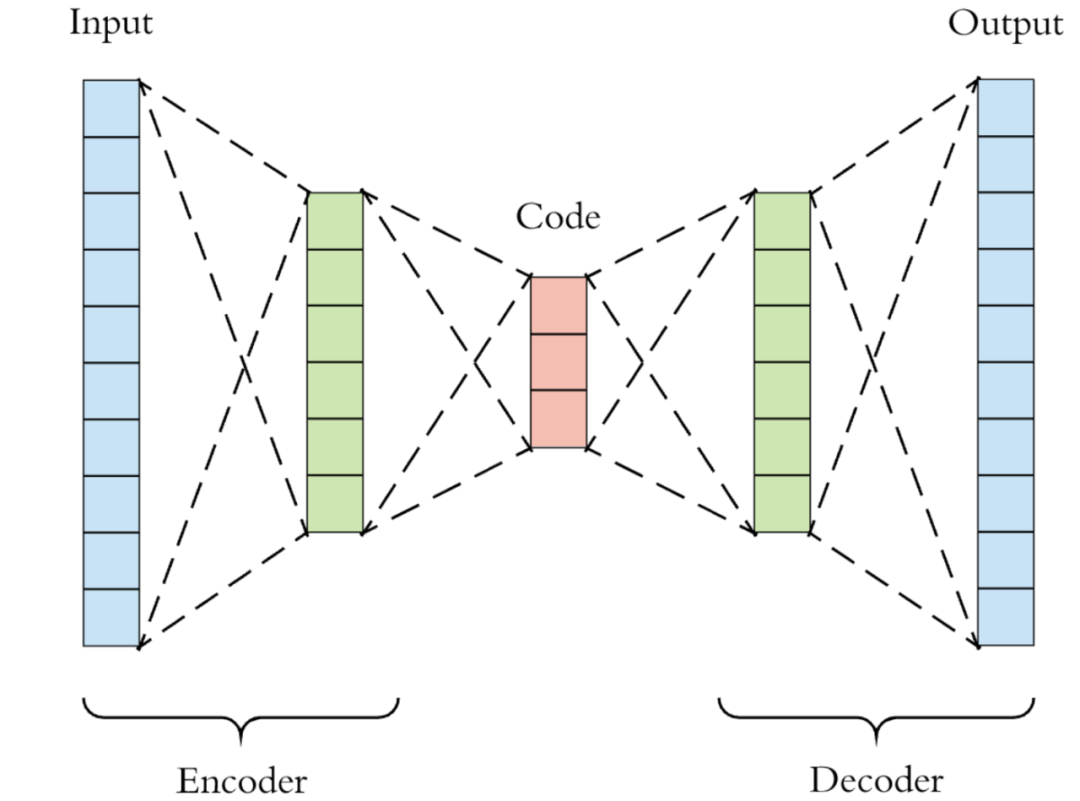
VAEs的網(wǎng)絡(luò)結(jié)構(gòu)和 AutoEncoder(AE)一樣,由兩個(gè)網(wǎng)絡(luò)構(gòu)成,分別是 Encoder 和 Decoder 。非常自然地, 對應(yīng)上述 , 而 對應(yīng)上述 。VAEs只是在 AE 的基礎(chǔ)上用了變分推斷,這也是其名字的由來。下圖是一個(gè)簡單的VAEs示意圖,實(shí)際情況中網(wǎng)絡(luò)結(jié)構(gòu)可能更加復(fù)雜。藍(lán)色分別為輸入和輸出,綠色為 Encoder / Decoder 的中間層,紅色為 Encoder 的輸出,一般是一個(gè)維度很低的向量 (僅限于早期簡單的 VAE),它有不同的名字,比如 code、latent representation、latent vector、embedding或者 bottleneck。
2.4 VAEs與AE的關(guān)系
最原始的 AE 的目標(biāo)函數(shù)是:
其被稱為 reconstruction error, 其目的便是希望 近似于恒等變換,但是 的輸出維度非常小 (可以用矩陣分解 SVD 或者 NMF 來類比)。這看上去與 VAEs 的目標(biāo)函數(shù)完全不同,但實(shí)際上有很強(qiáng)的聯(lián)系。
我們從 VAEs 的 reparameterization 講起。由于直接定義 和 是不現(xiàn)實(shí)的,我們假設(shè)這兩個(gè)分布都是 Gaussian. 我們可以進(jìn)一步簡化,假定 covariance matrix 都是對角矩陣。那么,VAEs 中的 和 只需要輸出 Gaussian distribution 的 mean () 和 covariance matrix () 的對角線即可。在這種情況下, 和 的表達(dá)形式都十分簡單。我們將 ELBO 的第一項(xiàng)寫開:
由于 , 我們有 , 其中 , 就是用一個(gè)標(biāo)準(zhǔn)正態(tài)分布先乘上標(biāo)準(zhǔn)差再加上均值。當(dāng)我們假定 且 很小的時(shí)候,上式與 AE 的目標(biāo)函數(shù)其實(shí)非常類似。而 ELBO 的第二項(xiàng)則可以被視為 regularization term, 使得 與 latent distribution 接近。因此,VAEs 的 ELBO 目標(biāo)函數(shù)常常被理解為 reconstruction error + regularization, 或者說在 AE 的基礎(chǔ)上增加了 regularization.
2.5 Beta-VAE
Beta-VAE 是 VAEs 的簡單推廣,但十分有效。我們剛剛提到 VAEs 在 AE 的基礎(chǔ)上增加了 regularization 從而得到更好的效果,那么我們可以直接增加一個(gè) regularization factor 進(jìn)一步提升效果:
= 1 便對應(yīng)的是原始 VAEs。在實(shí)際任務(wù)中,我們只需要把 當(dāng)作 hyper-parameter 進(jìn)行 fine tune 即可。人們也發(fā)現(xiàn),當(dāng) = 2,4,8 的時(shí)候效果一般會(huì)更好一些,尤其是生成的樣本邊緣更清晰 (sharp)。
當(dāng)然,我們可以從另一個(gè)角度理解 -VAE. 我們從 AE 出發(fā),優(yōu)化 likelihood:
但同時(shí) regularize term:
將上述優(yōu)化問題轉(zhuǎn)化為 Lagrangian multiplier, 我們有
舍棄最后的 項(xiàng),我們便得到了 -VAE 的目標(biāo)函數(shù)。
3. 模型衡量指標(biāo)
3.1 推薦系統(tǒng)的Recall@k
因?yàn)槭请x線計(jì)算的指標(biāo),所以計(jì)算的時(shí)候用模型計(jì)算召回topk,看有多少個(gè)被用戶真實(shí)點(diǎn)擊了,就是表示命中用戶喜歡樣本的比值。
那么這個(gè) 設(shè)置怎樣比較好呢?其實(shí)各有各的好處,比如5–500可能都有,一般會(huì)小的大的都看。如果 比較小,比如recall@5能代表模型的精確度,含義是在召回的top5中命中正樣本的概率,如果明顯精確度提高了,那么這個(gè)指標(biāo)會(huì)提升。如果 比較大,比如recall@500能代表模型的整體效果,可能這個(gè)召回渠道線上每次拉取的都是一個(gè)比較大的結(jié)果,那么在這個(gè)大的結(jié)果中只要能夠命中,都有可能最終被精排模型排出去,所以能代表模型整體召回效果。
「思考這個(gè)問題:Recall@k和線上指標(biāo)是否是正相關(guān)的呢?」
從理論角度分析,假設(shè)只有這一個(gè)召回渠道,那么指標(biāo)就是完全正相關(guān)的。但是線上正常情況不會(huì)這么簡單,可能會(huì)有多個(gè)召回渠道,當(dāng)前召回要經(jīng)過粗排,最終進(jìn)入到精排模型里面的數(shù)目是不確定的,所以如果離線指標(biāo)recall@k從0~線上最大召回都是有提升的,那么就一定是正相關(guān)的,所以可以分區(qū)間多算幾個(gè)看,比如recall@5,recall@10,recall@50,recall@100,recall@500。
3.2 NDCG@K
歸一化折損累計(jì)增益(Normalization discounted cumulative gain)常用于排序任務(wù),NDCG考慮到排序列表中每個(gè)item的評分大小。
「(1)CG@k」
CG(cumulative gain)累計(jì)增益,可用于評價(jià)基于評分的推薦系統(tǒng),列表前 項(xiàng)的計(jì)算過程如下:
這里的 是用戶對第 個(gè)item的評分值。需注意的是CG的計(jì)算并沒有考慮列表中item的順序。
「(2)DCG@k」
DCG(discounted CG)折扣增益的計(jì)算引入了item順序的因素,列表前 項(xiàng)的計(jì)算過程如下:
不難發(fā)現(xiàn),DCG結(jié)果的取值范圍為全體非負(fù)實(shí)數(shù),僅給出一個(gè)DCG的值無法判斷推薦算法的效果。
「(3)NDCG@k」
NDCG將DCG的結(jié)果歸一化到 之間,且越接近于 ,算法的效果越好。NDCG的歸一化系數(shù)是IDCG,即理想的完美DCG。IDCG計(jì)算的是按照用戶評分從高到低排序的列表DCG值。
結(jié)果列表前 項(xiàng)NDCG的計(jì)算過程如下:
4. 關(guān)于VAEs的若干問題思考
4.1 AutoEncoder、DAE和VAE之間的區(qū)別與聯(lián)系?為什么會(huì)有VAE的出現(xiàn)?
由于AutoEncoder通過神經(jīng)網(wǎng)絡(luò)來學(xué)習(xí)每個(gè)樣本的唯一抽象表示,這會(huì)帶來一個(gè)問題:當(dāng)神經(jīng)網(wǎng)絡(luò)的參數(shù)復(fù)雜到一定程度時(shí)AutoEncoder很容易存在過擬合的風(fēng)險(xiǎn)。為了緩解經(jīng)典AutoEncoder容易過擬合的問題,在傳統(tǒng)AutoEncoder輸入層加入隨機(jī)噪聲來增強(qiáng)模型的魯棒性,即降噪自動(dòng)編碼。相比于自編碼器,VAE更傾向于數(shù)據(jù)生成。只要訓(xùn)練好了Decoder,我們就可以從某一個(gè)標(biāo)準(zhǔn)正態(tài)分布生成數(shù)據(jù)作為解碼器Decoder的輸入,來生成類似的、但不完全相同于訓(xùn)練數(shù)據(jù)的新數(shù)據(jù),也許是我們從來沒見過的數(shù)據(jù),作用類似GAN。
4.2 VAE和GAN都是生成式模型,VAE與GAN的區(qū)別與聯(lián)系?
這個(gè)問題,網(wǎng)上有很多答案,這里我給一個(gè)知乎的討論帖子,里面有很多優(yōu)秀的回答:
GAN 和 VAE 的本質(zhì)區(qū)別是什么?為什么兩者總是同時(shí)被提起?- 知乎 https://www.zhihu.com/question/317623081
4.3 VAEs的后驗(yàn)坍塌(Posterior Collapse)?GAN的模式坍塌(Mode Collapse)?
「(1)VAEs的后驗(yàn)坍塌(Posterior Collapse)?」
涉及兩個(gè)網(wǎng)絡(luò)的模型訓(xùn)練起來都不是很簡單, GAN 如此,VAE 亦如此。VAE 容易出現(xiàn)一種被稱為 posterior collapse 的問題,即 完全學(xué)不出來。這個(gè)問題至今也沒有完全被解決。有一個(gè)十分有意思的嘗試是基于 normalizing flow (NF) 的,即 是一個(gè) NF 模型。由于 NF 能直接定義 density, 且表征能力至少比 Gaussian 好不少,因此基于 NF 的 VAE 效果會(huì)得到顯著提升。
「(2)GAN的模式坍塌(Mode Collapse)?」
Mode collapse 是指 GAN 生成的樣本單一,其認(rèn)為滿足某一分布的結(jié)果為 true,其他為 False。
4.4 VAEs為什么在推薦的召回側(cè)效果好?
VAEs是生成式模型而不是Encode壓縮,保證了信息的完整性,Latent Vector是一個(gè)分布,而不是固定的,使得隱含空間在相似樣本上的差異更加平滑,從而提高模型的擬合能力,避免樣本細(xì)微的變化帶來的模型參數(shù)波動(dòng)。
4.5 AUC是否能作為召回離線評估指標(biāo)呢?
首先,AUC是代表模型的排序能力,因?yàn)樵谡倩丨h(huán)節(jié)考慮所有推薦物品的順序沒有太大意義,所以不是一個(gè)好的評估指標(biāo)。
其次,AUC高并不代表召回的好,因?yàn)槲覀兺蓸拥呢?fù)樣本都是easy的,這樣召回模型的AUC一般都是偏高的(auc=0.8+/0.9+都是有可能的)。實(shí)際上好的召回可能AUC低一些,但是會(huì)召回出更符合真實(shí)分布的內(nèi)容,實(shí)際工作中AUC當(dāng)作參考就好。
最后,召回模型AUC高也引出另一個(gè)召回的問題,就是如何挖掘hard負(fù)樣本,以提升模型對于邊界樣本的區(qū)分能力,挖掘出好的hard負(fù)樣本,也能減緩召回模型AUC過高的問題。
4.6 AUC和線上優(yōu)化指標(biāo)正相關(guān)嘛?
不相關(guān)。我們先從AUC的計(jì)算說起,計(jì)算AUC需要知道每個(gè)item的label和score,score決定了最終出去的順序,但是這里的順序只是召回環(huán)節(jié)的順序,而召回后面還有模型排序,甚至中間可能還有粗排,所以最終用戶看到的排序是精排模型的打分,和召回的分可能沒有關(guān)系,甚至可能是相反的。所以說AUC在這里意義不太大,「那么AUC是否可以作為一個(gè)參考指標(biāo)呢?」
答案是依然意義不大,因?yàn)檎倩氐哪康氖前延脩艨赡軙?huì)喜歡的召回出來,最終順序反而不是重要的,因?yàn)檫@里的順序決定不了什么。反而召回結(jié)果中那些能進(jìn)入到排序,以及推薦出去那些用戶點(diǎn)擊了的更重要。「那么有沒有可能AUC是可以作為參考的呢?」
當(dāng)召回層模型和排序側(cè)使用相同的模型的時(shí)候,有參考價(jià)值,比如萬能的FM模型,假設(shè)召回和排序用相同的,那么召回側(cè)的順序和精排模型側(cè)排序是一樣的,這樣AUC就和線上指標(biāo)完全相關(guān)了,可以作為離線評估效果指標(biāo)。
5. 總結(jié)自編碼器在推薦場景上的應(yīng)用
《AutoRec: Autoencoders Meet Collaborative Filtering》WWW 2015,較早采用自編碼器進(jìn)行推薦的論文。 《Deep Collaborative Filtering via Marginalized Denoising Auto-encoder》 CIKM 2015,這篇論文是矩陣分解的DAE解法。 《Variational Autoencoders for Collaborative Filtering》WWW2018,詳細(xì)信息已在本篇文章進(jìn)行了介紹,且該論文在工業(yè)界有落地應(yīng)用。 《Collaborative Denoising Auto-Encoders for Top-N Recommender Systems》發(fā)表在 the ninth ACM international conference on web search and data mining 2016,本文的亮點(diǎn)是可以在輸入層加入用戶側(cè)的side information,該論文也在工業(yè)界有落地應(yīng)用。
6. Reference
【1】變分自編碼器 (VAE) Overview - Zhifeng的文章 - 知乎
https://zhuanlan.zhihu.com/p/420419446
【2】BERT模型精講 - Microstrong的文章 - 知乎 https://zhuanlan.zhihu.com/p/150681502
【3】用于協(xié)同過濾的變分自編碼器論文引介 - 聽歌的小孩的文章 - 知乎 https://zhuanlan.zhihu.com/p/60330303
【4】基于自編碼器的推薦系統(tǒng)論文引介 - Richard Gaole的文章 - 知乎 https://zhuanlan.zhihu.com/p/36241871
【5】Comprehensive Introduction to Autoencoders,地址:https://towardsdatascience.com/generating-images-with-autoencoders-77fd3a8dd368
【6】變分自編碼器VAE:原來是這么一回事 | 附開源代碼 - PaperWeekly的文章 - 知乎 https://zhuanlan.zhihu.com/p/34998569
【7】召回離線評估指標(biāo)問題記錄,地址:http://yougth.top/2020/10/15/%E5%8F%AC%E5%9B%9E%E7%A6%BB%E7%BA%BF%E8%AF%84%E4%BC%B0%E6%8C%87%E6%A0%87/
【8】推薦算法評價(jià)指標(biāo) - Noah的文章 - 知乎 https://zhuanlan.zhihu.com/p/359528909
【9】《變分自動(dòng)編碼器在協(xié)同過濾中的使用》做推薦召回 《Variational Autoencoders for Collaborative Filtering 》,地址:https://blog.csdn.net/xiewenbo/article/details/103724357
【10】論文解讀:Variational Autoencoders for Collaborative Filtering.(WWW2018),地址:https://blog.csdn.net/yfreedomliTHU/article/details/92093649?