
如何可視化你的CV模型?
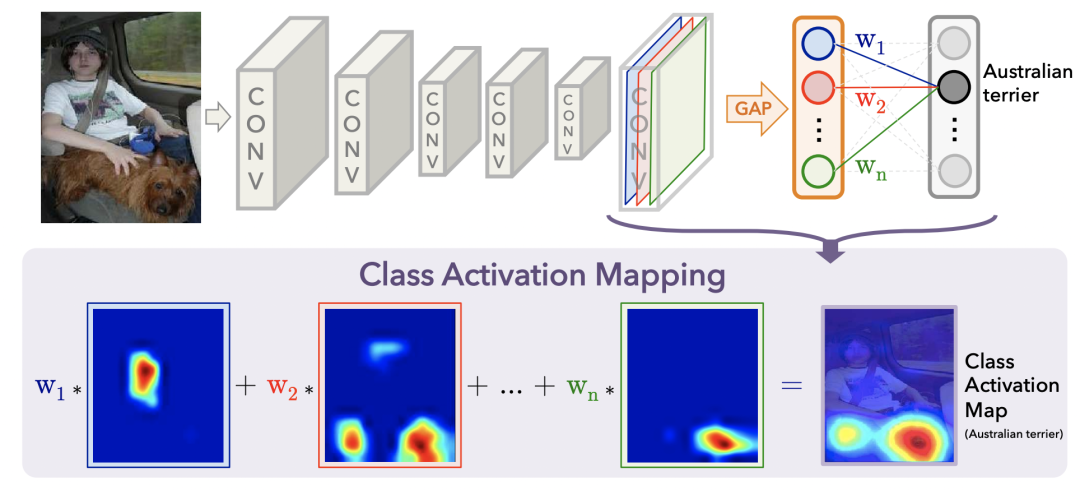
首先,獲取模型最后一層卷積輸出的特征圖[W, H, C],其中C是channel維度,也就是特征圖的個(gè)數(shù),每個(gè)特征圖是W*H的矩陣。利用Global Average Pooling(GAP)將每一個(gè)channel的特征圖融合。
然后,利用全連接+softmax根據(jù)各個(gè)channel的特征圖學(xué)習(xí)分類任務(wù),這樣就能通過(guò)softmax得到每個(gè)channel的權(quán)重。對(duì)于一個(gè)多分類任務(wù),選擇正確類別相對(duì)于各個(gè)channel的softmax打分,作為每個(gè)特征圖的權(quán)重w。
最后,利用學(xué)到的權(quán)重w對(duì)各個(gè)channel的特征圖加權(quán)平均,得到最終的可視化結(jié)果,即圖像上每個(gè)位置的重要性。整個(gè)過(guò)程如下圖所示。

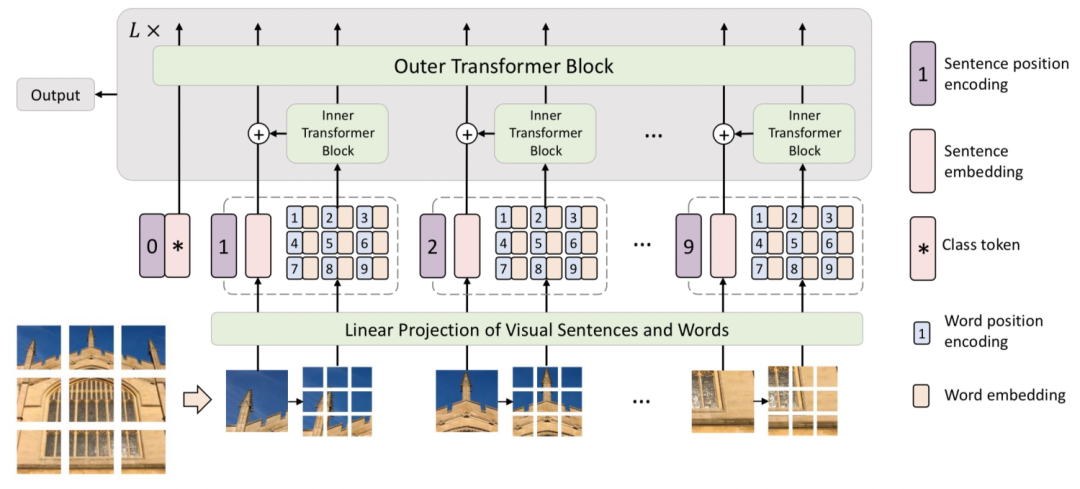

第一步——融合多head結(jié)果:需要先獲取到ViT每層的[CLS] token對(duì)于各個(gè)patch的attention打分。一般ViT使用的都是多頭注意力機(jī)制,這里我們把各個(gè)head的attention score求平均作為每層的整體attention。
第二步——考慮殘差連接:由于Transformer中,每層之間都有residual connection,直接將上一層的輸入和本層的輸出加和。這對(duì)應(yīng)于每個(gè)位置的token和自己做了一個(gè)權(quán)重為1的attention。為了把這部分信息體現(xiàn)出來(lái),通過(guò)生成一個(gè)對(duì)角線為1的矩陣,加和到初始的attention score矩陣上,再進(jìn)行歸一化,得到考慮了殘差連接的attention打分。
第三步——考慮多層累乘關(guān)系,當(dāng)我們想繪制多層attention矩陣時(shí),各層attention矩陣是有一個(gè)傳導(dǎo)關(guān)系的。第二層Transformer在做attention時(shí),輸入是第一層attention加權(quán)的結(jié)果。為了把這個(gè)因素考慮在內(nèi),代碼中會(huì)循環(huán)進(jìn)行attention weight相乘。用上一層累乘的attention矩陣,與當(dāng)前層直接從模型中獲取的attention矩陣相乘,模擬了輸入是上一層attention加權(quán)融合后的結(jié)果。
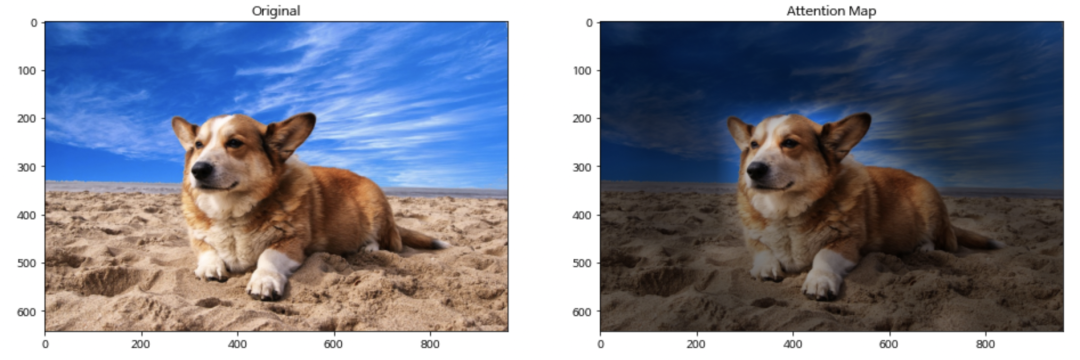
第四步——插值還原:我們得到的attention map是pacth_size * patch_size的,和原來(lái)圖像的尺寸肯定是不一樣的。我們需要把這個(gè)attention矩陣通過(guò)插值的方法還原成和圖像相同的尺寸,再用這個(gè)attention score和圖像上對(duì)應(yīng)像素點(diǎn)相乘,得到可視化圖像。代碼中直接使用了cv2的resize函數(shù),這個(gè)函數(shù)通過(guò)雙線性插值的方法將輸入矩陣擴(kuò)大成和原圖像相同的尺寸。


交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有美顏、三維視覺(jué)、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群
個(gè)人微信(如果沒(méi)有備注不拉群!) 請(qǐng)注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會(huì)分享
在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風(fēng)格指南
在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):c++,即可下載。歷經(jīng)十年考驗(yàn),最權(quán)威的編程規(guī)范!
下載3 CVPR2021 在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):CVPR,即可下載1467篇CVPR 2020論文 和 CVPR 2021 最新論文
