點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

最近在學習LSTM應用在時間序列的預測上,但是遇到一個很大的問題就是LSTM在傳統(tǒng)BP網絡上加上時間步后,其結構就很難理解了,同時其輸入輸出數(shù)據格式也很難理解,網絡上有很多介紹LSTM結構的文章,但是都不直觀,對初學者是非常不友好的。我也是苦苦冥思很久,看了很多資料和網友分享的LSTM結構圖形才明白其中的玄機。
1、傳統(tǒng)的BP網絡和CNN網絡
2、LSTM網絡
3、LSTM的輸入結構
4、pytorch中的LSTM
4.1 pytorch中定義的LSTM模型
4.2 喂給LSTM的數(shù)據格式
4.3 LSTM的output格式
5、LSTM和其他網絡組合
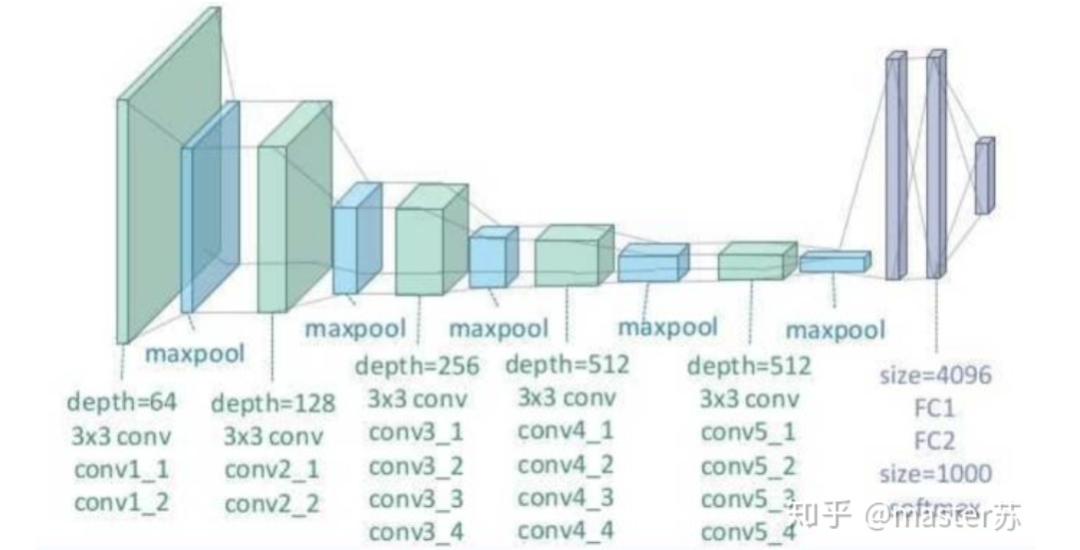
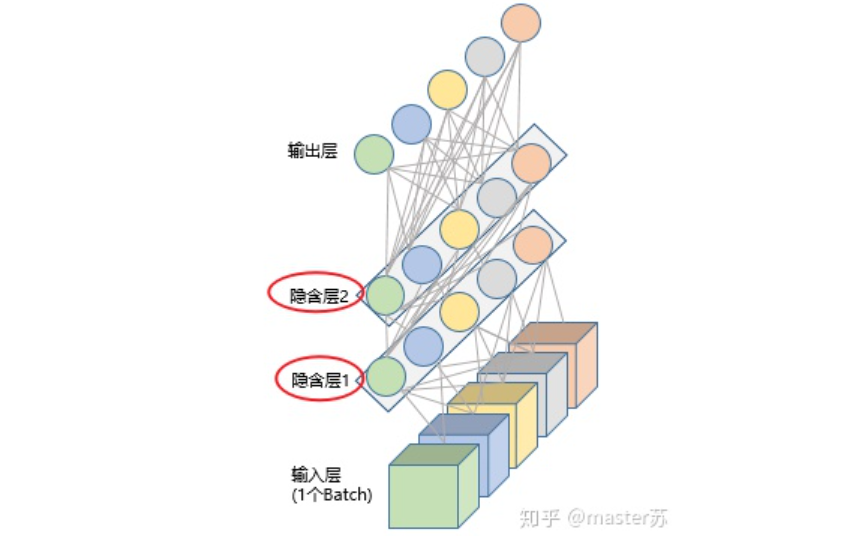
BP網絡和CNN網絡沒有時間維,和傳統(tǒng)的機器學習算法理解起來相差無幾,CNN在處理彩色圖像的3通道時,也可以理解為疊加多層,圖形的三維矩陣當做空間的切片即可理解,寫代碼的時候照著圖形一層層疊加即可。如下圖是一個普通的BP網絡和CNN網絡。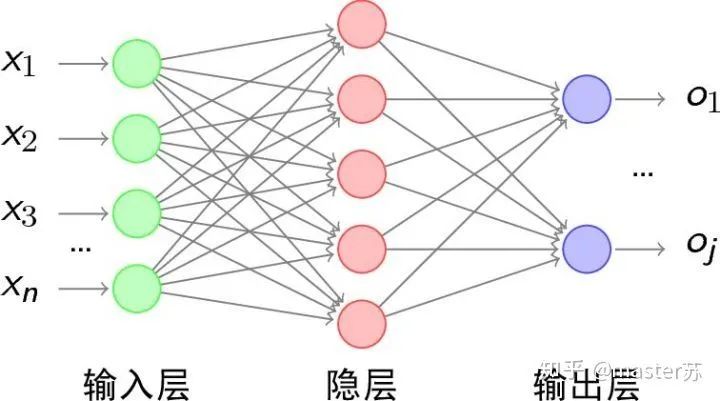 圖中的隱含層、卷積層、池化層、全連接層等,都是實際存在的,一層層前后疊加,在空間上很好理解,因此在寫代碼的時候,基本就是看圖寫代碼,比如用keras就是:
圖中的隱含層、卷積層、池化層、全連接層等,都是實際存在的,一層層前后疊加,在空間上很好理解,因此在寫代碼的時候,基本就是看圖寫代碼,比如用keras就是:# 示例代碼,沒有實際意義model = Sequential()model.add(Conv2D(32, (3, 3), activation='relu')) # 添加卷積層model.add(MaxPooling2D(pool_size=(2, 2))) # 添加池化層model.add(Dropout(0.25)) # 添加dropout層
model.add(Conv2D(32, (3, 3), activation='relu')) # 添加卷積層model.add(MaxPooling2D(pool_size=(2, 2))) # 添加池化層model.add(Dropout(0.25)) # 添加dropout層
.... # 添加其他卷積操作
model.add(Flatten()) # 拉平三維數(shù)組為2維數(shù)組model.add(Dense(256, activation='relu')) 添加普通的全連接層model.add(Dropout(0.5))model.add(Dense(10, activation='softmax'))
.... # 訓練網絡
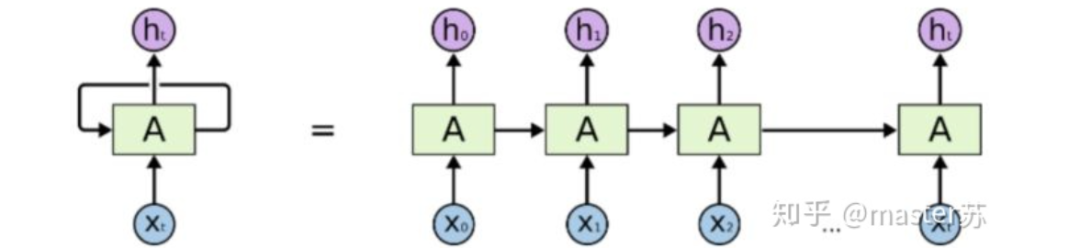
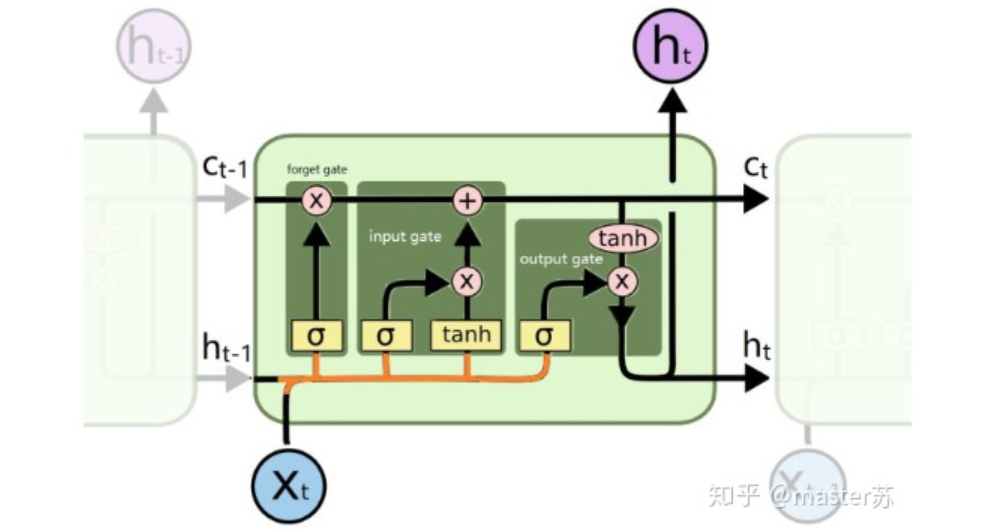
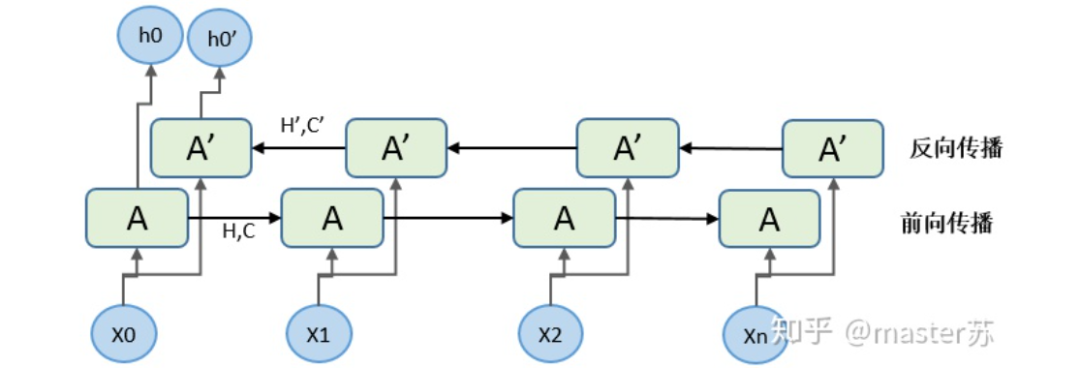
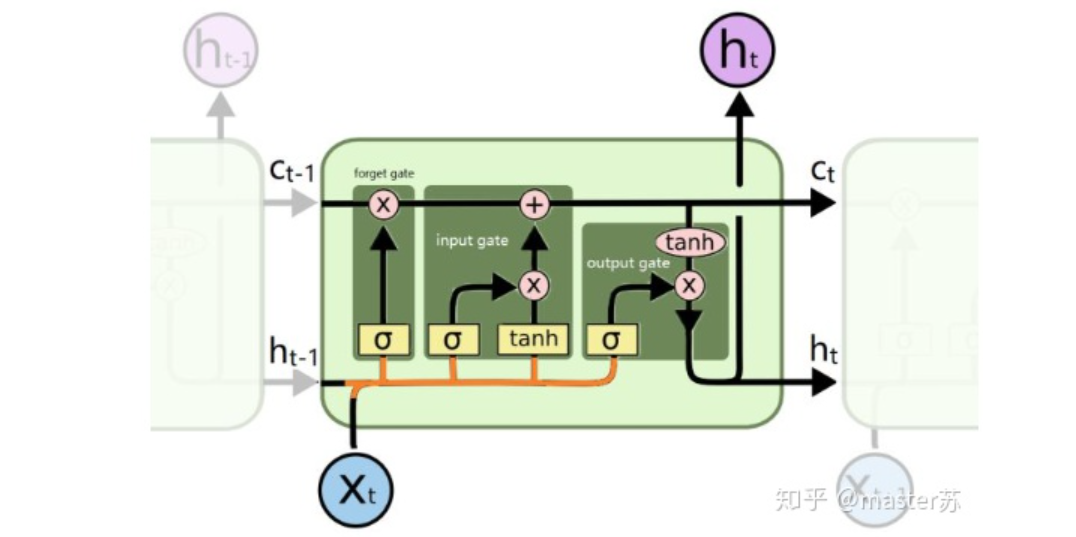
當我們在網絡上搜索看LSTM結構的時候,看最多的是下面這張圖:這是RNN循環(huán)神經網絡經典的結構圖,LSTM只是對隱含層節(jié)點A做了改進,整體結構不變,因此本文討論的也是這個結構的可視化問題。中間的A節(jié)點隱含層,左邊是表示只有一層隱含層的LSTM網絡,所謂LSTM循環(huán)神經網絡就是在時間軸上的循環(huán)利用,在時間軸上展開后得到右圖。看左圖,很多同學以為LSTM是單輸入、單輸出,只有一個隱含神經元的網絡結構,看右圖,以為LSTM是多輸入、多輸出,有多個隱含神經元的網絡結構,A的數(shù)量就是隱含層節(jié)點數(shù)量。WTH?思維轉不過來啊。這就是傳統(tǒng)網絡和空間結構的思維。實際上,右圖中,我們看Xt表示序列,下標t是時間軸,所以,A的數(shù)量表示的是時間軸的長度,是同一個神經元在不同時刻的狀態(tài)(Ht),不是隱含層神經元個數(shù)。我們知道,LSTM網絡在訓練時會使用上一時刻的信息,加上本次時刻的輸入信息來共同訓練。舉個簡單的例子:在第一天我生病了(初始狀態(tài)H0),然后吃藥(利用輸入信息X1訓練網絡),第二天好轉但是沒有完全好(H1),再吃藥(X2),病情得到好轉(H2),如此循環(huán)往復知道病情好轉。因此,輸入Xt是吃藥,時間軸T是吃多天的藥,隱含層狀態(tài)是病情狀況。因此我還是我,只是不同狀態(tài)的我。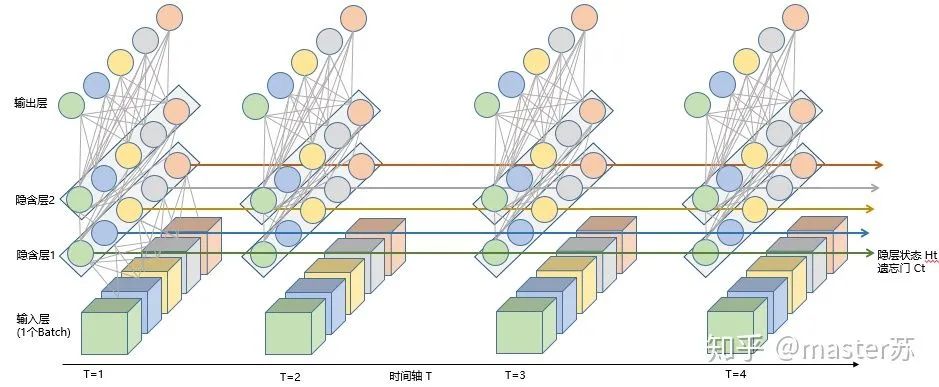 上面的圖表示包含2個隱含層的LSTM網絡,在T=1時刻看,它是一個普通的BP網絡,在T=2時刻看也是一個普通的BP網絡,只是沿時間軸展開后,T=1訓練的隱含層信息H,C會被傳遞到下一個時刻T=2,如下圖所示。上圖中向右的五個常常的箭頭,所的也是隱含層狀態(tài)在時間軸上的傳遞。注意,圖中H表示隱藏層狀態(tài),C是遺忘門,后面會講解它們的維度。
上面的圖表示包含2個隱含層的LSTM網絡,在T=1時刻看,它是一個普通的BP網絡,在T=2時刻看也是一個普通的BP網絡,只是沿時間軸展開后,T=1訓練的隱含層信息H,C會被傳遞到下一個時刻T=2,如下圖所示。上圖中向右的五個常常的箭頭,所的也是隱含層狀態(tài)在時間軸上的傳遞。注意,圖中H表示隱藏層狀態(tài),C是遺忘門,后面會講解它們的維度。
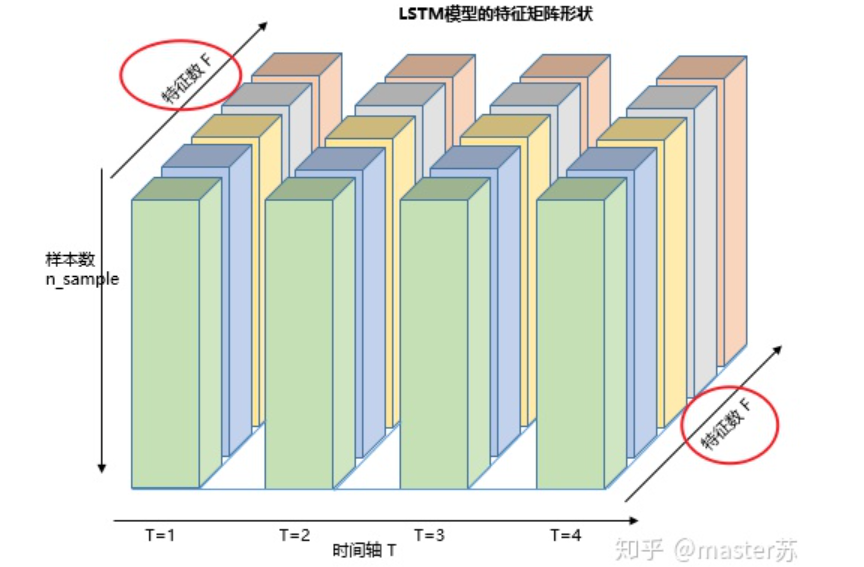
為了更好理解LSTM結構,還必須理解LSTM的數(shù)據輸入情況。仿照3通道圖像的樣子,在加上時間軸后的多樣本的多特征的不同時刻的數(shù)據立方體如下圖所示: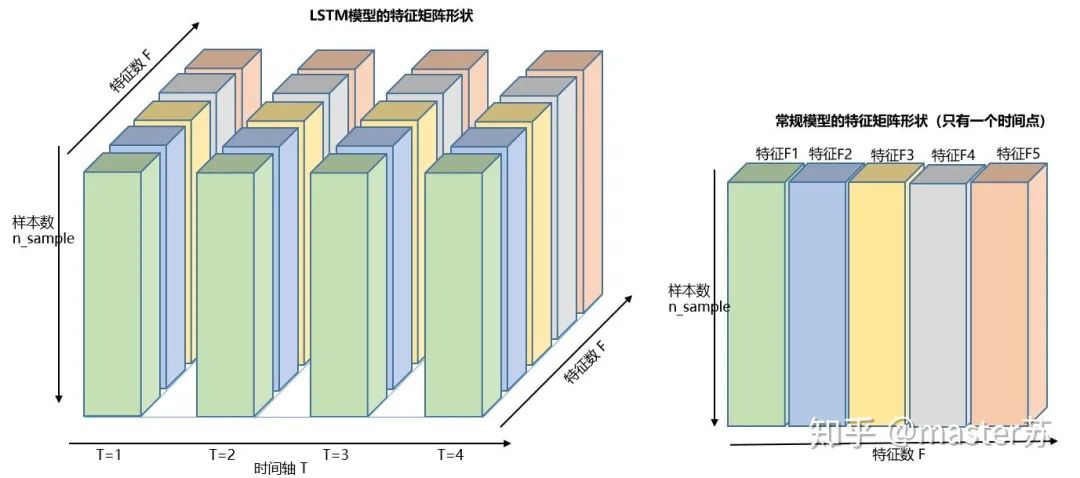 右邊的圖是我們常見模型的輸入,比如XGBOOST,lightGBM,決策樹等模型,輸入的數(shù)據格式都是這種(N*F)的矩陣,而左邊是加上時間軸后的數(shù)據立方體,也就是時間軸上的切片,它的維度是(N*T*F),第一維度是樣本數(shù),第二維度是時間,第三維度是特征數(shù),如下圖所示:
右邊的圖是我們常見模型的輸入,比如XGBOOST,lightGBM,決策樹等模型,輸入的數(shù)據格式都是這種(N*F)的矩陣,而左邊是加上時間軸后的數(shù)據立方體,也就是時間軸上的切片,它的維度是(N*T*F),第一維度是樣本數(shù),第二維度是時間,第三維度是特征數(shù),如下圖所示: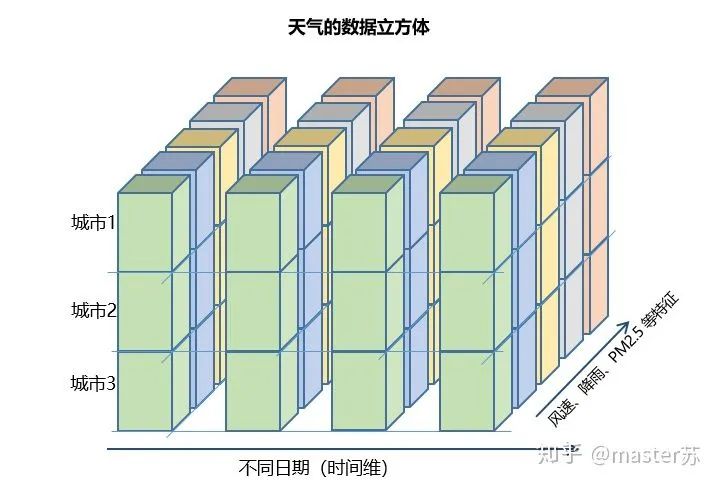 這樣的數(shù)據立方體很多,比如天氣預報數(shù)據,把樣本理解成城市,時間軸是日期,特征是天氣相關的降雨風速PM2.5等,這個數(shù)據立方體就很好理解了。在NLP里面,一句話會被embedding成一個矩陣,詞與詞的順序是時間軸T,索引多個句子的embedding三維矩陣如下圖所示:
這樣的數(shù)據立方體很多,比如天氣預報數(shù)據,把樣本理解成城市,時間軸是日期,特征是天氣相關的降雨風速PM2.5等,這個數(shù)據立方體就很好理解了。在NLP里面,一句話會被embedding成一個矩陣,詞與詞的順序是時間軸T,索引多個句子的embedding三維矩陣如下圖所示: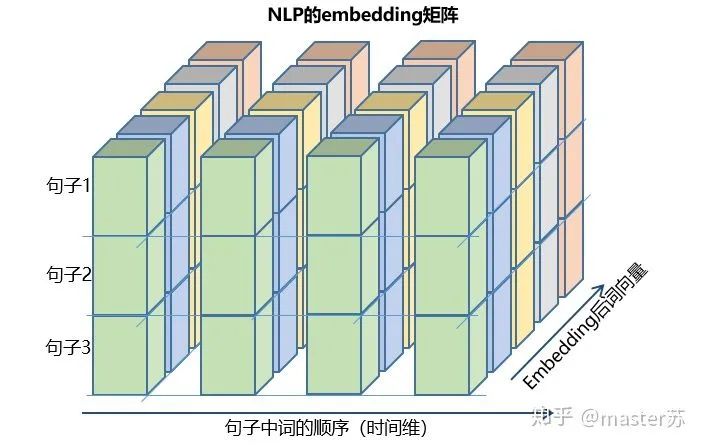
4.1 pytorch中定義的LSTM模型
pytorch中定義的LSTM模型的參數(shù)如下class torch.nn.LSTM(*args, **kwargs)參數(shù)有: input_size:x的特征維度 hidden_size:隱藏層的特征維度 num_layers:lstm隱層的層數(shù),默認為1 bias:False則bihbih=0和bhhbhh=0. 默認為True batch_first:True則輸入輸出的數(shù)據格式為 (batch, seq, feature) dropout:除最后一層,每一層的輸出都進行dropout,默認為: 0 bidirectional:True則為雙向lstm默認為False
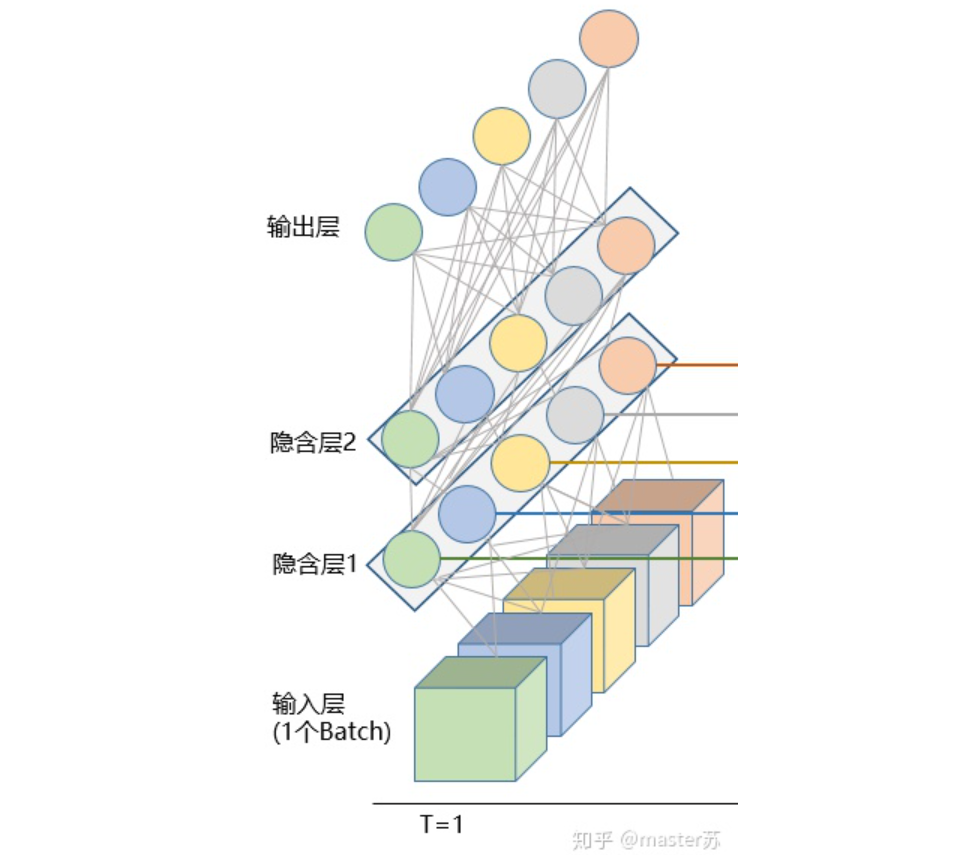
(1)input_size:x的特征維度,就是數(shù)據立方體中的F,在NLP中就是一個詞被embedding后的向量長度,如下圖所示:(2)hidden_size:隱藏層的特征維度(隱藏層神經元個數(shù)),如下圖所示,我們有兩個隱含層,每個隱藏層的特征維度都是5。注意,非雙向LSTM的輸出維度等于隱藏層的特征維度。
(3)num_layers:lstm隱層的層數(shù),上面的圖我們定義了2個隱藏層。
(4)batch_first:用于定義輸入輸出維度,后面再講。(5)bidirectional:是否是雙向循環(huán)神經網絡,如下圖是一個雙向循環(huán)神經網絡,因此在使用雙向LSTM的時候我需要特別注意,正向傳播的時候有(Ht, Ct),反向傳播也有(Ht', Ct'),前面我們說了非雙向LSTM的輸出維度等于隱藏層的特征維度,而雙向LSTM的輸出維度是隱含層特征數(shù)*2,而且H,C的維度是時間軸長度*2。
4.2 喂給LSTM的數(shù)據格式
pytorch中LSTM的輸入數(shù)據格式默認如下:input(seq_len, batch, input_size)參數(shù)有: seq_len:序列長度,在NLP中就是句子長度,一般都會用pad_sequence補齊長度 batch:每次喂給網絡的數(shù)據條數(shù),在NLP中就是一次喂給網絡多少個句子 input_size:特征維度,和前面定義網絡結構的input_size一致。
前面也說到,如果LSTM的參數(shù) batch_first=True,則要求輸入的格式是:input(batch, seq_len, input_size)
剛好調換前面兩個參數(shù)的位置。其實這是比較好理解的數(shù)據形式,下面以NLP中的embedding向量說明如何構造LSTM的輸入。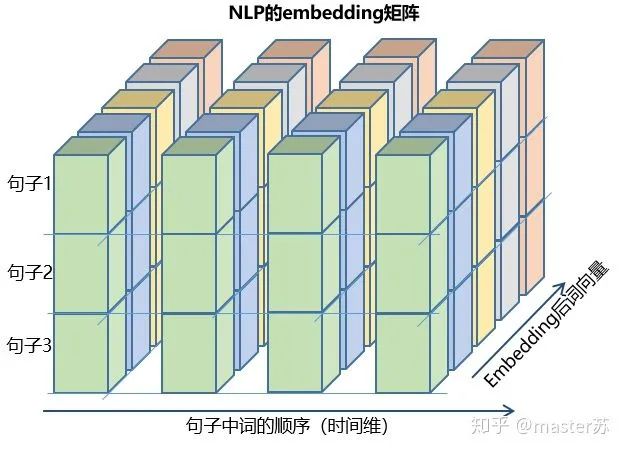 如果把batch放在第一位,則三維矩陣的形式如下:
如果把batch放在第一位,則三維矩陣的形式如下: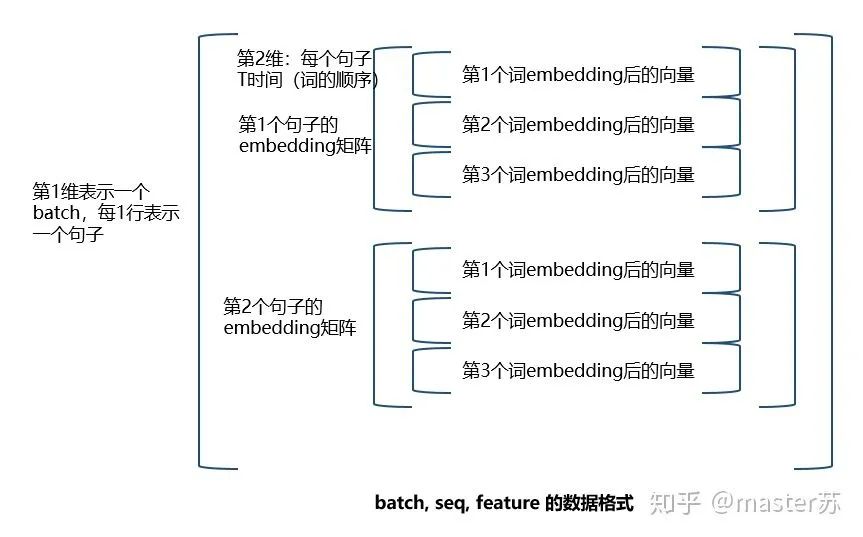
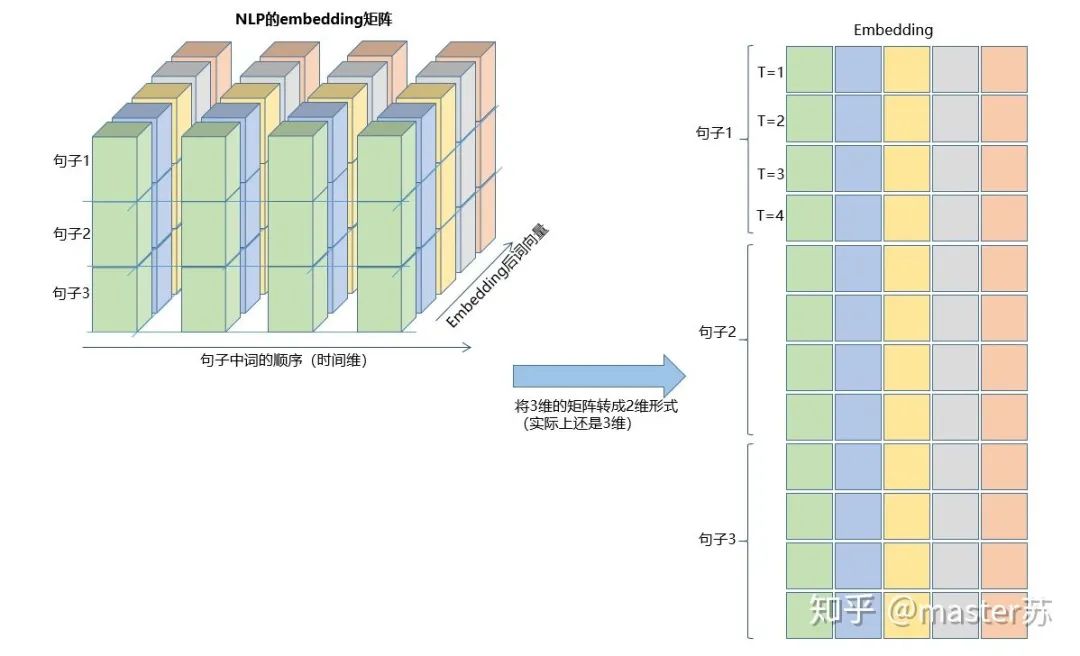 看懂了嗎,這就是輸入數(shù)據的格式,是不是很簡單。LSTM的另外兩個輸入是 h0?和 c0,可以理解成網絡的初始化參數(shù),用隨機數(shù)生成即可。
看懂了嗎,這就是輸入數(shù)據的格式,是不是很簡單。LSTM的另外兩個輸入是 h0?和 c0,可以理解成網絡的初始化參數(shù),用隨機數(shù)生成即可。h0(num_layers * num_directions, batch, hidden_size)c0(num_layers * num_directions, batch, hidden_size)參數(shù): num_layers:隱藏層數(shù) num_directions:如果是單向循環(huán)網絡,則num_directions=1,雙向則num_directions=2 batch:輸入數(shù)據的batch hidden_size:隱藏層神經元個數(shù)
input(batch, seq_len, input_size)
h0(batc,num_layers * num_directions, h, hidden_size)c0(batc,num_layers * num_directions, h, hidden_size)
4.3 LSTM的output格式
output,(ht, ct) = net(input) output: 最后一個狀態(tài)的隱藏層的神經元輸出 ht:最后一個狀態(tài)的隱含層的狀態(tài)值 ct:最后一個狀態(tài)的隱含層的遺忘門值
output(seq_len, batch, hidden_size * num_directions)ht(num_layers * num_directions, batch, hidden_size)ct(num_layers * num_directions, batch, hidden_size)
和input的情況類似,如果我們前面定義的input格式是:input(batch, seq_len, input_size)
ht(batc,num_layers * num_directions, h, hidden_size)ct(batc,num_layers * num_directions, h, hidden_size)
說了這么多,我們回過頭來看看ht和ct在哪里,請看下圖:還記得嗎,output的維度等于隱藏層神經元的個數(shù),即hidden_size,在一些時間序列的預測中,會在output后,接上一個全連接層,全連接層的輸入維度等于LSTM的hidden_size,之后的網絡處理就和BP網絡相同了,如下圖: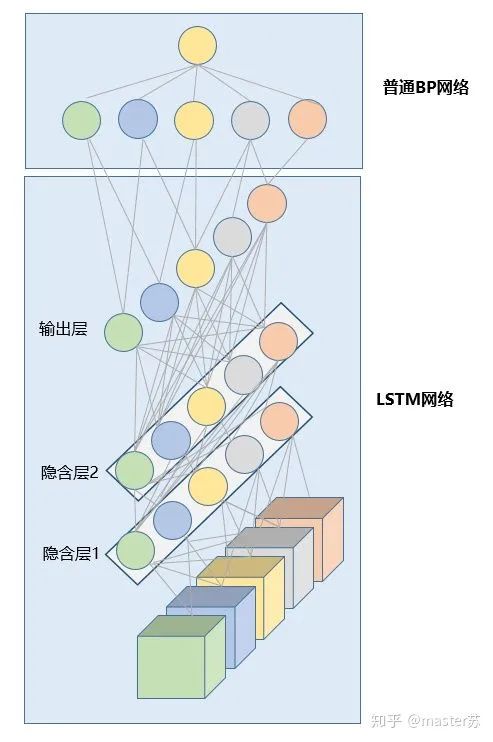
import torchfrom torch import nn
class RegLSTM(nn.Module): def __init__(self): super(RegLSTM, self).__init__() # 定義LSTM self.rnn = nn.LSTM(input_size, hidden_size, hidden_num_layers) # 定義回歸層網絡,輸入的特征維度等于LSTM的輸出,輸出維度為1 self.reg = nn.Sequential( nn.Linear(hidden_size, 1) )
def forward(self, x): x, (ht,ct) = self.rnn(x) seq_len, batch_size, hidden_size= x.shape x = y.view(-1, hidden_size) x = self.reg(x) x = x.view(seq_len, batch_size, -1) return x
當然,有些模型則是將輸出當做另一個LSTM的輸入,或者使用隱藏層ht,ct的信息進行建模,不一而足。好了,以上就是我對LSTM的一些學習心得,看完記得關注點贊。https://zhuanlan.zhihu.com/p/94757947https://zhuanlan.zhihu.com/p/59862381https://zhuanlan.zhihu.com/p/36455374https://www.zhihu.com/question/41949741/answer/318771336https://blog.csdn.net/android_ruben/article/details/80206792
下載1:OpenCV-Contrib擴展模塊中文版教程
在「小白學視覺」公眾號后臺回復:擴展模塊中文教程,即可下載全網第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標跟蹤、生物視覺、超分辨率處理等二十多章內容。下載2:Python視覺實戰(zhàn)項目52講在「小白學視覺」公眾號后臺回復:Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學校計算機視覺。在「小白學視覺」公眾號后臺回復:OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現(xiàn)20個實戰(zhàn)項目,實現(xiàn)OpenCV學習進階。交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據研究方向邀請進入相關微信群。請勿在群內發(fā)送廣告,否則會請出群,謝謝理解~