↑↑↑關(guān)注后" 星標(biāo) "Datawhale 來源丨h(huán)ttps://zhuanlan.zhihu.com/p/264887767
本文作者從圖像空間、特征空間、 Loss profile 空間以及 利用backpropagated gradient信息做異常檢測四個方面,結(jié)合2019年和2020的頂會論文,對工業(yè)圖像上的異常檢測的最新進(jìn)展進(jìn)行了總結(jié)。
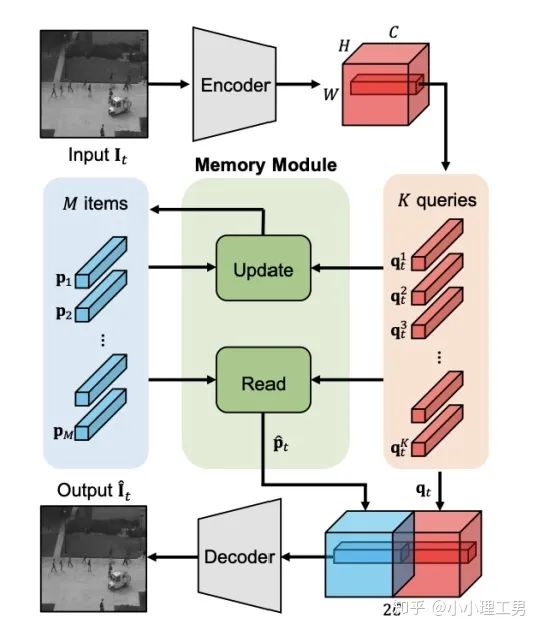
寫在前面 這里對我最近的研究領(lǐng)域——工業(yè)圖像上的異常檢測中最新的一些進(jìn)展做一個總結(jié)。主要總結(jié)的是在2019和2020的一些頂會上,關(guān)于Semi-supervised或者Unsupervised anomaly detection的一些比較有意思的文章,并給出我自己的一些看法。 由于水平有限,所以大家辯證地看就好,如有不當(dāng)之處或可補充之處,歡迎指正~ 1. 簡要地介紹一下什么是異常檢測(anomaly detection) 如果將每個樣本看作空間中的一個點的話,異常(anomaly)簡單地來說就是離群點 ,或者說是“非主流”的點,即離大多數(shù)樣本點都比較遠(yuǎn)。這里隱藏的意思是,異常通常是少數(shù) 。 下圖很形象地展示了什么是異常。其中,黑色的點為正常的樣本點,紅色的點為異常點樣本點。(更多的介紹可以參考Kiwi:異常檢測概述(一):An Overview of Anomaly Detection Part I https://zhuanlan.zhihu.com/p/50384515 ) 異常檢測的任務(wù),就是找到正常樣本與異常樣本之間的界線,盡可能地將正常樣本與異常樣本分開。這里的界線,可以是在各種空間中的,例如圖像空間、特征空間,甚至后文會介紹到的一篇論文中的loss profile空間(現(xiàn)在可能看到這個比較懵逼,后面的文章會介紹這篇文章,還是挺有意思的)。 目前實際的異常檢測遇到的一個很大的困難,是在實際的場景中(例如工業(yè)流水線等),異常樣本往往很難獲得,甚至很多時候沒有異常樣本。這就迫使我們采用semi-supervised或者unsupervised的方法。接下來介紹的文章也都是semi-supervised或者unsupervised的方法。 下面我將以做異常檢測的空間為劃分標(biāo)準(zhǔn),將最近的一些新方法做一個分類。預(yù)計將分3-4篇文章介紹完。 2. 圖像空間上的異常檢測方法 圖像空間上的異常檢測一般采用的是下圖的Auto-encoder結(jié)構(gòu)。 圖像空間上的異常檢測方法的主流結(jié)構(gòu) 主要的思想是,如果我們只在正常樣本的訓(xùn)練集上訓(xùn)練我們的Auto-encoder,則我們重構(gòu)出來的圖像會比較趨近于正常樣本。利用這一個假設(shè)/性質(zhì),在推理階段,即使輸入的圖像是異常樣本,我們重構(gòu)出來的圖像也會像正常樣本。所以我們只需對比原圖和重構(gòu)后的圖,就可以判斷輸入的圖像是否為異常,甚至可以定位到異常區(qū)域。 2.1 MemAE :利用Memory抑制模型的泛化能力 上文所說的Auto-encoder框架其實隱藏了一個問題:機器學(xué)習(xí)模型一般都是具有泛化能力的。也就是說,即使我們在只有正常樣本的訓(xùn)練集上訓(xùn)練,在推理階段,如果輸入異常樣本,由于泛化能力的存在,我們的模型也有一定的概率輸出類似于異常的樣本。這時候我們對比原圖和重構(gòu)后的圖像,會發(fā)現(xiàn)非常相似... 這時候我們的異常檢測方法就失效了QwQ。 所以ICCV 2019的一篇文章提出了MemAE來顯式地抑制Auto-encoder的泛化能力。他們的思路是,既然Auto-encoder泛化能力有時候會過強,那么如果讓輸入decoder的embedding都由正常樣本的embedding組合而成,能夠預(yù)計decoder輸出的重構(gòu)圖像也主要由正常樣本的特征組成。這樣,通過抑制泛化能力來逼迫重構(gòu)后的圖像貼近于正常樣本。 具體做法是,將所有正常樣本經(jīng)過encoder得到的embedding保存在Memory中。當(dāng)輸入一個圖像時,首先用encoder提取出其embedding,并逐一計算圖像的embedding和memory中的各個embedding的相似度(例如cosine similarity),再用相似度作為權(quán)重,將memory中的embedding加權(quán)平均得到新的embedding。 得到的這個新的embedding將同時具有兩個特點: 再將這個新的embedding輸入decoder中,就可以得到既接近于原圖、又貼近于正常樣本的圖像了。 首先是在加權(quán)Memory中embedding時weight的計算:
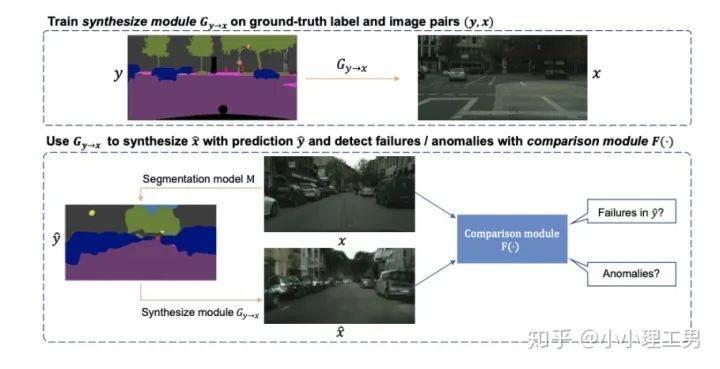
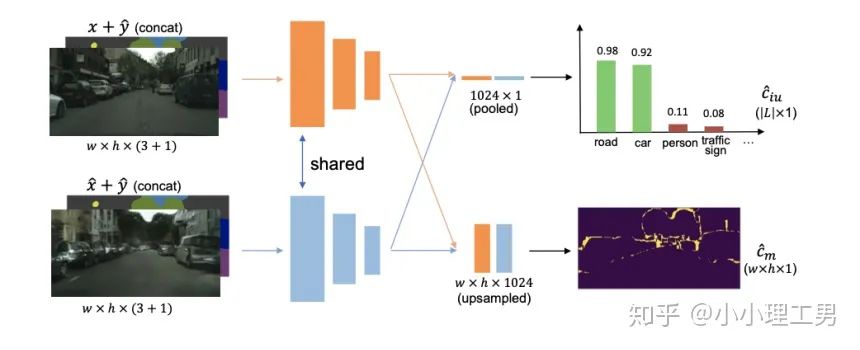
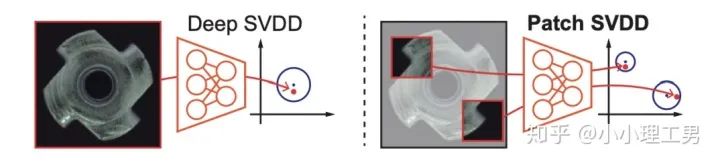
其中 ?為輸入圖像的embedding,? ?為memory中第? ?個embedding, ?為 對應(yīng)的權(quán)重。 2. 限制參與融合的memory的個數(shù): 文章中提到了一個有趣的現(xiàn)象,當(dāng)memory中參與融合的embeding過多時,重構(gòu)后的圖像在異常檢測中的效果會下降。這樣比較好理解:畢竟正常的要素過多,也會組成異常。 為了抑制這個現(xiàn)象,文章中限制了參與融合的embedding個數(shù)。一種比較naive的方式如下: 優(yōu)點: 這篇文章提出了一個非常好的想法來抑制auto-encoder的泛化能力——加入只由正常樣本特征構(gòu)成的memory。據(jù)我所知,這應(yīng)該是第一篇將memory引入異常檢測的文章,能夠算是一篇挖坑之作。后續(xù)也有文章跟進(jìn)這一方面的研究。缺點: 一般來說由于缺少類似于U-net中的skip connection的存在,auto-encoder重構(gòu)出來的圖像一般都比較糊。此篇也不例外。這就給異常區(qū)域的定位帶來了一定的困難。所以可以看到此篇文章的實驗都是在比較簡單的數(shù)據(jù)集上(例如MNIST, cifar10等)做的實驗,而且只能將圖片分類為正常或異常,而不能定位到異常的位置。我覺得后續(xù)如何在只用正常樣本的特征情況下,重構(gòu)出清晰的圖,從而定位到異常區(qū)域位置也是一個可以挖的點。2.2 Memory的進(jìn)一步改進(jìn) 這是CVPR 2020的一篇文章,可以看作是在上一篇文章之上的升級版。我個人認(rèn)為這篇文章對上一篇文章的改進(jìn)之處主要有以下幾點: 增加了memory update的機制,只需存儲固定個數(shù)的memory; 引入了feature compactness loss 和 feature separateness loss,減少需要保存的memory的數(shù)量; 采用了將原圖的embedding和memory中的embedding結(jié)合輸入decoder的方式,一定程度上解決了重構(gòu)后的圖像比較糊的缺點,從而可以定位到異常區(qū)域的位置,從而可以運用到一些更加復(fù)雜、貼近現(xiàn)實情況的數(shù)據(jù)集上。 這里主要介紹一下feature compactness loss和feature separateness loss。 feature copactness loss的作用是使得memory中的embedding和數(shù)據(jù)集中圖像的embedding盡可能的接近。其計算公式如下圖。具體地,對于圖像的每一個embedding feature compactness loss公式. K為一個圖像的embedding (query) 的個數(shù),T為視頻的幀數(shù) feature separateness loss的作用則是使得memory中的embedding相距越大越好。想象一下,如果僅有feature compactness loss,則memory中的embedding會有一種趨于一致的趨勢,那么memory就沒有什么存在的意義了。 feature separateness loss的計算公式如下。對于圖像的每一個embedding 2.3 利用bad quality reconstructed image做異常檢測 這是CVPR 2020的一篇論文中的工作,是一種無監(jiān)督異常檢測的方法,模型名稱為OGNet。 OGNet框架 這篇文章總體不是嚴(yán)格的Auto-encoder架構(gòu),而是采用另一種在異常檢測領(lǐng)域也比較常用的架構(gòu)——GAN。一般的用GAN做異常檢測有兩種思路: 用generator重構(gòu)圖像,discriminator只是用來幫助generator更好地重構(gòu)圖像。在判斷異常時,類似于auto-encoder檢測異常的思路,用generator重構(gòu)后的圖像和原圖做對比,不同處認(rèn)為是異常; 總體思路與1中類似,只是在檢測異常時,綜合generator和discriminator的結(jié)果作為判斷異常的依據(jù)。 這篇文章的亮點就是將discriminator的任務(wù)做了轉(zhuǎn)化:區(qū)分圖像為原圖還是generator生成的圖 -> 區(qū)分是高質(zhì)量重構(gòu)圖像還是低質(zhì)量重構(gòu)圖像。 按照文章中的說法,這樣可以使得在判斷異常時,discriminator更能找到generator重構(gòu)異常圖像時的細(xì)微的擾動,從而更加取得更好的異常檢測效果。這篇文章的細(xì)節(jié)有幾個需要注意的點: 如何生成高質(zhì)量和低質(zhì)量的重構(gòu)圖像? 第一個階段按照通常的方法訓(xùn)練GAN,即generator負(fù)責(zé)重構(gòu)圖像,discriminator負(fù)責(zé)判斷圖像為原圖還是重構(gòu)的圖像; 第二階段選用兩個generator:一個是第一階段中訓(xùn)練好的generator(即圖中的? 此外,文章中還提出了另一種bad quality examples——偽異常重構(gòu)圖像(pseudo-anomaly recontructed image),即人為地偽造異常的圖像。偽異常重構(gòu)圖像生成的方式如下圖所示,即從訓(xùn)練集中隨機選取兩張圖像,用? 偽異常重構(gòu)圖像(pseudo-anomaly recontructed image)生成示意圖 2. 兩階段discriminator的任務(wù) 第一階段中discriminator的任務(wù)和傳統(tǒng)的方法相同,即判斷圖像為原圖還是重構(gòu)后的圖像。如下圖(6)式所示。 第二階段中discriminator的任務(wù)發(fā)生了變化,原圖? 數(shù)據(jù)增強。用不充分訓(xùn)練的generator和人為偽造出來的異常圖像作為負(fù)樣本,來訓(xùn)練discriminator; 異常檢測任務(wù)轉(zhuǎn)移。將檢測異常的任務(wù)從generator或者generator與discriminator共同承擔(dān),轉(zhuǎn)移到由discriminator承擔(dān) 2.4 利用image segmentation信息做異常檢測 這是發(fā)表在ECCV 2020的一篇文章。也是做無監(jiān)督的異常檢測。 文章的核心方法是從image segmentation的結(jié)果出發(fā),利用cGAN重構(gòu)圖像,再將重構(gòu)后的圖像與原圖做比較,不同之處認(rèn)為是異常。整個異常檢測的流程為: 原圖 -> image segmentation結(jié)果 -> 基于segmentation結(jié)果重構(gòu)后的圖像 -> 對比,檢測異常 說白了就是用image segmentation模型和cGAN替代之前auto-encoder框架中auto-encoder的角色,不算是一個特別有意思的story。 文章除了上述用到了cGAN來重構(gòu)圖像的亮點之外,還將failure detection和anomaly detection融合到了同一個框架中,如下圖所示。不過據(jù)我讀文章時的認(rèn)識,failure detection和anomaly detection只是流程框架一致,但是不能同時處理,更不能相輔相成。如果我理解的沒錯的話,也沒有太多的意思。 特征空間的方法主要是將圖像的數(shù)據(jù)通過某種方法映射到特征空間上,再通過特征空間中的距離判斷是否為特征。 相比于圖像空間上的異常檢測,我個人更看好在特征空間上的異常檢測。因為特征空間表達(dá)的是比圖像空間更高層次、更抽象的信息;而且特征空間更加靈活,因為特征空間可以有非常多種定義,而圖像空間只有一個。 3.1 利用teacher和students的差異做異常檢測 這是CVPR 2020上的一篇文章,主要用teacher-students框架做無監(jiān)督的異常檢測。值得一提的是,這篇文章的作者也是MVTec AD這個異常檢測數(shù)據(jù)集的提出者。所以這篇文章比較有借鑒意義。雖然他們沒有公開代碼,但是我自己曾復(fù)現(xiàn)過他們的結(jié)果,指標(biāo)上還是基本一致的。 在僅包含正常樣本的數(shù)據(jù)集上,讓pretrained的teacher模型去教沒有pretrain的student模型,使得teacher模型和student模型輸出的embedding盡可能一致。那么在inference時,由于teacher只教過student如何embed正常樣本,所以正常樣本上teacher模型和student模型輸出的embedding會比較相似,但異常樣本上兩者輸出的embedding差異會比較大; 如果在1中的訓(xùn)練過程中,采用多個隨即初始化的students模型和一個pretrained teacher模型,那么在正常樣本上students之間的embedding比較一致,而在異常樣本上,由于students是隨機初始化的,且teacher并沒有在異常樣本上教過他們,所以在students之間embedding差異也會比較大。 利用這兩個假設(shè),在inference時,如果在某個樣本上,teacher和students的embedding差異比較大,且students的embeddings之間差異也比較大,那么就說明該樣本為異常樣本。 此外,為了定位異常的位置,而不是僅僅判斷某張圖片是否為異常,teacher和students的輸入是圖片的patch,而不是整張圖像。 這樣,當(dāng)在某個patch上teacher和students表現(xiàn)差異很大,或者students之間表現(xiàn)差異很大時,就可以認(rèn)為這個patch為異常,從而定位到了異常的區(qū)域。 多尺度。由于模型的輸入都是patch,所以patch的大小直接決定了異常檢測的resolution。由于圖像中的異常大小不盡相同,當(dāng)異常區(qū)域比較大時,用比較大的patch可能會比較好;反之,比較小的patch效果會比較好。所以文章中采用了三種邊長的正方形patch: 17, 33和64(單位為pixel)。將這三種patch size的結(jié)果做算數(shù)平均就得到了multi-scale的結(jié)果; 如何pretrain模型。現(xiàn)在有很多unsupervised pretrain的方法,例如MoCo。但是文章沒有采用這種unsupervised方法,而是用pretrained resnet-18,通過蒸餾得到了teacher模型。我個人比較困惑的一點是為什么不直接用pretrained resnet-18,可能是為了更快吧...(迷) 優(yōu)點:teacher students這個框架用在異常檢測還是比較有新意的。這種方法既利用了在異常數(shù)據(jù)上pretrain過的模型和沒有pretrain過的模型的差異,也利用了沒有pretrain過的模型之間的差異;此外multi-scale也可以勉強算一個新意... 缺點:multi-scale過于粗糙,只采用三種patch size的結(jié)果疊加;另外復(fù)現(xiàn)出來之后看結(jié)果會發(fā)現(xiàn)一個比較致命的缺點,但是由于我目前做的工作與之相關(guān),所以暫時保密 :-) 3.2 以patch為單位做SVDD 這是一篇掛在arxiv上的文章,主要將SVDD方法從以圖像為單位擴展到了以patch為單位。SVDD是一個比較“古老”的one-class classification方法,因為異常檢測也可以看作是一個one-class classification(正常樣本為一類,之外的都是異常樣本),所以SVDD通常也用作異常檢測。 SVDD的主要思想是,用某種方法將樣本投射到某個特征空間中,計算出所有樣本投影的中心點,再規(guī)定一個半徑? SVDD和Depp SVDD都有一個缺點,那就是他們處理的都是整個圖像,也就是說,在投影的過程中將每個圖像對應(yīng)特征空間中的一個點。這樣的缺點是,我們只能判別這個圖像是否為異常,但是不能定位異常的區(qū)域。 所以patch SVDD做的事情就是將處理的對象從整個圖像變?yōu)閜atch,每個patch對應(yīng)特征空間上的一個點。 此外,由于不同的patch的特征可能會非常不同,即使是正常樣本的patch,在特征空間中的距離也可能非常遠(yuǎn),所以只用一個中心點是不可行的。patch SVDD將SVDD中的一個中心點,改為了用聚類的方式形成多個中心點, patch SVDD用到的backbone就是一個encoder,輸入為patch,輸出為patch的embedding. 文章的精髓就在于在訓(xùn)練時如何設(shè)計監(jiān)督,使得patch的embedding能夠自動地聚類為在多個中心周圍(中心的個數(shù)是我們無法事先設(shè)定的,需要在訓(xùn)練中模型自己生成)。 Training階段 ,作者設(shè)計了兩個Loss,用來達(dá)到相鄰patch的embedding相似,但patch embedding之間具有一定的區(qū)分度的效果 。第一個是SVDD loss,計算公式如下:其中? 但是如果只用? 其中, 如果所有patch embedding都極為相似,那么? Inference階段,作者通過下面的式子計算patch的anomaly score: 其中? 這篇文章的優(yōu)點在story部分已經(jīng)介紹得很詳細(xì),不再贅述。這里主要講講我個人認(rèn)為的不足之處: 信息提取不充分(這里和我現(xiàn)在做的工作有關(guān),所以不詳細(xì)說了hhh) 訓(xùn)練時使相鄰的patch特征聚合在一起,這個設(shè)想不一定合理 對于物品會旋轉(zhuǎn)的類別,判斷patch相對方位可能不合理 結(jié)構(gòu)圖 這是ECCV 2020 CMU的一篇文章,是一個semi-supervised的異常檢測工作。他們提出了一個比較新穎的思路——在loss profile空間上做異常檢測。所謂的loss profile,就是在訓(xùn)練過程中l(wèi)oss的記錄曲線(橫軸為iteration / epoch,縱軸為loss)。 這篇文章觀察到了一個現(xiàn)象:當(dāng)auto-encoder在正常樣本為主的訓(xùn)練集上訓(xùn)練時,訓(xùn)練圖像中正常區(qū)域的reconstruction loss隨訓(xùn)練的iteration / epoch增加而穩(wěn)步下降,而異常區(qū)域的reconstruction loss則不斷波動。 所以作者提出利用loss隨訓(xùn)練次數(shù)的變化趨勢——loss profile來做異常檢測。換句話說,將異常檢測的空間從通常的圖像空間/特征空間轉(zhuǎn)化到了loss profile空間。因為在訓(xùn)練時訓(xùn)練集只要以正常樣本為主即可,所以這個方法是semi-supervised的。 雖然上面的想法聽起來很新穎且非常易懂,但是實際上文章的實現(xiàn)是比較復(fù)雜的,涉及到的細(xì)節(jié)非常多。所以這里只介紹模型的大致框架,感興趣的朋友可以閱讀原論文。 如上結(jié)構(gòu)圖所示,模型主要由三個部分組成: 如《異常檢測最新研究總結(jié)(三)》中所說,當(dāng)需要定位圖像中的異常區(qū)域時,一般模型的處理單位為圖像的patch而不是整張圖像。這篇文章為了定位到圖像中的異常區(qū)域,也是以patch為單位處理。 Neural Batch Sampler是一個RL (reinforcement learing) 模型,其作用就是選出那些使得loss profile差距最大的正常和異常的patches。 這部分就是通常的auto-encoder,輸入為圖像的patch,輸出為重構(gòu)后的patch predictor用以預(yù)測圖像中的pixel-wise的異常區(qū)域。其輸入為經(jīng)過FIFO Buffer累積的訓(xùn)練時的loss profile,輸出為對圖像中每個pixel是否為異常的pixel-wise的label。由于是semi-supervised的,所以可以用已知的正常和異常圖像的ground truth做監(jiān)督,得到? 優(yōu)點: 這篇文章最大的優(yōu)點就是它的insight。利用loss profile做異常檢測這個思路是非常新穎的,感覺是一個可以深挖的坑;此外,這個模型還可以定位到異常的位置,且從論文的實驗部分可以看出,該模型在工業(yè)數(shù)據(jù)集MVTec AD上表現(xiàn)也還不錯。所以是相對成熟的。缺點: 讀這篇文章的時候就會發(fā)現(xiàn),其實這篇文章涉及到的模型非常多,訓(xùn)練的tricks也很多。此外個人感覺這個模型雖然復(fù)雜,實際效果可能并不和其復(fù)雜度成正比,感覺有簡化的空間。但是總體來說還是一篇非常不錯、非常有借鑒意義的文章。 (CMU的四大之一的名頭果然名不虛傳)這一篇也是ECCV 2020上的一篇文章,做的是unsupervised的異常檢測。他們也提出了一個比較新穎的角度:用backpropagated gradient做異常檢測。個人感覺雖然沒有上一篇那么新穎,但是這個insight還是非常不錯的。 他們也是基于一個重要的觀察:當(dāng)一個auto-encoder在只包含正常樣本的訓(xùn)練集上訓(xùn)練好之后,如果再在一個正常樣本上訓(xùn)練,則模型通常只需要比較小的update;但是如果再在一個異常樣本上訓(xùn)練,由于這個樣本不同于之前所有的訓(xùn)練樣本,則模型需要比較大的update。update的不同體現(xiàn)在backpropagated gradient上。所以利用gradient的差異(文中用的是cosine similarity),就可以將正常樣本和異常樣本區(qū)分開來。 模型的結(jié)構(gòu)比較簡單,其實就是一個auto-encoder。所不同的是他們用的loss。所以下面將重點介紹loss: 總的loss ? 計算公式如下: 其中,? 乍一看很嚇人,其實不復(fù)雜。? 優(yōu)點: 據(jù)我所知應(yīng)該是第一篇將gradient用于異常檢測的文章,雖然gradient在其他領(lǐng)域可能不算是新穎的idea,在異常檢測領(lǐng)域還是比較新穎的;此外,如果閱讀原論文的話,可以發(fā)現(xiàn)文章從Geometric和Theory兩個角度對gradient的方法做了解讀,讓人不明覺厲 :-)缺點: 文章中只用gradient估計了圖片的anomaly score,但沒有定位anomaly的位置;此外,文章中experiment的datasets比較簡單,在更加復(fù)雜的異常檢測數(shù)據(jù)集上的表現(xiàn)有待檢驗。綜合來說,這篇文章也算是一篇挖坑之作,雖然個人覺得相對于上一篇loss profile異常檢測來說,idea不是那么新穎,且方法也沒有那么成熟(數(shù)據(jù)集較簡單且不能定位異常區(qū)域)。 到此為止,我最近看到的異常檢測方面的最新論文就介紹完畢了(完結(jié)撒花~)。感謝大家的閱讀、點贊、關(guān)注和評論中的鼓勵。其實每天看到自己寫的文章被閱讀、點贊,或者新增了關(guān)注還是很開心的。 雖然現(xiàn)在還是一個非常小的號,但是我會一直堅持寫下去,一方面是對自己的監(jiān)督和總結(jié),另一方面,人還是要有點夢想,說不定哪天我就成了百萬大V了呢(逃 【1】Gong D, Liu L, Le V, et al. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection[C]//Proceedin gs of the IEEE International Conference on Computer V i sion. 2019: 1705-1714. 【2】Park H, Noh J, Ham B. Learning Memory-guided Normality for Anomaly Detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 14372-14381. 【3】Zaheer M Z, Lee J, Astrid M, et al. Old is Gold: Redefining the Adversarially Learned One-Class Classifier Training Paradigm[C]//Proceedings of the IEEE/CVF Conference on Computer 【4】Xia Y, Zhang Y, Liu F, et al. Synthesize then Compare: Detecting Failures and Anomalies for Semantic Segmentation[J]. arXiv preprint arXiv:2003.08440, 2020. 【5】Bergmann, P., Fauser, M., Sattlegger, D., & Steger, C. (2020). Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4183-4192). 【6】Bergmann, P., Fauser, M., Sattlegger, D., & Steger, C. (2019). MVTec AD--A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 9592-9600). 【7】He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9729-9738). 【8】Yi, J., & Yoon, S. (2020). Patch SVDD: Patch-level SVDD for Anomaly Detection and Segmentation. arXiv preprint arXiv:2006.16067 【9】Chu W H, Kitani K M. Neural Batch Sampling with Reinforcement Learning for Semi-Supervised Anomaly Detection[D]. Carnegie Mellon University Pittsburgh, 2020. 【10】Kwon G, Prabhushankar M, Temel D, et al. Backpropagated Gradient Representations for Anomaly Detection[J]. arXiv preprint arXiv:2007.09507, 2020. 閱讀原文 可以參與異常檢測實踐


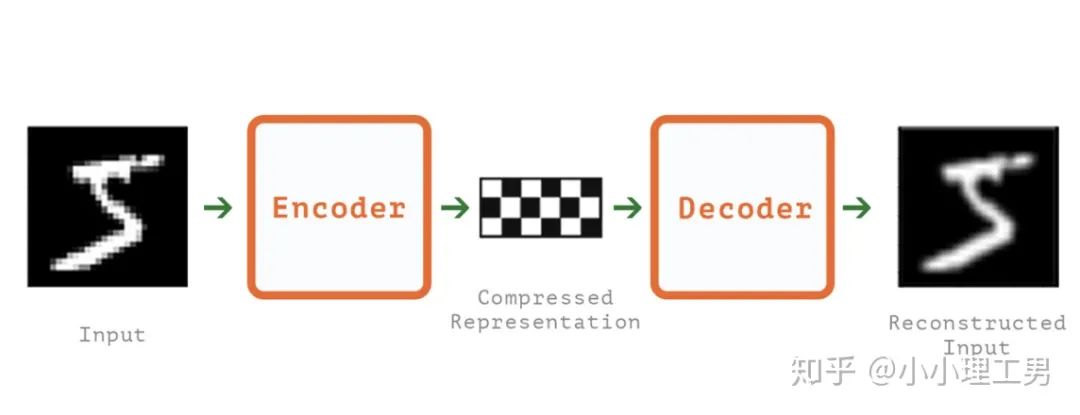 圖像空間上的異常檢測方法的主流結(jié)構(gòu)
圖像空間上的異常檢測方法的主流結(jié)構(gòu)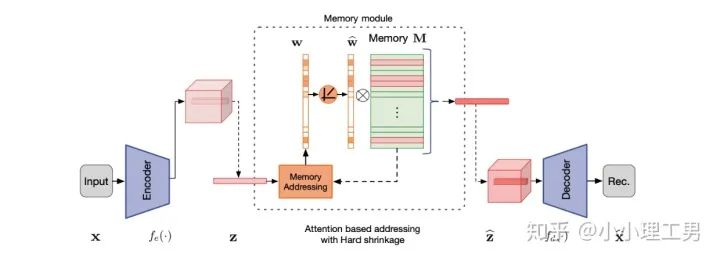
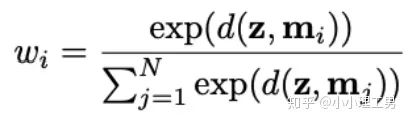
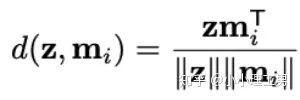
 ?為輸入圖像的embedding,?
?為輸入圖像的embedding,? ?為memory中第?
?為memory中第? ?個embedding,
?個embedding, ?為
?為

 ?,找到memory中與其距離最近的embedding?
?,找到memory中與其距離最近的embedding? ?,使得它們的距離越小越好。
?,使得它們的距離越小越好。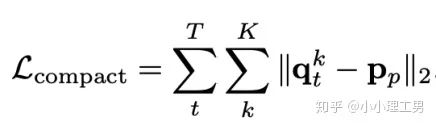
 ?和距離第二近的embedding?
?和距離第二近的embedding? ?,使得?
?,使得?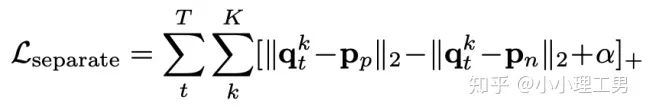
 OGNet框架
OGNet框架 ?),另一個是第一階段中訓(xùn)練的次數(shù)較少的generator(即圖中的?
?),另一個是第一階段中訓(xùn)練的次數(shù)較少的generator(即圖中的? ?)。認(rèn)為?
?)。認(rèn)為? ?(其實這個三角形應(yīng)該在X上面,但是我查不到怎么打出來QwQ,大家意會一下即可),再將?
?(其實這個三角形應(yīng)該在X上面,但是我查不到怎么打出來QwQ,大家意會一下即可),再將? ?.
?.
 ?和高質(zhì)量重構(gòu)圖像?
?和高質(zhì)量重構(gòu)圖像? ?為positive的類別,低質(zhì)量重構(gòu)圖像?
?為positive的類別,低質(zhì)量重構(gòu)圖像? 和偽異常重構(gòu)圖像?
和偽異常重構(gòu)圖像?

 ?。距離中心點在?
?。距離中心點在?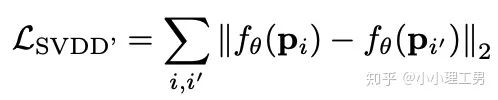
 ?是encoder,
?是encoder, ?和?
?和? ?是相鄰的某兩個patch,上面?
?是相鄰的某兩個patch,上面? ?的作用就是讓相鄰的patch的embedding盡可能接近。
?的作用就是讓相鄰的patch的embedding盡可能接近。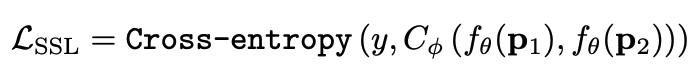
 ?是一個分類器,?
?是一個分類器,? ?是分類的label。大家讀到這里可能一頭霧水,我結(jié)合下面這張圖來解釋?
?是分類的label。大家讀到這里可能一頭霧水,我結(jié)合下面這張圖來解釋? ?是怎么讓不同patch的embedding具有區(qū)分度的。
?是怎么讓不同patch的embedding具有區(qū)分度的。
 ?)周圍8個方向分別有8個patch,我們將這8個patch按照相對于中心patch的方位依次標(biāo)記為?
?)周圍8個方向分別有8個patch,我們將這8個patch按照相對于中心patch的方位依次標(biāo)記為? ?。然后從這8個patch中隨機選一個patch(記為?
?。然后從這8個patch中隨機選一個patch(記為? ?),將?
?),將? ?和?
?和? ?)輸入分類器?
?)輸入分類器?
 ?為待檢測異常的patch,而?
?為待檢測異常的patch,而? ?則是訓(xùn)練集中正常的patch。通過尋找在embedding空間上與?
?則是訓(xùn)練集中正常的patch。通過尋找在embedding空間上與?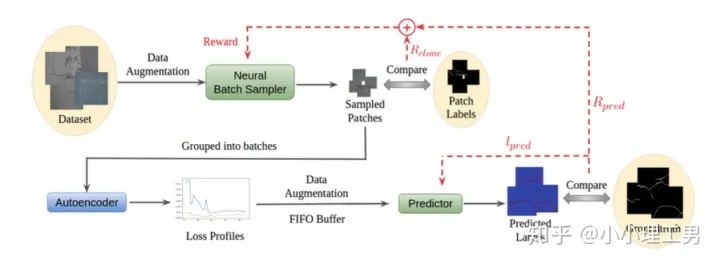 結(jié)構(gòu)圖
結(jié)構(gòu)圖 ?,還可以順帶給neural batch sampler一個reward?
?,還可以順帶給neural batch sampler一個reward?

 ?計算公式如下:
?計算公式如下: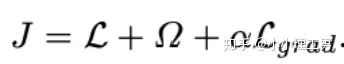
 為reconstruction loss,
為reconstruction loss, ?為latent loss,都是auto-encoder中常用的loss,這里就不多加贅述。?
?為latent loss,都是auto-encoder中常用的loss,這里就不多加贅述。? ?是文章的重點,正常樣本和異常樣本的gradient的差異就體現(xiàn)這個?
?是文章的重點,正常樣本和異常樣本的gradient的差異就體現(xiàn)這個?
 ?是當(dāng)前訓(xùn)練次數(shù),
?是當(dāng)前訓(xùn)練次數(shù), ?就是前?
?就是前? ?次訓(xùn)練的gradient平均,?
?次訓(xùn)練的gradient平均,? ?就是當(dāng)前訓(xùn)練的gradient。通過計算兩者的cosine similarity,如果cosine similarity較小,說明當(dāng)前訓(xùn)練帶給模型的變化較大,?
?就是當(dāng)前訓(xùn)練的gradient。通過計算兩者的cosine similarity,如果cosine similarity較小,說明當(dāng)前訓(xùn)練帶給模型的變化較大,?