
工業(yè)圖像異常檢測最新研究總結(2019-2020)
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達
導讀
?本文作者從圖像空間、特征空間、Loss profile 空間以及利用backpropagated gradient信息做異常檢測四個方面,結合2019年和2020的頂會論文,對工業(yè)圖像上的異常檢測的最新進展進行了總結。
寫在前面
1. 簡要地介紹一下什么是異常檢測(anomaly detection)

2. 圖像空間上的異常檢測方法
 圖像空間上的異常檢測方法的主流結構
圖像空間上的異常檢測方法的主流結構2.1 MemAE:利用Memory抑制模型的泛化能力
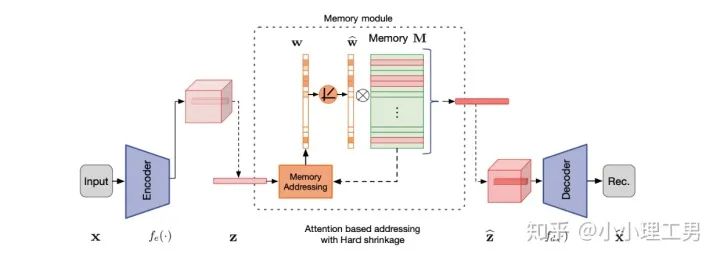
比較接近原本圖像的embedding; 由正常樣本的特征構成。
首先是在加權Memory中embedding時weight的計算: 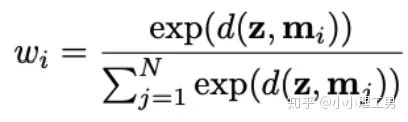

 ?為輸入圖像的embedding,?
?為輸入圖像的embedding,? ?為memory中第?
?為memory中第? ?個embedding,
?個embedding, ?為對應的權重。
?為對應的權重。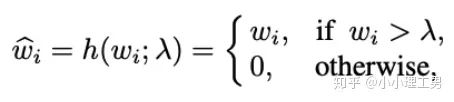
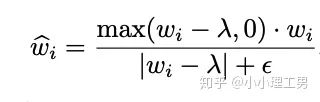
2.2 Memory的進一步改進
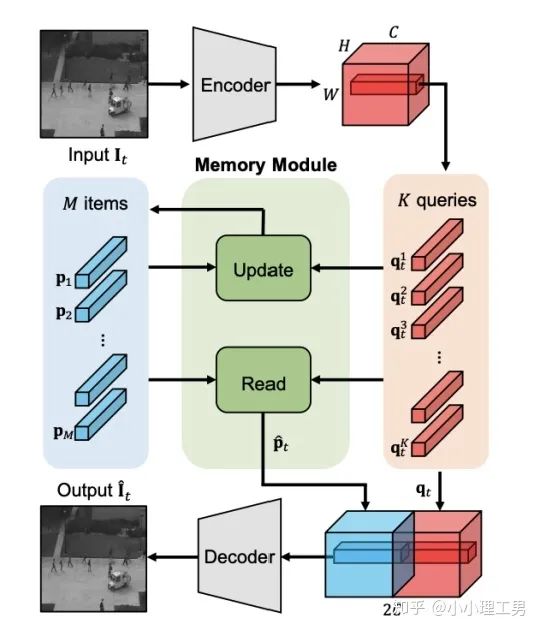
增加了memory update的機制,只需存儲固定個數(shù)的memory; 引入了feature compactness loss 和 feature separateness loss,減少需要保存的memory的數(shù)量; 采用了將原圖的embedding和memory中的embedding結合輸入decoder的方式,一定程度上解決了重構后的圖像比較糊的缺點,從而可以定位到異常區(qū)域的位置,從而可以運用到一些更加復雜、貼近現(xiàn)實情況的數(shù)據集上。
 ?,找到memory中與其距離最近的embedding?
?,找到memory中與其距離最近的embedding? ?,使得它們的距離越小越好。
?,使得它們的距離越小越好。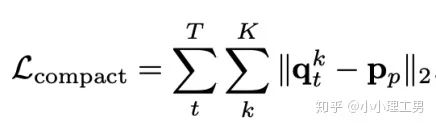 ?,找到memory中與其距離最近的embedding?
?,找到memory中與其距離最近的embedding? ?和距離第二近的embedding?
?和距離第二近的embedding? ?,使得??和??的距離越小越好,??和??的距離越大越好。
?,使得??和??的距離越小越好,??和??的距離越大越好。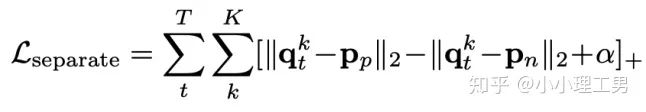
2.3 利用bad quality reconstructed image做異常檢測
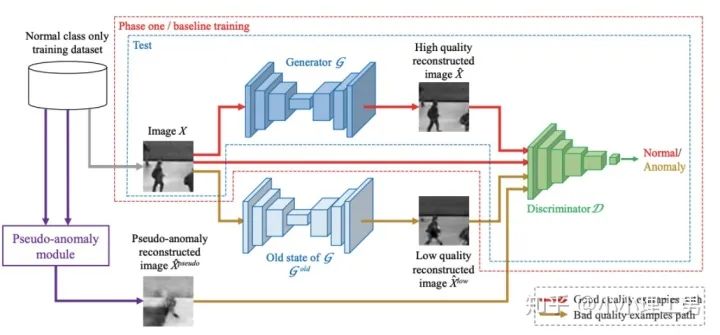 OGNet框架
OGNet框架Story:
用generator重構圖像,discriminator只是用來幫助generator更好地重構圖像。在判斷異常時,類似于auto-encoder檢測異常的思路,用generator重構后的圖像和原圖做對比,不同處認為是異常; 總體思路與1中類似,只是在檢測異常時,綜合generator和discriminator的結果作為判斷異常的依據。
如何生成高質量和低質量的重構圖像?
 ?),另一個是第一階段中訓練的次數(shù)較少的generator(即圖中的?
?),另一個是第一階段中訓練的次數(shù)較少的generator(即圖中的? ?)。認為??生成的圖像為高質量重構圖像,??生成的圖像為低質量重構圖像。?重構后將結果做pixel-level的平均,得到新的偽異常圖像?
?)。認為??生成的圖像為高質量重構圖像,??生成的圖像為低質量重構圖像。?重構后將結果做pixel-level的平均,得到新的偽異常圖像? ?(其實這個三角形應該在X上面,但是我查不到怎么打出來QwQ,大家意會一下即可),再將??用??再重構一遍就得到了偽異常重構圖像?
?(其實這個三角形應該在X上面,但是我查不到怎么打出來QwQ,大家意會一下即可),再將??用??再重構一遍就得到了偽異常重構圖像? ?.
?.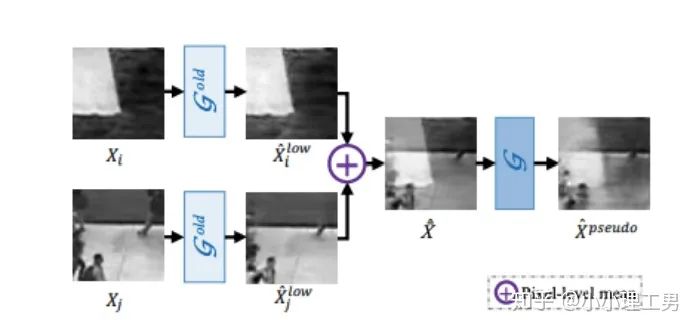
 ?和高質量重構圖像?
?和高質量重構圖像? ?為positive的類別,低質量重構圖像?
?為positive的類別,低質量重構圖像? 和偽異常重構圖像??為negative的類別。如下圖(7)式所示。
和偽異常重構圖像??為negative的類別。如下圖(7)式所示。
數(shù)據增強。用不充分訓練的generator和人為偽造出來的異常圖像作為負樣本,來訓練discriminator; 異常檢測任務轉移。將檢測異常的任務從generator或者generator與discriminator共同承擔,轉移到由discriminator承擔
2.4 利用image segmentation信息做異常檢測
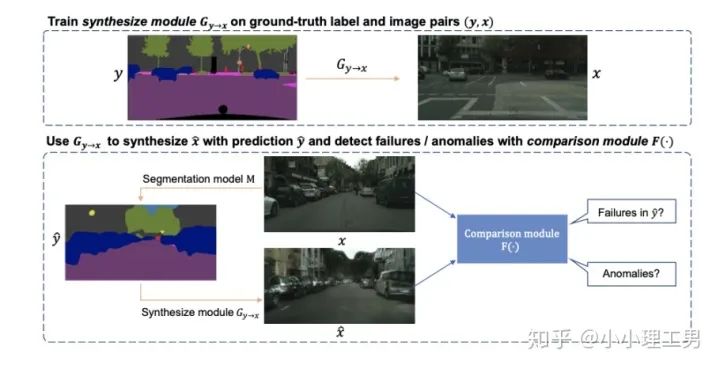

3. 特征空間上的異常檢測方法
3.1 利用teacher和students的差異做異常檢測
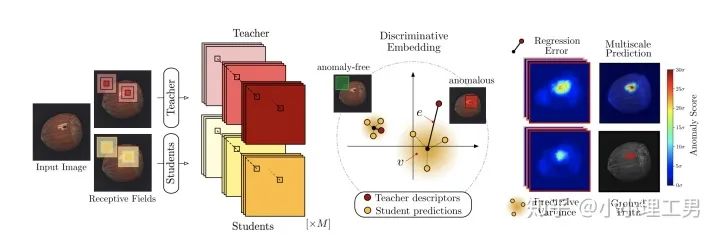
在僅包含正常樣本的數(shù)據集上,讓pretrained的teacher模型去教沒有pretrain的student模型,使得teacher模型和student模型輸出的embedding盡可能一致。那么在inference時,由于teacher只教過student如何embed正常樣本,所以正常樣本上teacher模型和student模型輸出的embedding會比較相似,但異常樣本上兩者輸出的embedding差異會比較大; 如果在1中的訓練過程中,采用多個隨即初始化的students模型和一個pretrained teacher模型,那么在正常樣本上students之間的embedding比較一致,而在異常樣本上,由于students是隨機初始化的,且teacher并沒有在異常樣本上教過他們,所以在students之間embedding差異也會比較大。
多尺度。由于模型的輸入都是patch,所以patch的大小直接決定了異常檢測的resolution。由于圖像中的異常大小不盡相同,當異常區(qū)域比較大時,用比較大的patch可能會比較好;反之,比較小的patch效果會比較好。所以文章中采用了三種邊長的正方形patch: 17, 33和64(單位為pixel)。將這三種patch size的結果做算數(shù)平均就得到了multi-scale的結果; 如何pretrain模型。現(xiàn)在有很多unsupervised pretrain的方法,例如MoCo。但是文章沒有采用這種unsupervised方法,而是用pretrained resnet-18,通過蒸餾得到了teacher模型。我個人比較困惑的一點是為什么不直接用pretrained resnet-18,可能是為了更快吧...(迷)
3.2 以patch為單位做SVDD
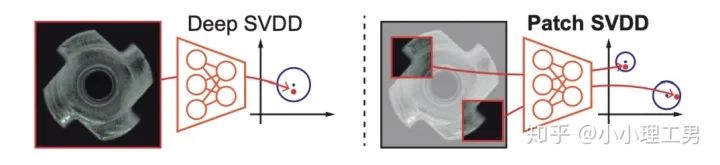
 ?。距離中心點在??以內的認為是正常樣本,否則認為是異常樣本。Deep SVDD則是將這個投影的過程用深度神經網絡處理,所以在SVDD前加了Deep。
?。距離中心點在??以內的認為是正常樣本,否則認為是異常樣本。Deep SVDD則是將這個投影的過程用深度神經網絡處理,所以在SVDD前加了Deep。
 ?是encoder,
?是encoder, ?和?
?和? ?是相鄰的某兩個patch,上面?
?是相鄰的某兩個patch,上面? ?的作用就是讓相鄰的patch的embedding盡可能接近。?,那么模型就會有讓所有的patch都輸出同一個embedding的趨勢,這肯定不是我們想要的。所以作者加入了另一個loss,SSL(self-supervised learning) loss,來使得不同patch的embedding具有一定區(qū)分度:
?的作用就是讓相鄰的patch的embedding盡可能接近。?,那么模型就會有讓所有的patch都輸出同一個embedding的趨勢,這肯定不是我們想要的。所以作者加入了另一個loss,SSL(self-supervised learning) loss,來使得不同patch的embedding具有一定區(qū)分度: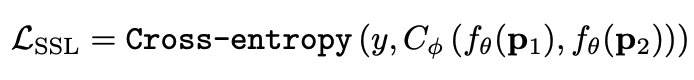 ?是encoder,?
?是encoder,? ?是一個分類器,?
?是一個分類器,? ?是分類的label。大家讀到這里可能一頭霧水,我結合下面這張圖來解釋?
?是分類的label。大家讀到這里可能一頭霧水,我結合下面這張圖來解釋? ?是怎么讓不同patch的embedding具有區(qū)分度的。
?是怎么讓不同patch的embedding具有區(qū)分度的。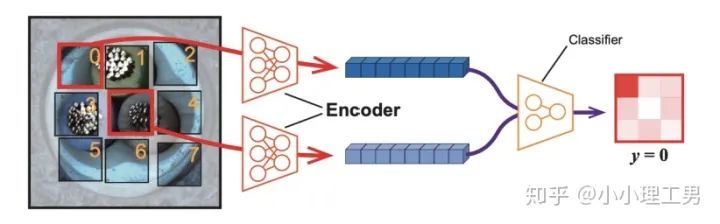
上圖中,中間的patch(記為?
 ?)周圍8個方向分別有8個patch,我們將這8個patch按照相對于中心patch的方位依次標記為?
?)周圍8個方向分別有8個patch,我們將這8個patch按照相對于中心patch的方位依次標記為? ?。然后從這8個patch中隨機選一個patch(記為?
?。然后從這8個patch中隨機選一個patch(記為? ?),將??和??的embedding(分別是?
?),將??和??的embedding(分別是? ?和?
?和? ?)輸入分類器??中,讓??來分類??相對于??的方位(即標簽??),最后用Cross Entropy Loss來計算分類器結果和標簽之間的損失。?將無法分辨出相鄰patch之間的相對方位,就會非常大。這樣就通過加入??避免了patch embedding完全一致的情況。
?)輸入分類器??中,讓??來分類??相對于??的方位(即標簽??),最后用Cross Entropy Loss來計算分類器結果和標簽之間的損失。?將無法分辨出相鄰patch之間的相對方位,就會非常大。這樣就通過加入??避免了patch embedding完全一致的情況。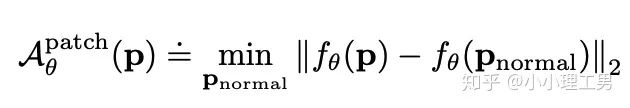
 ?為待檢測異常的patch,而?
?為待檢測異常的patch,而? ?則是訓練集中正常的patch。通過尋找在embedding空間上與??最近的那個正常patch,計算它們倆embedding之間的距離,作為??的anomaly score。即與正常patch的最近距離越大,異常越嚴重。
?則是訓練集中正常的patch。通過尋找在embedding空間上與??最近的那個正常patch,計算它們倆embedding之間的距離,作為??的anomaly score。即與正常patch的最近距離越大,異常越嚴重。信息提取不充分(這里和我現(xiàn)在做的工作有關,所以不詳細說了hhh) 訓練時使相鄰的patch特征聚合在一起,這個設想不一定合理 對于物品會旋轉的類別,判斷patch相對方位可能不合理
4. Loss profile 空間上做異常檢測
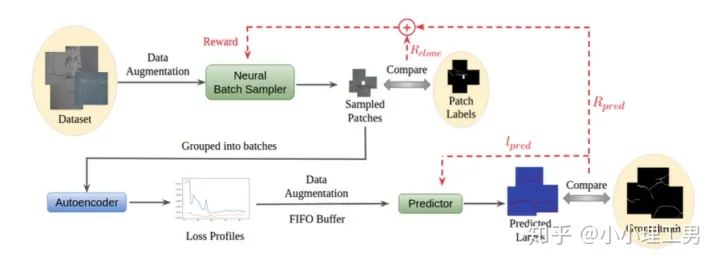 結構圖
結構圖Neural Batch Sampler
 ?,還可以順帶給neural batch sampler一個reward?
?,還可以順帶給neural batch sampler一個reward?
5. 利用backpropagated gradient信息做異常檢測
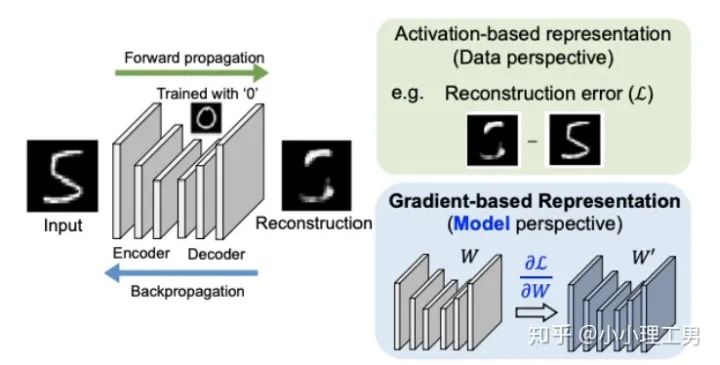
 ?計算公式如下:
?計算公式如下: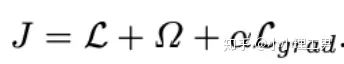
 為reconstruction loss,
為reconstruction loss, ?為latent loss,都是auto-encoder中常用的loss,這里就不多加贅述。?
?為latent loss,都是auto-encoder中常用的loss,這里就不多加贅述。? ?是文章的重點,正常樣本和異常樣本的gradient的差異就體現(xiàn)這個??上。?的計算公式如下:
?是文章的重點,正常樣本和異常樣本的gradient的差異就體現(xiàn)這個??上。?的計算公式如下:
 ?是當前訓練次數(shù),
?是當前訓練次數(shù), ?就是前?
?就是前? ?次訓練的gradient平均,?
?次訓練的gradient平均,? ?就是當前訓練的gradient。通過計算兩者的cosine similarity,如果cosine similarity較小,說明當前訓練帶給模型的變化較大,??也較大;反之說明當前訓練對模型改變不大,??也相應較小。
?就是當前訓練的gradient。通過計算兩者的cosine similarity,如果cosine similarity較小,說明當前訓練帶給模型的變化較大,??也較大;反之說明當前訓練對模型改變不大,??也相應較小。寫在后面
評論
圖片
表情