
【數(shù)據(jù)競(jìng)賽】競(jìng)賽常見問題解答
問題:Kaggle與國(guó)內(nèi)比賽有什么區(qū)別么?
Kaggle與國(guó)內(nèi)競(jìng)賽模式存在區(qū)別,比如Notebook平臺(tái)資源,其次Kaggle的分享機(jī)制比較好。
Kaggle整體面向全球,國(guó)內(nèi)人數(shù)也蠻多,整體難度也會(huì)更難。
問題:機(jī)器學(xué)習(xí)、深度學(xué)習(xí)算法方向,需要有多少數(shù)學(xué)基礎(chǔ)?
大學(xué)數(shù)學(xué)的基礎(chǔ)即可,特別是線性代數(shù)、矩陣計(jì)算。可以多關(guān)注如何計(jì)算和求導(dǎo)的過程,其他的過程可以之后用到再學(xué)。
問題:CV方面輕量化transformer有哪些idea,可以從哪些方面入手,可以不使用官方預(yù)訓(xùn)練評(píng)判模型效果嗎?
答:transformer在推薦系統(tǒng)和CV中有使用,具體可以參考CNN輕量化的思路。
問題:lightgbm如何調(diào)參?
可以關(guān)注比較核心的參數(shù):https://lightgbm.readthedocs.io/en/latest/Parameters-Tuning.html
同時(shí)也建議多去理解模型的參數(shù)含義,以及參數(shù)如何影響模型的精度。
問題:stacking具體的細(xì)節(jié)能講講嗎?
按照如下交叉驗(yàn)證的思路進(jìn)行,每個(gè)模型對(duì)訓(xùn)練集和測(cè)試集增加一列特征,迭代進(jìn)行。
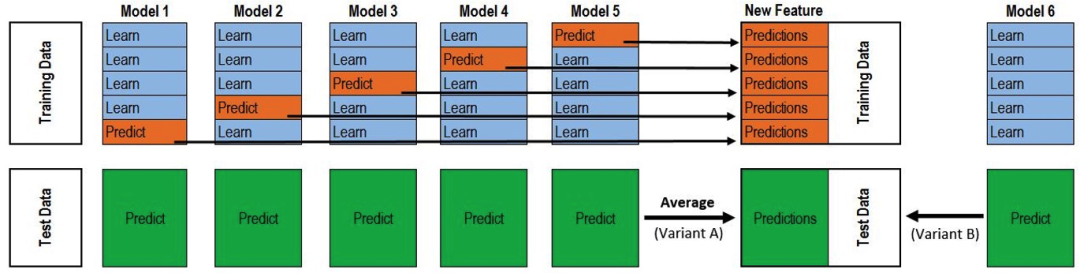
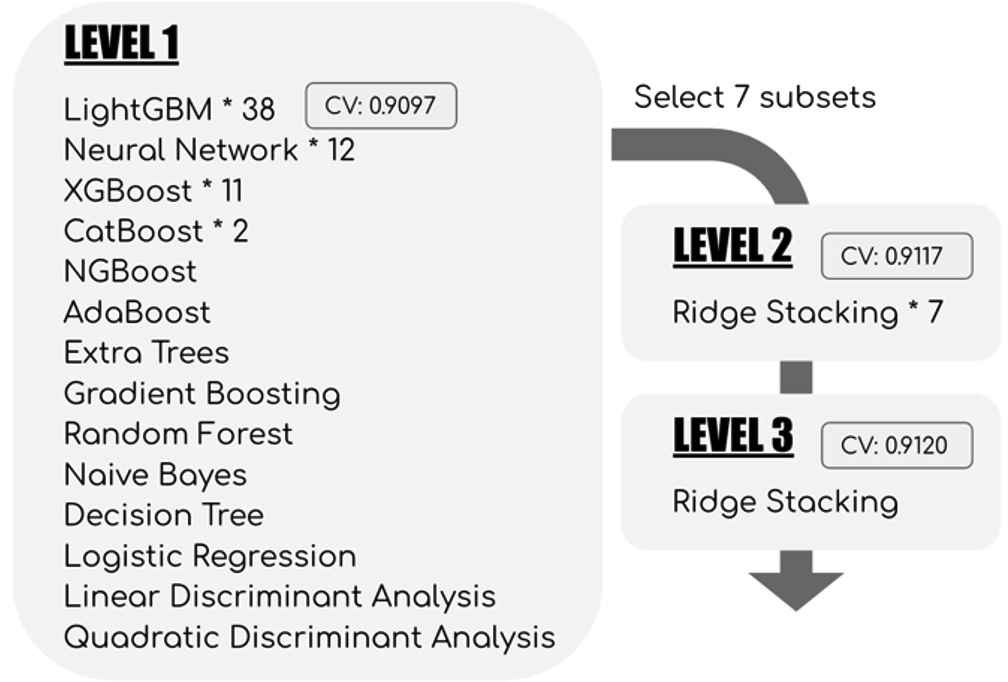
問題:智能科學(xué)與技術(shù)專業(yè)大四在讀,老師說畢業(yè)設(shè)計(jì)題目任選,且目前在準(zhǔn)備考研,想問關(guān)于選題有什么建議嗎?
首先建議考研方向和選題相關(guān),其次本科畢業(yè)設(shè)計(jì)其實(shí)要求不是很多,要么是做應(yīng)用,要么是研究。
問題:能說一下,對(duì)于nan值的處理方法嗎?
你應(yīng)該知道數(shù)據(jù)是如何產(chǎn)生的,哪些特征對(duì)業(yè)務(wù)有影響,只有這樣你才能給出最好的數(shù)據(jù)結(jié)果。
具體參考我們之前的文章Kaggle知識(shí)點(diǎn):缺失值處理方法
問題:怎么處理數(shù)據(jù)類別極度不均衡的情況?
可以從損失函數(shù)、樣本權(quán)重、評(píng)價(jià)指標(biāo)、數(shù)據(jù)采樣考慮。調(diào)節(jié)權(quán)重與采樣在概率部分存在區(qū)別,采樣后的模型的輸出概率需要校準(zhǔn)。
問題:回歸用什么損失函數(shù)比較好,訓(xùn)練后期進(jìn)行驗(yàn)證,驗(yàn)證集上指標(biāo)有1到3個(gè)點(diǎn)波動(dòng)正常嗎?
這個(gè)看看數(shù)據(jù)量和標(biāo)簽量級(jí),從文字表達(dá)暫時(shí)看不出問題。
問題:如果構(gòu)造一個(gè)驗(yàn)證集?
首先分任務(wù),時(shí)序任務(wù) & 非時(shí)序任務(wù)
時(shí)序任務(wù):與測(cè)試集最近的一天 & 最相似的一天作為驗(yàn)證集 非時(shí)序任務(wù):按照樣本的分布采樣驗(yàn)證集
問題:小白不知道怎么開始一個(gè)有質(zhì)量的競(jìng)賽
推薦先掌握pandas、sklearn工具,理論和工具不斷累計(jì)即可。
問題:結(jié)構(gòu)化數(shù)據(jù)中的文本特征應(yīng)該如何處理,(不采用nn,使用樹模型的話)
-?文本?->?分詞?-> TFIDF -> SVD/PCA/LDA降維
-?文本?->?嵌入?->?mean/max?pooling
問題:如何形成規(guī)模的代碼塊?
可以按照模型API、數(shù)據(jù)特征處理、特征編碼
問題:對(duì)數(shù)據(jù)比賽無從下手,該從什么地方開始好?或者很難在baseline上做提升,怎么辦?
如果無從下手,可以去嘗試做一個(gè)baseline。如果想對(duì)baseline做改進(jìn),可以從驗(yàn)證集的分?jǐn)?shù)去分析,然后做改進(jìn),可以參考類似的模型,或者添加業(yè)務(wù)特征。
問題:就那種用歷史數(shù)據(jù)預(yù)測(cè)未來數(shù)據(jù)時(shí),如何構(gòu)造特征呢
序列的模式,趨勢(shì)、周期、相關(guān)性、隨機(jī)性 自回歸 & 多元回歸
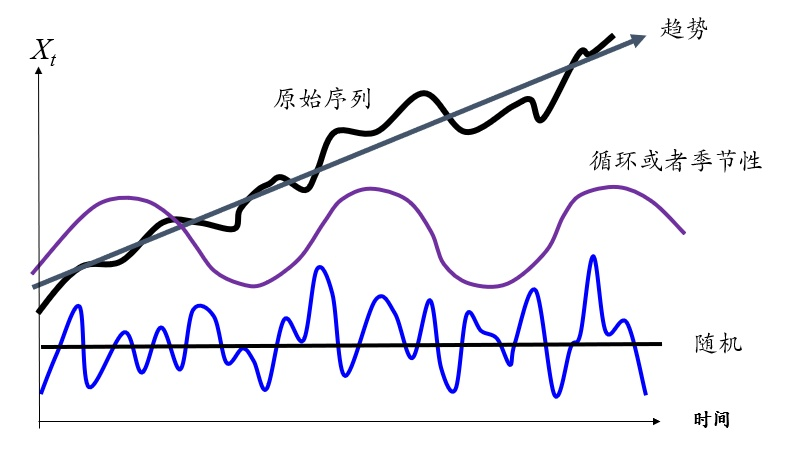
問題:全是匿名字段的結(jié)構(gòu)化數(shù)據(jù)應(yīng)該怎么進(jìn)行特征構(gòu)造和eda探索呢。
首先看字段類型、看字段分布、相關(guān)性
問題:想請(qǐng)教水哥和魚佬,業(yè)內(nèi)通常是怎么做分布式訓(xùn)練的呀?
工業(yè)主要看庫和平臺(tái),具體的方法有模型并行,數(shù)據(jù)并行和參數(shù)平均。
具體細(xì)節(jié)可以參考:《分布式機(jī)器學(xué)習(xí):算法、理論與實(shí)踐》
問題:torch和tensorflow推薦?
初學(xué)者torch,tensorflow1.X比較多,paddlepaddle也是不錯(cuò)的選擇。
問題:在分類問題中,對(duì)于樹模型輸出的特征重要度里面有些重要度為0的特征,drop后auc下降了,那這類特征需要?jiǎng)h除嗎?
樹模型的特征重要性和最終的得分并不是一致的,這里可以通過模型包裹式來選擇特征。
問題:魚佬,你的書有推薦的閱讀路線嗎?小白讀的讀起來有點(diǎn)難懂。
如果數(shù)據(jù)集比較大可以用部分?jǐn)?shù)據(jù)集進(jìn)行訓(xùn)練,小白建議按照章節(jié)依次閱讀。
往期精彩回顧 本站qq群554839127,加入微信群請(qǐng)掃碼: