
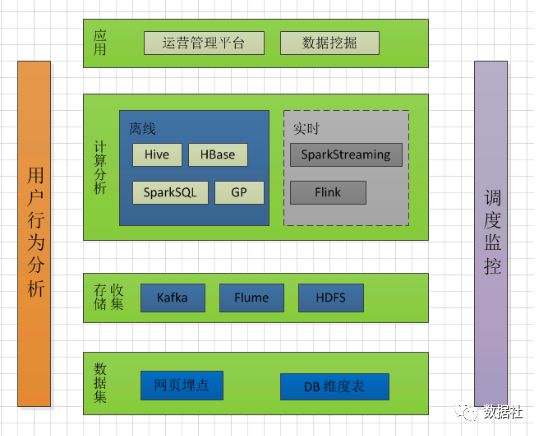
用戶行為分析之?dāng)?shù)據(jù)采集
用戶行為分析主要關(guān)心的指標(biāo)可以概括如下:哪個用戶在什么時候做了什么操作在哪里做了什么操作,為什么要做這些操作,通過什么方式,用了多長時間等問題,總結(jié)出來就是WHO,WHEN,WHERE,WHAT,WHY以及HOW,HOW TIME。
根據(jù)以上5個W和2H,我們來討論下們?nèi)绾螌崿F(xiàn)。
WHO,首先需要x獲取登陸用戶個人的信息。用戶名稱,角色等
WHEN,獲取用戶訪問頁面每個模塊的時間,開始時間,結(jié)束時間等
WHAT,獲取用戶登陸頁面后都做了什么操作,點擊了哪些頁面以及模塊等
WHY,分析用戶點擊這些模塊的目的是什么
HOW,用戶通過什么方式訪問的系統(tǒng),web,APP,小程序等
HOW TIME,用戶訪問每個模塊,瀏覽某個頁面多長時間等
以上都是我們要獲取的數(shù)據(jù),獲取到相關(guān)數(shù)據(jù)我們才能接著分析用戶的行為。
用戶行為數(shù)據(jù)采集
埋點
埋點一般分為無埋點和代碼埋點。這兩種各有優(yōu)缺點,這里只做一個簡單的介紹:
全埋點是前端的一種埋點方式, 在產(chǎn)品中嵌入SDK,最統(tǒng)一的埋點,通過界面配置的方式對關(guān)鍵的行為進行定義,完成埋點采集,這種是前端埋點方式之一。
優(yōu)勢:
可視化展示宏觀指標(biāo),滿足基礎(chǔ)分析需求,如PV,UV,每個控件的點擊聯(lián)系
使用和部署較簡單,只需要嵌入SDK,避免了很多因為需求變更,埋點錯誤等導(dǎo)致需要重新埋點(這個深有體會)
用戶友好性強,觸發(fā)埋點之后自動向服務(wù)器發(fā)送數(shù)據(jù),避免人為失誤
劣勢:
作為前端埋點會存在一些天然的劣勢
只能采集用戶交互數(shù)據(jù),對于一些關(guān)鍵行為還是需要代碼埋點
兼容性問題
數(shù)據(jù)采集不全面,傳輸問題,時效性,數(shù)據(jù)可靠性
代碼埋點,這個也是目前我們使用的埋點方式,代碼埋點分為前端代碼埋點和后端代碼埋點,前端埋點類似于全埋點,也需要嵌入SDK,不同的是對于每個事件行為都需要調(diào)用SDK代碼,傳入必要的事件名,屬性參數(shù)等等,然后發(fā)到后臺數(shù)據(jù)服務(wù)器。后端埋點則將事件、屬性通過后端模塊調(diào)用SDK接口方式發(fā)送到后臺服務(wù)器。
我們采用的是代碼埋點,分為前后端。埋點是一個特別重要的過程,它是數(shù)據(jù)的源頭,如果數(shù)據(jù)源頭出現(xiàn)問題,那么數(shù)據(jù)本身就存在問題,分析結(jié)果也就喪失了意義。
由于我負責(zé)日志檢測,也就是埋點后的事件日志的檢測告警,并通知對應(yīng)的埋點開發(fā)人員,運營方,產(chǎn)品方,所以也就遇到了過其中存在的很多坑,大部分是流程方面的。
事件屬性是有一套元數(shù)據(jù)管理系統(tǒng),業(yè)內(nèi)的一些服務(wù)也是這種結(jié)構(gòu)。一般是先定義事件、屬性,后埋點的方式,原因是事件日志數(shù)據(jù)是需要經(jīng)過檢查的,需要檢查事件是否存在,屬性是否缺失,數(shù)據(jù)是否正常等等。
遇到的坑:
運營產(chǎn)品未定義,開發(fā)便已經(jīng)埋點上線
運營產(chǎn)品和埋點開發(fā)的需求文檔有問題或者溝通問題或開發(fā)未按照規(guī)范
導(dǎo)致事件對不上,屬性字段對不上,缺失或格式存在問題
開發(fā)埋點漏埋點,埋點不全,或者埋點邏輯有問題出現(xiàn)重復(fù)埋點,出現(xiàn)重復(fù)數(shù)據(jù)
屬性數(shù)據(jù)對不上
元數(shù)據(jù)定義,運營人員的理解和給開發(fā)的需求以及開發(fā)的理解可能不對應(yīng),但最終檢測邏輯只會按照定義的情況判斷
數(shù)據(jù)不對,這種情況很難檢測出來,需要運營產(chǎn)品在分析中發(fā)現(xiàn),這也是就難受的一點
有了上面的思路,下面我們來說下實現(xiàn)的相關(guān)技術(shù)問題,如何落地用戶行為分析。
數(shù)據(jù)采集
根據(jù)運營定義好的埋點接口形式獲取到的用戶的訪問日志數(shù)據(jù),一定要提前后端和前端定義好數(shù)據(jù)的保存格式,也就是保存哪些字段內(nèi)容,需要把埋點數(shù)據(jù)按照約定的格式統(tǒng)一封裝,以便于存儲分析。
下面該數(shù)據(jù)采集神器Flume出場了。
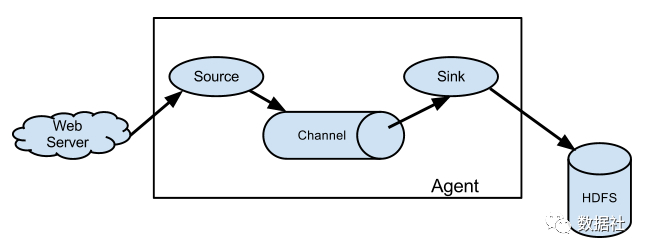
source 可以接收外部源發(fā)送過來的數(shù)據(jù)。不同的 source,可以接受不同的數(shù)據(jù)格式。比如有目錄池(spooling directory)數(shù)據(jù)源,可以監(jiān)控指定文件夾中的新文件變化,如果目錄中有文件產(chǎn)生,就會立刻讀取其內(nèi)容。
channel 是一個存儲地,接收 source 的輸出,直到有 sink 消費掉 channel 中的數(shù)據(jù)。channel 中的數(shù)據(jù)直到進入到下一個channel中或者進入終端才會被刪除。當(dāng) sink 寫入失敗后,可以自動重啟,不會造成數(shù)據(jù)丟失,因此很可靠。
sink 會消費 channel 中的數(shù)據(jù),然后送給外部源或者其他 source。如數(shù)據(jù)可以寫入到 HDFS 或者 HBase 中。
實時的埋點數(shù)據(jù)采集一般會與兩種方法:
直接觸發(fā)的日志發(fā)送到指定的HTTP端口,寫入kafka,然后Flume消費kafka到HDFS
用戶訪問日志落磁盤,在對應(yīng)的主機上部署flume agent,采集日志目錄下的文件,發(fā)送到kafka,然后在云端部署flume消費kafka數(shù)據(jù)到HDFS中
那么Flume 采集系統(tǒng)的搭建相對簡單,只需要兩步:
在服務(wù)器上部署 agent 節(jié)點,修改配置文件
啟動 agent 節(jié)點,將采集到的數(shù)據(jù)匯聚到指定的 HDFS 目錄中
flume配置模板:
a1.sources = source1a1.sinks = k1a1.channels = c1a1.sources.source1.type = org.apache.flume.source.kafka.KafkaSourcea1.sources.source1.channels = c1a1.sources.source1.kafka.bootstrap.servers = kafka-host1:port1,kafka-host2:port2...a1.sources.source1.kafka.topics = flume-testa1.sources.source1.kafka.consumer.group.id = flume-test-group# Describe the sinka1.sinks.k1.type = hdfsa1.sinks.k1.hdfs.path = /tmp/flume/test-dataa1.sinks.k1.hdfs.fileType=DataStream# Use a channel which buffers events in memorya1.channels.c1.type = memorya1.channels.c1.capacity = 100a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channela1.sources.source1.channels = c1a1.sinks.k1.channel = c1
? ??