
elasticsearch 增刪改查底層原理


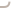
點擊上方藍色“邁莫coding”,選擇“設為星標”
一、預備知識
?
在對document的curd進行深度分析之前,我們不得不了解以下幾個小的知識點,不了解一下幾個知識點我們將很難理解document是如何進行增刪改查的。
?
11.1、路由(索引)與primary shard不可變
大家有沒有考慮過這個問題,當你索引一個文檔,它被存儲在單獨一個主分片上。
?
Elasticsearch是如何知道文檔屬于哪個分片的呢?當你創(chuàng)建一個新文檔,它是如何知道是應該存儲在分片1還是分片2上的呢?進程不能是隨機的,因為我們將來要檢索文檔。事實上,它根據(jù)一個簡單的算法決定:
shard = hash(routing) % number_of_primary_shards?
routing值是一個任意字符串,它默認是?_id 但也可以自定義。這個 routing 字符串通過哈 希函數(shù)生成一個數(shù)字,然后除以主切片的數(shù)量得到一個余數(shù)(remainder),余數(shù)的范圍永遠 是 0 到 number_of_primary_shards - 1 ,這個數(shù)字就是特定文檔所在的分片。
?
這也解釋了為什么主分片的數(shù)量只能在創(chuàng)建索引時定義且不能修改:如果主分片的數(shù)量在未來改變了,所有先前的路由值就失效了,文檔也就永遠找不到了。
?
我們演示一下這個路由的過程。假設我們有三個節(jié)點,一個student索引,對應有三個primary shard和一個replica shard。此時集群如圖1所示
?
?
向該節(jié)點中插入一個document,并且我們指定_id(在es中_id可以自定義es也可以自動生成)假如_id = 1000,根據(jù)我們上面描述,此時會按照如下算法計算其會命中哪個shard。假設此時hash(1000)= 13;
shard?=?hash(routing)?%?number_of_primary_shards即:
shard = 13 % 3 = 1;(假設hash(1000) = 13)
注:因為es的hash函數(shù)具體是怎么計算的不得而知,也不重要,我們主要是關(guān)注其原理。
?
?根據(jù)計算可得該插入請求會命中P1,shard此時會將該document插入到P1。是不是很簡單。
?
以上也可就是es路由的過程,也可稱為es索引(這個索引是動詞,理解一下)過程。?
?
?
在es集群中每個節(jié)點,每個shard(包括primary shard和replica shard)都具備處理任何請求的能力。這意味著在es集群中節(jié)點間是高度的負載均衡的,即并不是只有主節(jié)點是流量的入口,每個節(jié)點都具備處理請求的能力。primary shard和replica shard也是高度負載均衡的,因為并不是只有primary shard才具備處理curd的能力,replica shard可處理檢索的請求。這也是es的性能為什么表現(xiàn)這么好的原因之一。
?
二、document增、刪、改
12.1、增刪改過程分析
?
新建、索引和刪除請求都是寫(write)操作,它們必須在primary shard上成功完成才能復制到相關(guān)的replica shard分片上。
?
關(guān)于新增document索引過程可以參考
?elasticsearch?document的索引過程分析
公眾號:邁莫codingelasticsearch document的索引過程分析?
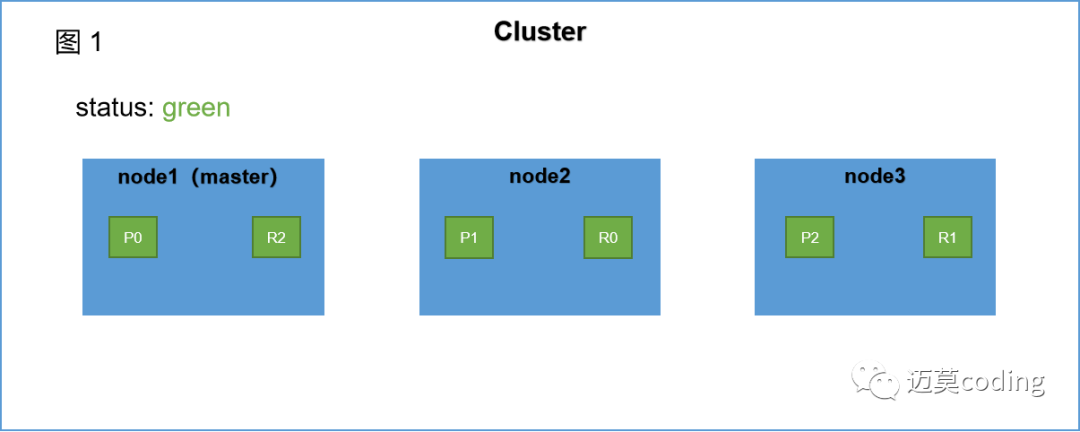
?
?如上圖所示,從客戶端發(fā)起請求到es集群向客戶端響應大致可以分為以上6個階段。
?
階段1:
客戶端向node1發(fā)起增、刪、改請請求。node1將作為協(xié)調(diào)節(jié)點(coordinate node)進行相關(guān)工作。
?
階段2:
?
?node1根據(jù)文檔 _id 計算出命中的primary shard為P1,然后將請求轉(zhuǎn)發(fā)到node2,P1分片位于node2上面。
?
階段3:
node2在P1上處理該請求。如果請求處理成功,node2將會把請求繼續(xù)轉(zhuǎn)發(fā)到其副本R1上。R1位于node3。
?
階段4:
?
?node3在R1上處理完該請求,如果成功,node3會將處理成功的消息返回給node2。
?
階段5:
?
?node2收到P1副本處理成功的消息,也就意味著該請求已經(jīng)處理完成。然后將處理結(jié)果返回給node1節(jié)點。
?
階段6:
?
協(xié)調(diào)節(jié)點node1收到響應結(jié)果后,將該結(jié)果返回給客戶端。
整個過程就完成了。
?
看到這里大家是不是也在思考一個請求進來,我還要等待所有的分片都處理完成這個操作才算是完成,這樣是不是很影響響應速度。基于這個思考,es同樣也給我們提供了自定義參數(shù)的支持,比如我們可以使用replication參數(shù)來指定primary shard是不是要等到replica shard處理完成后才能響應到客戶端。但是,該配置配置參數(shù)并不推薦使用,大家知道有這么個東西就行了。
?
replication:默認值為 sync ?該值意味著primary shard需要等到其所有的副本分片都完成后才會響應客戶端。如果我們將該值設置為 async ,意味著primary shard完成后就會返回給客戶端,但是并不意味著其不會將請求轉(zhuǎn)發(fā)到副本上,主分片依然會將請求轉(zhuǎn)發(fā)到replica shard上,只不過我們不再確定副本是不是也完成了該請求,這樣將不能保證數(shù)據(jù)的一致性。
?
12.1、寫一致性保障
?
首先需要說明的一點,增刪改其實都是一個寫操作,所以這里的寫指的是增刪改三個操作。
?
這里我們所說的寫一致性指的是primary shard和replica shard上數(shù)據(jù)的一致性。es API為我們提供了一個可自定的參數(shù)consistency。該參數(shù)可以讓我們自定義處理一次增刪改請求,是不是必須要求所有分片都是active的才會執(zhí)行。
?
該參數(shù)可選的值有三個:one,all,quorum(default,默認)。
1 one:要求我們這個寫操作,只要有一個primary shard是active活躍可用的,就可以執(zhí)行。2 all:要求我們這個寫操作,必須所有的primary shard和replica shard都是活躍的,才可以執(zhí)行這個寫操作3 quorum:默認的值,要求所有的shard中,必須是大部分的shard都是活躍的,可用的,才可以執(zhí)行這個寫操作
?
?上面三點其實很好理解,只有quorum所謂的“大部分”感覺不是那么的明確。下面有個公式,當集群中的active(可用)分片數(shù)量達到如下公式結(jié)果時寫操作就是可以執(zhí)行的。否則該操作將無法進行。
?
int( (primary + number_of_replicas) / 2 ) + 1?
依然用我們上面的例子,假設我們創(chuàng)建了一個student索引,并且設置primary shard為3個,replica shard有1個(這個1個是相對于索引來說的,對于主分片該數(shù)字1意味著每個primary shard都對應的存在一個副本)。也就意味著primary=3,number_of_replicas=1(依然是相對于索引)。shard總數(shù)為6。
?
此時計算上面公式可知:
int((3+1)/2) + 1 = 3?
也就是說當集群中可用的shard數(shù)量>=3寫操作就是可以執(zhí)行的。
?
說了這么多好像還沒解釋以上跟寫一致性有什么關(guān)系。es對寫一致性的保證就是通過quorum來保證的,以為quorum要求es集群中的可用shard數(shù)量達到一定要求才能執(zhí)行。也就間接保證了shard的數(shù)據(jù)一致性。
?
具體使用也很簡單
?
PUT /index/type/id?consistency=quorum?
?當然如果我們不指定就是使用默認的,也就是quorum。
?
三、document檢索
?
document的檢索過程和增刪改略有不同:文檔能夠從主分片(primary shard)或任意一個復制分片(replicashard)被檢索。
?
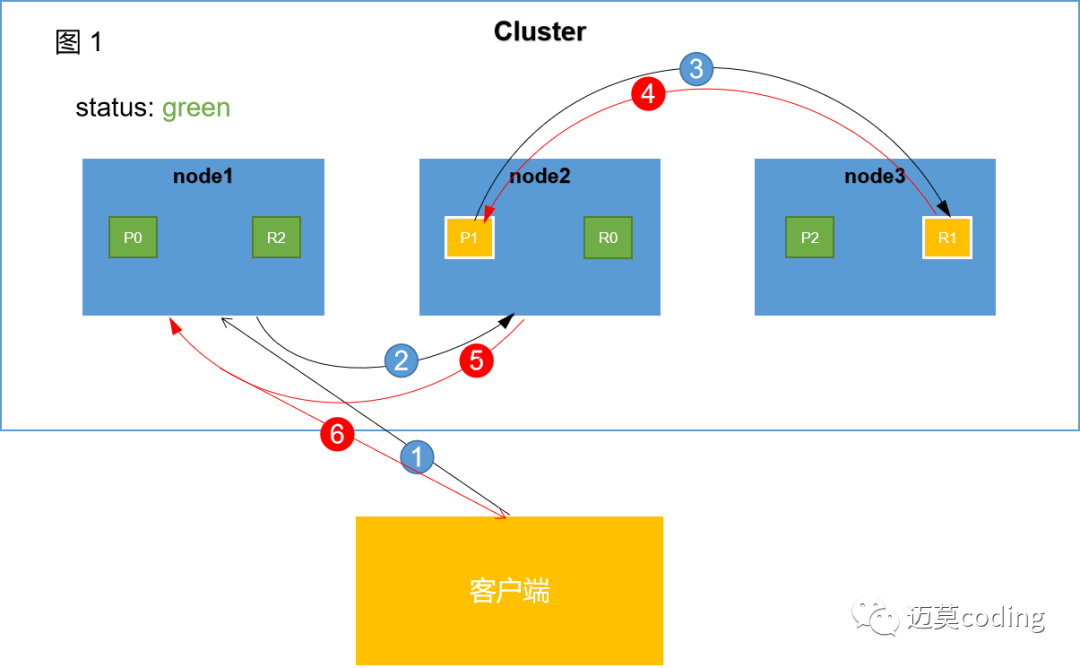
?
?
檢索過程大致可以分為4個階段
?
階段1:
?
客戶端向node1發(fā)送檢索請求。node1將作為協(xié)調(diào)節(jié)點(coordinate node)進行相關(guān)工作。
?
階段2:
node1根據(jù)文檔 _id 計算出命中的primary shard為P1,node1會找到P1的所有副本,然后通過round-robin隨機輪詢算法,在primary shard以及其所有replica中隨機選擇一個,讓讀請求負載均衡。假如此時隨機選取的是P1,node1會將該請求轉(zhuǎn)發(fā)到P1對應的節(jié)點上。
?
階段3:
?
?P1處理完該請求將結(jié)果返回給協(xié)調(diào)節(jié)點node1。
?
階段4:
協(xié)調(diào)節(jié)點node1收到該node2的相應結(jié)果,進而將該結(jié)果返回給客戶端。
?
可能的情況是,一個被索引的文檔已經(jīng)存在于主分片上卻還沒來得及同步到復制分片上。這時復制分片會報告文檔未找到,主分片會成功返回文檔。一旦索引請求成功返回給用戶,文檔則在主分片和復制分片都是可用的。
?
對與mget和bulk批量請求,與單文檔檢索還有一點區(qū)別,差別是協(xié)調(diào)節(jié)點需要計算每個文檔所在的分片。它把多文檔請求拆成每個分片的對文檔請求,然后轉(zhuǎn)發(fā)每個參與的節(jié)點。一旦接收到每個節(jié)點的應答,然后整理這些響應組合為一個單獨的響應,最后返回給客戶端。
分割線
原文地址:https://www.cnblogs.com/hello-shf/p/11543480.html
往期推薦
文章也會持續(xù)更新,可以微信搜索「 邁莫coding 」第一時間閱讀。每天分享優(yōu)質(zhì)文章、大廠經(jīng)驗、大廠面經(jīng),助力面試,是每個程序員值得關(guān)注的平臺。
你點的每個贊,我都認真當成了喜歡