
【NLP】使用Google的T5提取文本特征
編譯 | VK
來(lái)源 | Towards Data Science
下圖是文本到文本框架的示意圖。每個(gè)任務(wù)都使用文本作為模型的輸入,通過(guò)訓(xùn)練生成一些目標(biāo)文本。
這允許在不同的任務(wù)中使用相同的模型、損失函數(shù)和超參數(shù),包括翻譯(綠色)、語(yǔ)言可接受性(紅色)、句子相似性(黃色)和文檔摘要(藍(lán)色)。

在本文中,我們將演示如何使用Google T5對(duì)表格數(shù)據(jù)中的文本進(jìn)行特征化。你可以使用這個(gè)存儲(chǔ)庫(kù)中的Jupyter筆記本:
https://github.com/mikewcasale/nlp_primitives
當(dāng)試圖在機(jī)器學(xué)習(xí)管道中利用真實(shí)世界的數(shù)據(jù)時(shí),通常會(huì)遇到書(shū)面文本—例如,在預(yù)測(cè)房地產(chǎn)估價(jià)時(shí),有許多數(shù)字特征,例如:
“臥室數(shù)量”
“浴室數(shù)量”
“面積(平方英尺)”
“緯度”
“經(jīng)度”
等等…
但同時(shí),也有大量的書(shū)面文本,比如在Zillow等網(wǎng)站的房地產(chǎn)上市描述中。這些文本數(shù)據(jù)可以包括許多其他方面沒(méi)有考慮到的有價(jià)值的信息,例如:
開(kāi)放式廚房/平面圖
花崗巖個(gè)數(shù)
硬木地板
不銹鋼電器
最近的裝修
等等…
然而,令人驚訝的是,許多AutoML工具完全忽略了這些信息,因?yàn)橹T如XGBoost之類(lèi)的流行表格算法不能直接使用書(shū)面文本。
這就是Featuretools基本函數(shù)的用武之地。Featuretools旨在為不同類(lèi)型的數(shù)據(jù)(包括文本)自動(dòng)創(chuàng)建特征,然后表格機(jī)器學(xué)習(xí)模型可以使用這些數(shù)據(jù)。
在本文中,我們將展示如何擴(kuò)展nlp Primitive庫(kù),以便與Google最先進(jìn)的T5模型一起使用,并在此過(guò)程中創(chuàng)建最重要的nlp特征,進(jìn)而提高準(zhǔn)確性。
關(guān)于T5
對(duì)于任何不熟悉T5的讀者來(lái)說(shuō),T5模型出現(xiàn)在谷歌的論文中,題目是Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer。
使用Hugging Face T5的一個(gè)機(jī)器學(xué)習(xí)demo

在NLP的背景下,Hugging Face Transformers是一個(gè)自然語(yǔ)言處理庫(kù),對(duì)很多ML模型開(kāi)放,并得到了像Flair、Asteroid、ESPnet、Pyannote等庫(kù)的支持。
為了擴(kuò)展NLP庫(kù)以便與T5一起使用,我們將構(gòu)建兩個(gè)自定義TransformPrimitive類(lèi)。出于實(shí)驗(yàn)?zāi)康模覀儨y(cè)試了兩種方法:
微調(diào)Hugging Face T5-base
Hugging Face T5-base的情感分析
首先,讓我們加載基本模型。
from simpletransformers.t5
import T5Modelmodel_args = {
"max_seq_length": 196,
"train_batch_size": 8,
"eval_batch_size": 8,
"num_train_epochs": 1,
"evaluate_during_training": True,
"evaluate_during_training_steps": 15000,
"evaluate_during_training_verbose": True,
"use_multiprocessing": False,
"fp16": False,
"save_steps": -1,
"save_eval_checkpoints": False,
"save_model_every_epoch": False,
"reprocess_input_data": True,
"overwrite_output_dir": True,
"wandb_project": None,
}
model = T5Model("t5", "t5-base", args=model_args)
第二,讓我們加載預(yù)訓(xùn)練模型。
model_pretuned_sentiment = T5Model('t5',
'mrm8488/t5-base-finetuned-imdb-sentiment',
use_cuda=True)
model_pretuned_sentiment.args
為了對(duì)t5模型進(jìn)行微調(diào),需要對(duì)訓(xùn)練數(shù)據(jù)進(jìn)行重組和格式化。
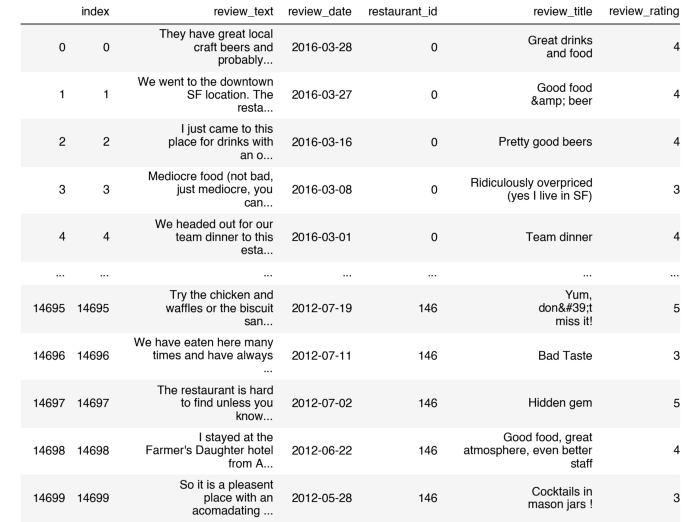
從Kaggle數(shù)據(jù)集,我們將review_text列映射到一個(gè)名為input_text的新列,我們將review_rating列映射到一個(gè)名為target_text的新列,這意味著review_rating就是我們?cè)噲D預(yù)測(cè)的內(nèi)容。
這些更改符合Simpletransformers庫(kù)接口,用于微調(diào)t5,其中主要的附加要求是指定一個(gè)“前綴”,用于幫助進(jìn)行多任務(wù)訓(xùn)練(注意:在本例中,我們將重點(diǎn)放在單個(gè)任務(wù)上,因此前綴不必使用,但是,我們無(wú)論如何都會(huì)定義它,以便于使用)。
dft5 = df[['review_text','review_rating']
].rename({
'review_text':'input_text',
'review_rating':'target_text'
},axis=1)
dft5['prefix'] = ['t5-encode' for x in range(len(dft5))]dft5['target_text'] =
dft5['target_text'].astype(str)
dft5
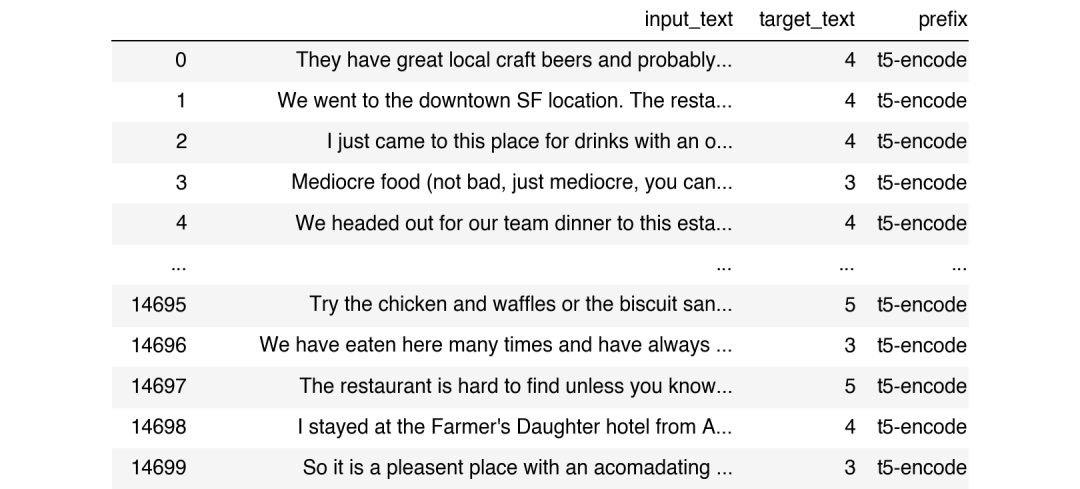
本例中的目標(biāo)文本是消費(fèi)者對(duì)給定餐廳的評(píng)分。我們可以通過(guò)以下方法輕松地微調(diào)T5模型
from sklearn.model_selection import train_test_split
train_df, eval_df = train_test_split(dft5)
model.train_model(train_df, eval_data=eval_df)
接下來(lái),我們加載預(yù)訓(xùn)練模型。
test = ['Great drinks and food',
list(np.array(model.predict(test)).astype(float))
'Good food & beer',
Generating outputs: 0%| | 0/1 [00:00<?, ?it/s] Generating outputs: 100%|██████████| 1/1 [00:00<00:00, 3.17it/s] Generating outputs: 100%|██████████| 1/1 [00:00<00:00, 3.16it/s] Decoding outputs: 0%| | 0/3 [00:00<?, ?it/s] Decoding outputs: 33%|███▎ | 1/3 [00:00<00:01, 1.14it/s] Decoding outputs: 100%|██████████| 3/3 [00:00<00:00, 3.43it/s] Out[14]: [4.0, 4.0, 4.0]
'Pretty good beers']
我們可以看到,微調(diào)模型輸出了review_rankings列表[4.0,4.0,4.0],這是一個(gè)預(yù)測(cè)結(jié)果。
接下來(lái),讓我們使用預(yù)訓(xùn)練的模型進(jìn)行測(cè)試。
test = ['Great drinks and food',
'Good food & beer',
'Pretty good beers']
list(np.where(np.array(model_pretuned_sentiment.predict(test))=='positive', 1.0, 0.0))
Generating outputs: 0%| | 0/1 [00:00<?, ?it/s] Generating outputs: 100%|██████████| 1/1 [00:00<00:00, 7.57it/s] Generating outputs: 100%|██████████| 1/1 [00:00<00:00, 7.56it/s] Decoding outputs: 0%| | 0/3 [00:00<?, ?it/s] Decoding outputs: 33%|███▎ | 1/3 [00:00<00:01, 1.17it/s] Decoding outputs: 100%|██████████| 3/3 [00:00<00:00, 3.50it/s] Out[15]: [1.0, 1.0, 1.0]
注意,預(yù)訓(xùn)練模型輸出一個(gè)布爾真/假值列表,該列表指示語(yǔ)句是正還是負(fù)-我們將它們轉(zhuǎn)換為浮點(diǎn)值,以便更好地與表格建模集成。在這種情況下,所有值都為true,因此輸出變?yōu)閇1.0、1.0、1.0]。
既然我們已經(jīng)加載了兩個(gè)版本的T5,我們可以構(gòu)建TransformPrimitive類(lèi),這些類(lèi)將與NLP和Featuretools庫(kù)集成。
from featuretools.primitives.base import TransformPrimitive
from featuretools.variable_types import Numeric, Text
class T5Encoder(TransformPrimitive):
name = "t5_encoder"
input_types = [Text]
return_type = Numeric
default_value = 0
def __init__(self, model=model):
self.model = model
def get_function(self):
def t5_encoder(x):
model.args.use_multiprocessing = True
return list(np.array(model.predict(x.tolist())).astype(float))
return t5_encoder
以上代碼創(chuàng)建了一個(gè)名為T(mén)5編碼器的新類(lèi),該類(lèi)將使用微調(diào)的T5模型,下面的代碼創(chuàng)建了一個(gè)名為T(mén)5SentimentEncoder的新類(lèi),該類(lèi)將使用預(yù)訓(xùn)練的T5模型。
class T5SentimentEncoder(TransformPrimitive):
name = "t5_sentiment_encoder"
input_types = [Text]
return_type = Numeric
default_value = 0
def __init__(self, model=model_pretuned_sentiment):
self.model = model
def get_function(self):
def t5_sentiment_encoder(x):
model.args.use_multiprocessing = True
return list(np.where(np.array(model_pretuned_sentiment.predict(x.tolist()))=='positive',1.0,0.0))
return t5_sentiment_encoder
Featuretools現(xiàn)在知道如何使用T5來(lái)為文本列提供特征,它甚至?xí)褂肨5輸出計(jì)算聚合
定義了這些新類(lèi)之后,我們只需將它們與默認(rèn)類(lèi)一起以所需的Featuretools格式包起來(lái),這將使它們可用于自動(dòng)化特征工程
trans = [
T5Encoder,
T5SentimentEncoder,
DiversityScore,
LSA,
MeanCharactersPerWord,
PartOfSpeechCount,
PolarityScore,
PunctuationCount,
StopwordCount,
TitleWordCount,
UniversalSentenceEncoder,
UpperCaseCount
]
ignore = {'restaurants': ['rating'],
'reviews': ['review_rating']}
drop_contains = ['(reviews.UNIVERSAL']
features = ft.dfs(entityset=es,
target_entity='reviews',
trans_primitives=trans,
verbose=True,
features_only=True,
ignore_variables=ignore,
drop_contains=drop_contains,
max_depth=4)
正如你在下面的輸出中看到的,F(xiàn)eaturetools庫(kù)非常強(qiáng)大!事實(shí)上,除了這里顯示的T5特征之外,它還使用指定的所有其他NLP Primitive創(chuàng)建了數(shù)百個(gè)特征,非常酷!
feature_matrix = ft.calculate_feature_matrix(features=features,
entityset=es,
verbose=True)
features
機(jī)器學(xué)習(xí)
現(xiàn)在我們使用包含新創(chuàng)建的T5 Primitive的特征矩陣從sklearn創(chuàng)建和測(cè)試各種機(jī)器學(xué)習(xí)模型。
作為提醒,我們將比較T5增強(qiáng)的精確度和Alteryx博客《自動(dòng)特征工程的自然語(yǔ)言處理》中演示的精確度:https://innovation.alteryx.com/natural-language-processing-featuretools/
使用邏輯回歸:


請(qǐng)注意,上面的0.64邏輯回歸分?jǐn)?shù)顯示了比Featuretools原生邏輯回歸分?jǐn)?shù)0.63有0.01的改進(jìn)。
使用隨機(jī)林分類(lèi)器:


請(qǐng)注意,上面T5增強(qiáng)的0.65隨機(jī)林分類(lèi)器分?jǐn)?shù)顯示了比Featuretools本機(jī)隨機(jī)林分類(lèi)器分?jǐn)?shù)0.64有0.01的改進(jìn)。
隨機(jī)森林分類(lèi)器特征重要性
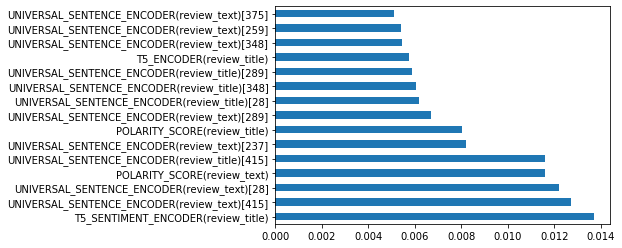
我們可以查看sklearn隨機(jī)森林分類(lèi)器的特征重要性,可以看到改進(jìn)的分?jǐn)?shù)歸于新的T5特征。
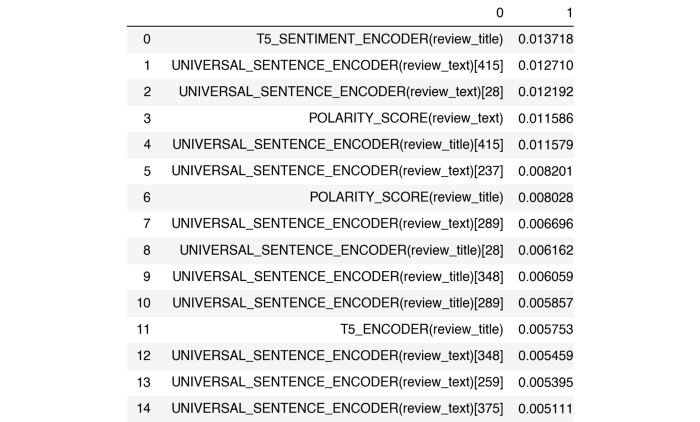
從上表中我們可以看到,隨機(jī)林模型的最高特征重要性是新創(chuàng)建的特征
T5情感編碼器(標(biāo)題)!
關(guān)鍵特征

T5模型是一個(gè)健壯、靈活的文本到文本轉(zhuǎn)換器,它可以增強(qiáng)幾乎任何NLP任務(wù)的結(jié)果,包括處理文本數(shù)據(jù)時(shí)NLP Primitive庫(kù)的結(jié)果。雖然額外的準(zhǔn)確度在這里微不足道,但幾乎可以肯定的是,除了情緒分析之外,通過(guò)實(shí)施額外的預(yù)訓(xùn)練模型,可以提高準(zhǔn)確度。
此外,在這個(gè)例子中,我們微調(diào)的T5版本只在
review_text上訓(xùn)練,而不是在review_title數(shù)據(jù)上訓(xùn)練,這似乎與Featuretools創(chuàng)建的特征不一致。糾正這個(gè)問(wèn)題很可能意味著更高的整體性能。擴(kuò)展Featuretools框架非常簡(jiǎn)單,可以使用Hugging Face transformers和Simpletransformers庫(kù)。再加上幾行代碼,精確度就提高了,代碼的復(fù)雜度也保持不變。
往期精彩回顧 本站qq群851320808,加入微信群請(qǐng)掃碼: