
使用DeepWalk從圖中提取特征
點擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達

本文轉(zhuǎn)自:opencv學(xué)堂
-
從表格或圖像數(shù)據(jù)中提取特征的方法已經(jīng)眾所周知了,但是圖(數(shù)據(jù)結(jié)構(gòu)的圖)數(shù)據(jù)呢? -
學(xué)習(xí)如何使用DeepWalk從圖中提取特征 -
我們還將用Python實現(xiàn)DeepWalk來查找相似的Wikipedia頁面
我被谷歌搜索的工作方式迷住了。每次我搜索一個主題都會有很多小問題出現(xiàn)。以“人們也在搜索?”為例。當(dāng)我搜索一個特定的人或一本書,從谷歌我總是得到與搜索內(nèi)容類似的建議。
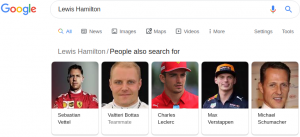
數(shù)據(jù)的圖示
不同類型的基于圖的特征
節(jié)點屬性
局部結(jié)構(gòu)特征
節(jié)點嵌入
DeepWalk簡介
在Python中實施DeepWalk以查找相似的Wikipedia頁面
當(dāng)你想到“網(wǎng)絡(luò)”時,會想到什么?通常是諸如社交網(wǎng)絡(luò),互聯(lián)網(wǎng),已連接的IoT設(shè)備,鐵路網(wǎng)絡(luò)或電信網(wǎng)絡(luò)之類的事物。在圖論中,這些網(wǎng)絡(luò)稱為圖。
網(wǎng)絡(luò)是互連節(jié)點的集合。節(jié)點表示實體,它們之間的連接是某種關(guān)系。
例如,我們可以用圖的形式表示一組社交媒體帳戶:
為什么我們將數(shù)據(jù)表示為圖?
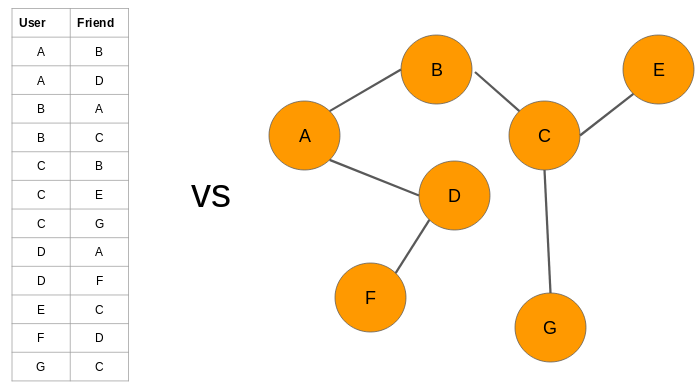
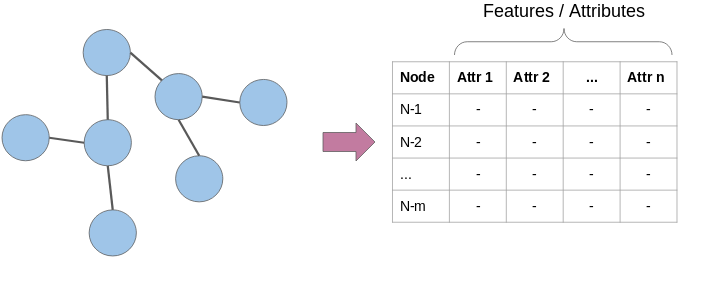
-
節(jié)點屬性:我們知道圖中的節(jié)點代表實體,并且這些實體具有自己的特征屬性。我們可以將這些屬性用作每個節(jié)點的特征。例如,在航空公司航線網(wǎng)絡(luò)中,節(jié)點將代表機場。這些節(jié)點將具有飛機容量,航站樓數(shù)量,著陸區(qū)等特征。
2.局部結(jié)構(gòu)特點:節(jié)點的度(相鄰節(jié)點的數(shù)量),相鄰節(jié)點的平均度,一個節(jié)點與其他節(jié)點形成的三角形數(shù),等等。 -
節(jié)點嵌入:上面討論的特征僅包含與節(jié)點有關(guān)的信息。它們不捕獲有關(guān)節(jié)點上下文的信息。在上下文中,我指的是周圍的節(jié)點。節(jié)點嵌入通過用固定長度向量表示每個節(jié)點,在一定程度上解決了這個問題。這些向量能夠捕獲有關(guān)周圍節(jié)點的信息(上下文信息)
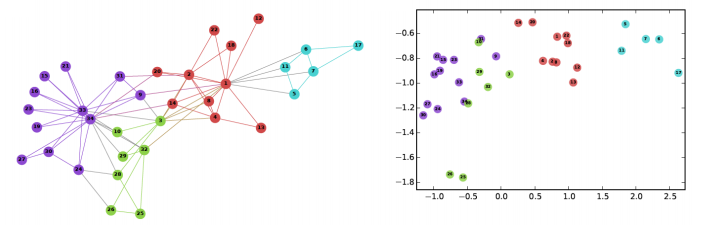
https://www.analyticsvidhya.com/blog/2019/07/how-to-build-recommendation-system-word2vec-python/?utm_source=blog&utm_medium=graph-feature-extraction-deepwalk
-
我乘巴士孟買 -
我乘火車去孟買
什么是隨機游走?
隨機游走是一種從圖中提取序列的技術(shù)。我們可以使用這些序列來訓(xùn)練一個skip-gram模型來學(xué)習(xí)節(jié)點嵌入。
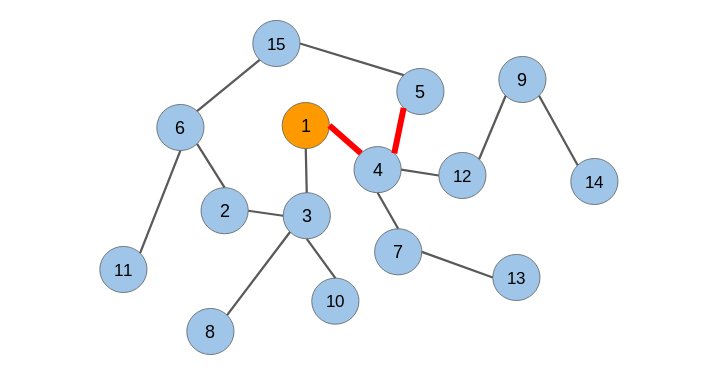
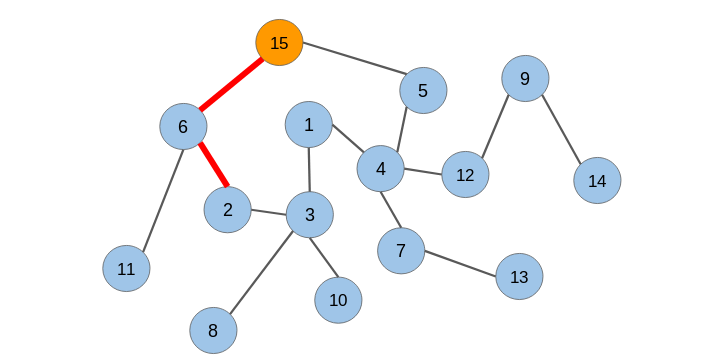
在生成節(jié)點序列之后,我們必須將它們提供給一個skip-gram模型以獲得節(jié)點嵌入。整個過程被稱為Deepwalk。
-
如果有數(shù)百萬個節(jié)點,那么我們需要大量的計算能力來解析文本并從所有這些節(jié)點或頁面中學(xué)習(xí)詞嵌入 -
這種方法不會捕獲這些頁面之間連接的信息。例如,一對直接連接的頁面可能比一對間接連接的頁面具有更強的關(guān)系
導(dǎo)入所需的Python庫
import networkx as nximport pandas as pdimport numpy as npimport randomfrom tqdm import tqdmfrom sklearn.decomposition import PCAimport matplotlib.pyplot as plt%matplotlib inline
加載數(shù)據(jù)集
https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2019/11/space_data.zip
df = pd.read_csv("space_data.tsv", sep = "\t")df.head()
Output:

構(gòu)造圖
G = nx.from_pandas_edgelist(df, "source", "target", edge_attr=True, create_using=nx.Graph())讓我們檢查圖中的節(jié)點數(shù):
len(G)Output: 2088
我們將處理2,088個Wikipedia頁面。
隨機游走
def get_randomwalk(node, path_length):random_walk = [node]for i in range(path_length-1):temp = list(G.neighbors(node))temp = list(set(temp) - set(random_walk))if len(temp) == 0:breakrandom_node = random.choice(temp)random_walk.append(random_node)node = random_nodereturn random_walk
讓我們來試試節(jié)點“space exploration”這個函數(shù):
get_randomwalk('space exploration', 10)輸出:

# 從圖獲取所有節(jié)點的列表all_nodes = list(G.nodes())random_walks = []for n in tqdm(all_nodes):for i in range(5):random_walks.append(get_randomwalk(n,10))# 序列個數(shù)len(random_walks)
# importing required librariesimport pandas as pdimport networkx as nximport numpy as npimport randomfrom tqdm import tqdmfrom sklearn.decomposition import PCAimport pprintfrom gensim.models import Word2Vecimport warningswarnings.filterwarnings('ignore')# read the datasetdf = pd.read_csv("space_data.tsv", sep = "\t")print(df.head())G = nx.from_pandas_edgelist(df, "source", "target", edge_attr=True, create_using=nx.Graph())G = nx.from_pandas_edgelist(df, "source", "target", edge_attr=True, create_using=nx.Graph())print('The number of nodes in pur graph: ',len(G))def get_randomwalk(node, path_length):random_walk = [node]for i in range(path_length-1):temp = list(G.neighbors(node))temp = list(set(temp) - set(random_walk))if len(temp) == 0:breakrandom_node = random.choice(temp)random_walk.append(random_node)node = random_nodereturn random_walkprint('\n\nRandom sequence of nodes generated from Random Walk\n\n')while True:first_node = input("Enter name of first node (for example 'space exploration') : ")if len(first_node) > 0:breakpprint.pprint(get_randomwalk(first_node, 10))# 從圖中獲取所有節(jié)點的列表all_nodes = list(G.nodes())random_walks = []for n in tqdm(all_nodes):for i in range(5):random_walks.append(get_randomwalk(n,10))# 序列長度len(random_walks)# 訓(xùn)練skip-gram (word2vec)模型model = Word2Vec(window = 4, sg = 1, hs = 0,negative = 10, # 負(fù)采樣alpha=0.03, min_alpha=0.0007,seed = 14)model.build_vocab(random_walks, progress_per=2)model.train(random_walks, total_examples = model.corpus_count, epochs=20, report_delay=1)print('\n\n Get similar nodes\n\n')while True:any_node = input("Enter name of any node (for example 'space toursim') : ")if len(any_node) > 0:breakpprint.pprint(model.similar_by_word(any_node))
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細(xì)分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~