
【NLP】使用AutoX_nlp自動化提取文本特征
背景

你是否曾面對結構化數(shù)據(jù)中的文本列,不知如何處理?文本數(shù)據(jù)作為一種常見的數(shù)據(jù)類型,包含了大量重要特征,如情感、意圖等。為了高效地將文本轉換為可供模型使用的特征,AutoX_nlp提供了文本列自動特征提取的解決方案。通過該方案,可以很方便地調用文本處理工具,將文本特征變成數(shù)值特征,進行后續(xù)訓練、預測。
效果
目前AutoX_nlp結合AutoX端到端自動機器學習建模方案,已在多個包含文本域的數(shù)據(jù)集上取得優(yōu)于其他自動建模工具的結果。
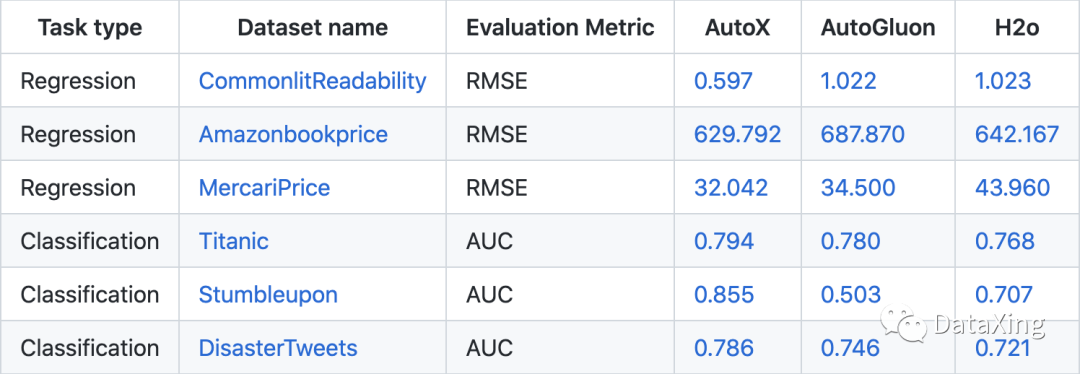
案例說明
你可以很容易地使用AutoX_nlp,幾行代碼即可完成文本特征提取:
from autox.autox_nlp import NLP_featureNLP_feature = NLP_feature()text_columns = ['text1','text2']train_text_feature = NLP_feature.fit_transform(train,text_columns)test_text_feature?=?NLP_feature.transform(test)
AutoX_nlp介紹
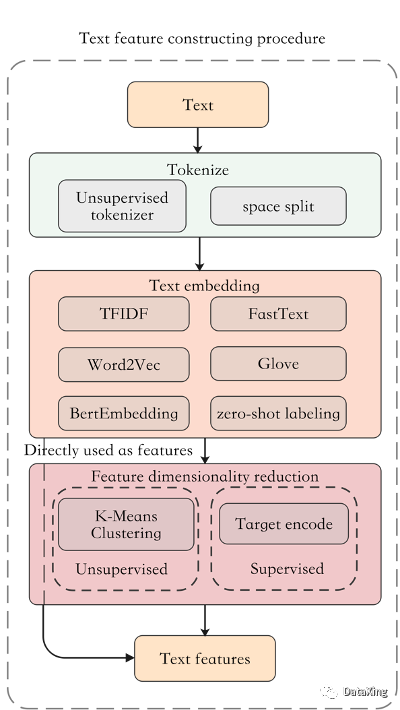
主要流程包括:
1. 分詞:將單條文本拆分為多個token,將文本信息拆分細化。默認為空格分詞,無監(jiān)督分詞器可以動態(tài)選擇較合適的分詞粒度;
2. 特征提取:將拆分后的文本表示為數(shù)值特征向量,默認為TFIDF,此外還支持Word2Vec、FastText、Glove、Bert、Zero-shot labeling。其中zero shot labeling使用在NLI任務下訓練的模型對文本潛在的類別進行預測,適用于提前知曉文本列所指代特征的情況;
3. 輸出:將特征轉化為期望的輸出格式,默認為離散型,此外也可以直接以稀疏矩陣輸出第二步的特征,以及使用有監(jiān)督的方式輸出連續(xù)型特征。
往期精彩回顧
適合初學者入門人工智能的路線及資料下載 (圖文+視頻)機器學習入門系列下載 中國大學慕課《機器學習》(黃海廣主講) 機器學習及深度學習筆記等資料打印 《統(tǒng)計學習方法》的代碼復現(xiàn)專輯 機器學習交流qq群955171419,加入微信群請掃碼:
評論
圖片
表情