
盤點工業(yè)界AI項目流程以及邊緣設(shè)備現(xiàn)狀

極市導(dǎo)讀
本文作者分享了自己踏入深度學(xué)習(xí)第一個項目的經(jīng)驗以及自己從事邊緣計算行業(yè)中知識總結(jié):AI項目的開發(fā)交付流程、市面上常見的邊緣計算設(shè)備性能和參數(shù)的對比。 >>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿
文章目錄
1 個人簡介
2 第一個深度學(xué)習(xí)項目
3 從GPU到邊緣計算設(shè)備
3.1 AI項目的一般開發(fā)交付流程3.2 AI產(chǎn)品常見的三種交付形態(tài)
3.3 應(yīng)用類產(chǎn)品的基本框架
3.4 為什么選擇邊緣計算設(shè)備?
3.5 邊緣計算設(shè)備的特點
4 常見的邊緣計算設(shè)備平臺
4.1 NVIDIA Jeston4.2 華為atlas4.3 比特大陸 Sophon SE54.4 Amlogic4.5 寒武紀(jì)MLU
5 邊緣計算設(shè)備的使用
5.1 邊緣計算設(shè)備的選型思路5.2 邊緣計算設(shè)備比較5.3 邊緣設(shè)備與GPU服務(wù)器的區(qū)別5.4 邊緣計算設(shè)備的一般開發(fā)流程5.5 常見問題
6 互動問答
1 個人簡介
大家好,我是白夜。目前在蘇州,主要從事邊緣計算設(shè)備端側(cè),智能安防應(yīng)用的開發(fā)與部署。我本科是電子信息工程專業(yè),碩士是電磁場與微波技術(shù)方向,2018年底開始接觸并進(jìn)入AI行業(yè)。
因為工作中用過很多公司的邊緣設(shè)備,在大白的社群中,很多人也都對邊緣設(shè)備感興趣。因此今天主要結(jié)合工作中接觸過的幾種邊緣計算設(shè)備,圍繞深度學(xué)習(xí)應(yīng)用部署這個主題,與大家分享一些心得體會。
2 第一個深度學(xué)習(xí)項目
相信很多人可能跟我一樣,接觸的第一個深度學(xué)習(xí)項目,應(yīng)該就是手寫數(shù)字/漢字的識別。
18年底面試目前的公司時,復(fù)試的考題就是手寫漢字識別。因為是第一個項目,所以對于考題現(xiàn)在還記憶猶新。當(dāng)時的考題主要是中文字符分類,提供了3755個漢字,每個漢字有若干個手寫字符。
題目很簡單,而要求是:
① 使用任意一種深度神經(jīng)網(wǎng)絡(luò)框架下,編寫程序,實現(xiàn)識別字符的功能;
② 通過修改超參、網(wǎng)絡(luò)參數(shù)、網(wǎng)絡(luò)結(jié)構(gòu)(替換或增加網(wǎng)絡(luò)層)等方式,提高模型的分類準(zhǔn)確率;
③ 完成報告,說明字符分類的原理、修改網(wǎng)絡(luò)參數(shù)或結(jié)構(gòu)的理由和具體操作、模型性能分析;
④ 提交完整可執(zhí)行代碼,附帶代碼執(zhí)行說明文檔。
當(dāng)時對于AI行業(yè)還不是很熟,經(jīng)過大量的檢索及思考。最終參考論文《Deep Convolutional Network for Handwritten Chinese Character Recognition》,選用了一個基于VGG和Alexet的M5網(wǎng)絡(luò)(包含3個conv3卷積層和2個全連接層),并使用Tensorflow構(gòu)建了一個3755類的圖像分類器,完成了任務(wù)。

通過這個任務(wù),在短時間內(nèi),我惡補了機器學(xué)習(xí)和深度學(xué)習(xí)相關(guān)的基本概念(如模型訓(xùn)練集、驗證集、測試集等)。厘清了人工神經(jīng)網(wǎng)絡(luò)和CNN的區(qū)別,并熟悉了深度學(xué)習(xí)軟件環(huán)境的安裝和使用,熟悉了在linux下開發(fā)編程的基本流程。那個時候,感覺學(xué)習(xí)的速度,和勁頭是最足的。
通過手寫漢字識別,我算是簡單入了門,了解了圖像分類的基本原理,之后慢慢地也開始接觸目標(biāo)檢測、特征提取、目標(biāo)追蹤等相關(guān)的模型和算法。當(dāng)時Pytorch還沒有現(xiàn)在這么火,大家用的比較多的是Tensorflow和Caffe。得益于Tensorflow完備的用戶手冊和官方教程,學(xué)習(xí)的路上省力不少。慢慢地在一次次地編譯Caffe、FFmpeg、Opencv和Debug中,對Linux系統(tǒng)、環(huán)境變量、軟件多版本共存、庫包依賴關(guān)系、Cmake、Makefile、CUDA等有了更加深刻的認(rèn)識。終于后來也可以用Caffe實現(xiàn)自定義算子和神經(jīng)網(wǎng)絡(luò)層了。
后來我加入了公司的的項目工程化落地小組,開始參與基礎(chǔ)平臺的研發(fā)和具體項目的開發(fā):從視頻編解碼到模型推理加速,從Opencv到FFmpeg,從Gstreamer到DeepStream,從CUDA到Tensor RT。慢慢地我開始認(rèn)識到模型訓(xùn)練和推理僅僅是一個開始,在 AI項目落地的過程中,其實還有相當(dāng)大一部分不AI的工作,這些工作甚至占據(jù)了項目開發(fā)的絕大部分時間。
其中,也有很多值得我們思考和解決的問題:
① 比如如何縮短項目開發(fā)周期,快速應(yīng)對不同客戶的多樣需求,完成POC演示,推進(jìn)項目落地?
② 針對不同的實際場景,如何對算法硬件平臺進(jìn)行選型?
③ 如何綜合現(xiàn)有技術(shù)手段,解決CV以及深度學(xué)習(xí)算法無法解決的盲區(qū)問題,為客戶提供最優(yōu)的解決方案?
④ 如何充分挖掘邊緣計算設(shè)備的算力,降低單路視頻分析的成本?
⑤ 如何形成數(shù)據(jù)的閉環(huán),在項目部署后便捷地采集數(shù)據(jù),不斷迭代優(yōu)化模型,提高客戶的滿意度?
上面主要是工作中,對于AI項目的一些思考。下面再回到本次分享的主題,聊聊在項目中,為什么使用邊緣計算設(shè)備?
3 從GPU到邊緣計算設(shè)備
不過在詳細(xì)介紹邊緣設(shè)備前,我們先了解下AI項目的一般開發(fā)交付流程。
3.1 AI項目的一般開發(fā)交付流程
AI項目的開發(fā)過程中,通常包括以下環(huán)節(jié):
① 數(shù)據(jù)采集:現(xiàn)場數(shù)據(jù)采集、數(shù)據(jù)標(biāo)定、數(shù)據(jù)集校驗;
② 模型訓(xùn)練:設(shè)計模型、訓(xùn)練模型;
③ 模型部署:模型轉(zhuǎn)化、模型量化、模型裁剪、模型微調(diào);
④ 業(yè)務(wù)開發(fā):根據(jù)項目的需求,設(shè)計業(yè)務(wù)規(guī)則,完成相應(yīng)業(yè)務(wù)邏輯處理代碼的編寫調(diào)試;
⑤ 項目部署:制作安裝包或者docker鏡像,安裝部署在目標(biāo)平臺上;
⑥ 模型優(yōu)化:根據(jù)現(xiàn)場的應(yīng)用采集數(shù)據(jù),優(yōu)化模型
在整個流程有兩個難點:一是數(shù)據(jù),二是需求。有時候沒有數(shù)據(jù),模型達(dá)不到理想的效果,可能客戶都不給試用的機會,更別提數(shù)據(jù)采集優(yōu)化模型了;有時候客戶很配合,數(shù)據(jù)不是問題,但是客戶的需求很多,要求很高,甚至有些需求目前的AI根本做不到,但是為了生存也只能硬著頭皮上,還要應(yīng)對客戶隨時都可能“微調(diào)”的新要求。
所以現(xiàn)實往往是:
① 要么做了一堆沒有客戶愿意買單的POC項目,要么做了幾個遲遲無法完成交付,錢也不多的小項目。
② 客戶以為我們提供的是個拿來即用的成熟產(chǎn)品,然而事實卻僅僅是個待采集數(shù)據(jù)進(jìn)一步優(yōu)化的試驗品。
因此,面對紛繁復(fù)雜的應(yīng)用場景,客戶自己也可能不太清楚的不確定需求。
AI公司要想走出研發(fā)投入多、成本高、項目交付周期長的困局,必須要解決規(guī)模復(fù)制效益的問題,集中力量向某個方向發(fā)力,打造有技術(shù)壁壘或者市場壁壘的產(chǎn)品。哪怕是做項目,也應(yīng)當(dāng)按照做產(chǎn)品的思維設(shè)計和組織,把項目開發(fā)變成搭積木,因為只有可復(fù)制的產(chǎn)品,才能分?jǐn)偢甙旱难邪l(fā)成本,應(yīng)對快速變化的市場需求。
3.2 AI產(chǎn)品常見的三種交付形態(tài)
了解了AI項目開發(fā)的流程,再看一下客戶產(chǎn)品的交付。
在工作中,面對不同的客戶,通常需要交付不同的非標(biāo)類產(chǎn)品,所以先聊一下常見的交付方式。行業(yè)場景和客戶需求雖然五花八門,但總的來說,交付的產(chǎn)品通常有3種形態(tài):
(1)服務(wù)Service:
AI模型的部署服務(wù),客戶端可以通過HTTP/REST或GRPC的方式來請求服務(wù)。輸入一張圖片/一段視頻,輸出圖片/視頻的分析結(jié)果,通常按次數(shù)收費或者按時間段授權(quán)。比如百度AI市場上提供的各種API服務(wù):
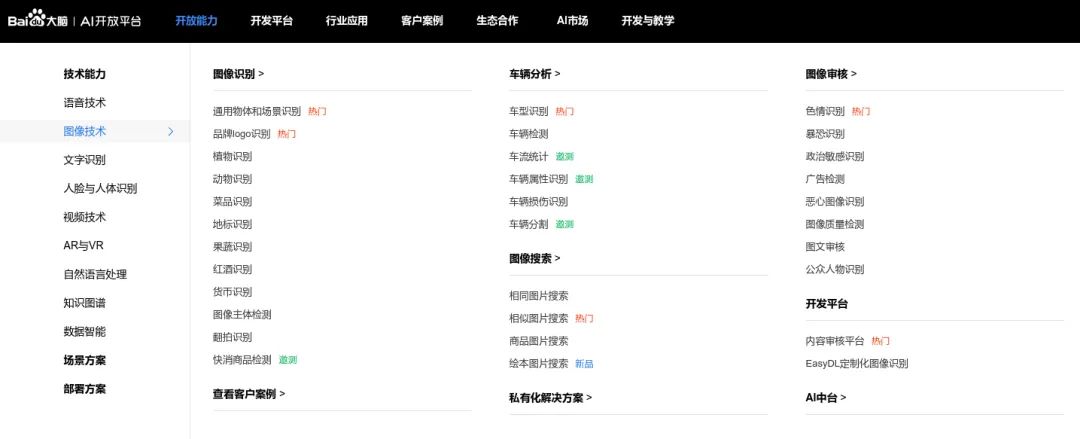
這種形式,業(yè)務(wù)流程相對是單一的,主要需要考慮的是充分利用GPU算力資源,能夠提供穩(wěn)定的高吞吐量的服務(wù)。這種服務(wù)通常部署在GPU服務(wù)器上,可能是客戶局域網(wǎng)內(nèi)的服務(wù)器,也可能是公有云上的服務(wù)器。市面上也有一些成熟的商用框架可以使用,如NVIDIA的Triton Inference Server, Google的TF Servering,百度的Paddle Serving等。Triton是 NVIDIA 推出的 Inference Server,專門做 AI 模型的部署服務(wù)。
而客戶端可以通過HTTP/REST或GRPC的方式來請求服務(wù),特性包括以下方面:
① 支持多種框架,例如 Tensorflow、TensoRT、Pytorch、ONNX甚至自定義框架后端;
② 支持 GPU 和 CPU 方式運行,能最大化利用硬件資源;
③ 容器化部署,集成 k8s,可以方便的進(jìn)行編排和擴展;
④ 支持并發(fā)模型,支持多種模型或同一模型的不同實例在同一GPU上運行;
⑤ 支持多種批處理算法,可以提高推理吞吐量;
(2)開發(fā)包SDK或者功能組件:
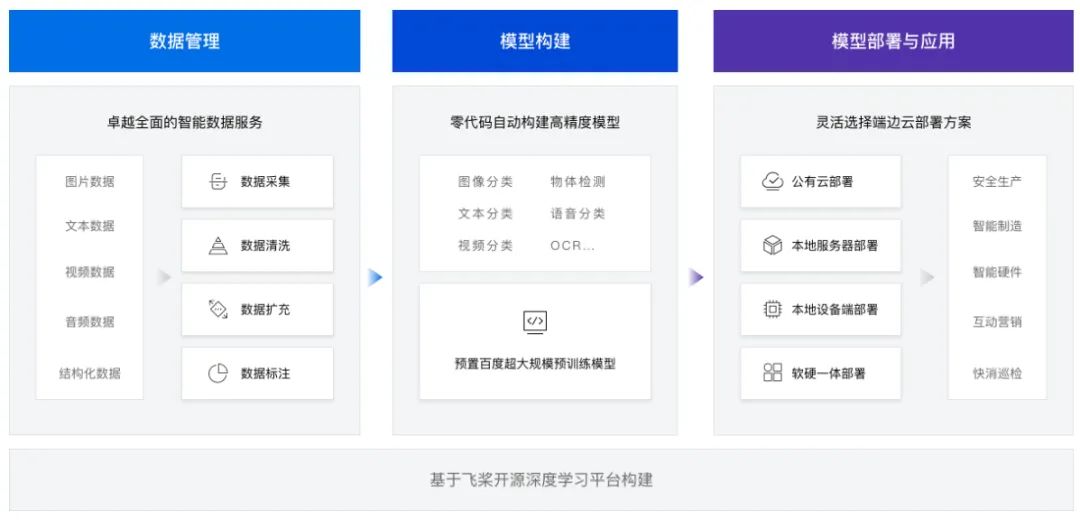
有的中間商或集成商以及一些傳統(tǒng)的非AI公司,需要用深度學(xué)習(xí)解決問題的能力。把基于深度學(xué)習(xí)的算法能力,集成到自己的業(yè)務(wù)系統(tǒng)中,為最終用戶提供服務(wù)。這時,他們會尋找第三方的合作伙伴,提供一套封裝了深度學(xué)習(xí)算法能力的SDK或者功能組件。向他們的業(yè)務(wù)系統(tǒng)賦能AI算法能力,比如百度的EasyDL-零門檻AI開發(fā)平臺,云從科技的人臉識別服務(wù)等。
下圖是百度EasyDL開發(fā)平臺的功能示意圖:
(3)應(yīng)用Application:
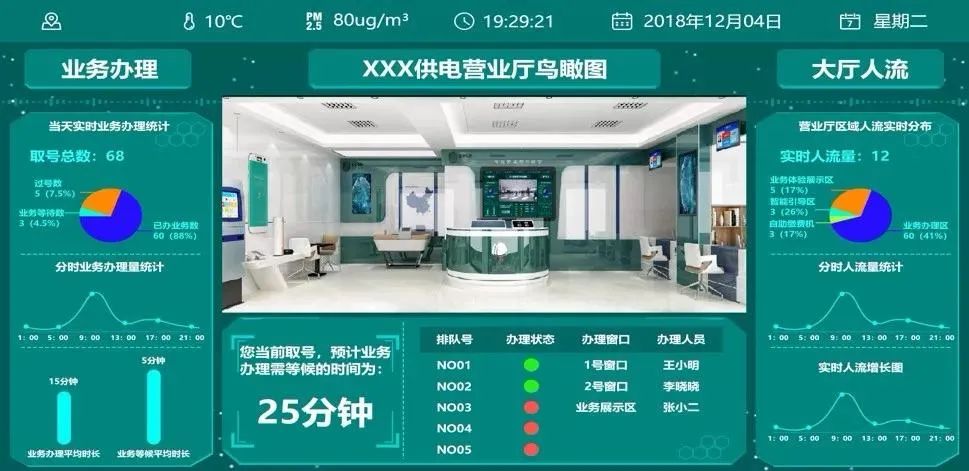
這種形式的產(chǎn)品,通常面向的是某個場景的最終用戶。因此交付的產(chǎn)品,是一整套包括交互界面在內(nèi)的軟件系統(tǒng),有時也會將硬件一起捆綁交付。對這類產(chǎn)品,用戶需要的其實只是應(yīng)用的分析輸出結(jié)果。比如繪制了違規(guī)提醒框的實時畫面,web、郵件甚至手機短信聯(lián)動的告警消息,某個時段或者滿足某種條件的數(shù)據(jù)分析報表等。
這類產(chǎn)品一方面需要提供友好的操作界面供用戶查看使用,同時可能還需要提供對接用戶第三方平臺的接口,將分析產(chǎn)生的告警結(jié)果等信息,推送到用戶的業(yè)務(wù)管理平臺。
3.3 應(yīng)用類產(chǎn)品的基本框架
當(dāng)然對于大多數(shù)中小型公司來說,主要做的還是應(yīng)用類項目。這些項目,并不只是單個的功能,而是一套比較完整的系統(tǒng)。以視頻分析為例,通常包括:視頻結(jié)構(gòu)化引擎、業(yè)務(wù)中臺、管理平臺等。
(1)視頻結(jié)構(gòu)化引擎:
通過分析視頻內(nèi)容,生成包含了目標(biāo)坐標(biāo)、類別、屬性、特征、追蹤id等信息的結(jié)構(gòu)化數(shù)據(jù),供業(yè)務(wù)中臺做進(jìn)一步的業(yè)務(wù)邏輯處理。為了簡化開發(fā)流程,提高代碼復(fù)用率,降低代碼維護(hù)難度,視頻結(jié)構(gòu)化引擎作為一個基礎(chǔ)平臺,應(yīng)當(dāng)適配不同硬件平臺,屏蔽硬件差異,向管理平臺提供統(tǒng)一的接口,同時支持根據(jù)不同需求靈活配置任務(wù)流程。
視頻結(jié)構(gòu)化引擎主要分成三個部分:
① 視頻源接入:支持多種接入,圖片,視頻文件,rtsp流,GB28181流,海康SDK(工業(yè)相機)
② 流程Pipeline配置和創(chuàng)建:
a.輸入數(shù)據(jù)預(yù)處理:對輸入數(shù)據(jù)做尺寸縮放、歸一化等;
b.模型推理:使用多種硬件平臺進(jìn)行推理,如NVIDIA GPU、Jetson、Bitmain、Cambricon等
c.輸出數(shù)據(jù)后處理:對模型的結(jié)果,進(jìn)行后處理,得到可以顯示的結(jié)果;
③ 結(jié)果輸出:終端打印、寫入Redis、輸出畫面到屏幕、保存結(jié)果到視頻文件、推送rtsp流等。
(2)業(yè)務(wù)中臺:
主要對業(yè)務(wù)進(jìn)行邏輯處理,通常由業(yè)務(wù)邏輯和對外接口構(gòu)成。
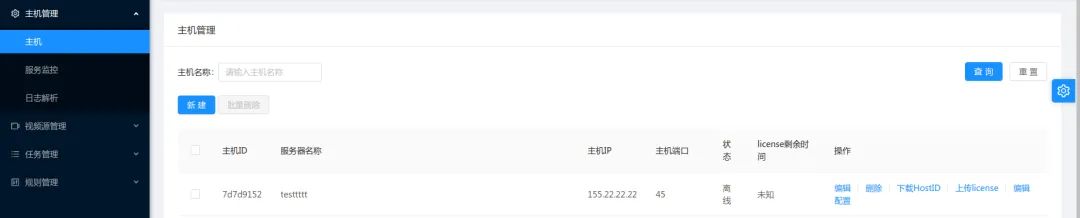
(3)管理平臺:
視頻結(jié)構(gòu)化引擎或者業(yè)務(wù)平臺可能是分布式的,部署在同一局域網(wǎng)內(nèi)的不同主機、甚至是不同局域網(wǎng)內(nèi)的不同主機上,管理平臺用來管理這些主機,通常包含以下部分:
① 主機管理
② 視頻源管理
③ 任務(wù)管理
④ 用戶交互界面與結(jié)果查看
⑤ license認(rèn)證與管理
比如下圖是我們系統(tǒng)中,管理平臺的圖示。
3.4 為什么選擇邊緣計算設(shè)備?
了解AI項目的開發(fā)流程、交付方式,以及基本架構(gòu),下面再回到本文的核心:邊緣計算設(shè)備。
邊緣計算設(shè)備,其實是相對于云計算而言的。不同于云計算的中心式服務(wù),邊緣服務(wù)是指在靠近物或數(shù)據(jù)源頭的一側(cè),采用網(wǎng)絡(luò)、計算、存儲、應(yīng)用核心能力為一體的開放平臺,就近提供最近端服務(wù)。其應(yīng)用程序在邊緣側(cè)發(fā)起,為了產(chǎn)生更快的網(wǎng)絡(luò)服務(wù)響應(yīng)。滿足行業(yè)在實時業(yè)務(wù)、應(yīng)用智能、安全與隱私保護(hù)等方面的基本需求。由于數(shù)據(jù)處理和分析,是在傳感器附近或設(shè)備產(chǎn)生數(shù)據(jù)的位置進(jìn)行的,因此稱之為邊緣計算。
因此我們可以看出,邊緣計算的優(yōu)點:
① 低延遲:計算能力部署在設(shè)備側(cè)附近,設(shè)備請求實時響應(yīng);
② 低帶寬運行:將工作遷移至更接近于用戶,或是數(shù)據(jù)采集終端的能力,能夠降低站點帶寬限制所帶來的影響;
③ 隱私保護(hù):數(shù)據(jù)本地采集,本地分析,本地處理,有效減少了數(shù)據(jù)暴露在公共網(wǎng)絡(luò)的機會,保護(hù)了數(shù)據(jù)隱私;
當(dāng)然許多同學(xué),可能都是使用GPU服務(wù)器做視頻分析,對邊緣計算設(shè)備接觸不一定多,但是有的場景下,直接使用GPU服務(wù)器做視頻分析,存在幾個問題:
① 許多場景下,數(shù)據(jù)源(攝像頭)是分布式的,可能分布在不同的子網(wǎng)內(nèi),甚至分布在不同的城市,使用GPU服務(wù)器集中處理延時大、帶寬占用高、能耗高(因為傳輸?shù)臄?shù)據(jù)中大部分是無效信息);
對于分散的工地或者連鎖店店鋪等場景,如果要集中處理,不僅要占用寶貴的專線帶寬,還要內(nèi)網(wǎng)穿透,麻煩且不經(jīng)濟(jì);
② 有的場景下使用GPU,會造成算力過程、資源浪費,比如連鎖店鋪的客流統(tǒng)計,每個店鋪可能只有2-4路攝像頭,少的甚至只有1路,使用GPU顯然大材小用;
③ 相比較純軟件的產(chǎn)品,客戶更傾向于為軟硬件一體的產(chǎn)品買單;
再舉一個更直觀的案例,更明顯的看出邊緣設(shè)備的優(yōu)點,之前在知乎上看到的。以波音787為例,其每一個飛行來回可產(chǎn)生TB級的數(shù)據(jù)。美國每個月收集360萬次飛行記錄;監(jiān)視所有飛機中的25000個引擎,每個引擎一天產(chǎn)生588GB的數(shù)據(jù)。這樣一個級別的數(shù)據(jù),如果都通過遠(yuǎn)程,上傳到云計算的服務(wù)器中,無論對于算力和帶寬,都提出了苛刻的要求。風(fēng)力發(fā)電機裝有測量風(fēng)速、螺距、油溫等多種傳感器,每隔幾毫秒測一次,用于檢測葉片、變速箱、變頻器等的磨損程度,一個具有500個風(fēng)機的風(fēng)場一年會產(chǎn)生2PB的數(shù)據(jù)。如此級別的數(shù)據(jù),如果實時上傳到云計算中心并產(chǎn)生決策,無論從算力和帶寬的角度,都提出了苛刻的要求,更不要說由于延遲而產(chǎn)生的即時響應(yīng)問題。

面對這樣的場景,邊緣計算就體現(xiàn)出它的優(yōu)勢了。由于部署在設(shè)備側(cè)附近,可以通過算法即時反饋決策,并可以過濾絕大部分的數(shù)據(jù),有效降低云端的負(fù)荷,使得海量連接和海量數(shù)據(jù)處理成為可能。因此,選擇使用服務(wù)器還是邊緣計算設(shè)備,主要還是考慮哪種方式更符合場景需求,哪種方式更便捷更經(jīng)濟(jì)。
如果應(yīng)用場景需要集中分析大量數(shù)據(jù),比如幾十路甚至上百路攝像頭,那肯定還是應(yīng)當(dāng)選擇x86服務(wù)器。當(dāng)然這種情況不一定只有Nvidia GPU一種選擇,比特大陸、華為、寒武紀(jì)都有PCIE的計算加速卡可以選擇;如果應(yīng)用場景分布在不同地點的節(jié)點,并且每個節(jié)點要分析的攝像頭數(shù)量在10-20路以下,那么選擇邊緣計算設(shè)備顯然更經(jīng)濟(jì)更有效;有的時候甚至可以直接選用帶AI處理芯片的智能攝像頭。
3.5 邊緣計算設(shè)備的特點
了解了選擇邊緣計算設(shè)備的原因,我們再來看一下邊緣計算設(shè)備的特點:
(1)算力有限:常常在幾T~幾十T INT8 OPS之間
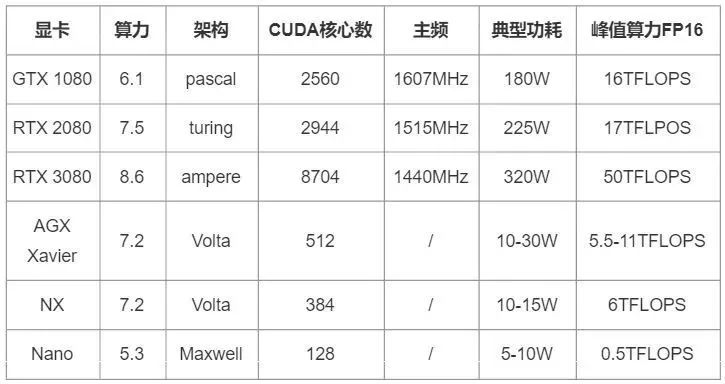
表格中的前3項是NVIDIA的GPU,其峰值算力為根據(jù)CUDA核心數(shù)、主頻,折算為FP16而計算的理論值,估算公式為:
計算能力的峰值 = 單核單周期計算次數(shù) × 處理核個數(shù) × 主頻
后三項為NVIDIA的邊緣計算模組Jetson的不同產(chǎn)品,峰值算力為產(chǎn)品手冊中給出的參考值。這些峰值算力雖然并不完全準(zhǔn)確,但也基本代表了設(shè)備的算力情況。
不準(zhǔn)確的原因主要有兩方面:
① 這些是理論值,實際中還要考慮線程調(diào)度、數(shù)據(jù)拷貝、異構(gòu)同步等,實際算力肯定達(dá)不到理論值;
② 除了CUDA核心,設(shè)備內(nèi)還會有其他加速單元,比如Tensor Core、DLA(深度學(xué)習(xí)加速器)。
以Jetson AGX Xavier為例,他還有48個Tensor Core,以及DLA,(2x) NVDLA Engines* | 5 TFLOPS (FP16),相當(dāng)于額外的5TFLOPS算力。因此官方手冊中會寫AGX Xavier的AI算力是32TOPS INT8(16TOPS FP16)。
(2) 功耗低:通常邊緣計算設(shè)備的功耗在5-30W,可以通過太陽能供電,進(jìn)行戶外移動作業(yè)。
(3) 硬件接口豐富:便于與其他設(shè)備/系統(tǒng)對接。
(4) 體積小,重量輕:安裝簡便靈活,便于分布式部署和擴展。
4 幾種邊緣計算設(shè)備平臺
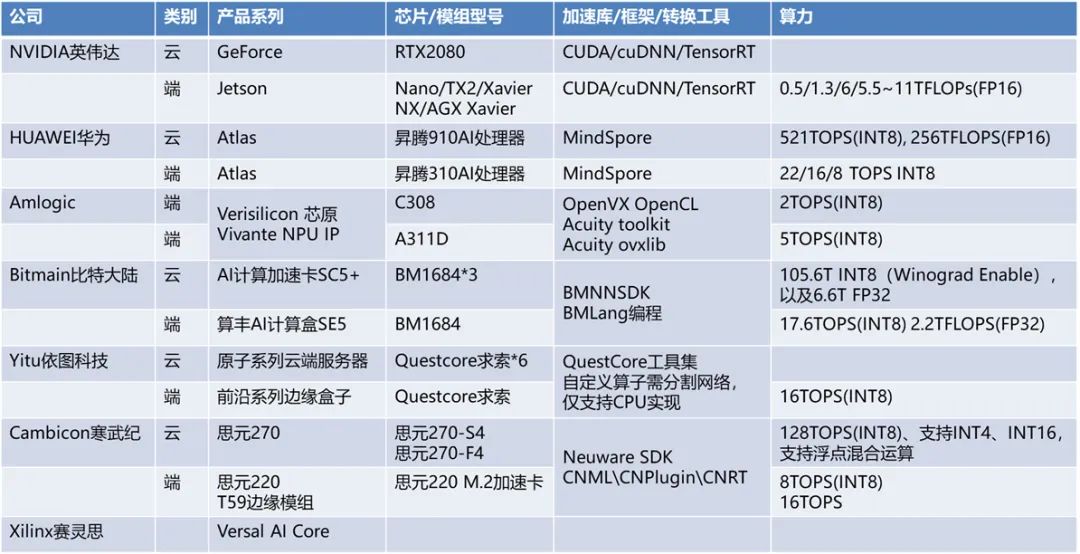
掌握了邊緣設(shè)備的一些基礎(chǔ)知識,我們再了解市面上常用的一些邊緣計算設(shè)備。市場上推出商用深度學(xué)習(xí)計算加速設(shè)備的廠商其實有很多,只不過在訓(xùn)練領(lǐng)域,主要還是英偉達(dá)占據(jù)了大部分市場份額。
除此之外,比特大陸(算豐Sophon),寒武紀(jì)(思元MLU),華為(昇騰Ascend,海思),晶晨(Versillion),依圖(QuestCore),還有英特爾(Movidius VPU),谷歌(TPU),百度,特斯拉(Dojo D1),賽靈思都有自己的深度學(xué)習(xí)處理器或者解決方案。
(1) 訓(xùn)練平臺:通常以英偉達(dá)Nvidia-GPU為主;
(2)推理平臺:云端和設(shè)備端,CPU(x86 arm),GPU,NPU,TPU,F(xiàn)PGA,ASIC;
下圖是相關(guān)平臺的圖示:

下面,我再重點介紹一下幾種常見的邊緣計算設(shè)備。

4.1 NVIDIA Jetson
NVIDIA Jetson是NVIDIA為新一代自主機器設(shè)計的嵌入式系統(tǒng),是一個AI平臺 ,這個系列已經(jīng)有不少成員了。
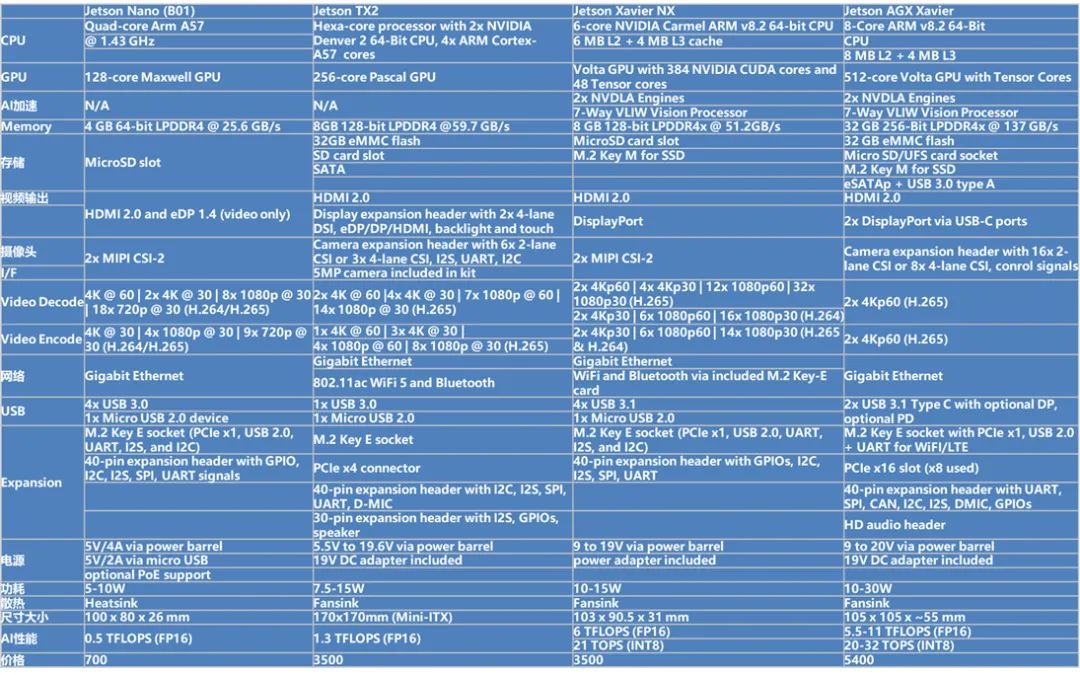
4.1.1 硬件參數(shù)
目前Jseton系列也有很多不同的型號,下圖是不同型號的相關(guān)參數(shù):

4.1.2 開發(fā)工具鏈
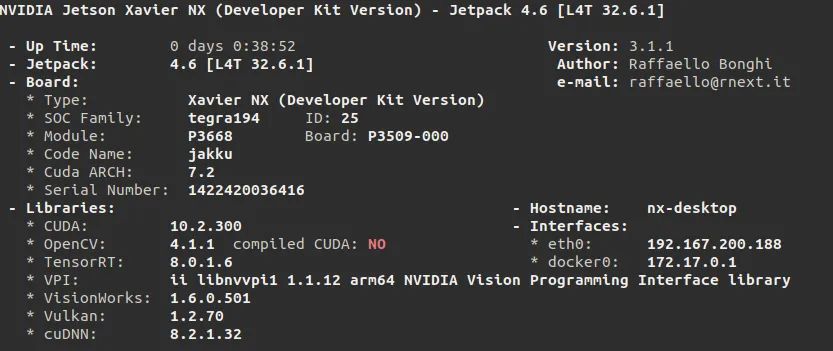
當(dāng)然每個邊緣設(shè)備平臺,還有專門的開發(fā)工具鏈。Jetson也是NVIDIA生態(tài)的一員,因此,也是基于CUDA、cuDNN以及TensorRT的。與GPU不同,Jetson所依賴的軟件庫包是以Jetpack的形式整體打包提供的,其中包含了操作系統(tǒng)、CUDA、cuDNN、TensorRT、Opencv、視頻編解碼等豐富的庫包及API接口。目前,官方最新的版本是JetPack 4.6,其內(nèi)的軟件版本相關(guān)信息如下圖:
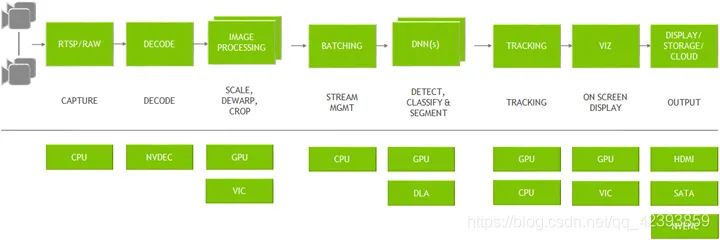
其他需要的軟件,比如支持支持CUDA的OpenCV、CUDA的Pytorch,可以通過源碼交叉編譯或者從NVIDIA的官方論壇下載。英偉達(dá)提供了豐富的SDK包供各個領(lǐng)域和方向的用戶選擇,比如音視頻分析中常用的數(shù)據(jù)流分析工具包Deeptream。 開發(fā)人員可以GStreamer插件的形式自定義插件,構(gòu)建個性化的視頻分析管道,通過硬件加速完成各種任務(wù),實現(xiàn)深度學(xué)習(xí)任務(wù)的快速部署。
比如下圖就是一個典型的視頻分析管道:
4.2 華為 atlas
Atlas是華為基于昇騰系列AI處理器和業(yè)界主流異構(gòu)計算部件,打造的智能計算平臺。通過模塊、板卡、小站、AI服務(wù)器等豐富的產(chǎn)品形態(tài),打造面向“端、邊、云”的全場景AI基礎(chǔ)設(shè)施方案,可廣泛用于“平安城市、智慧交通、智慧醫(yī)療、AI推理”等領(lǐng)域。
4.2.1 硬件參數(shù)
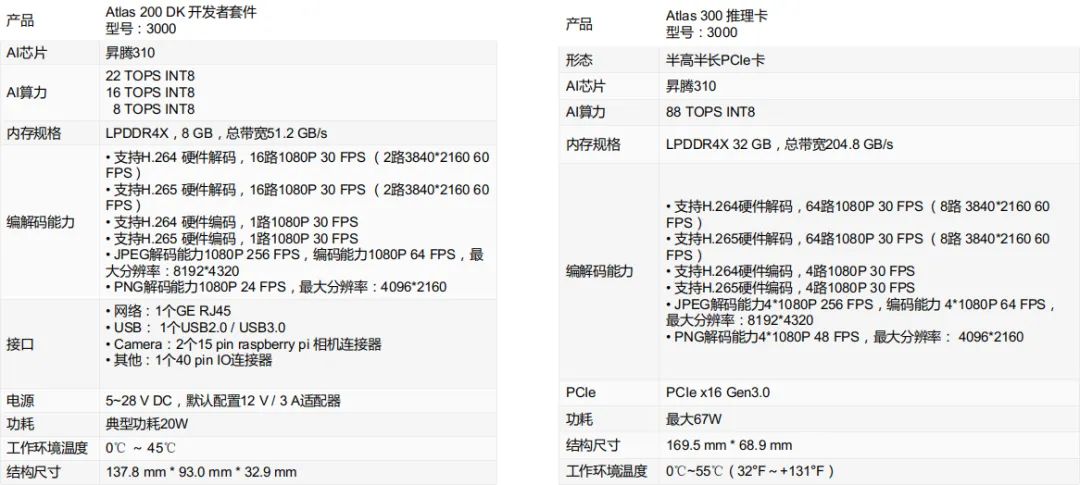
下圖是Atlas各個版本的相關(guān)參數(shù)及產(chǎn)品圖示:


4.2.2 開發(fā)工具鏈
華為atlas的開發(fā)工具鏈主要有兩部分:
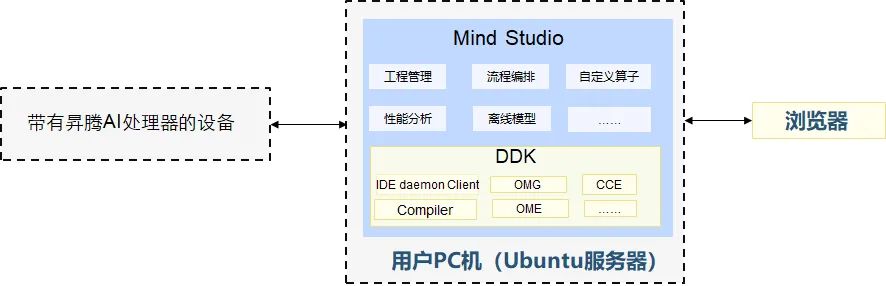
(1)mind studio:這是基于昇騰AI處理器的開發(fā)工具鏈平臺,提供了基于芯片的算子開發(fā)、調(diào)試、調(diào)優(yōu)以及第三方算子的開發(fā)功能。
同時還提供了網(wǎng)絡(luò)移植、優(yōu)化和分析功能,另外在業(yè)務(wù)引擎層提供了一套可視化的AI引擎拖拽式編程服務(wù),極大的降低了AI引擎的開發(fā)門檻。
不過mind studio是通過Web的方式向開發(fā)者提供一系列的服務(wù),其實也不是個必需品,許多開發(fā)者在開發(fā)過程中只是用它來查看日志。 因為atlas的日志都是加密的,必須使用mind studio來查看。
(2)DDK(Device Development Kit):設(shè)備開發(fā)工具包,為開發(fā)者提供基于昇騰AI處理器的相關(guān)算法開發(fā)工具包,旨在幫助開發(fā)者進(jìn)行快速、高效的人工智能算法開發(fā)。
DDK可以用于構(gòu)建相關(guān)工程的編譯環(huán)境,集成了TE、DVPP、流程編排等昇騰AI處理器算法開發(fā)依賴的頭文件和庫文件、編譯工具鏈、調(diào)試調(diào)優(yōu)工具以及其他工具等。下圖是華為atlas開發(fā)工具鏈的示意圖:
需要注意的是,Atlas500小站是主從架構(gòu)的,主機端host側(cè)為華為自研海思Hi3559A,從機端device側(cè)為Atlas 200 AI加速模塊,host和device上運行著2個相互獨立的系統(tǒng),也就是device側(cè)的Atlas200上也是有arm cpu的。這就導(dǎo)致,調(diào)試過程中有時很別扭,比如,程序運行過程中,想要查看Atlas200的打印信息,只能通過mind studio查看日志。
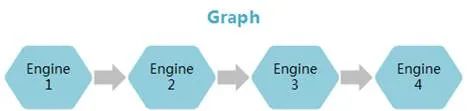
值得一提的是,為了高效使用Ascend 310芯片的算力,華為提供了Matrix框架來完成推理業(yè)務(wù)遷移,有點類似gstreamer的味道。把每個功能節(jié)點抽象成流程的基本單元Engine,每個Engine對應(yīng)著一個獨立的線程。在Graph配置文件中配置Engine節(jié)點間的串接和節(jié)點屬性(運行該節(jié)點所需的參數(shù))。節(jié)點間數(shù)據(jù)的實際流向根據(jù)具體業(yè)務(wù)在節(jié)點中實現(xiàn),通過向業(yè)務(wù)的開始節(jié)點輸入數(shù)據(jù)激活Graph。每個Graph是一個獨立的進(jìn)程。
Mind Studio也提供了可視化的界面用于配置Graph:
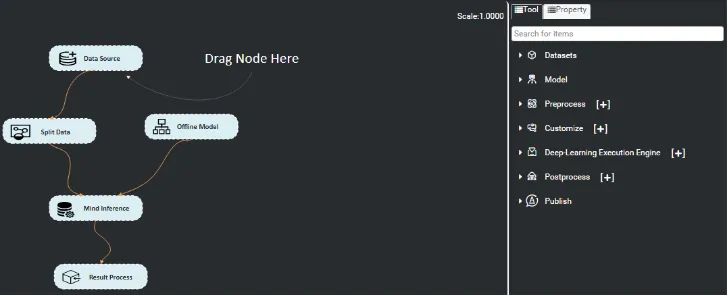
Atlas500智算小站整體開發(fā)體驗良好,特別是Matrix框架,將場景抽象,便于靈活地應(yīng)對不同業(yè)務(wù)需求。但device側(cè)在運行中崩潰以后問題不好排查,此外,Graph中各個Engine節(jié)點之間通信依賴的HDC如果崩潰,也會直接影響業(yè)務(wù)進(jìn)程的運行。
4.3 比特大陸 Sophon SE5
比特大陸,對,就是那家做礦機起家的比特大陸,憑借其在礦機芯片領(lǐng)域積累的技術(shù)實力,也積極向人工智能方向發(fā)力,推出了一系列性能強勁的AI算力產(chǎn)品(Sophon系列),包括算力芯片、算力服務(wù)器、算力云,主要應(yīng)用于區(qū)塊鏈和人工智能領(lǐng)域。
下圖是其官網(wǎng)列出的主要產(chǎn)品:

4.3.1 硬件參數(shù)
SOPHON SE5智算盒是一款高性能、低功耗邊緣計算產(chǎn)品,搭載算豐科技自主研發(fā)的第三代TPU芯片BM1684,INT8算力高達(dá)17.6TOPS,可同時處理16路高清視頻,支持38路1080P高清視頻硬件解碼與2路編碼。

4.3.2 開發(fā)工具鏈
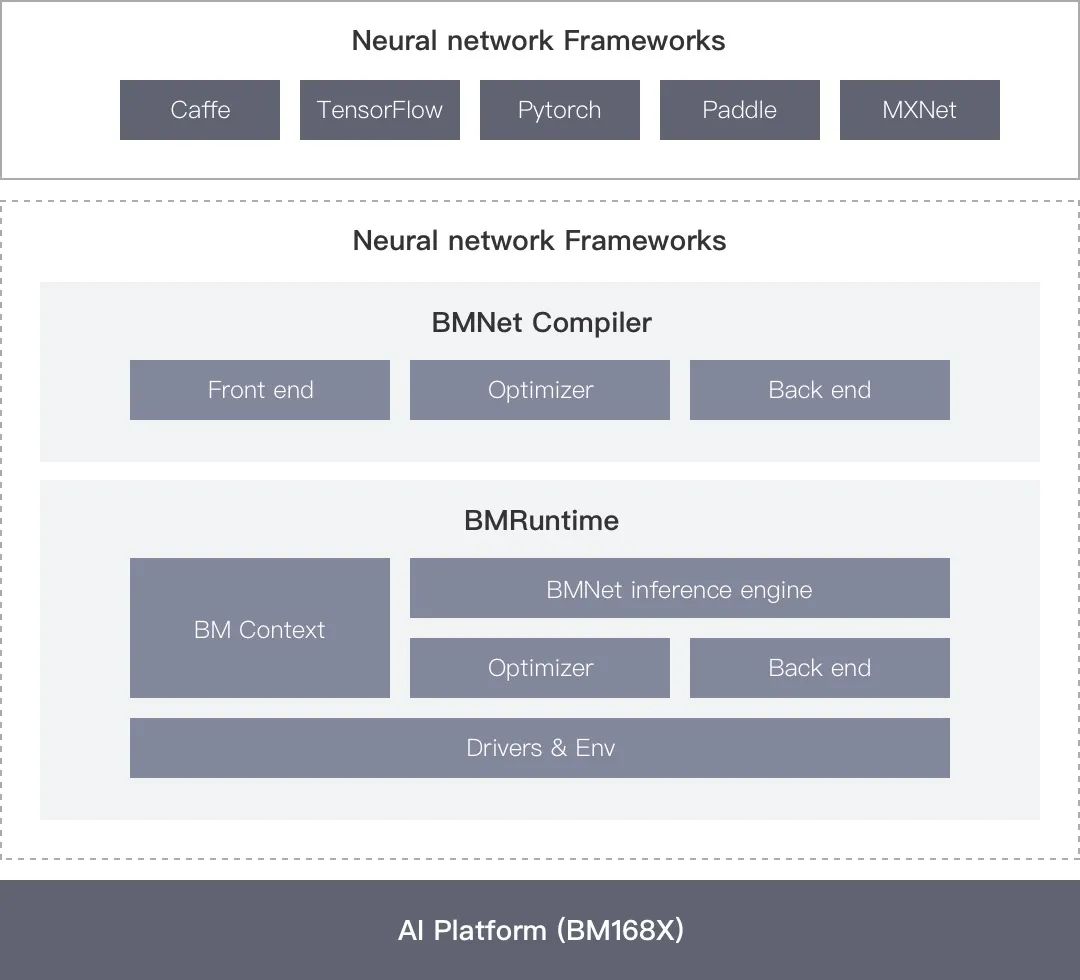
比特大陸提供了BMNNSDK(SOPHON Neural Network SDK)一站式工具包,提供底層驅(qū)動環(huán)境、編譯器、推理部署工具等一系列軟件工具。
BMNNSDK,涵蓋了神經(jīng)網(wǎng)絡(luò)推理階段所需的模型優(yōu)化、高效運行時支持等能力,由BMNet Compiler和BMRuntime兩部分組成。
BMNet Compiler 負(fù)責(zé)對各種深度神經(jīng)網(wǎng)絡(luò)模型(如caffemodel)進(jìn)行優(yōu)化和轉(zhuǎn)換,充分平衡EU運算和訪存時間,提升運算的并行度,并最終轉(zhuǎn)換成算豐科技TPU支持的bmodel模型。BMNet Compiler支持Caffe、Darknet、Tensorflow、Pytorch、MXNet等框架模型的轉(zhuǎn)換,暫不支持ONNX模型的直接轉(zhuǎn)換。如果轉(zhuǎn)換失敗,提供BMLang編程語言,通過CPU指令或者BMKernel底層語言實現(xiàn)不支持的算子或?qū)印?/p>
BMRuntime 負(fù)責(zé)驅(qū)動TPU芯片,為上層應(yīng)用程序提供統(tǒng)一的可編程接口,使程序可以通過bmodel模型進(jìn)行神經(jīng)網(wǎng)絡(luò)推理,而用戶無需關(guān)心底層硬件實現(xiàn)細(xì)節(jié)。
此外,BMNNSDK重新編譯了FFmpeg和OpenCV,增加了硬件加速支持,同時提供了一套高級接口SAIL,支持通過C++、Python直接使用SAIL接口編程。
4.4 Amlogic
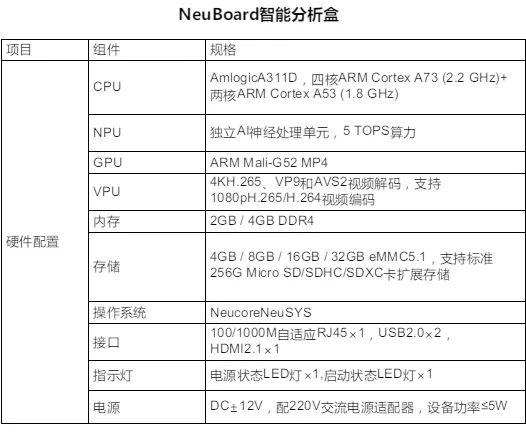
Amlogic,晶晨半導(dǎo)體是全球無晶圓半導(dǎo)體系統(tǒng)設(shè)計的領(lǐng)導(dǎo)者,為智能機頂盒、智能電視、智能家居等多個產(chǎn)品領(lǐng)域,提供多媒體SoC芯片和系統(tǒng)級解決方案。 下圖是搭載了其A331D芯片的智能盒子NeuBoard的相關(guān)參數(shù),具有功耗低、性價比高的優(yōu)點,有需要的同學(xué)也可以參考:
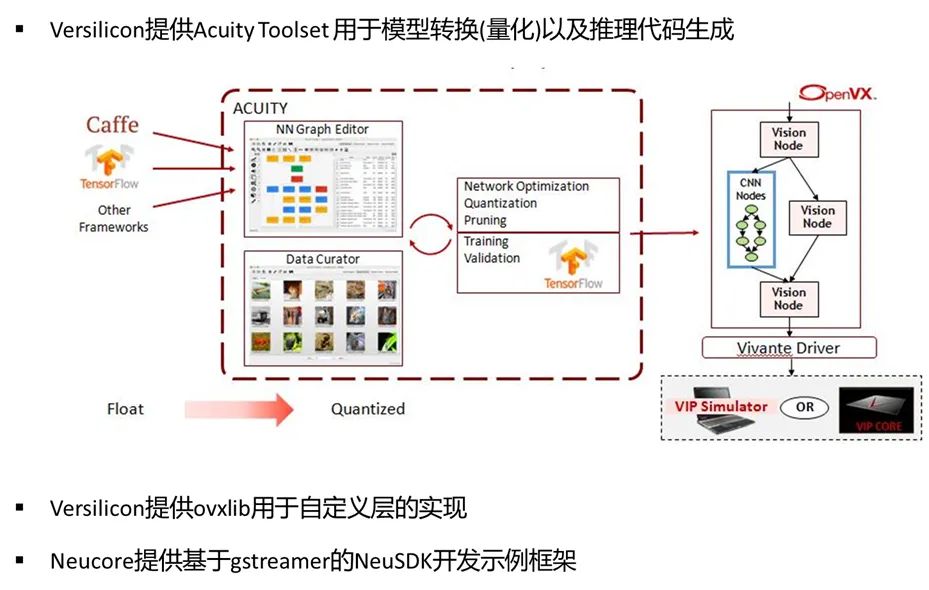
Amlogic的A311D中集成了ARM、NPU、GPU、VPU,NPU,NPU IP是由芯原微電子(Versilicon)提供的Vivante? NPU IP。
Versilicon提供了一套基于OpenVX的工具套件,Acuity Toolset幫助用戶將原生模型轉(zhuǎn)換為Vivante? NPU IP支持的模型。
Acuity Toolset支持Tensorflow、Tensorflow-Lite、Caffe、PyTorch、ONNX、TVM、IREE/MLIR等框架。
OPEN AI LAB 開源的針對嵌入式設(shè)備開發(fā)的輕量級、高性能并且模塊化引擎Tengine就支持Vivante? NPU IP。
此外,上海锘科智能科技(Neucore),Neucore也基于gstreamer開發(fā)了一套獨有的HCS框架,提供Linux和Android下的NeuSDK,可幫助客戶實現(xiàn)算法在CPU、NPU、GPU、DSP等多種架構(gòu)的快速移植和部署。NeuSDK中的Neucore Graph為客戶提供了一種更加便捷靈活的pipeline搭建方式,用戶可以使用SDK按照gstreamer插件的實現(xiàn)方式一樣實現(xiàn)自定義插件,并在web界面中通過拖拽式的操作快速自定義一系列的算法流程,完成任務(wù)部署。
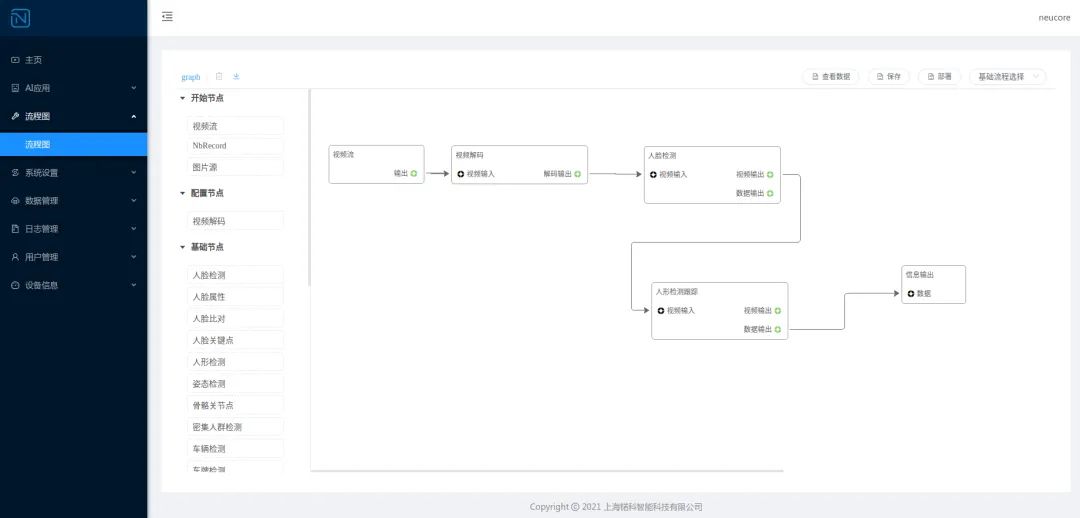
4.5 寒武紀(jì) MLU
中科寒武紀(jì)其實是較早布局深度學(xué)習(xí)處理器的企業(yè)之一,也是目前國際上少數(shù)幾家全面系統(tǒng),掌握了通用型智能芯片及其基礎(chǔ)系統(tǒng)軟件研發(fā)和產(chǎn)品化核心技術(shù)的企業(yè)之一。且能提供云邊端一體、軟硬件協(xié)同、訓(xùn)練推理融合、具備統(tǒng)一生態(tài)的系列化智能芯片產(chǎn)品和平臺化基礎(chǔ)系統(tǒng)軟件。
寒武紀(jì)的產(chǎn)品線也比較豐富,但由于它本身是專注做芯片、模組與基礎(chǔ)軟件的,并不提供成品的邊緣計算設(shè)備或服務(wù)器,如果需要,可以從其合作的下游廠商處購買。
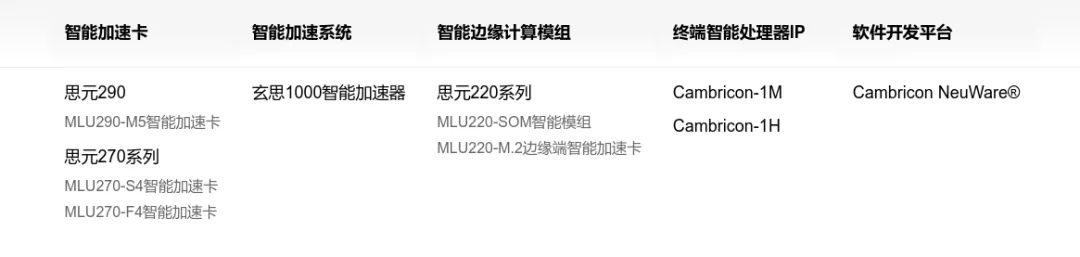
下圖是寒武紀(jì)MLU第一到第三代的相關(guān)參數(shù):
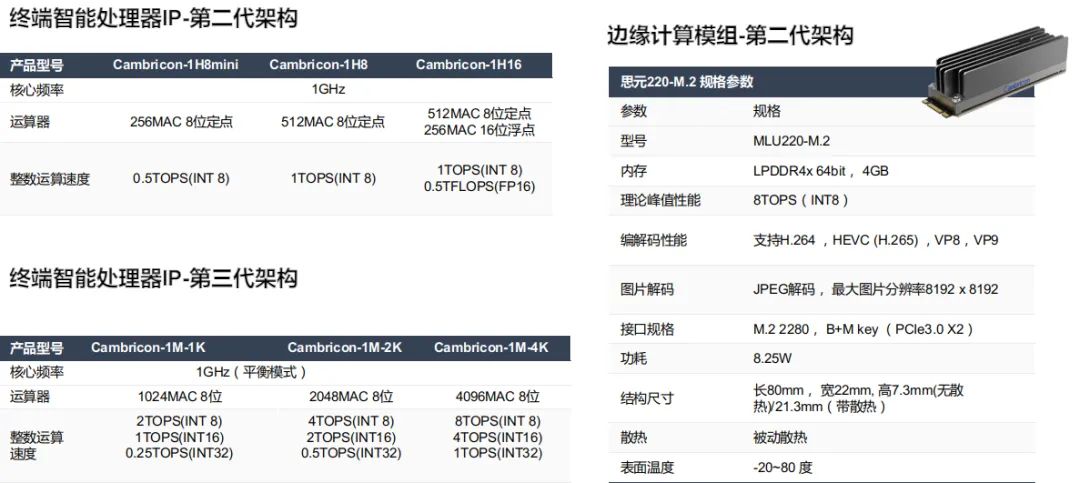
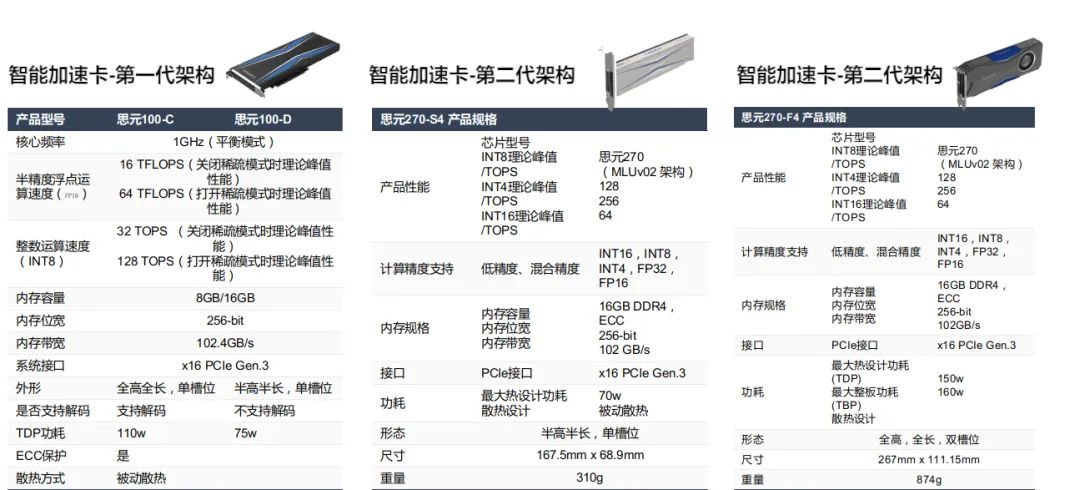
寒武紀(jì)人工智能開發(fā)平臺(Cambricon NeuWare?)是寒武紀(jì)專門針對其云、邊、端的智能處理器產(chǎn)品打造的軟件開發(fā)平臺, Neuware采用端云一體的架構(gòu),可同時支持寒武紀(jì)云、邊、端的全系列產(chǎn)品。下圖是寒武紀(jì)SDK的架構(gòu)圖及常用的工具包:

5 邊緣計算設(shè)備的使用
5.1 邊緣計算設(shè)備的選型思路
通過前面邊緣設(shè)備的介紹,我們知道市面上有很多款邊緣計算設(shè)備。那么針對各種不同的邊緣設(shè)備,當(dāng)算法訓(xùn)練完成,想要用邊緣設(shè)備部署時,如何選型?應(yīng)該關(guān)注哪些參數(shù)和性能呢?其實主要是以下幾點:
① 性能:arm核心數(shù)量和主頻、內(nèi)存與AI模組專用內(nèi)存、深度學(xué)習(xí)推理能力、視頻編解碼能力、jpeg編解碼以及其他視覺運算硬件加速能力。
② 價格:在性能都能滿足要求的情況下,價格自然成為選型的決定因素。特別是同一個AI模組,其實會有多家廠商競品可供選擇。比如浪潮的EIS200和凌華的DLAP-211-JNX都是基于NVIDIA的Jetson NX模組;
③ 工具鏈:支持主流框架模型情況,算子及網(wǎng)絡(luò)模型支持情況,接口易用程度,SDK、技術(shù)論壇完備程度和技術(shù)支持力度;
④ 外圍接口:板載的外圍接口是否能滿足應(yīng)用場景需求;
⑤ 功耗:有的客戶可能因為作業(yè)環(huán)境的限制對功耗要求比較嚴(yán)格,比如是在野外使用太陽能供電,但通常較低的功耗也意味著較低的算力。
5.2 邊緣計算設(shè)備比較
下圖是我整理的,幾種邊緣設(shè)備主要參數(shù)的對比圖:
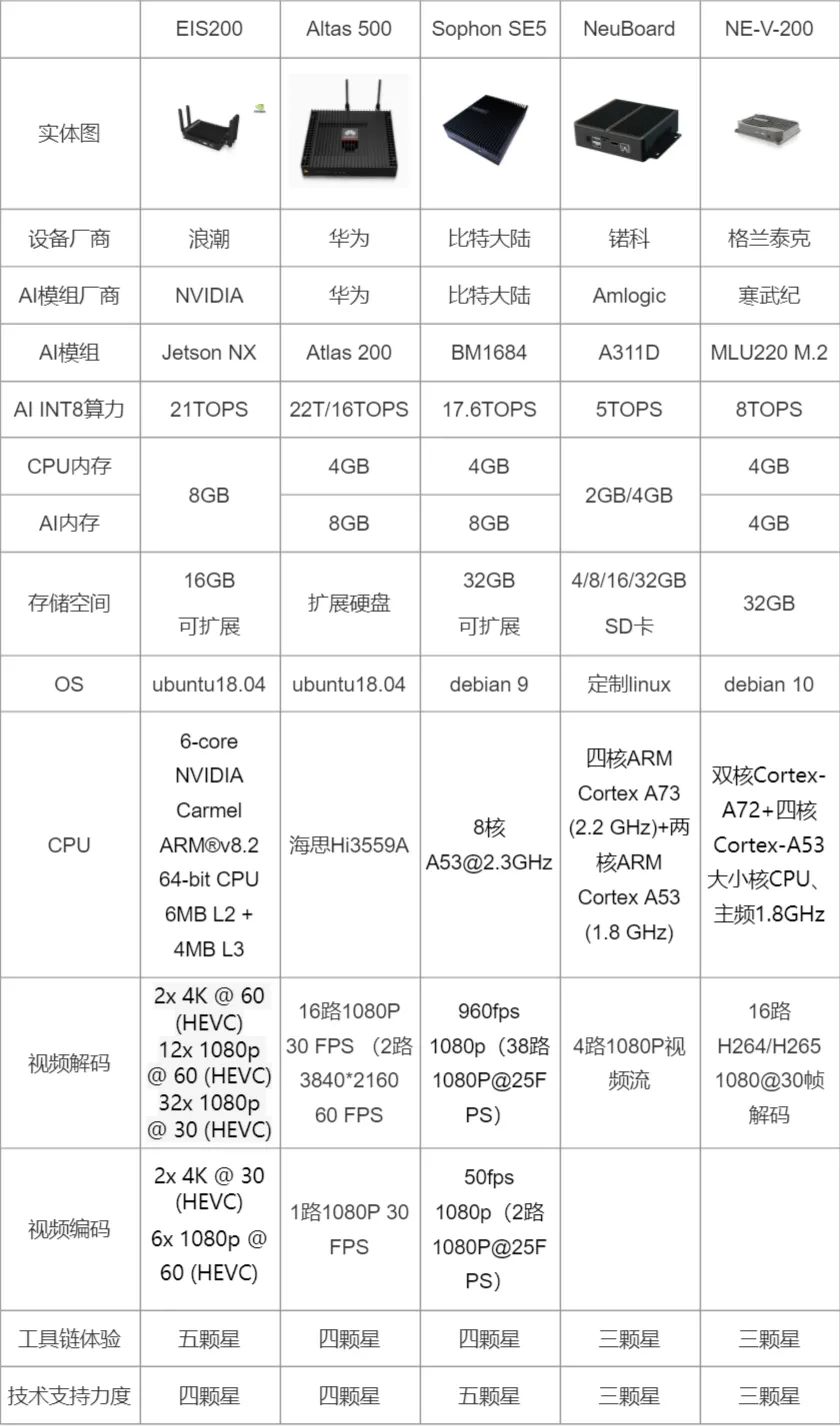
5.3 邊緣計算設(shè)備開發(fā)與GPU服務(wù)器開發(fā)的區(qū)別
我們再看一下,與GPU服務(wù)器相比,在邊緣計算設(shè)備上的AI應(yīng)用開發(fā)部署的主要區(qū)別有:
① CPU架構(gòu)不同:GPU服務(wù)器是x86架構(gòu),GPU插在主板的PCIE插槽內(nèi);而邊緣計算設(shè)備是基于aarch64的整體設(shè)備,其中有ARM CPU和GPU以及NPU、TPU、VPU等;
② 資源有限:邊緣設(shè)備由于資源有限,底層要使用C/C++推理,程序需要充分優(yōu)化,以壓榨硬件資源性能;
③ 交叉編譯:C/C++代碼直接在邊緣計算設(shè)備上編譯比較耗時,有的甚至不支持在設(shè)備中編譯,通常通過交叉編譯的方式,在宿主機上生成代碼,再拷貝到邊緣計算設(shè)備中執(zhí)行;
④ 遠(yuǎn)程調(diào)試:由于需要使用gdb server遠(yuǎn)程調(diào)試,VSCode很好用;
⑤ 軟件安裝:邊緣計算設(shè)備通常運行的是裁剪/定制的linux,debian/ubuntu可以使用apt在線安裝庫包,但有的邊緣計算設(shè)備內(nèi)的linux是精簡版的,沒有包管理工具,安裝軟件只能源碼交叉編譯;
5.4 邊緣計算設(shè)備的一般開發(fā)流程
了解了邊緣設(shè)備的內(nèi)容,我們再看一下邊緣設(shè)備的一般開發(fā)流程,通常由幾部分組成:
(1)基礎(chǔ)平臺開發(fā): 深度學(xué)習(xí)分析引擎、業(yè)務(wù)中臺、管理平臺;
(2)模型轉(zhuǎn)換、驗證及優(yōu)化: 使用硬件平臺廠商提供的模型轉(zhuǎn)換工具套件將caffe、tensorflow、pytorch、mxnet、darknet、onnx等模型轉(zhuǎn)換為目標(biāo)平臺模型,必要時進(jìn)行模型量化以及模型finetune;對不支持的模型或?qū)樱远x算子、插件實現(xiàn)
(3)視頻結(jié)構(gòu)化引擎代碼適配: 主要是視頻流及圖片編解碼、推理等模塊,任務(wù)管理、流程控制、前后處理等其他代碼通常都是跨平臺的;
(4)交叉編譯及測試: 使用交叉編譯工具鏈編譯及調(diào)試代碼,交叉編譯工具工具鏈主要包括2部分內(nèi)容,linaro gcc g++編譯及調(diào)試器和包含了目標(biāo)平臺系統(tǒng)環(huán)境及軟件庫的所有代碼文件;
(5)業(yè)務(wù)代碼實現(xiàn): 針對不同場景的業(yè)務(wù)需求開發(fā)業(yè)務(wù)邏輯處理代碼;
(6)系統(tǒng)部署: 通常使用docker部署,使用docker-compose編排多個docker容器或使用K8S管理多個分布式節(jié)點。
5.5 常見問題
當(dāng)然在開發(fā)過程中,還會存在一些常見的問題,這里也羅列一些問題和解決方式:
(1)模型轉(zhuǎn)換失敗:
解決方案:
① onnx模型轉(zhuǎn)換失敗,可能是onnx和opset的版本不支持,可以更換版本嘗試;
② onnx模型轉(zhuǎn)換失敗,也可能是轉(zhuǎn)換工具對onnx某些層支持不好,可以先使用onnx-simplifier簡化模型,優(yōu)化其中不必要的容易引起問題的層;
③ 如果是pytorch模型轉(zhuǎn)換失敗,需要注意pytorch有兩種類型的保存格式,一種是只有權(quán)重的,一種是帶有模型結(jié)構(gòu)和權(quán)重的JIT模型;轉(zhuǎn)換工具基本都要求JIT模型,應(yīng)當(dāng)使用torch.jit.trace保存。
④ 使用工具鏈提供的編程語言自定義算子實現(xiàn)不支持的層;
⑤ 將問題反饋給硬件廠商,詢問是否有新版本的SDK或等待問題解決;
⑥ 反饋給算法同事,修改模型結(jié)構(gòu),嘗試使用其他支持的等價算子,重新訓(xùn)練模型;
(2)模型推理結(jié)果不對:
解決方案:
① 檢查前后處理(包括輸入、輸出層的scale因子);
② 檢查模型轉(zhuǎn)換后輸出tensor的順序;
③ 使用工具鏈中提供的工具保存中間層結(jié)果,逐步排查解決。
(3)模型量化精度損失:
解決方案:
① 量化是一定會有精度損失的,這個無法避免;
② 數(shù)量更多和內(nèi)容更均衡的量化集,可以在一定程序改善量化模型的精度;
③ 如果仍無法滿足要求,重新訓(xùn)練量化后的模型(不是所有的平臺都支持)
(4)程序優(yōu)化:
解決方案:
① 首先,檢查程序最耗時的部分是在哪里,找出制約性能的瓶頸:視頻解碼?任務(wù)隊列?數(shù)據(jù)拷貝?還是算力資源不夠,模型需要進(jìn)一步裁剪優(yōu)化?
② 然后,針對具體問題優(yōu)化程序:使用更加高效的計算庫或者硬件加速接口、優(yōu)化多線程多進(jìn)程、改進(jìn)數(shù)據(jù)結(jié)構(gòu)、使用多Batch推理或者根據(jù)任務(wù)實際設(shè)置合理的處理幀率等。總之,優(yōu)化的主要原則就是減少不必要的數(shù)據(jù)拷貝、充分利用計算單元資源。
③ 通常,觀察AIPU(GPU/NPU/TPU)的利用率情況,如果一直比較平穩(wěn),說明計算資源得到了充分的利用;如果起伏比較大,甚至有突然的高峰和低谷,說明某些時刻AIPU在等待數(shù)據(jù);
④ 此外,某些AIPU可能對某種尺寸的數(shù)據(jù)、某些操作或特定參數(shù)的神經(jīng)網(wǎng)絡(luò)算子做了專門優(yōu)化,在設(shè)計模型時應(yīng)優(yōu)先選用高效的結(jié)構(gòu)和參數(shù)。 比如有的AI加速芯片的,若卷積層的輸入不是8的倍數(shù),底層會額外進(jìn)行多次padding操作;stride為3的卷積核比其他卷積核要更高效;輸入尺寸是512的倍數(shù)時的計算效率 > 256的倍數(shù)時的計算效率 > 128的倍數(shù)時的計算效率等。
互動問答1
Q:能簡單說說交叉編譯嗎?典型場景是啥?
A:由于C/C++代碼是依賴于硬件平臺的二進(jìn)制代碼,源碼需要經(jīng)過編譯器編譯、鏈接,最終生成可執(zhí)行的二進(jìn)制代碼。當(dāng)我們在一個架構(gòu)的平臺上,編譯生成在另一個架構(gòu)的平臺上運行的代碼的過程,就叫交叉編譯。交叉的意思就是編譯源碼的平臺與代碼運行的目標(biāo)平臺不同,比如我們要在x86的機器上編譯生成在邊緣計算盒子aarch64上的代碼,就需要交叉編譯。
互動問答2
Q:分享中從性能角度比較了幾款邊緣小站,從性價比角度,你覺得哪個更好?或者這么說, 如果讓你們公司挑選一個小站,把自有算法適配進(jìn)去,以軟硬一體的標(biāo)準(zhǔn)品賣出去,你會挑選哪個盒子?
A:關(guān)于盒子的選擇,首選還是推薦N vidia的Jetson系列。無論從價格還是生態(tài)來說,對開發(fā)者都是最友好的,同時代碼移植成本也最低。這幾款邊緣計算設(shè)備,華為官方的atlas 500小站價格比較高,要1.2-1.6W;amlogic的算力相對比較低,要便宜一些;其他的幾種差別不大,都在6000-8000,當(dāng)然如果供貨量大,價格應(yīng)該可以商量。此外,NVIDIA的Jetson盒子成品雖然價格比較高,但是官方出的模組并不貴,比如NX是3500,AGX是5000多,對于初學(xué)者和個人開發(fā)者比較友好。總的來說 ,推薦按照英偉達(dá)、比特大陸、華為、寒武紀(jì)、Amlogic的順序考察選定。
互動問答3
Q:在x86上的gnu工具是編譯不出aarch64的目標(biāo)代碼的,需要用到對應(yīng)aarch64的編譯器版本吧?這個就叫工具鏈?
A:編譯器是工具鏈中很重要的一部分,但是工具鏈中還有一部分就是目標(biāo)平臺的系統(tǒng)環(huán)境,其中包含了程序依賴的運行庫。這些依賴庫分為2部分:(1)一部分是屬于linux系統(tǒng)的基本庫,這部分庫通常都跟編譯器集成在一起;(2)另一部分是特殊的庫,比如我交叉編譯在比特大陸邊緣計算設(shè)備里的深度學(xué)習(xí)推理程序,還需要比特大陸的推理運行庫,這部分庫比特大陸會單獨提供,包含在其提供的sdk BMNNSDK中。所以這些應(yīng)該是一個整體,編譯器+系統(tǒng)/依賴庫。
互動問答4
Q:TensorRT部署比直接原生Pytorch,性能上有哪些優(yōu)勢?
A:首先,使用TensorRT部署和使用原生pytorch部署,其實并不是一個層面的概念,因為Pytorch也可以使用TensorRT。與TensorRT部署相對應(yīng)的,是直接使用CUDA;與原生Pytorch部署相對應(yīng)的,是使用libtorch或者其他框架比如DeepStream部署。現(xiàn)在我們再來說說部署的問題。
使用原生pytorch部署,主要有3個問題:
① 依賴于Python環(huán)境和Pytorch環(huán)境,這其實一個比較重的依賴,會導(dǎo)致程序比較龐大;
② Python的執(zhí)行效率沒有C/C++高,雖然單從模型推理這部分來說,效率差異也許不是那么明顯,畢竟就算是Python,底層很多庫也都是用C/C++實現(xiàn)的。但對于預(yù)處理、后處理以及視頻文件或視頻流的解碼等操作,Python就和C/C++差別比較大了。
③ Python不利于代碼的保護(hù),雖然也有一些措施可以保護(hù)源碼,比如使用Pyc或者通過修改Python解釋器源碼將py文件先加密解釋執(zhí)行時再解密,但效果有限,總的來說Python不如C/C++能夠更高的保護(hù)代碼。針對這一問題,Pytorch提供了libtorch庫,以方便開發(fā)人員使用C/C++代碼完成部署。
④ 使用TensorRT的好處: TensorRT是英偉達(dá)專門針對模型推理過程提供的優(yōu)化推理引擎,它會將模型中的很多操作進(jìn)行裁剪、整合、合并、并行化以及量化,使得模型推理速度提高2-10倍。
但在實際生產(chǎn)環(huán)境中,我們會更傾向于使用DeepStream,而不是libtorch,原因在于:⑤ DeepStream使得構(gòu)建任務(wù)流程變得更加簡單靈活,他不僅僅可以執(zhí)行推理,還可以利用英偉達(dá)優(yōu)化過的插件執(zhí)行視頻編解碼、多視頻流分析等其他也很重要的工作。
⑥ 在生產(chǎn)環(huán)境中部署時,我們應(yīng)盡可能使用硬件廠商提供的庫或SDK,而盡量少的依賴于其他第三方提供的庫,因為只有硬件廠商提供的庫才是更新和維護(hù)最及時的。
互動問答5
Q:DeepStream框架怎么應(yīng)用部署,有沒有典型的參考案例?
A:DeepStream SDK隨附了多個測試應(yīng)用程序,包括預(yù)訓(xùn)練的模型,示例配置文件和可用于運行這些應(yīng)用程序的示例視頻流,具體可以查看解壓后的文件夾下Samples文件夾下的內(nèi)容。DeepStream還內(nèi)置了人員檢測、車輛檢測、車輛分類、人臉檢測識別、車牌識別等多個模型和組件。
具體可以參考官方網(wǎng)站:https://developer.nvidia.com/deepstream-sdk。官方論壇:https://www.nvidia.cn/forums/,Github上也有許多豐富的樣例工程,CSDN上也有很多人撰寫的教程及說明。
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“CVPR21檢測”獲取CVPR2021目標(biāo)檢測論文下載~

# CV技術(shù)社群邀請函 #

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測-深圳)
即可申請加入極市目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
