
MySQL 分庫分表及其平滑擴(kuò)容方案
作者:王克鋒
出處:https://kefeng.wang/2018/07/22/mysql-sharding/
眾所周知,數(shù)據(jù)庫很容易成為應(yīng)用系統(tǒng)的瓶頸。單機(jī)數(shù)據(jù)庫的資源和處理能力有限,在高并發(fā)的分布式系統(tǒng)中,可采用分庫分表突破單機(jī)局限。本文總結(jié)了分庫分表的相關(guān)概念、全局ID的生成策略、分片策略、平滑擴(kuò)容方案、以及流行的方案。
1 分庫分表概述
在業(yè)務(wù)量不大時,單庫單表即可支撐。
當(dāng)數(shù)據(jù)量過大存儲不下、或者并發(fā)量過大負(fù)荷不起時,就要考慮分庫分表。
1.1 分庫分表相關(guān)術(shù)語
讀寫分離: 不同的數(shù)據(jù)庫,同步相同的數(shù)據(jù),分別只負(fù)責(zé)數(shù)據(jù)的讀和寫;
分區(qū): 指定分區(qū)列表達(dá)式,把記錄拆分到不同的區(qū)域中(必須是同一服務(wù)器,可以是不同硬盤),應(yīng)用看來還是同一張表,沒有變化;
分庫:一個系統(tǒng)的多張數(shù)據(jù)表,存儲到多個數(shù)據(jù)庫實例中;
分表: 對于一張多行(記錄)多列(字段)的二維數(shù)據(jù)表,又分兩種情形:
(1) 垂直分表: 豎向切分,不同分表存儲不同的字段,可以把不常用或者大容量、或者不同業(yè)務(wù)的字段拆分出去;
(2) 水平分表(最復(fù)雜): 橫向切分,按照特定分片算法,不同分表存儲不同的記錄。
1.2 真的要采用分庫分表?
需要注意的是,分庫分表會為數(shù)據(jù)庫維護(hù)和業(yè)務(wù)邏輯帶來一系列復(fù)雜性和性能損耗,除非預(yù)估的業(yè)務(wù)量大到萬不得已,切莫過度設(shè)計、過早優(yōu)化。
規(guī)劃期內(nèi)的數(shù)據(jù)量和性能問題,嘗試能否用下列方式解決:
當(dāng)前數(shù)據(jù)量:如果沒有達(dá)到幾百萬,通常無需分庫分表;
數(shù)據(jù)量問題:增加磁盤、增加分庫(不同的業(yè)務(wù)功能表,整表拆分至不同的數(shù)據(jù)庫);
性能問題:升級CPU/內(nèi)存、讀寫分離、優(yōu)化數(shù)據(jù)庫系統(tǒng)配置、優(yōu)化數(shù)據(jù)表/索引、優(yōu)化 SQL、分區(qū)、數(shù)據(jù)表的垂直切分;
如果仍未能奏效,才考慮最復(fù)雜的方案:數(shù)據(jù)表的水平切分。
2 全局ID生成策略
2.1 自動增長列
優(yōu)點:數(shù)據(jù)庫自帶功能,有序,性能佳。
缺點:單庫單表無妨,分庫分表時如果沒有規(guī)劃,ID可能重復(fù)。解決方案:
2.1.1 設(shè)置自增偏移和步長
###?假設(shè)總共有?10?個分表
###?級別可選:?SESSION(會話級),?GLOBAL(全局)
SET?@@SESSION.auto_increment_offset?=?1;?###?起始值,?分別取值為?1~10
SET?@@SESSION.auto_increment_increment?=?10;?###?步長增量
如果采用該方案,在擴(kuò)容時需要遷移已有數(shù)據(jù)至新的所屬分片。
2.1.2 全局ID映射表
在全局 Redis 中為每張數(shù)據(jù)表創(chuàng)建一個 ID 的鍵,記錄該表當(dāng)前最大 ID;
每次申請 ID 時,都自增 1 并返回給應(yīng)用;
Redis 要定期持久至全局?jǐn)?shù)據(jù)庫。
2.2 UUID(128位)
在一臺機(jī)器上生成的數(shù)字,它保證對在同一時空中的所有機(jī)器都是唯一的。通常平臺會提供生成UUID的API。
UUID 由4個連字號(-)將32個字節(jié)長的字符串分隔后生成的字符串,總共36個字節(jié)長。形如:550e8400-e29b-41d4-a716-446655440000。
UUID 的計算因子包括:以太網(wǎng)卡地址、納秒級時間、芯片ID碼和許多可能的數(shù)字。
UUID 是個標(biāo)準(zhǔn),其實現(xiàn)有幾種,最常用的是微軟的 GUID(Globals Unique Identifiers)。
優(yōu)點:簡單,全球唯一;
缺點:存儲和傳輸空間大,無序,性能欠佳。
2.3 COMB(組合)
參考資料:The Cost of GUIDs as Primary Keys
組合 GUID(10字節(jié)) 和時間(6字節(jié)),達(dá)到有序的效果,提高索引性能。
2.4 Snowflake(雪花) 算法
參考資料:twitter/snowflake,Snowflake 算法詳解
Snowflake 是 Twitter 開源的分布式 ID 生成算法,其結(jié)果為 long(64bit) 的數(shù)值。
其特性是各節(jié)點無需協(xié)調(diào)、按時間大致有序、且整個集群各節(jié)點單不重復(fù)。
該數(shù)值的默認(rèn)組成如下(符號位之外的三部分允許個性化調(diào)整):
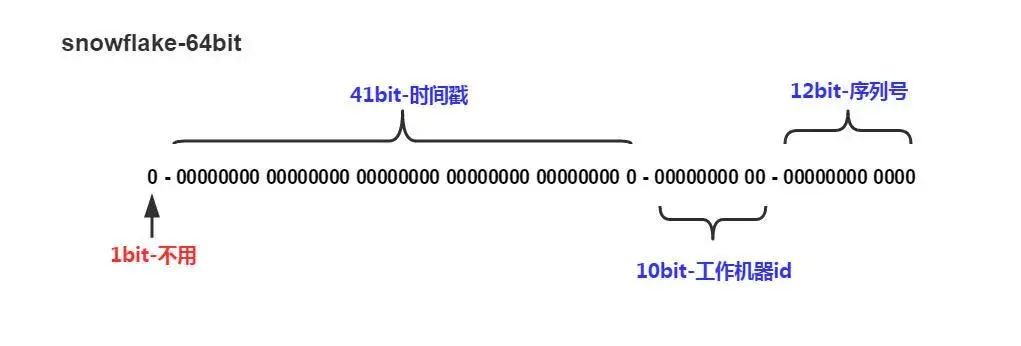
1bit: 符號位,總是 0(為了保證數(shù)值是正數(shù))。
41bit: 毫秒數(shù)(可用 69 年);
10bit: 節(jié)點ID(5bit數(shù)據(jù)中心 + 5bit節(jié)點ID,支持 32 * 32 = 1024 個節(jié)點)
12bit: 流水號(每個節(jié)點每毫秒內(nèi)支持 4096 個 ID,相當(dāng)于 409萬的 QPS,相同時間內(nèi)如 ID 遇翻轉(zhuǎn),則等待至下一毫秒)
3 分片策略
3.1 連續(xù)分片
根據(jù)特定字段(比如用戶ID、訂單時間)的范圍,值在該區(qū)間的,劃分到特定節(jié)點。
優(yōu)點:集群擴(kuò)容后,指定新的范圍落在新節(jié)點即可,無需進(jìn)行數(shù)據(jù)遷移。
缺點:如果按時間劃分,數(shù)據(jù)熱點分布不均(歷史數(shù)冷當(dāng)前數(shù)據(jù)熱),導(dǎo)致節(jié)點負(fù)荷不均。
3.3 ID取模分片
缺點:擴(kuò)容后需要遷移數(shù)據(jù)。
3.2 一致性Hash算法
優(yōu)點:擴(kuò)容后無需遷移數(shù)據(jù)。
3.4 Snowflake 分片
優(yōu)點:擴(kuò)容后無需遷移數(shù)據(jù)。
4 分庫分表引入的問題
4.1 分布式事務(wù)
參見 分布式事務(wù)的解決方案
由于兩階段/三階段提交對性能損耗大,可改用事務(wù)補(bǔ)償機(jī)制。
4.2 跨節(jié)點 JOIN
對于單庫 JOIN,MySQL 原生就支持;
對于多庫,出于性能考慮,不建議使用 MySQL 自帶的 JOIN,可以用以下方案避免跨節(jié)點 JOIN:
全局表: 一些穩(wěn)定的共用數(shù)據(jù)表,在各個數(shù)據(jù)庫中都保存一份;
字段冗余: 一些常用的共用字段,在各個數(shù)據(jù)表中都保存一份;
應(yīng)用組裝:應(yīng)用獲取數(shù)據(jù)后再組裝。
另外,某個 ID 的用戶信息在哪個節(jié)點,他的關(guān)聯(lián)數(shù)據(jù)(比如訂單)也在哪個節(jié)點,可以避免分布式查詢。
4.3 跨節(jié)點聚合
只能在應(yīng)用程序端完成。
但對于分頁查詢,每次大量聚合后再分頁,性能欠佳。
4.4 節(jié)點擴(kuò)容
節(jié)點擴(kuò)容后,新的分片規(guī)則導(dǎo)致數(shù)據(jù)所屬分片有變,因而需要遷移數(shù)據(jù)。
5 節(jié)點擴(kuò)容方案
相關(guān)資料: 數(shù)據(jù)庫秒級平滑擴(kuò)容架構(gòu)方案
5.1 常規(guī)方案
如果增加的節(jié)點數(shù)和擴(kuò)容操作沒有規(guī)劃,那么絕大部分?jǐn)?shù)據(jù)所屬的分片都有變化,需要在分片間遷移:
預(yù)估遷移耗時,發(fā)布停服公告;
停服(用戶無法使用服務(wù)),使用事先準(zhǔn)備的遷移腳本,進(jìn)行數(shù)據(jù)遷移;
修改為新的分片規(guī)則;
啟動服務(wù)器。
5.2 免遷移擴(kuò)容
采用雙倍擴(kuò)容策略,避免數(shù)據(jù)遷移。擴(kuò)容前每個節(jié)點的數(shù)據(jù),有一半要遷移至一個新增節(jié)點中,對應(yīng)關(guān)系比較簡單。
具體操作如下(假設(shè)已有 2 個節(jié)點 A/B,要雙倍擴(kuò)容至 A/A2/B/B2 這 4 個節(jié)點):
無需停止應(yīng)用服務(wù)器;
新增兩個數(shù)據(jù)庫 A2/B2 作為從庫,設(shè)置主從同步關(guān)系為:A=>A2、B=>B2,直至主從數(shù)據(jù)同步完畢(早期數(shù)據(jù)可手工同步);
調(diào)整分片規(guī)則并使之生效:
原ID%2=0 => A改為ID%4=0 => A, ID%4=2 => A2;
原ID%2=1 => B改為ID%4=1 => B, ID%4=3 => B2。解除數(shù)據(jù)庫實例的主從同步關(guān)系,并使之生效;
此時,四個節(jié)點的數(shù)據(jù)都已完整,只是有冗余(多存了和自己配對的節(jié)點的那部分?jǐn)?shù)據(jù)),擇機(jī)清除即可(過后隨時進(jìn)行,不影響業(yè)務(wù))。
6 分庫分表方案
6.1 代理層方式
部署一臺代理服務(wù)器偽裝成 MySQL 服務(wù)器,代理服務(wù)器負(fù)責(zé)與真實 MySQL 節(jié)點的對接,應(yīng)用程序只和代理服務(wù)器對接。對應(yīng)用程序是透明的。
比如 MyCAT,官網(wǎng),源碼,參考文檔:MyCAT+MySQL 讀寫分離部署
MyCAT 后端可以支持 MySQL, SQL Server, Oracle, DB2, PostgreSQL等主流數(shù)據(jù)庫,也支持MongoDB這種新型NoSQL方式的存儲,未來還會支持更多類型的存儲。
MyCAT 不僅僅可以用作讀寫分離,以及分表分庫、容災(zāi)管理,而且可以用于多租戶應(yīng)用開發(fā)、云平臺基礎(chǔ)設(shè)施,讓你的架構(gòu)具備很強(qiáng)的適應(yīng)性和靈活性。
6.2 應(yīng)用層方式
處于業(yè)務(wù)層和 JDBC 層中間,是以 JAR 包方式提供給應(yīng)用調(diào)用,對代碼有侵入性。主要方案有:
(1)淘寶網(wǎng)的 TDDL: 已于 2012 年關(guān)閉了維護(hù)通道,建議不要使用。
(2)當(dāng)當(dāng)網(wǎng)的 Sharding-JDBC: 仍在活躍維護(hù)中:
是當(dāng)當(dāng)應(yīng)用框架 ddframe 中,從關(guān)系型數(shù)據(jù)庫模塊 dd-rdb 中分離出來的數(shù)據(jù)庫水平分片框架,實現(xiàn)透明化數(shù)據(jù)庫分庫分表訪問,實現(xiàn)了 Snowflake 分片算法;
Sharding-JDBC定位為輕量Java框架,使用客戶端直連數(shù)據(jù)庫,無需額外部署,無其他依賴,DBA也無需改變原有的運維方式。
Sharding-JDBC分片策略靈活,可支持等號、between、in等多維度分片,也可支持多分片鍵。
SQL解析功能完善,支持聚合、分組、排序、limit、or等查詢,并支持Binding Table以及笛卡爾積表查詢。
Sharding-JDBC直接封裝JDBC API,可以理解為增強(qiáng)版的JDBC驅(qū)動,舊代碼遷移成本幾乎為零:
可適用于任何基于Java的ORM框架,如JPA、Hibernate、Mybatis、Spring JDBC Template或直接使用JDBC。
可基于任何第三方的數(shù)據(jù)庫連接池,如DBCP、C3P0、 BoneCP、Druid等。
理論上可支持任意實現(xiàn)JDBC規(guī)范的數(shù)據(jù)庫。雖然目前僅支持MySQL,但已有支持Oracle、SQLServer等數(shù)據(jù)庫的計劃。
推薦閱讀:
不是你需要中臺,而是一名合格的架構(gòu)師(附各大廠中臺建設(shè)PPT)
企業(yè)IT技術(shù)架構(gòu)規(guī)劃方案
論數(shù)字化轉(zhuǎn)型——轉(zhuǎn)什么,如何轉(zhuǎn)?
企業(yè)10大管理流程圖,數(shù)字化轉(zhuǎn)型從業(yè)者必備!
【中臺實踐】華為大數(shù)據(jù)中臺架構(gòu)分享.pdf
超詳細(xì)280頁Docker實戰(zhàn)文檔!開放下載