據(jù)Facebook 官方博客公告,PyTorch1.7版本已經(jīng)于昨日正式發(fā)布,相比于以往的 PyTorch 版本,此次更新除了增加了更多的API,還能夠支持 NumPy兼容下的傅里葉變換、性能分析工具,以及對基于分布式數(shù)據(jù)并行(DDP)和遠程過程調(diào)用(RPC)的分布式訓練。此外,原有的一些功能也轉(zhuǎn)移到了穩(wěn)定版,包括自定義C++?-> 類(Classes)、內(nèi)存分析器、通過自定義張量類對象進行的擴展、RPC中的用戶異步功能以及Torch.Distributed中的許多其他功能,如Per-RPC超時、DDP動態(tài)分組(bucketing)和RRef助手。1、PyTorch.org上提供的二進制文件現(xiàn)在正式支持CUDA 112、對Autograd分析器中的RPC、TorchScript和堆棧跟蹤的分析和性能進行了更新和添加。3、(測試版)通過torch.fft支持NumPy兼容的快速傅立葉變換(FFT)。4、(原型)支持NVIDIA A100 GPU和本地的TF32格式。注:從Pytorch1.6版本開始,PyTorch 的特性將分為 Stable(穩(wěn)定版)、Beta(測試版)和 Prototype(原型版)前端接口
[測試版]與Numpy兼容的TORCH.FFT模塊與FFT相關(guān)的功能通常用于各種科學領域,如信號處理。雖然PyTorch過去一直支持一些與FFT相關(guān)的函數(shù),但1.7版本添加了一個新的torch.fft模塊,該模塊使用與NumPy相同的API實現(xiàn)與FFT相關(guān)的函數(shù)。此新模塊必須導入才能在1.7版本中使用,因為它的名稱與之前(現(xiàn)已棄用)的torch.fft函數(shù)沖突。
? ? ? ? ? ? ? ?[測試版]對轉(zhuǎn)換器NN模塊的C++支持從PyTorch1.5開始,就繼續(xù)保持了Python和C++前端API之間的一致性。這次更新能夠讓開發(fā)人員使用C++前端的nn.former模塊。此外,開發(fā)人員不再需要將模塊從python/JIT保存并加載到C++中,因為它現(xiàn)在可以在C++中直接使用。再現(xiàn)性(逐位確定性)可能有助于在調(diào)試或測試程序時識別錯誤。為了便于實現(xiàn)重現(xiàn)性,PyTorch 1.7添加了torch.set_defiristic(Bool)函數(shù),該函數(shù)可以指導PyTorch操作符選擇確定性算法(如果可用),并在操作可能導致不確定性行為時給出運行時錯誤的標識。默認情況下,此函數(shù)控制的標志為false,這意味著在默認情況下,PyTorch可能無法確定地實現(xiàn)操作。1、已知沒有確定性實現(xiàn)的操作給出運行時錯誤;2、具有確定性變體( variants)的操作使用這些變體(與非確定性版本相比,通常會降低性能);3、設置:torch.backends.cudnn.deterministic = True .請注意,對于PyTorch程序的單次運行中的確定性而言,這屬于非充分必要條件。還有其他隨機性來源也可能導致不確定性行為,例如隨機數(shù)生成器、未知操作、異步或分布式計算。
? ? ? ?[測試版]對轉(zhuǎn)換器NN模塊的C++支持從PyTorch1.5開始,就繼續(xù)保持了Python和C++前端API之間的一致性。這次更新能夠讓開發(fā)人員使用C++前端的nn.former模塊。此外,開發(fā)人員不再需要將模塊從python/JIT保存并加載到C++中,因為它現(xiàn)在可以在C++中直接使用。再現(xiàn)性(逐位確定性)可能有助于在調(diào)試或測試程序時識別錯誤。為了便于實現(xiàn)重現(xiàn)性,PyTorch 1.7添加了torch.set_defiristic(Bool)函數(shù),該函數(shù)可以指導PyTorch操作符選擇確定性算法(如果可用),并在操作可能導致不確定性行為時給出運行時錯誤的標識。默認情況下,此函數(shù)控制的標志為false,這意味著在默認情況下,PyTorch可能無法確定地實現(xiàn)操作。1、已知沒有確定性實現(xiàn)的操作給出運行時錯誤;2、具有確定性變體( variants)的操作使用這些變體(與非確定性版本相比,通常會降低性能);3、設置:torch.backends.cudnn.deterministic = True .請注意,對于PyTorch程序的單次運行中的確定性而言,這屬于非充分必要條件。還有其他隨機性來源也可能導致不確定性行為,例如隨機數(shù)生成器、未知操作、異步或分布式計算。性能與性能分析
用戶現(xiàn)在不僅可以看到分析器輸出表中的操作員名稱/輸入,還可以看到操作員在代碼中的位置。在具體工作流程中,只需極少的更改即可利用此功能。用戶像以前一樣使用自動評分檢測器,但帶有可選的新參數(shù):WITH_STACK和GROUP_BY_STACK_n。注意:常規(guī)分析運行不應使用此功能,因為它會增加大量成本。分布式訓練和RPC
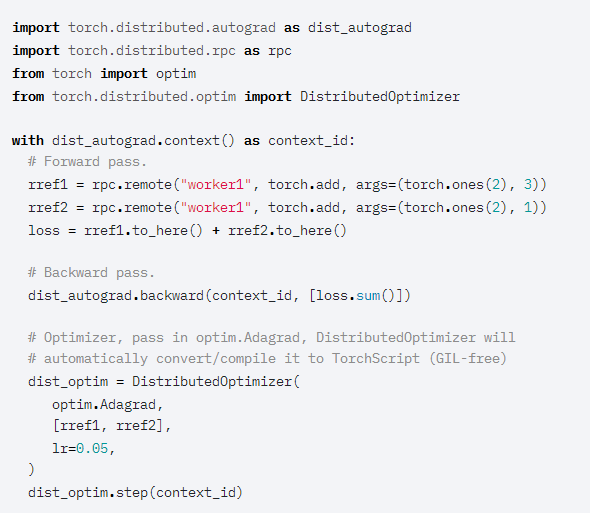
[穩(wěn)定]TORCHELASTIC現(xiàn)在綁定到PYTORCH DOCKER鏡像Torchelastic提供了一個當前Torch.Distributed的嚴格superset,啟動CLI時增加了容錯和彈性功能。如果用戶對容錯不感興趣,可以通過設置max_restarts=0獲得更加精確的指定。另外,還增加了自動分配RANK和MASTER_ADDR|PORT的便利性。通過將Torchelastic捆綁在與PyTorch相同的鏡像中,用戶可以立即開始嘗試使用TorchElastic,而不必單獨安裝Torchelastic。除了方便之外,當在現(xiàn)有Kubeflow的分布式PyTorch操作符中添加對彈性參數(shù)的支持時,這項工作也是非常有用的。[測試版]支持DDP中不均勻的數(shù)據(jù)集輸入PyTorch1.7引入了一個新的上下文管理器,該管理器將與使用torch.nn.parallel.DistributedDataParallel 訓練的模型結(jié)合使用,以支持跨進程使用不均勻的數(shù)據(jù)集進行訓練。此功能在使用DDP時提供了更大的靈活性,用戶不用“手動”,就能保證數(shù)據(jù)集大小相同。使用此上下文管理器,DDP將自動處理不均勻的數(shù)據(jù)集大小,這可以防止訓練結(jié)束時出現(xiàn)錯誤。[測試版]NCCL可靠性-ASYNC錯誤/超時處理在過去,NCCL的訓練運行會因為集體卡住而無限期地掛起(hang),使得用戶體驗非常糟糕。如果檢測到潛在的掛起(hang),此功能會給出異常/使進程崩潰的警告。當與torchelastic(它可以恢復“最近”的訓練過程)之類的東西一起使用時,分布式訓練將更加可靠。此功能并不強制,屬于可選性操作,并且位于需要顯式設置才能啟用此功能。[測試版]TORCHSCRIPT RPC_REMOTE和RPC_SYNC在早期版本中,Torch.Distributed.rpc.rpc_async已在TorchScript中提供。對于PyTorch1.7,此功能將擴展到剩下的兩個核心RPCAPI:torch.Distributed.rpc.rpc_sync和torch.Distributed.rpc.remote。這將完成計劃在TorchScript中支持的主要RPC API,它允許用戶在TorchScript中使用現(xiàn)有的python RPC API,并可能提高多線程環(huán)境中的應用程序性能。[測試版]支持TORCHSCRIPT的分布式優(yōu)化器PyTorch提供了一系列用于訓練算法的優(yōu)化器,這些優(yōu)化器已作為python API的一部分。然而,用戶通常希望使用多線程訓練而不是多進程訓練,因為多線程訓練在大規(guī)模分布式訓練中提供了更好的資源利用率和效率。以前的分布式優(yōu)化器沒有此效率,因為需要擺脫python全局解釋器鎖(GIL)的限制才能實現(xiàn)這一點。在PyTorch1.7中,啟用了分布式優(yōu)化器中的TorchScript支持來刪除GIL,并使優(yōu)化器能夠在多線程應用程序中運行。新的分布式優(yōu)化器具有與以前完全相同的接口,但是它會自動將每個Worker中的優(yōu)化器轉(zhuǎn)換為TorchScript,從而使每個GIL空閑。PyTorch 1.6首次引入了對結(jié)合使用PyTorch分析器和RPC框架的支持。在PyTorch 1.7中,進行了以下增強:1、’實現(xiàn)了對通過RPC分析TorchScript函數(shù)的更好支持。2、在使用RPC的分析器功能方面實現(xiàn)了奇偶校驗。3、增加了對服務器端異步RPC函數(shù)的支持(使用rpc.functions.async_Execution)。用戶現(xiàn)在可以使用熟悉的性能分析工具,比如torch.autograd.profiler.profile()和torch.autograd.profiler.record_function,這可以與RPC框架配合使用,這些RPC框架具有:全功能支持、配置文件異步函數(shù)和TorchScript函數(shù)。PyTorch1.7為Windows平臺上的DistributedDataParallel和集合通信提供了原型支持。在此版本中,僅支持基于Gloo的ProcessGroup和FileStore。如果要跨多臺計算機使用此功能,可以在init_process_group中提供來自共享文件系統(tǒng)的文件。? ? ?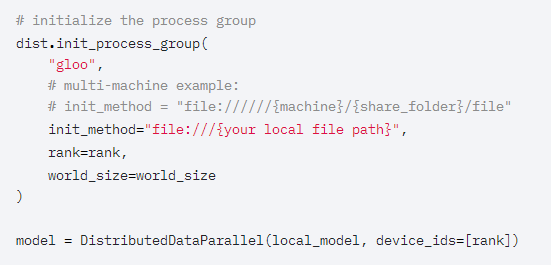
Mobile
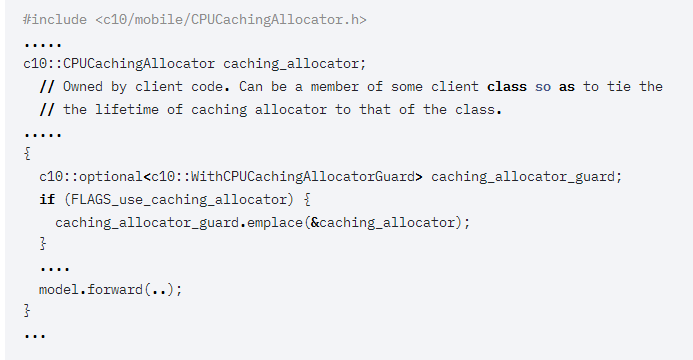
PyTorch Mobile支持iOS和Android,CocoaPods和JCenter,并分別提供了二進制軟件包。在一些移動平臺上,比如Pixel,內(nèi)存歸還給系統(tǒng)過于頻繁的時候,會導致頁面錯誤。原因是作為功能框架的PyTorch不維護操作符的狀態(tài)。因此,對于大多數(shù)操作,每次執(zhí)行操作時都會動態(tài)分配輸出。為了改善由此造成的性能損失,PyTorch1.7為CPU提供了一個簡單的緩存分配器。分配器按張量大小緩存分配,目前只能通過PyTorch C++API使用。緩存分配器本身歸客戶端所有,客戶端擁有的緩存分配器然后可以與c10::WithCPUCachingAllocatorGuard 一起使用,以允許在該作用域內(nèi)使用緩存分配。緩存分配器僅在移動版本上可用,因此在移動版本之外使用緩存分配器將會失效。torchvision
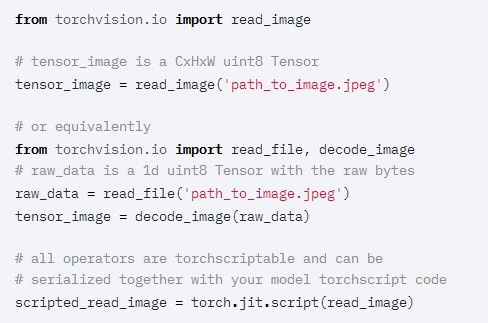
[穩(wěn)定]TRANSFORMS現(xiàn)在支持張量輸入、批處理計算、GPU和TORCHSCRIPTTorchvision transforms 現(xiàn)在繼承自 nn.Module,并且可以編寫TorchScript腳本并將其應用于 torch Tensor ?輸入以及PIL圖像。它們還支持具有批處理維度的張量,并可在CPU/GPU設備上無縫工作:2、批量轉(zhuǎn)換,例如根據(jù)視頻的需要。3、變換多波段torch張量圖像(3-4個以上通道)TorchScript transforms ?與模型一起部署時請注意:TorchScript支持的例外包括Compose、RandomChoice、RandomOrder、Lambda等等[穩(wěn)定]JPEG和PNG格式的本地圖像IOTorchvision 0.8.0引入了JPEG和PNG格式的本地圖像讀寫操作。這些操作符支持TorchScript并以uint8格式返回CxHxW tensors,因此現(xiàn)在可以成為在C++環(huán)境中部署的模型的一部分。
? ? ? ? ? ? ? ?此版本為Retinanet添加了預先訓練的模型,該模型具有ResNet50主干,可用于物體檢測。此版本引入了一個新的視頻閱讀API,可以更細粒度地控制視頻的更新迭代。它支持圖像和音頻,并實現(xiàn)了迭代器接口,因此可以與其他python庫(如itertools)交互操作。
? ? ? ?
? ? ? ?此版本為Retinanet添加了預先訓練的模型,該模型具有ResNet50主干,可用于物體檢測。此版本引入了一個新的視頻閱讀API,可以更細粒度地控制視頻的更新迭代。它支持圖像和音頻,并實現(xiàn)了迭代器接口,因此可以與其他python庫(如itertools)交互操作。
? ? ? ? ? ? ?1、要使用Video Reader API測試版,必須使用源編譯torchvision,并在系統(tǒng)中安裝ffmpeg。
? ? ?1、要使用Video Reader API測試版,必須使用源編譯torchvision,并在系統(tǒng)中安裝ffmpeg。torchaudio
通過這個版本,torchaudio正在擴展對模型和端到端應用,增加了wav2letter訓練管道和端到端文本到語音以及源分離管道在上一個版本中添加了用于語音識別的Wave2Letter模型的基礎上,現(xiàn)在使用LibriSpeech數(shù)據(jù)集添加了一個Wave2Letter訓練管道。.為了支持文本到語音的應用程序,在此存儲庫的實現(xiàn)的基礎上,添加了一個基于WaveRNN模型的聲碼器。另外,還提供了一個示例:WaveRNN訓練管道,該管道使用在pytorch 1.7版本中添加到torchaudio中的LibriTTS數(shù)據(jù)集。隨著ConvTasNet模型的加入,基于“Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation,””一文,Torchaudio現(xiàn)在也支持源分離。WSJ-MIX數(shù)據(jù)集提供了一個示例:ConvTasNet訓練管道。https://pytorch.org/blog/pytorch-1.7-released/往期精彩:
【原創(chuàng)首發(fā)】機器學習公式推導與代碼實現(xiàn)30講.pdf
【原創(chuàng)首發(fā)】深度學習語義分割理論與實戰(zhàn)指南.pdf
?2020,從TF Boy 變成 Torch User
喜歡您就點個在看!