
目標檢測 | 清晰易懂的SSD算法原理綜述
重磅干貨,第一時間送達

SSD(Single Shot Detection)是一個流行且強大的目標檢測網(wǎng)絡,網(wǎng)絡結構包含了基礎網(wǎng)絡(Base Network),輔助卷積層(Auxiliary Convolutions)和預測卷積層(Predicton Convolutions)。
本文包含了以下幾個部分:
(1)理解SSD網(wǎng)絡算法所需要理解的幾個重要概念
(2)SSD網(wǎng)絡框架圖
(3)SSD網(wǎng)絡中幾個重要概念的詳細解釋
(4)SSD網(wǎng)絡如何定位目標
(5)SSD網(wǎng)絡的算法流程圖
(5)小結
Single Shot Detection :早期的目標檢測系統(tǒng)包含了兩個不同階段:目標定位和目標檢測,這類系統(tǒng)計算量非常耗時,不適用實際應用。Single Shot Detection模型在網(wǎng)絡的前向運算中封裝了定位和檢測,從而顯著提高了運算速度。
多尺度特征映射圖(Multiscale Feature Maps):小編認為這是SSD算法的核心之一,原始圖像經(jīng)過卷積層轉換后的數(shù)據(jù)稱為特征映射圖(Feature Map),特征映射圖包含了原始圖像的信息。SSD網(wǎng)絡包含了多個卷積層,用多個卷積層后的特征映射圖來定位和檢測原始圖像的物體。
先驗框(Priors):在特征映射圖的每個位置預先定義不同大小的矩形框,這些矩形框包含了不同的寬高比,它們用來匹配真實物體的矩形框。
預測矩形框:每個特征映射圖的位置包含了不同大小的先驗框,然后用預測卷積層對特征映射進行轉換,輸出每個位置的預測矩形框,預測矩形框包含了框的位置和物體的檢測分數(shù)。比較預測矩形框和真實物體的矩形框,輸出最佳的預測矩形框。
損失函數(shù):我們知道了預測的矩形框和真實物體的矩形框,如何計算兩者的損失函數(shù)?
損失函數(shù)包含了位置損失函數(shù)和分類損失函數(shù),由于大部分矩形框只包含了背景,背景的位置不需要定位,因此計算兩者的位置損失函數(shù)用L1函數(shù)即可。我們把背景稱為負類,包含了物體的矩形框稱為正類,不難理解圖像中大部分的矩形框只包含了負類,若用全部的負類和正類來計算損失函數(shù),那么訓練出來的模型偏向于給出負類的結果。解決辦法是在計算分類損失函數(shù)時,我們只選擇最難檢測的幾個負類和全部正類來計算。
非極大值抑制(Non-maximum?Suppression):若兩個矩形框都包含了相同的物體,且兩個矩形框的重疊度較高,則選擇分數(shù)較高的矩形框,刪除分數(shù)較低的矩形框。
SSD網(wǎng)絡包含了基礎網(wǎng)絡,輔助卷積層和預測卷積層:
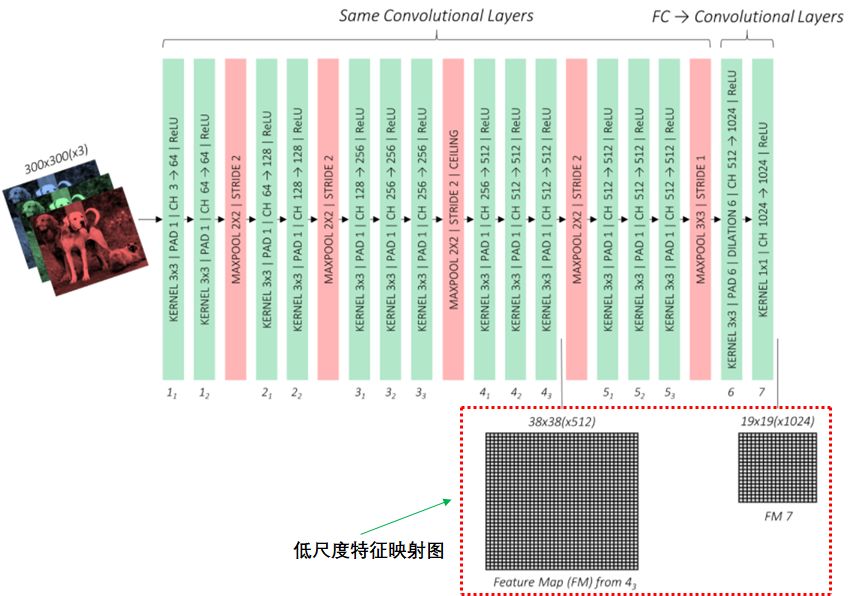
基礎網(wǎng)絡:提取低尺度的特征映射圖
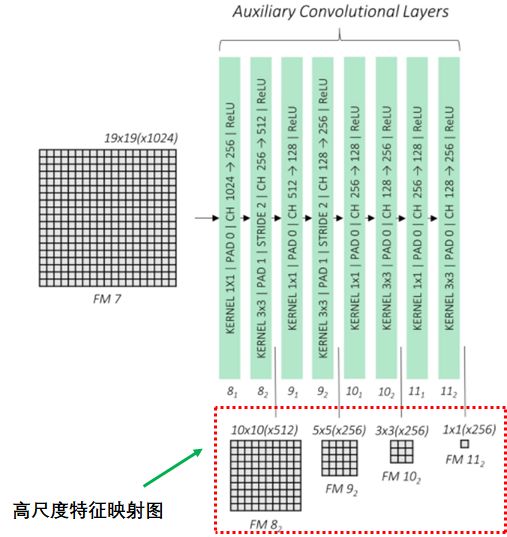
輔助卷積層:提取高尺度的特征映射圖
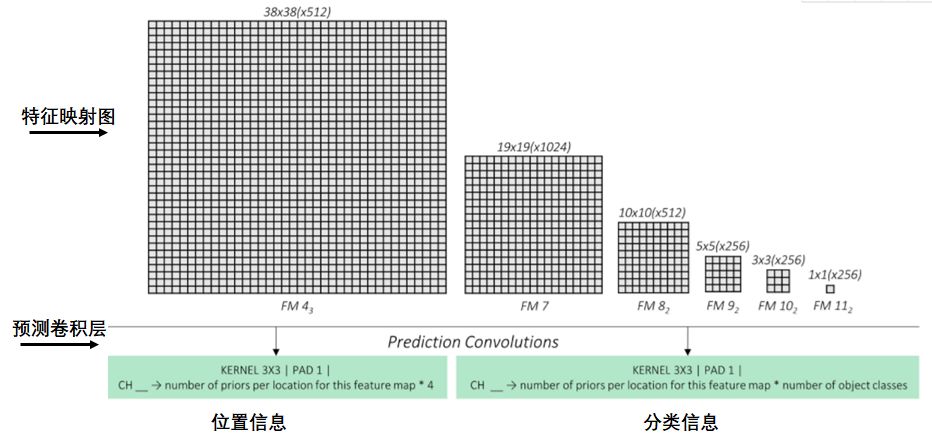
預測卷積層:輸出特征映射圖的位置信息和分類信息
下面介紹SSD網(wǎng)絡的這三個部分
基礎網(wǎng)絡
基礎網(wǎng)絡的結構采用了VCG-16網(wǎng)絡架構,VCG-16網(wǎng)絡如下圖:
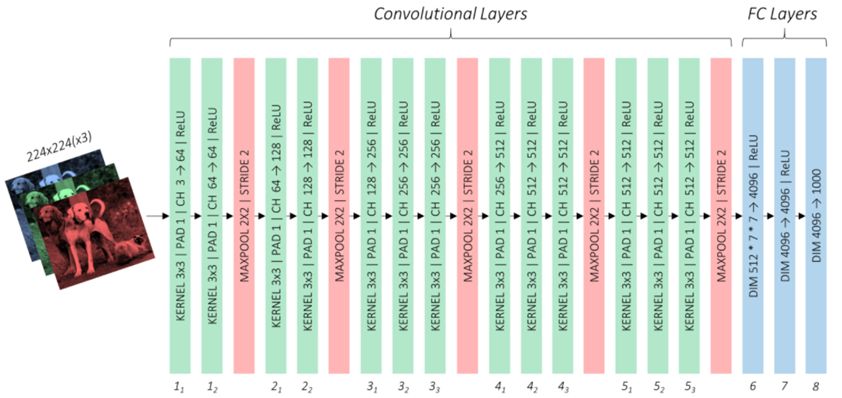
VCG-16網(wǎng)絡包含了卷積層和全連接層(FC Layers),全連接層的任務用來分類,由于基礎網(wǎng)絡只需要提取特征映射圖,因此需要對全連接層用卷積層代替,這一部分的參數(shù)和VCG-16網(wǎng)絡的卷積層參數(shù)用遷移學習的方法獲取。
基于VCG網(wǎng)絡架構的基礎網(wǎng)絡如下圖:
輔助卷積層
輔助卷積層連接基礎網(wǎng)絡最后的特征映射圖,通過卷積神經(jīng)網(wǎng)絡輸出4個高尺度的特征映射圖:
預測卷積層
預測卷積層預測特征映射圖每個點的矩形框信息和所屬類信息,如下圖:
如何表示矩形框
我們用矩形框定位物體的位置信息和所屬類,如下圖:

常用四個維度表示矩形框信息,前兩個維度表示矩形框的中心點的位置,后兩個維度表示矩形的寬度和高度。為了統(tǒng)一,我們使用歸一化的方法表示矩形框:

上圖貓的矩形框為:(0.78,0.80,0.24,0.30)
如何衡量兩個矩形框的重疊度
SSD算法中有兩處需要計算矩形框的重疊度,第一處是計算先驗矩形框和真實矩形框的重疊度,目的是根據(jù)重疊度確定先驗框所屬的類,包括背景類;第二處是計算預測矩形框和真實矩形框的重疊度,目的是根據(jù)重疊度篩選最優(yōu)的矩形框。
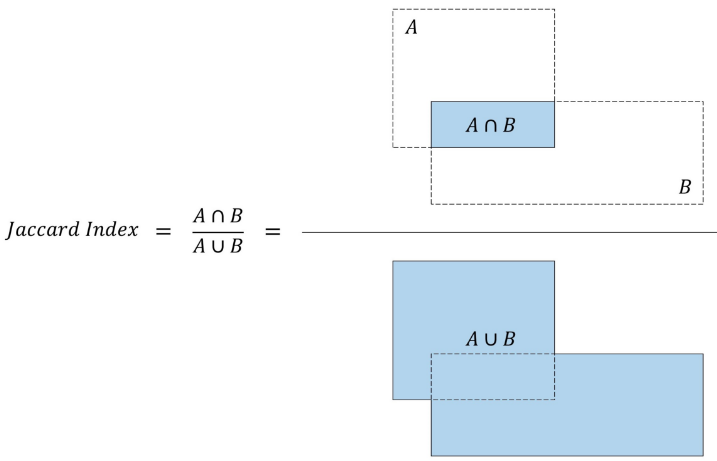
我們用Jaccard Index或交并比(IoU)衡量矩形框的重疊度。
交并比等于兩個矩形框交集的面積與矩形框并集的面積之比,如下圖:
損失函數(shù)算法
預測層預測了映射圖每個點的矩形框信息和分類信息,該點的損失值等于矩形框位置的損失與分類的損失之和。
首先我們計算映射圖每個點的先驗框與真實框的交并比,若交并比大于設置的閾值,則該先驗框與真實框所標記的類相同,稱為正類;若小于設置的閾值,則認為該先驗框標記的類是背景,稱為負類。
然后預測層輸出了映射圖每個點的預測框,預測框的標記與先驗框的標記相同。
預測框與真實框的損失函數(shù)等于預測框位置的損失與分類的損失之和。
1. 預測框位置的損失:
由于不需要用矩形框定位背景類,所以只計算預測正類矩形框與真實矩形框的位置損失:
我們用 nn.L1Loss函數(shù)計算矩形框位置的損失。
n1.L1Loss函數(shù):
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
公式:
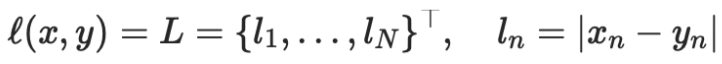
其中N表示樣本個數(shù)。
如果reduction不為'none'(默認設為'mean'),則
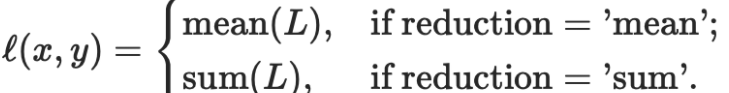
假設共有N個正類的預測矩形框,每個矩形框的位置為
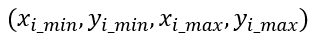
其中 i = 1,2,...,N
每個預測矩形框對應的正類真實矩形框的位置為:
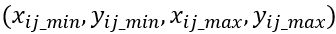
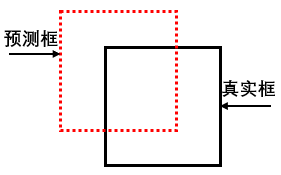
如下圖的預測矩形框和對應的正類真實矩形框:
損失函數(shù)為:
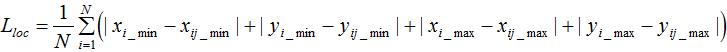
2.預測類的損失:
由第一節(jié)的損失函數(shù)介紹可知,大部分的預測矩形框包含了負類(背景類),容易知道一張圖中負類的個數(shù)遠遠多于正類,若我們計算所有類的損失值,那么訓練出來的模型會偏向于預測負類的結果。
因此我們選擇一定數(shù)量的負類個數(shù)和全部的正類個數(shù)來訓練模型,負類個數(shù)N_hn,正類個數(shù)N_p,負類個數(shù)與正類個數(shù)滿足下式:
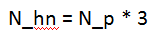
我們知道了負類個數(shù),如何從數(shù)量龐大的負類中選擇所需要的負類個數(shù)?本文采用了最難檢測到負類的預測框作為訓練的負類,稱為Hard Negative Mining。
現(xiàn)在我們知道了如何選擇負類,那么如何預測分類損失函數(shù)?關于多分類任務,我們常用交叉熵來評價分類損失函數(shù)。
若預測的類個數(shù)為K(包含了背景類),交叉熵公式如下:
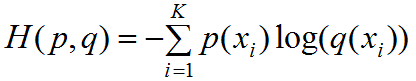
其中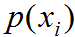 為真實類屬于第 i 類概率,若屬于第?i ?類則
為真實類屬于第 i 類概率,若屬于第?i ?類則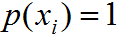
;若不滿足則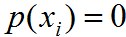 。
。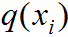 為預測類屬于第i類的概率,每個先驗框的預測類是一個1行K列的矩陣。
為預測類屬于第i類的概率,每個先驗框的預測類是一個1行K列的矩陣。
若交叉熵損失函數(shù)為CE Loss,預測類的損失為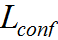 ,有:
,有:
?
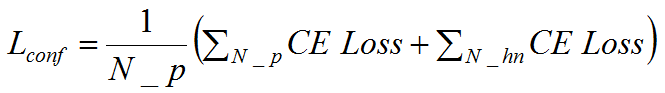
?
其中N_P和N_hn分別為正類、負類個數(shù)。
?
總損失函數(shù)為預測類損失和預測位置損失之和,記為L,有:
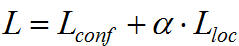
α常設置為1,或者也可作為待學習的參,SSD論文中設置α等于1。
前面介紹通過先驗框和真實框的交并比來分類,若交并比大于閾值則為正類(包含某個特定物體的類),若交并比小于閾值則為負類(背景類)。
?
預測框與先驗框的個數(shù)相等,若有多個相同正類的預測框的交并比很大(如下圖),如何選擇最優(yōu)的預測框?

上圖的五個預測框預測了三只狗和兩只貓,三只狗的交并比如下表:
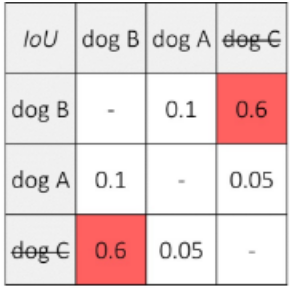
設置閾值為0.5,因為預測dog B的分數(shù)最大(0.96),且dog B和dog C的交并比大于閾值,因此一致dog C的預測框。由于dog A與其他預測框的交并比小于閾值,因此保留dog A的預測框。即狗的輸出結果為兩個。
貓的預測矩形框如下表:
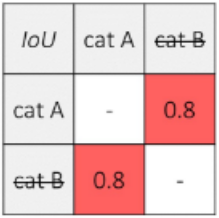
同理,由于cat A的預測分數(shù)最高,且cat B與cat A交并比大于閾值,因此抑制cat B預測框。
上述方法稱為非極大值抑制(Non-Maximum Suppression)。
根據(jù)非極大值抑制方法,貓狗的預測框如下圖:

介紹了SSD網(wǎng)絡結構以及理解該網(wǎng)絡所需要的基礎概念,基于這些知識,下面介紹SSD網(wǎng)絡的算法流程。
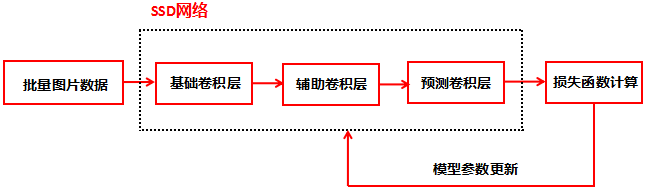
訓練階段:
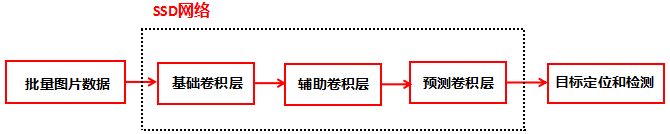
預測階段
本文介紹了SSD算法框架及原理,由于算法細節(jié)較多以及篇幅的關系,小編選擇了幾個非常重要且設計很巧妙的細節(jié)進行介紹,更詳細內容的鏈接https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Object-Detection,對于英文不好的同學,可參考該文幫助理解,若有不懂歡迎交流。
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關微信群。請勿在群內發(fā)送廣告,否則會請出群,謝謝理解~