
【機器學習】機器學習中缺失值處理方法大全(附代碼)
今天我們來看看數(shù)據(jù)預處理中一個有趣的問題:數(shù)據(jù)清理中,如何處理缺失值。在我們探討問題之前,我們一起回顧一些基本術(shù)語,幫助我們了解為什么需要關(guān)注缺失值。
目錄
數(shù)據(jù)清洗簡介 填補缺失值的重要性 缺失值導致的問題 缺失數(shù)據(jù)類型 如何處理數(shù)據(jù)集中缺失的數(shù)據(jù)

數(shù)據(jù)清洗

數(shù)據(jù)預處理中的數(shù)據(jù)清洗與機器學習方法、深度學習架構(gòu)或數(shù)據(jù)科學領(lǐng)域的任何其他復雜方法無關(guān)。我們有數(shù)據(jù)收集、數(shù)據(jù)預處理、建模(機器學習、計算機視覺、深度學習或任何其他復雜方法)、評估,以及最后的模型部署等等。因此數(shù)據(jù)處理建模技術(shù)是一個非常大熱門話題,但數(shù)據(jù)預處理有很多工作等著我們?nèi)ネ瓿伞?/p>
在數(shù)據(jù)分析與挖掘過程中,會熟悉這個比例:60:40 ,這意味著 60% 的工作與數(shù)據(jù)預處理有關(guān),有時這個比例會高至80%以上。
在這篇文章中,我們將一起學習數(shù)據(jù)預處理模塊中的數(shù)據(jù)清洗。即從數(shù)據(jù)集中糾正或消除不準確、損壞、格式錯誤、重復或不完整的數(shù)據(jù)的做法稱為數(shù)據(jù)清理。
填補缺失值的重要性
為了有效地管理數(shù)據(jù),理解缺失值的概念很重要。如果數(shù)據(jù)工作者沒有正確處理缺失的數(shù)字,他或她可能會對數(shù)據(jù)得出錯誤的結(jié)論,這將對建模階段產(chǎn)生重大影響。這是數(shù)據(jù)分析中的一個重要問題,因為它會影響結(jié)果。在分析數(shù)據(jù)過程,當我們發(fā)現(xiàn)有一個或多個特征數(shù)據(jù)缺失時,此時就很難完全理解或相信由此所得到的結(jié)論或建立的模型。數(shù)據(jù)中的缺失值可能會降低研究對象的統(tǒng)計能力,甚至由于估計的偏差而導致錯誤的結(jié)果。
缺失值導致的問題
在缺乏證據(jù)的情況下,統(tǒng)計能力,即檢驗在零假設(shè)錯誤時拒絕該零假設(shè)的幾率會降低。 數(shù)據(jù)的丟失可能導致參數(shù)估計出現(xiàn)偏差。 具有降低樣本代表性的能力。 這可能會使研究分析更具挑戰(zhàn)性。
缺失數(shù)據(jù)類型
根據(jù)數(shù)據(jù)集或數(shù)據(jù)中不存在的模式或數(shù)據(jù),可以將其分類。
完全隨機缺失(MCAR)
當丟失數(shù)據(jù)的概率與要獲得的精確值或觀察到的答案的集合無關(guān)時。隨機缺失(MAR)
當丟失響應的概率由觀察到的響應的集合而不是預期達到的精確缺失值決定時。非隨機缺失(MNAR)
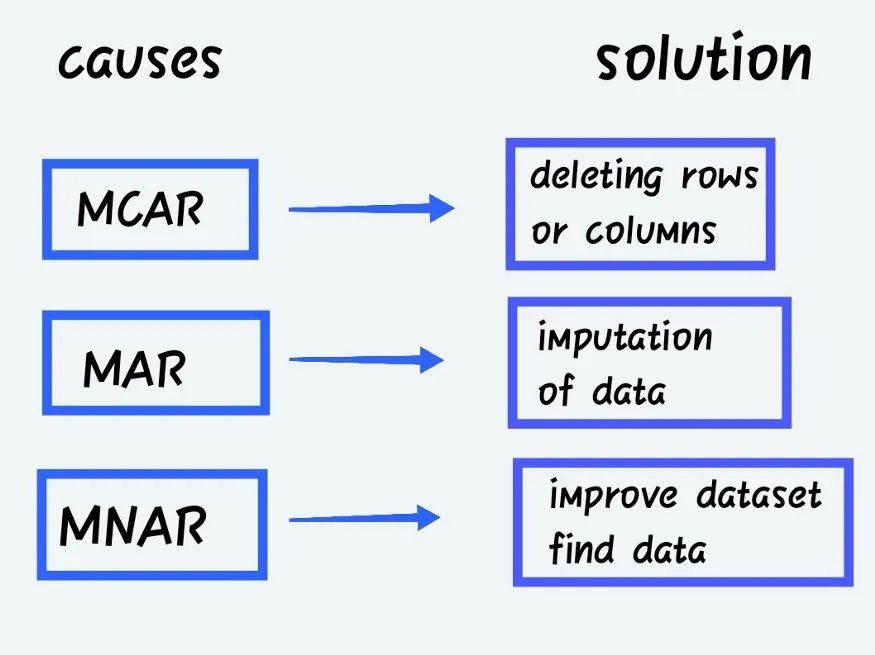
除了上述類別之外,MNAR 是缺失數(shù)據(jù)。MNAR 數(shù)據(jù)案例很難處理。在這種情況下,對缺失數(shù)據(jù)進行建模是獲得參數(shù)的公平近似值的唯一方法。
缺失值的類別
具有缺失值的列分為以下幾類:
連續(xù)變量或特征 — — 數(shù)值數(shù)據(jù)集,即數(shù)字可以是任何類型 分類變量或特征 — — 它可以是數(shù)值的或客觀的類型。
例如:
客戶評分 -- 差、滿意、好、更好、最好
或性別 -- 男性或女性。
缺失值插補類型
插補有多種大小和形式。這是在為我們的應用程序建模以提高精度之前解決數(shù)據(jù)集中缺失數(shù)據(jù)問題的方法之一。
單變量插補或均值插補是指僅使用目標變量對值進行插補。 多元插補: 根據(jù)其他因素插補值,例如使用線性回歸根據(jù)其他變量估計缺失值。 單一插補: 要構(gòu)建單個插補數(shù)據(jù)集,只需在數(shù)據(jù)集中插補一次缺失值。 大量插補: 在數(shù)據(jù)集中多次插補相同的缺失值。這本質(zhì)上需要重復單個插補以獲得大量插補數(shù)據(jù)集。
如何處理數(shù)據(jù)集中缺失的數(shù)據(jù)
有很多方法可以處理缺失的數(shù)據(jù)。首先導入我們需要的庫。
#?導入庫
import?pandas?as?pd
import?numpy?as?np
dataset?=?pd.read_csv("SalaryGender.csv",sep='\t')
#?然后我們需要導入數(shù)據(jù)集,
dataset.head()
檢查數(shù)據(jù)集的維度
dataset.shape
檢查缺失值
print(dataset.isnull().sum())
Salary 0
Gender 0
Age 0
PhD 0
dtype: int64
01 不作任何處理
不對丟失的數(shù)據(jù)做任何事情。一方面,有一些算法有處理缺失值的能力,此時我們可以將完全控制權(quán)交給算法來控制它如何響應數(shù)據(jù)。另一方面,各種算法對缺失數(shù)據(jù)的反應不同。例如,一些算法基于訓練損失減少來確定缺失數(shù)據(jù)的最佳插補值。以 XGBoost 為例。但在某些情況下算法也會出現(xiàn)錯誤,例如線性回歸,此時意味著我們必須在數(shù)據(jù)預處理階段或模型失敗時處理數(shù)據(jù)缺失值,我們必須弄清楚出了什么問題。
實際工作中,我們需要根據(jù)實際情況具體分析,這里為了演示缺失值的處理方法,我們運用試錯法,根據(jù)結(jié)果反推缺失值的處理方法。
#?帶有缺失值的舊數(shù)據(jù)集
dataset["Age"][:10]
0 47
1 65
2 56
3 23
4 53
5 27
6 53
7 30
8 44
9 63
Name: Age, dtype: int64
02 不使用時將其刪除(主要是 Rows)
排除具有缺失數(shù)據(jù)的記錄是一個最簡單的方法。但可能會因此而丟失一些關(guān)鍵數(shù)據(jù)點。我們可以通過使用 Python pandas 包的 dropna() 函數(shù)刪除所有缺失值的列來完成此操作。與其消除所有列中的所有缺失值,不如利用領(lǐng)域知識或?qū)で箢I(lǐng)域?qū)<业膸椭鷣碛羞x擇地刪除具有與機器學習問題無關(guān)的缺失值的行/列。
優(yōu)點: 刪除丟失的數(shù)據(jù)后,模型的魯棒性將會變得更好。 缺點: 有用的數(shù)據(jù)丟失,不能小看了這點,這也可能很重要。但如果數(shù)據(jù)集中缺失值很多,將會嚴重影響建模效率。
#deleting?行?-?錯過的值
dataset.dropna(inplace=True)
print(dataset.isnull().sum())
Salary 0
Gender 0
Age 0
PhD 0
dtype: int64
03 均值插補
使用這種方法,可以先計算列的非缺失值的均值,然后分別替換每列中的缺失值,并獨立于其他列。最大的缺點是它只能用于數(shù)值數(shù)據(jù)。這是一種簡單快速的方法,適用于小型數(shù)值數(shù)據(jù)集。但是,存在例如忽略特征相關(guān)性的事實的限制等。每次填補僅適用于其中某一獨立的列。
此外,如果跳過離群值處理,幾乎肯定會替換一個傾斜的平均值,從而降低模型的整體質(zhì)量。
缺點: 只適用于數(shù)值數(shù)據(jù)集,不能在獨立變量之間的協(xié)方差
#Mean?-?缺失值
dataset["Age"]?=?dataset["Age"].replace(np.NaN,?dataset["Age"].mean())
print(dataset["Age"][:10])
0 47
1 65
2 56
3 23
4 53
5 27
6 53
7 30
8 44
9 63
Name: Age, dtype: int64
04 中位數(shù)插補
解決上述方法中的異常值問題的另一種插補技術(shù)是利用中值。排序時,它會忽略異常值的影響并更新該列中出現(xiàn)的中間值。
缺點: 只適用于數(shù)值數(shù)據(jù)集,不能在獨立變量之間的協(xié)方差
#Median?-?缺失值
dataset["Age"]?=?dataset["Age"].replace(np.NaN,?dataset["Age"].median())
print(dataset["Age"][:10])
05 眾數(shù)插補
這種方法可應用于具有有限值集的分類變量。有些時候,可以使用最常用的值來填補缺失值。
例如,可用的選項是名義類別值(例如 True/False)還是條件(例如正常/異常)。對于諸如受教育程度之類的序數(shù)分類因素尤其如此。學前、小學、中學、高中、畢業(yè)等等都是教育水平的例子。不幸的是,由于這種方法忽略了特征連接,存在數(shù)據(jù)偏差的危險。如果類別值不平衡,則更有可能在數(shù)據(jù)中引入偏差(類別不平衡問題)。
優(yōu)點: 適用于所有格式的數(shù)據(jù)。 缺點: 無法預測獨立特征之間的協(xié)方差值。
#Mode?-?缺失值
import?statistics
dataset["Age"]?=?dataset["Age"].replace(np.NaN,?statistics.mode(dataset["Age"]))
print(dataset["Age"][:10])
06 分類值的插補
當分類列有缺失值時,可以使用最常用的類別來填補空白。如果有很多缺失值,可以創(chuàng)建一個新類別來替換它們。
優(yōu)點:?適用于小數(shù)據(jù)集。通過插入新類別來彌補損失 缺點:?不能用于除分類數(shù)據(jù)之外的其他數(shù)據(jù),額外的編碼特征可能會導致精度下降
dataset.isnull().sum()
#?確實值?-?分類?-?解決方案
dataset["PhD"]?=?dataset["PhD"].fillna('U')
#?檢查分類中的缺失值?-?機艙
dataset.isnull().sum()
07 前一次觀測結(jié)果(LOCF)
這是一種常見的統(tǒng)計方法,用于分析縱向重復測量數(shù)據(jù)時,一些后續(xù)觀察缺失。
#LOCF?-?前一次觀測結(jié)果
dataset["Age"]?=?dataset["Age"].fillna(method?='ffill')
dataset.isnull().sum()
08 線性插值
這是一種近似于缺失值的方法,沿著直線將點按遞增順序連接起來。簡而言之,它以與在它之前出現(xiàn)的值相同的升序計算未知值。因為線性插值是默認的方法,我們不需要在使用它的時候指定它。這種方法常用于時間序列數(shù)據(jù)集。
#interpolation?-?線性
dataset["Age"]?=?dataset["Age"].interpolate(method='linear',?limit_direction='forward',?axis=0)
dataset.isnull().sum()
09 KNN 插補
一種基本的分類方法是 k 最近鄰 (kNN) 算法。類成員是 k-NN 分類的結(jié)果。
項目的分類取決于它與訓練集中的點的相似程度,該對象將進入其 k 個最近鄰中成員最多的類。如果 k = 1,則該項目被簡單地分配給該項目最近鄰居的類。使用缺失數(shù)據(jù)找到與觀測值最近的 k 鄰域,然后根據(jù)鄰域中的非缺失值對它們進行插補可能有助于生成關(guān)于缺失值的預測。
#?for?knn?imputation?-?我們需要移除歸一化數(shù)據(jù)和我們需要轉(zhuǎn)換的分類數(shù)據(jù)
cat_variables?=?dataset[['PhD']]
cat_dummies?=?pd.get_dummies(cat_variables,?drop_first=True)
cat_dummies.head()
dataset?=?dataset.drop(['PhD'],?axis=1)
dataset?=?pd.concat([dataset,?cat_dummies],?axis=1)
dataset.head()
#?刪除不需要的功能
dataset?=?dataset.drop(['Gender'],?axis=1)
dataset.head()
#?scaling?在?knn?之前是強制性的
from?sklearn.preprocessing?import?MinMaxScaler
scaler?=?MinMaxScaler()
dataset?=?pd.DataFrame(scaler.fit_transform(dataset),?columns?=?dataset.columns)
dataset.head()
#?knn?插值
from?sklearn.impute?import?KNNImputer
imputer?=?KNNImputer(n_neighbors=3)
dataset?=?pd.DataFrame(imputer.fit_transform(dataset),columns?=?dataset.columns)
#檢查是否丟失
dataset.isnull().sum()
10 由鏈式方程 (MICE) 進行多元插補的插補
MICE 是一種通過多重插補替換數(shù)據(jù)收集中缺失數(shù)據(jù)值的方法。可以首先制作一個或多個變量中缺失值的數(shù)據(jù)集的重復副本。
#MICE
import?numpy?as?np?
import?pandas?as?pd
from?sklearn.experimental?import?enable_iterative_imputer
from?sklearn.impute?import?IterativeImputer
df?=?pd.read_csv('https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv')
df?=?df.drop(['PassengerId','Name'],axis=1)
df?=?df[["Survived",?"Pclass",?"Sex",?"SibSp",?"Parch",?"Fare",?"Age"]]
df["Sex"]?=?[1?if?x=="male"?else?0?for?x?in?df["Sex"]]
df.isnull().sum()
imputer=IterativeImputer(imputation_order='ascending',max_iter=10,random_state=42,n_nearest_features=5)
imputed_dataset?=?imputer.fit_transform(df)寫作最后
對于我們的數(shù)據(jù)集,我們可以使用上述想法來解決缺失值。處理缺失值的方法取決于我們的特征中的缺失值和我們需要應用的模型。因此,我們可以通過實錯的方法來確定模型的最佳選擇。
如果你對缺失值的查看感興趣,我想你推薦這篇文章,總結(jié)了數(shù)據(jù)分析過程中非常常用的缺失值分析方法。缺失值處理,你真的會了嗎?
往期精彩回顧