
實(shí)踐教程 | Evo-ViT:高性能Transformer加速方法

作者 | 沁園夏@知乎(已授權(quán))
來源 | https://zhuanlan.zhihu.com/p/397939585
編輯 | 極市平臺
極市導(dǎo)讀
本文提出了一種新式的Transformer加速算法:Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer,該算法能夠在保證分類準(zhǔn)確率損失較小的情況下,大幅提升Transformer的推理速度。 >>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿

論文地址:
https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2108.01390
前言
Transformer基礎(chǔ)網(wǎng)絡(luò)的高效性設(shè)計(jì)問題隨著Transformer在計(jì)算機(jī)視覺領(lǐng)域的蓬勃發(fā)展逐漸受到國內(nèi)外眾多學(xué)術(shù)機(jī)構(gòu)和企業(yè)的關(guān)注。本文提出了一種新式的Transformer加速算法:Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer,該算法能夠在保證分類準(zhǔn)確率損失較小的情況下,大幅提升Transformer的推理速度,如在ImageNet 1K數(shù)據(jù)集下,Evo-ViT可以提升DeiT-S 60%推理速度的同時(shí)僅僅損失0.4%的精度。
研究意義與背景
最近,Vision Transformer 及其變體在各種計(jì)算機(jī)視覺任務(wù)中顯示出巨大的潛力。通過自注意力機(jī)制捕獲短程和長程視覺依賴的能力是其成功的主要來源。但是長程感受野同樣帶來了巨大的計(jì)算開銷,特別是對于高分辨率視覺任務(wù)(例如,目標(biāo)檢測、分割)。研究者們開始研究如何在盡量保持原有模型準(zhǔn)確率的前提下,降低模型計(jì)算復(fù)雜度,從而使得視覺 Transformer成為一種更加通用、高效、低廉的解決框架。
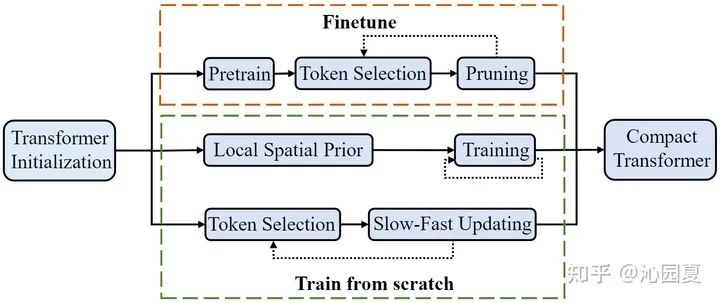
目前,主流的Transformer高效設(shè)計(jì)方案包括兩種:一種是借助結(jié)構(gòu)化的空間先驗(yàn),如PiT[2],LeViT[6]等利用空間下采樣構(gòu)造金字塔型模型,再例如PVT[1],Swin Transformer[9]等利用圖像局部先驗(yàn)構(gòu)造稀疏化的自注意力模塊;另一種是進(jìn)行非結(jié)構(gòu)化的網(wǎng)絡(luò)裁剪,例如DynamicViT[3]、PS-ViT[4],基于預(yù)訓(xùn)練好的模型,分析該模型的冗余性,對模型進(jìn)行空間token或者特征通道的裁剪。然而,非結(jié)構(gòu)化的裁剪會破化模型內(nèi)部特征的空間結(jié)構(gòu),使得這兩種方法無法相輔相成。
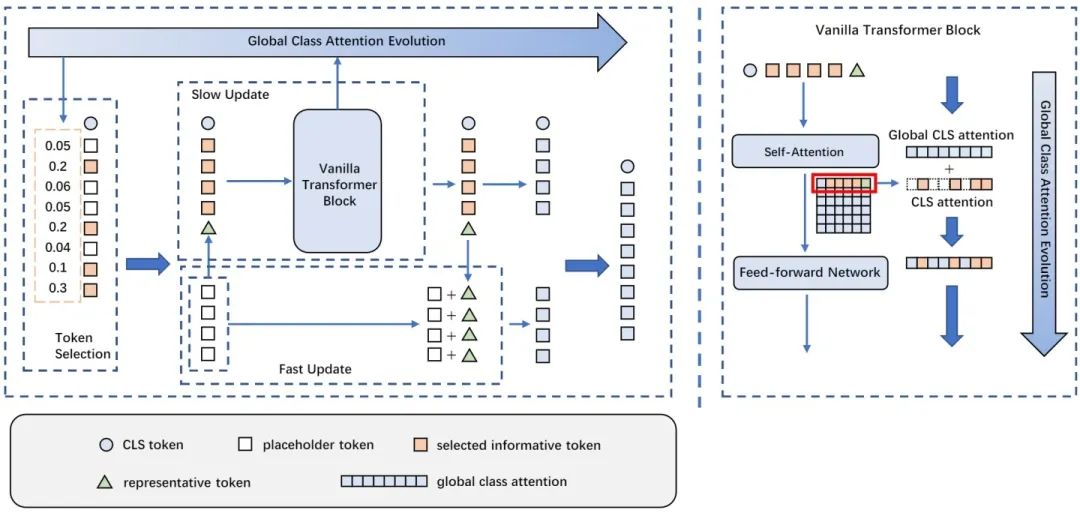
如圖1第三個(gè)分支,相比直接將信息量低的token裁剪掉,此次工作中提出一種新的即插即用的token雙流更新策略,能在模型訓(xùn)練的同時(shí)動(dòng)態(tài)判斷非結(jié)構(gòu)性的token冗余及低信息分布,從而高效更新低信息token、精細(xì)更新高信息token,實(shí)現(xiàn)模型的高效準(zhǔn)確建模,并保留了完整的空間結(jié)構(gòu)。因此,該工作所提出的Evo-ViT方法可以同時(shí)適用于直筒型和金字塔型Transformer結(jié)構(gòu)。
技術(shù)創(chuàng)新
與現(xiàn)有的Transformer高效設(shè)計(jì)方案相比,Evo-ViT是即插即用的加速策略,既適用于直筒型結(jié)構(gòu),也適用于金字塔型結(jié)構(gòu)的視覺Transformer,不破壞原有模型的結(jié)構(gòu)化設(shè)計(jì);同時(shí),Evo-ViT是在模型訓(xùn)練過程中動(dòng)態(tài)發(fā)掘冗余與低效信息,無需預(yù)訓(xùn)練模型,因此能同時(shí)提升模型的訓(xùn)練和推斷效率。方法主要兩點(diǎn)創(chuàng)新:
提出了結(jié)構(gòu)保留的token選擇策略,通過分析全局class attention,來動(dòng)態(tài)區(qū)分高信息token和低信息token,并保留低信息token來確保完整的信息流;
提出了雙流token更新策略,對高信息token及低信息token的歸納進(jìn)行精細(xì)更新,然后用歸納token對低信息token進(jìn)行高效更新,從而在不改變網(wǎng)絡(luò)結(jié)構(gòu)的情況下,大幅提升模型性能。
技術(shù)細(xì)節(jié)
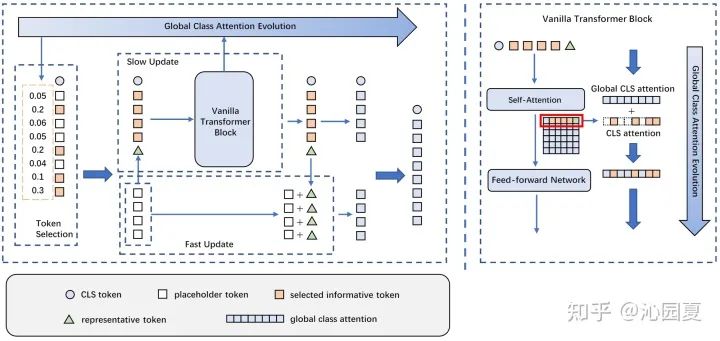
圖2 介紹了Evo-ViT的具體框架設(shè)計(jì),包括基于全局class attention的token選擇以及慢速-快速雙流token更新兩個(gè)模塊。其根據(jù)全局class attention的排序判斷高信息token和低信息token,將低信息token整合為一個(gè)歸納token,和高信息token一起輸入到原始多頭注意力(Multi-head Self-Attention, MSA)模塊以及前向傳播(Fast Fed-forward Network, FFN)模塊中進(jìn)行精細(xì)更新。更新后的歸納token用來快速更新低信息token。全局class attention也在精細(xì)更新過程中進(jìn)行同步更新變化。
實(shí)驗(yàn)結(jié)果
為了驗(yàn)證方法的有效性,Evo-ViT基于直筒型Transformer結(jié)構(gòu)DeiT[5]、金字塔型結(jié)構(gòu)LeViT[6],在主流Benchmark ImageNet-1k上進(jìn)行對比實(shí)驗(yàn)。
圖3是Evo-ViT和現(xiàn)有token相關(guān)高效性設(shè)計(jì)方法的對比,包括PS-ViT[4]、DynamicViT[3]、SViTE[7]、IA-RED2[8]。實(shí)驗(yàn)結(jié)果表明,其在確保準(zhǔn)確率的同時(shí),能夠有更高的吞吐量提升,性能優(yōu)化的表現(xiàn)更佳。
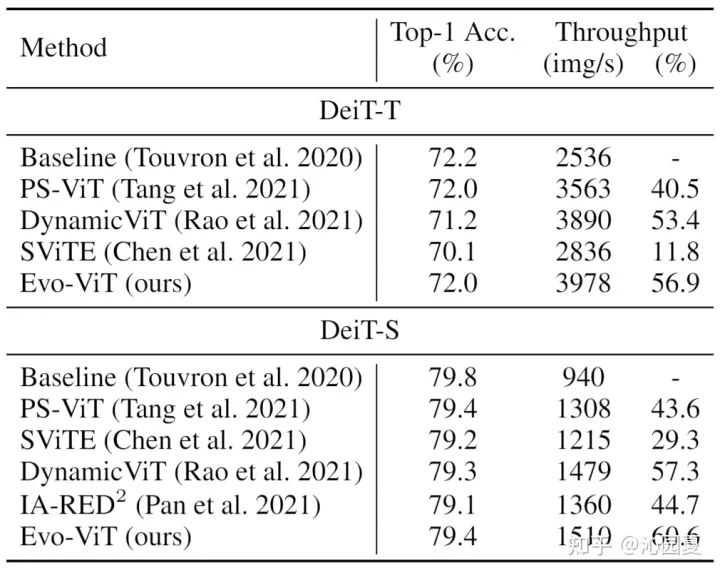
圖4為Evo-ViT在金字塔型結(jié)構(gòu)上的驗(yàn)證實(shí)驗(yàn)。由于以往直接裁剪的方法均無法直接用于具有空間先驗(yàn)的金字塔型結(jié)構(gòu),Evo-ViT只和目前SOTA的金字塔型Transformer進(jìn)行了比較。

該工作還進(jìn)一步可視化了其token選擇結(jié)果,如圖5所示。左邊部分為訓(xùn)練好的完整模型在各層的token選擇結(jié)果,右邊部分為訓(xùn)練過程中不同階段的token選擇結(jié)果。可以發(fā)現(xiàn),訓(xùn)練好的模型各層選擇基本趨于一致,這是因?yàn)槟P蛢A向于用更多的資源更新高信息量的token,即讓高信息量token通過所有層的精細(xì)更新。同時(shí),由于文章提出的保持結(jié)構(gòu)的雙流更新策略,可以發(fā)現(xiàn)一些淺層被誤判的token在深層也可以被撿回來,如第四行的棒球圖片,在前層時(shí)棒球桿被誤判為低信息量token,但是在深層全部被撿了回來。進(jìn)一步觀察右邊部分,可以發(fā)現(xiàn)隨著訓(xùn)練的深入token選擇效果逐漸趨于最優(yōu)。

結(jié)論
本文提出了一種基于慢速-快速雙流更新思想的通用視覺Transformer加速方法,Evo-ViT。不同于以往的方法,本文通過給高信息量token和低信息量token分配不同的計(jì)算優(yōu)先級,使得加速模型的同時(shí)保留了內(nèi)部特征的空間結(jié)構(gòu),同時(shí)適用于直筒型和金字塔型Transformer。實(shí)驗(yàn)表明Evo-ViT可以對模型進(jìn)行有效的加速。
從可視化結(jié)果可以看出,本文所提出的方法可以使模型更關(guān)注于圖像的核心區(qū)域,這對于模型的可解釋性,以及需要利用高層語義的任務(wù)有潛在的幫助。如何將本文的方法用于更多下游任務(wù),如檢測、分割,也是一個(gè)有趣的方向。
以上即Evo-ViT的基本介紹,更多細(xì)節(jié)可見論文。大家有什么想法意見歡迎評論留言~
參考文獻(xiàn)
[1] Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. arXiv:2102.12122
[2] Rethinking spatial dimensions of vision transformers. arXiv preprint arXiv:2103.16302
[3] DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification. arXiv:2106.02034.
[4] Patch Slimming for Efficient Vision Transformers. arXiv:2106.02852
[5] Training data-efficient image transformers & distillation through attention. arXiv:2012.12877.
[6] LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference. arXiv:2104.01136
[7] Chasing Sparsity in Vision Transformers: An End-to-End Exploration. arXiv:2106.04533
[8] IA-RED2: Interpretability-Aware Redundancy Reduction for Vision Transformers. arXiv:2106.12620
[9] Swin transformer: Hierarchical vision transformer using shifted windows. arXiv preprint arXiv:2103.14030.
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“CVPR21檢測”獲取CVPR2021目標(biāo)檢測論文下載~

# CV技術(shù)社群邀請函 #

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測-深圳)
即可申請加入極市目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動(dòng)駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實(shí)項(xiàng)目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動(dòng)交流~
