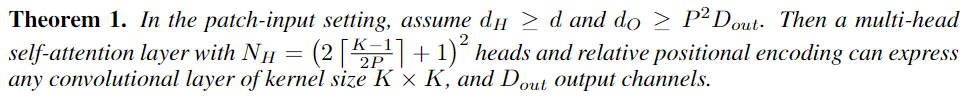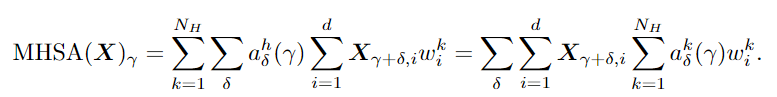來源:新智元? ? ? ? ? ? ?編輯:LRS
【導(dǎo)讀】在Transformer當(dāng)?shù)赖慕裉欤珻NN的光芒逐漸被掩蓋,但Transformer能否完全取代CNN還是一個(gè)未知數(shù)。最近北大聯(lián)合UCLA發(fā)表論文,他們發(fā)現(xiàn)Transformer可以在一定限制條件下模擬CNN,并且提出一個(gè)兩階段訓(xùn)練框架,性能提升了9%。
Visual Transformer(ViT)在計(jì)算機(jī)視覺界可以說是風(fēng)頭無兩,完全不使用卷積神經(jīng)網(wǎng)絡(luò)(CNN) 而只使用自注意力機(jī)制的情況下,還可以在各個(gè)CV任務(wù)上達(dá)到sota。研究結(jié)果也表明,只要有足夠的訓(xùn)練數(shù)據(jù)時(shí),ViT可以顯著地優(yōu)于基于卷積的神經(jīng)網(wǎng)絡(luò)模型。但這并不代表CNN推出了歷史舞臺,ViT在CIFAR-100等小型數(shù)據(jù)集上的表現(xiàn)仍然比CNN差。一個(gè)比較常見的解釋是Transformer更強(qiáng)大的原因在于自注意力機(jī)制獲得了上下文相關(guān)的權(quán)重,而卷積只能捕捉局部特征。然而,目前還沒有證據(jù)證明Transformer是否真的比CNN全方面、嚴(yán)格地好,也就是說,是否CNN的表達(dá)能力完全被Transformer包含?之前有學(xué)者給出了一些他們的答案,實(shí)驗(yàn)表明具有足夠數(shù)量header的自注意力層可以表示卷積,但它們只關(guān)注于注意力層的輸入表示為像素的情況,在輸入序列非常長時(shí)內(nèi)存成本巨大,這是不實(shí)用的。而且在ViT及其大多數(shù)變體中,輸入是非重疊圖像片段(image patch)的表示,而不是像素。卷積操作涉及的像素跨越了patch的邊界,ViT 中的一個(gè)自注意力層是否可以表示卷積仍然是未知的。來自北大、加利福尼亞大學(xué)洛杉磯分校UCLA、微軟的研究人員就這個(gè)問題進(jìn)行了研究并給出了一個(gè)具有證明、肯定的(affirmative)答案:具有相對位置編碼和足夠注意力header的ViT層即使在輸入是圖像補(bǔ)丁的情況下也可以表示任何卷積。https://arxiv.org/abs/2111.01353
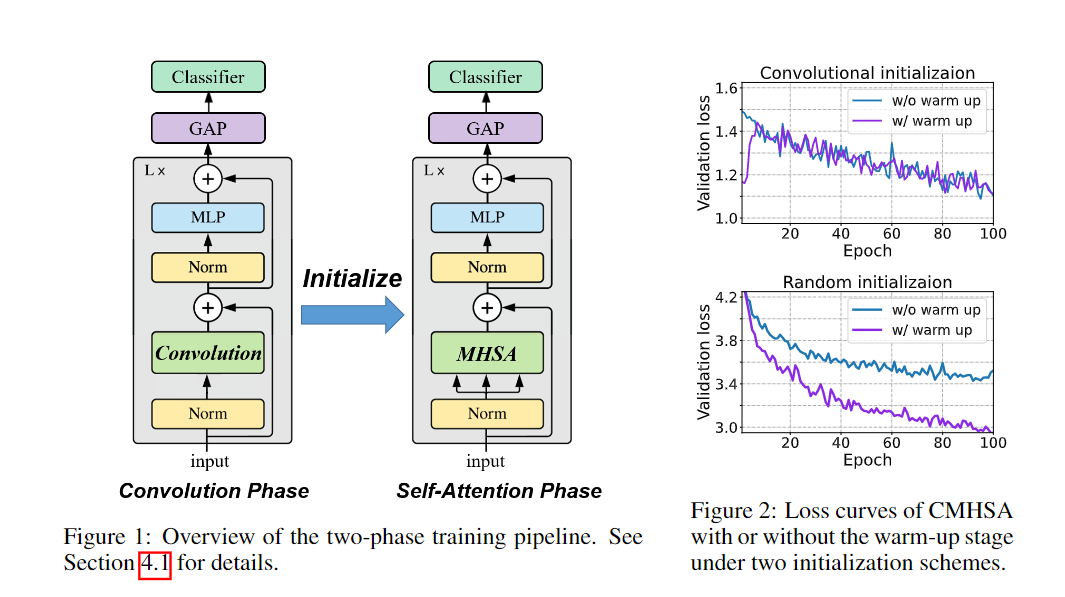
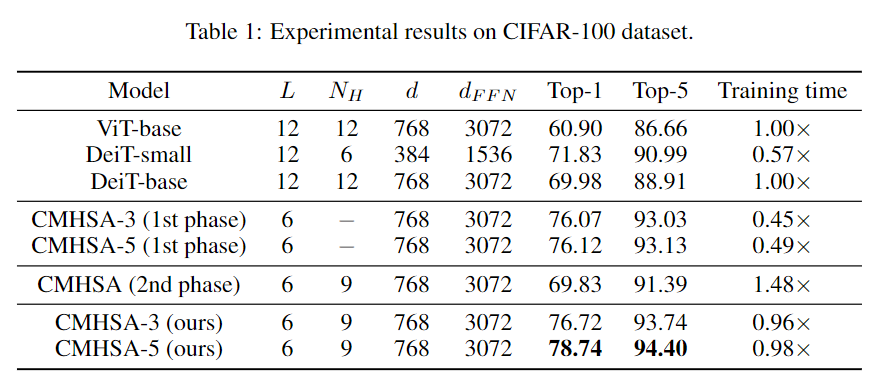
這意味著ViT在小數(shù)據(jù)集上的性能較差,主要是由于它的泛化性能,而不是表達(dá)能力。在理論研究的基礎(chǔ)上,文中提出了一種將卷積偏差引入視覺變換器的兩階段訓(xùn)練pipeline,并在低數(shù)據(jù)環(huán)境下進(jìn)行了實(shí)驗(yàn)驗(yàn)證。要考慮ViT中的MHSA(Multi-head Self-Attention)層來表示卷積的問題,作者主要關(guān)注輸入。圖像patch的輸入給驗(yàn)證這一結(jié)果帶來了很大的困難:卷積運(yùn)算可以在patch邊界像素上運(yùn)行,而Transformer不行。為了解決這一問題,首先需要將來自所有相關(guān)patch的信息聚合起來,通過利用相對位置編碼和多頭機(jī)制計(jì)算卷積,然后對聚合特征進(jìn)行線性投影。通過多頭機(jī)制還原卷積后,另一個(gè)問題是header的數(shù)量是否會影響最優(yōu)解。研究人員給出了MHSA層在像素輸入和patch輸入設(shè)置中表示卷積所需的頭部數(shù)量的較低限制,強(qiáng)調(diào)了多頭機(jī)制的重要性。研究結(jié)果清楚地表明了像素輸入和patch輸入設(shè)置之間的區(qū)別:即patch輸入使自注意力比像素輸入需要更少的頭來進(jìn)行卷積,尤其是當(dāng)k較大時(shí)。例如如果具有像素輸入的mhsa層需要至少25個(gè)header來執(zhí)行5×5卷積,而具有patch輸入的mhsa層只需要9個(gè)header。通常,在ViT中,MHSA層中的頭部數(shù)量很少,例如,VIT-base中只有12個(gè)header,因此理論和現(xiàn)實(shí)互相印證,與實(shí)際情況達(dá)成一致。上述理論結(jié)果提供了一種允許MHSA層表示卷積的結(jié)構(gòu)。研究人員又提出了一個(gè)兩階段的ViT 訓(xùn)練pipeline來進(jìn)行訓(xùn)練。首先訓(xùn)練ViT的卷積變體,其中mhsa層被k×k卷積層取代,也稱之為卷積訓(xùn)練階段。然后將預(yù)訓(xùn)練模型中的權(quán)重轉(zhuǎn)移到一個(gè)Transformer模型中,并在同一數(shù)據(jù)集上繼續(xù)訓(xùn)練模型,稱為自注意力訓(xùn)練階段。pipeline中的一個(gè)非常重要的步驟是從良好訓(xùn)練的卷積層中初始化MHSA層。由于卷積的存在,所以不能使用[cls]標(biāo)記進(jìn)行分類,而需要通過在最后一層的輸出上應(yīng)用全局平均池,然后使用線性分類器來執(zhí)行圖像分類,和CNN圖像分類一樣。從直覺來看,在卷積階段,模型對數(shù)據(jù)進(jìn)行卷積神經(jīng)網(wǎng)絡(luò)學(xué)習(xí),并具有包括局部性和空間不變性在內(nèi)的誘導(dǎo)偏差,使得學(xué)習(xí)更加容易。在自注意階段,該模型從模擬預(yù)先訓(xùn)練的CNN開始,逐漸學(xué)習(xí)到利用CNN的靈活性和強(qiáng)大的自注意表達(dá)能力。在實(shí)驗(yàn)部分,作者將模型命名為CMHSA-K(卷積MHSA),其中K 為第一階段訓(xùn)練中卷積核的大小。選取的模型包括ViT-base (直接用Transformer在圖像上進(jìn)行分類)和DeiT(用數(shù)據(jù)增強(qiáng)和隨機(jī)正則化來提升ViT性能)。可以看到,兩階段訓(xùn)練pipeline基本上提高了性能,也證明了DeiT的兩階段訓(xùn)練策略很有效。此外文中提出的兩階段訓(xùn)練pipeline模型和DeiT的性能有很大差別,例如,CMHSA-5模型的第1名精度比DeiT-base高出近9%,可以看到pipeline可以在低數(shù)據(jù)環(huán)境下的數(shù)據(jù)增強(qiáng)和規(guī)則化技術(shù)上提供進(jìn)一步的性能增益。并且兩個(gè)訓(xùn)練階段都很重要。在相同數(shù)量的訓(xùn)練時(shí)間下,只接受一個(gè)階段訓(xùn)練的CMHSA總是比接受兩個(gè)階段訓(xùn)練的CMHSA表現(xiàn)差。CMHSA(2nd phase)是一個(gè)隨機(jī)初始化的CMHSA,經(jīng)過400個(gè)epoch的訓(xùn)練,其測試精度遠(yuǎn)低于最終兩階段模型。因此,從第一階段轉(zhuǎn)移的卷積偏差(convolutional bias)對于模型獲得良好的性能至關(guān)重要。卷積階段也有助于加速訓(xùn)練。由于MHSA模塊的高計(jì)算復(fù)雜性,Transformer 的訓(xùn)練通常是耗時(shí)的。相比之下,CNNS的訓(xùn)練和推理速度要快得多。在文中提出的訓(xùn)練pipeline中,卷積階段非常快,雖然自注意力階段稍慢,但與DeiT-base 相比,仍然可以用更少的時(shí)間完成400個(gè)訓(xùn)練epoch。最后研究人員指出,由于ViT模型存在一定的限制,目前的方法無法實(shí)現(xiàn)任何ViT模型對CNN的模擬。特別是需要足夠數(shù)量的header(≥9)。對于較小數(shù)量的頭部來說,不存在精確的映射,即使精確映射不適用,如何從CNN正確初始化VIT也值得研究。參考資料:
https://arxiv.org/abs/2111.01353