來源:大數(shù)據(jù)DT(ID:hzdashuju)

大數(shù)據(jù)技術其實是分布式技術在數(shù)據(jù)處理領域的創(chuàng)新性應用,其本質(zhì)和此前講到的分布式技術思路一脈相承,即用更多的計算機組成一個集群,提供更多的計算資源,從而滿足更大的計算壓力要求。
大數(shù)據(jù)技術討論的是,如何利用更多的計算機滿足大規(guī)模的數(shù)據(jù)計算要求。
大數(shù)據(jù)就是將各種數(shù)據(jù)統(tǒng)一收集起來進行計算,發(fā)掘其中的價值。這些數(shù)據(jù),既包括數(shù)據(jù)庫的數(shù)據(jù),也包括日志數(shù)據(jù),還包括專門采集的用戶行為數(shù)據(jù);既包括企業(yè)內(nèi)部自己產(chǎn)生的數(shù)據(jù),也包括從第三方采購的數(shù)據(jù),還包括使用網(wǎng)絡爬蟲獲取的各種互聯(lián)網(wǎng)公開數(shù)據(jù)。
面對如此龐大的數(shù)據(jù),如何存儲、如何利用大規(guī)模的服務器集群處理計算才是大數(shù)據(jù)技術的核心。
01 HDFS分布式文件存儲架構
大規(guī)模的數(shù)據(jù)計算首先要解決的是大規(guī)模數(shù)據(jù)的存儲問題。如何將數(shù)百TB或數(shù)百PB的數(shù)據(jù)存儲起來,通過一個文件系統(tǒng)統(tǒng)一管理,這本身就是一項極大的挑戰(zhàn)。
HDFS的架構,如圖31-1所示。
HDFS可以將數(shù)千臺服務器組成一個統(tǒng)一的文件存儲系統(tǒng),其中NameNode服務器充當文件控制塊的角色,進行文件元數(shù)據(jù)管理,即記錄文件名、訪問權限、數(shù)據(jù)存儲地址等信息,而真正的文件數(shù)據(jù)則存儲在DataNode服務器上。DataNode以塊為單位存儲數(shù)據(jù),所有的塊信息,比如塊ID、塊所在的服務器IP地址等,都記錄在NameNode服務器上,而具體的塊數(shù)據(jù)則存儲在DataNode服務器上。理論上,NameNode可以將所有DataNode服務器上的所有數(shù)據(jù)塊都分配給一個文件,也就是說,一個文件可以使用所有服務器的硬盤存儲空間。此外,HDFS為了保證不會因為硬盤或者服務器損壞而導致文件損壞,還會對數(shù)據(jù)塊進行復制,每個數(shù)據(jù)塊都會存儲在多臺服務器上,甚至多個機架上。02 MapReduce大數(shù)據(jù)計算架構數(shù)據(jù)存儲在HDFS上的最終目標還是為了計算,通過數(shù)據(jù)分析或者機器學習獲得有益的結果。但是如果像傳統(tǒng)的應用程序那樣把HDFS當作普通文件,從文件中讀取數(shù)據(jù)后進行計算,那么對于需要一次計算數(shù)百TB數(shù)據(jù)的大數(shù)據(jù)計算場景,就不知道要算到什么時候了。大數(shù)據(jù)處理的經(jīng)典計算框架是MapReduce。MapReduce的核心思想是對數(shù)據(jù)進行分片計算。既然數(shù)據(jù)是以塊為單位分布存儲在很多臺服務器組成的集群上的,那么能不能就在這些服務器上針對每個數(shù)據(jù)塊進行分布式計算呢?事實上,MapReduce可以在分布式集群的多臺服務器上啟動同一個計算程序,每個服務器上的程序進程都可以讀取本服務器上要處理的數(shù)據(jù)塊進行計算,因此,大量的數(shù)據(jù)就可以同時進行計算了。但是這樣一來,每個數(shù)據(jù)塊的數(shù)據(jù)都是獨立的,如果這些數(shù)據(jù)塊需要進行關聯(lián)計算怎么辦?- 一部分是map過程,每個服務器上會啟動多個map進程,map優(yōu)先讀取本地數(shù)據(jù)進行計算,計算后輸出一個<key, value>集合;
- 另一部分是reduce過程,MapReduce在每個服務器上都會啟動多個reduce進程,然后對所有map輸出的<key, value>集合進行shuffle操作。所謂的shuffle就是將相同的key發(fā)送到同一個reduce進程中,在reduce中完成數(shù)據(jù)關聯(lián)計算。
下面以經(jīng)典的WordCount,即統(tǒng)計所有數(shù)據(jù)中相同單詞的詞頻數(shù)據(jù)為例,來認識map和reduce的處理過程,如圖31-2所示。▲圖31-2 詞頻統(tǒng)計程序WordCount的MapReduce處理過程假設原始數(shù)據(jù)有兩個數(shù)據(jù)塊,MapReduce框架啟動了兩個map進程進行處理,它們分別讀入數(shù)據(jù)。map函數(shù)會對輸入數(shù)據(jù)進行分詞處理,然后針對每個單詞輸出<單詞, 1>這樣的<key, value>結果。然后MapReduce框架進行shuffle操作,相同的key發(fā)送給同一個reduce進程,reduce的輸入就是<key, value列表>這樣的結構,即相同key的value合并成了一個value列表。在這個示例中,這個value列表就是由很多個1組成的列表。reduce對這些1進行求和操作,就得到每個單詞的詞頻結果了。public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
上面講述了map和reduce進程合作完成數(shù)據(jù)處理的過程,那么這些進程是如何在分布式的服務器集群上啟動的呢?數(shù)據(jù)是如何流動并最終完成計算的呢?下面以MapReduce1為例來看這個過程,如圖31-3所示。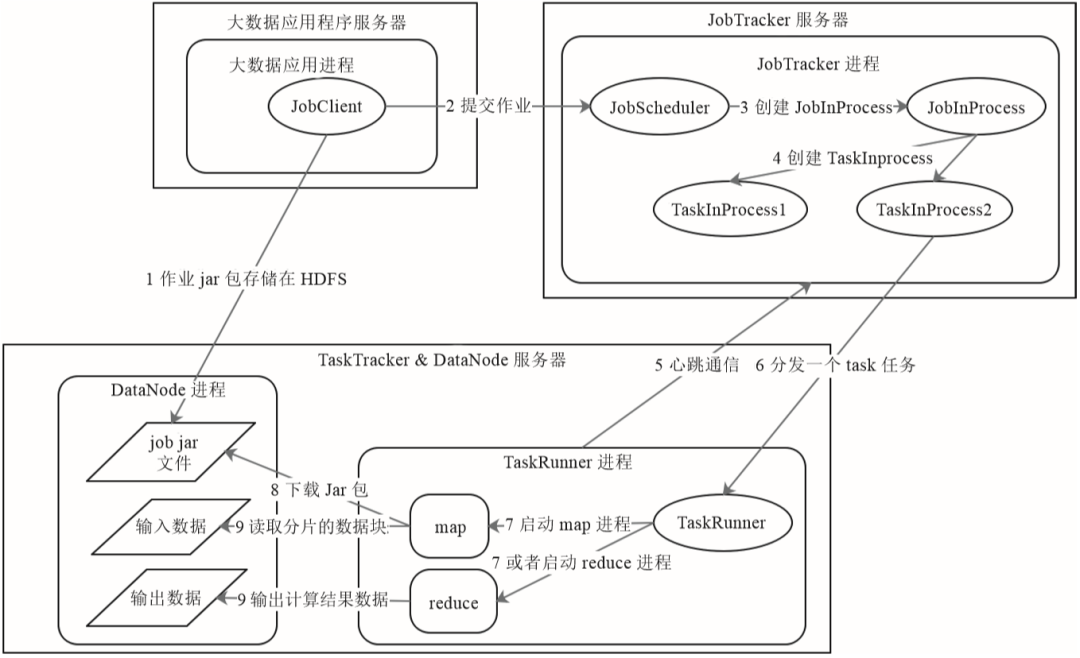
MapReduce1主要有JobTracker和TaskTracker這兩種進程角色,JobTracker在MapReduce集群中只有一個,而TaskTracker則和DataNode一起啟動在集群的所有服務器上。MapReduce應用程序JobClient啟動后,會向JobTracker提交作業(yè),JobTracker根據(jù)作業(yè)中輸入的文件路徑分析需要在哪些服務器上啟動map進程,然后就向這些服務器上的TaskTracker發(fā)送任務命令。TaskTracker收到任務后,啟動一個TaskRunner進程下載任務對應的程序,然后反射加載程序中的map函數(shù),讀取任務中分配的數(shù)據(jù)塊,并進行map計算。map計算結束后,TaskTracker會對map輸出進行shuffle操作,然后TaskRunner加載reduce函數(shù)進行后續(xù)計算。HDFS和MapReduce都是Hadoop的組成部分。MapReduce雖然只有map和reduce這兩個函數(shù),但幾乎可以滿足任何大數(shù)據(jù)分析和機器學習的計算場景。不過,復雜的計算可能需要使用多個job才能完成,這些job之間還需要根據(jù)其先后依賴關系進行作業(yè)編排,開發(fā)比較復雜。傳統(tǒng)上,主要使用SQL進行數(shù)據(jù)分析,如果能根據(jù)SQL自動生成MapReduce,就可以極大降低大數(shù)據(jù)技術在數(shù)據(jù)分析領域的應用門檻。Hive就是這樣一個工具。我們來看對于如下一條常見的SQL語句,Hive是如何將其轉(zhuǎn)換成MapReduce計算的。SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age;
這是一條常見的SQL統(tǒng)計分析語句,用于統(tǒng)計不同年齡的用戶訪問不同網(wǎng)頁的興趣偏好,具體數(shù)據(jù)輸入和執(zhí)行結果示例如圖31-4所示。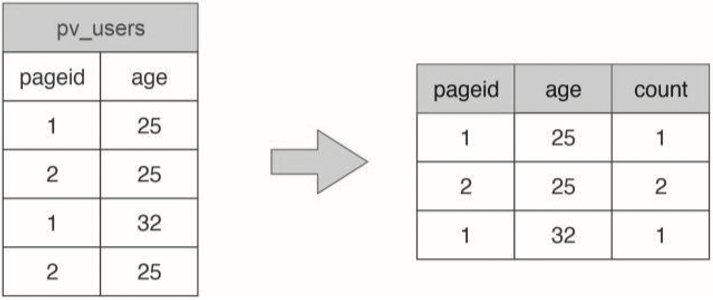
▲圖31-4 SQL統(tǒng)計分析輸入數(shù)據(jù)和執(zhí)行結果舉例看這個示例我們就會發(fā)現(xiàn),這個計算場景和WordCount很像。事實上也確實如此,我們可以用MapReduce完成這條SQL的處理,如圖31-5所示。
▲圖31-5 MapReduce完成SQL處理過程舉例map函數(shù)輸出的key是表的行記錄,value是1,reduce函數(shù)對相同的行進行記錄,也就是針對具有相同key的value集合進行求和計算,最終得到SQL的輸出結果。Hive要做的就是將SQL翻譯成MapReduce程序代碼。實際上,Hive內(nèi)置了很多Operator,每個Operator完成一個特定的計算過程,Hive將這些Operator構造成一個有向無環(huán)圖DAG,然后根據(jù)這些Operator之間是否存在shuffle將其封裝到map或者reduce函數(shù)中,之后就可以提交給MapReduce執(zhí)行了。Operator組成的DAG如圖31-6所示,這是一個包含where查詢條件的SQL,where查詢條件對應一個FilterOperator。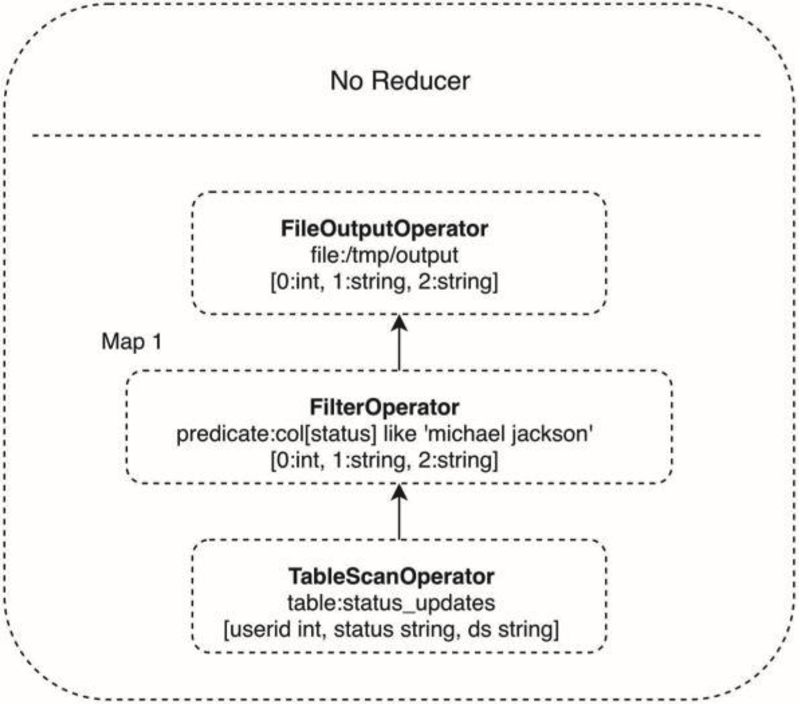
▲圖31-6 示例SQL的MapReduce 有向無環(huán)圖DAGHive整體架構如圖31-7所示。Hive的表數(shù)據(jù)存儲在HDFS。表的結構,比如表名、字段名、字段之間的分隔符等存儲在Metastore中。用戶通過Client提交SQL到Driver,Driver請求Compiler將SQL編譯成如上示例的DAG執(zhí)行計劃中,然后交給Hadoop執(zhí)行。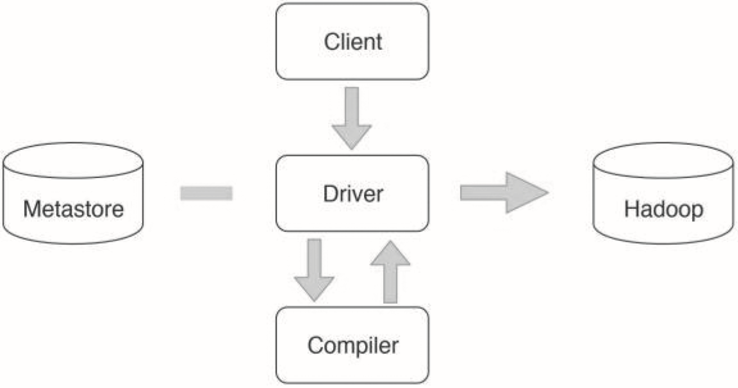
04 Spark快速大數(shù)據(jù)計算架構MapReduce主要使用硬盤存儲計算過程中的數(shù)據(jù),雖然可靠性比較高,但是性能卻較差。此外,MapReduce只能使用map和reduce函數(shù)進行編程,雖然能夠完成各種大數(shù)據(jù)計算,但是編程比較復雜。而且受map和reduce編程模型相對簡單的影響,復雜的計算必須組合多個MapReduce job才能完成,編程難度進一步增加。Spark在MapReduce的基礎上進行了改進,它主要使用內(nèi)存進行中間計算數(shù)據(jù)存儲,加快了計算執(zhí)行時間,在某些情況下性能可以提升上百倍。Spark的主要編程模型是RDD,即彈性數(shù)據(jù)集。在RDD上定義了許多常見的大數(shù)據(jù)計算函數(shù),利用這些函數(shù)可以用極少的代碼完成較為復雜的大數(shù)據(jù)計算。前面舉例的WorkCount如果用Spark編程,只需要三行代碼:val textFile = sc.textFile("hdfs://...")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
首先,從HDFS讀取數(shù)據(jù),構建出一個RDD textFile。然后,在這個RDD上執(zhí)行三個操作:- 一是將輸入數(shù)據(jù)的每一行文本用空格拆分成單詞;
- 二是將每個單詞進行轉(zhuǎn)換,比如word→(word, 1),生成<Key, Value>的結構;
- 三是針對相同的Key進行統(tǒng)計,統(tǒng)計方式是對Value求和。最后,將RDD counts寫入HDFS,完成結果輸出。
上面代碼中flatMap、map、reduceByKey都是Spark的RDD轉(zhuǎn)換函數(shù),RDD轉(zhuǎn)換函數(shù)的計算結果還是RDD,所以上面三個函數(shù)可以寫在一行代碼上,最后得到的還是RDD。Spark會根據(jù)程序中的轉(zhuǎn)換函數(shù)生成計算任務執(zhí)行計劃,這個執(zhí)行計劃就是一個DAG。Spark可以在一個作業(yè)中完成非常復雜的大數(shù)據(jù)計算,Spark DAG示例如圖31-8所示。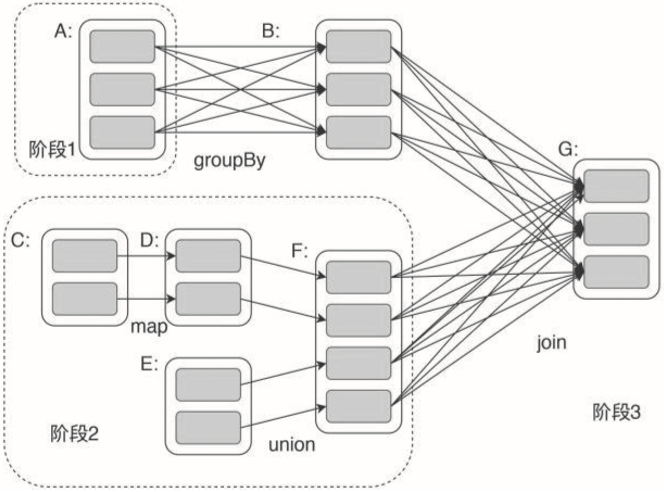
▲圖31-8 Spark RDD有向無環(huán)圖DAG示例在圖31-8中,A、C和E是從HDFS上加載的RDD。A經(jīng)過groupBy分組統(tǒng)計轉(zhuǎn)換函數(shù)計算后得到RDD B,C經(jīng)過map轉(zhuǎn)換函數(shù)計算后得到RDD D,D和E經(jīng)過union合并轉(zhuǎn)換函數(shù)計算后得到RDD F,B和F經(jīng)過join連接轉(zhuǎn)換函數(shù)計算后得到最終結果RDD G。Spark雖然比MapReduce快很多,但是在大多數(shù)場景下計算耗時依然是分鐘級別的,這種計算一般被稱為大數(shù)據(jù)批處理計算。而在實際應用中,有些時候需要在毫秒級完成不斷輸入的海量數(shù)據(jù)的計算處理,比如實時對攝像頭采集的數(shù)據(jù)進行監(jiān)控分析,這就是所謂的大數(shù)據(jù)流計算。早期比較著名的流式大數(shù)據(jù)計算引擎是Storm,后來隨著Spark的火爆,Spark上的流式計算引擎Spark Streaming也逐漸流行起來。Spark Streaming的架構原理是將實時流入的數(shù)據(jù)切分成小的一批一批的數(shù)據(jù),然后將這些小的一批批數(shù)據(jù)交給Spark執(zhí)行。由于數(shù)據(jù)量比較小,Spark Streaming又常駐系統(tǒng),不需要重新啟動,因此可以在毫秒級完成計算,看起來像是實時計算一樣,如圖31-9所示。
▲圖31-9 Spark Streaming流計算將實時流式數(shù)據(jù)轉(zhuǎn)化成小的批處理計算最近幾年比較流行的大數(shù)據(jù)引擎Flink其架構原理和Spark Streaming很相似,它可以基于不同的數(shù)據(jù)源,根據(jù)數(shù)據(jù)量和計算場景的要求,靈活地適應流計算和批處理計算。大數(shù)據(jù)技術可以說是分布式技術的一個分支,兩者都是面臨大量的計算壓力時,采用分布式服務器集群的方案解決問題。差別是大數(shù)據(jù)技術要處理的數(shù)據(jù)具有關聯(lián)性,所以需要有個中心服務器進行管理,NameNode、JobTracker都是這樣的中心服務器。而高并發(fā)的互聯(lián)網(wǎng)分布式系統(tǒng)為了提高系統(tǒng)可用性,降低中心服務器可能會出現(xiàn)的瓶頸壓力、提升性能,通常不會在架構中使用這樣的中心服務器。



