
ECCV2020 商湯提出語義分割模型新框架
轉自:學術頭條
【導讀】在ECCV 2020 上,商湯自動駕駛團隊提出了一種新型基于解耦優(yōu)化思路的語義分割模型。現(xiàn)有的語義分割方法要么通過對全局上下文信息建模來提高目標對象的內部一致性,要么通過多尺度特征融合來對目標對象的邊界細節(jié)進行優(yōu)化。我們提出了一種新的語義分割方法,本文認為性能強的語義分割方法需要明確地建模目標對象的主體(body)和邊緣(edge),這對應于圖像的高頻和低頻信息。為此,本文首先通過warp圖像特征來學習 flow field 使目標對象主體部分更加一致。在解耦監(jiān)督下,通過對不同部分(主體或邊緣)像素進行顯式采樣,進一步優(yōu)化產(chǎn)生的主體特征和殘余邊緣特征。我們的實驗表明,所提出的具有各種基準或主干網(wǎng)絡的框架可有更好的目標對象內部一致性和邊緣部分。我們提出的方法在包括 Cityscapes、CamVid、KITTI 和 BDD 在內的四個主要道路場景語義分割數(shù)據(jù)集上實現(xiàn)了 SOTA 的結果,同時保持了較高的推理效率。我們的方法僅使用精細標注的數(shù)據(jù)就可以在 Cityscapes 數(shù)據(jù)集上達到 83.7 mIoU。
挑戰(zhàn)和動機
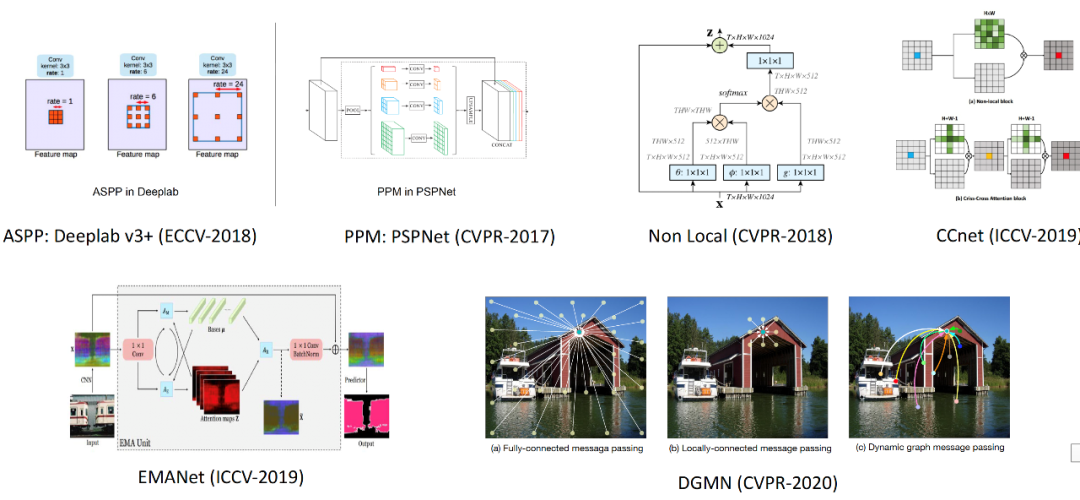
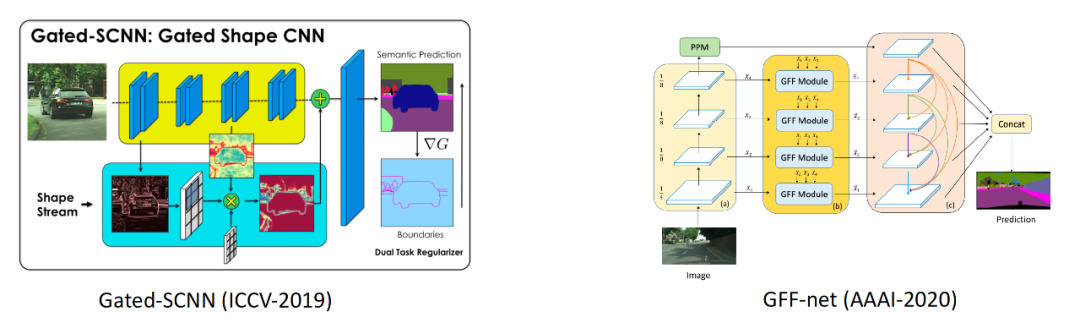
圖2?較底層信息融合
?圖3 動機示意圖
方法介紹
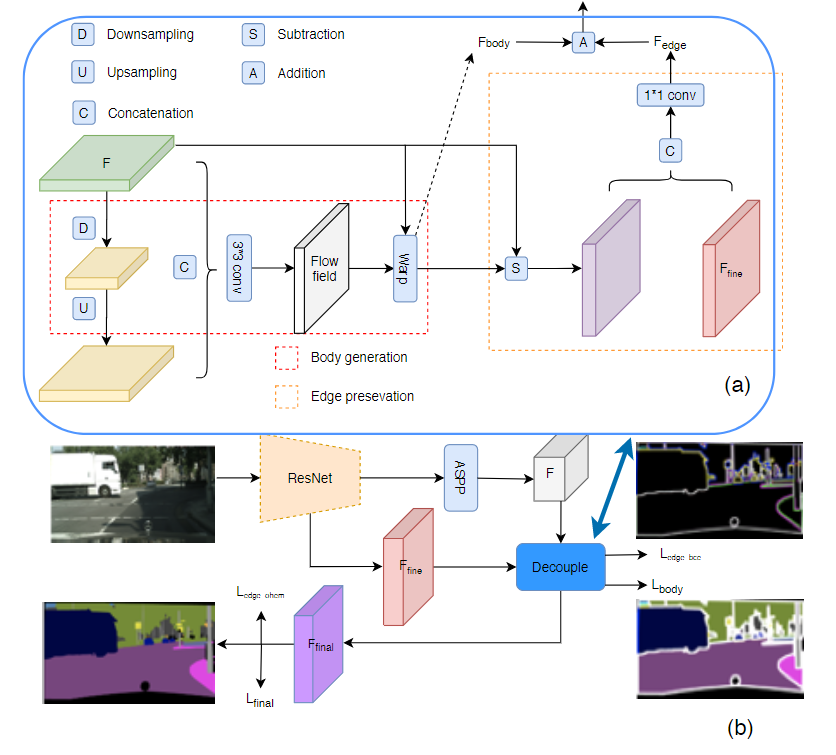
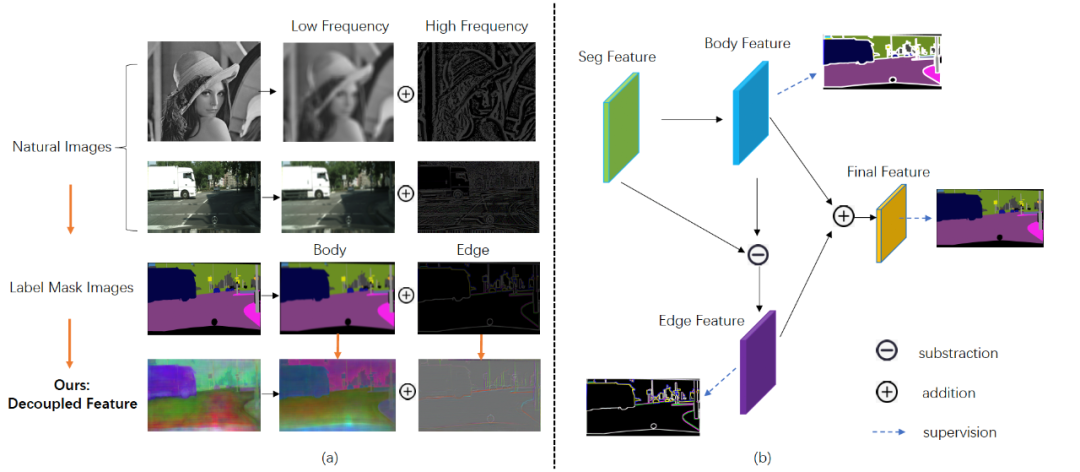
圖4方法示意圖
?
給定一個特征圖 H×W×C,其中 C 表示通道尺寸,H×W 表示空間分辨率,所提出的模塊輸出具有相同大小的細化特征圖。特征圖可以分解為 body 主體部分和 edge 邊緣部分。在本文中,假設它們滿足加法規(guī)則,這意味著特征圖 F:F = F_body + F_edge。本文模型目標是設計具有特定監(jiān)督權的組件,分別處理每個部分。因此,首先通過執(zhí)行 body 部分,然后通過顯式減法獲得邊緣部分。主體生成模塊旨在聚集對象內部的上下文信息并為每個對象形成清晰的主體對象。邊緣保留模塊用來保留更多的邊緣信息,學習到更好的邊緣特征。這兩個模塊采用不同的損失函數(shù)進行監(jiān)督訓練。
?
2,主體生成模塊
?
主體生成模塊負責為同一對象內的像素生成更一致的特征表示。因為物體內部的像素彼此相似,而沿邊界的像素則顯示出差異,因此可以顯式地學習主體和邊緣特征表示,為此,我們采用學習流場的方式(flow field),并使用 flow field 對原始特征圖進行 warp 以獲得顯式的主體特征表示。該模塊包含兩個部分:flow field 生成和特征差值。
?
2.1,F(xiàn)low field?generation 流場生成
?
為了生成主要指向對象內部的流場,突出對象中心部分的特征作為顯性引導是一種合理的方法。一般來說,低分辨率的特征圖(或粗表示)往往包含低頻項。低空間頻率項捕捉了圖像的總和,低分辨率特征圖代表了最突出的部分,在這里我們將其視為偽中心位置或種子點的集合。如圖 4(a)所示,我們采用了編碼器-解碼器的設計,編碼器將特征圖下采樣為低分辨率表示,并有較低的空間頻率部分,這里我們采用三次連續(xù)的 3×3 深度卷積來實現(xiàn)。對于 flow field 的生成,與 FlowNet-S 中做法一樣。我們首先將低頻特征圖上采樣插值到與原始特征圖相同的大小,然后將它們連在一起,并應用 3×3 卷積層來預測流場。由于我們得模型都是基于帶孔型的主干網(wǎng)絡,因此這里 3×3 的卷積核足夠大,在大多數(shù)情況下可以獲取到像素之間的長距離依賴關系。
2.2,F(xiàn)eature warping 特征差值
?
我們使用可微分的雙線性采樣機制進行插值生成主體部分的每個點, 其過程如下面公式所示:
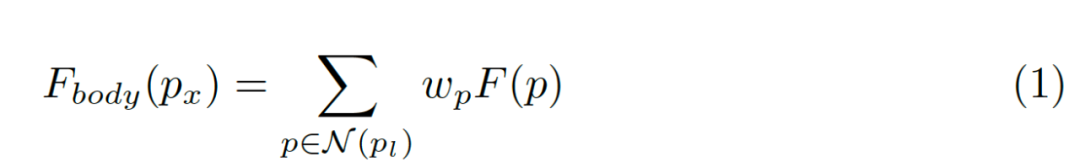
?
3,Edge preservation module邊緣保留模塊
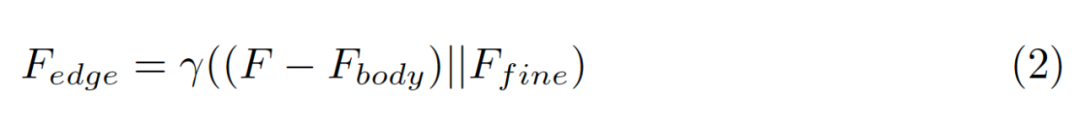
邊緣保留模塊旨在處理高頻項。它還包括兩個步驟:1)從原始特征圖F中減去主體特征圖;2)添加更精細的細節(jié)信息的低級特征作為補充。首先,從原始輸入特征圖F中減去主體特征,添加了額外的低級特征輸入,以補充缺少的細節(jié)信息,以增強主體特征中的高頻項。最后,將兩者連接起來,并采用 1×1 卷積層進行融合。該模塊可以用下面等式表示,其中 γ 是卷積層并且表示級聯(lián)運算。
?
4,Decoupled body and edge supervision解耦的損失函數(shù)
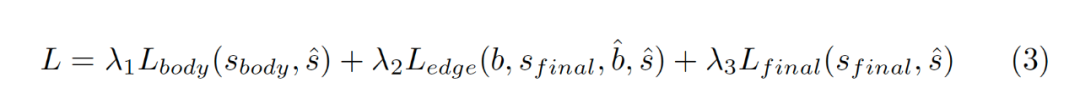
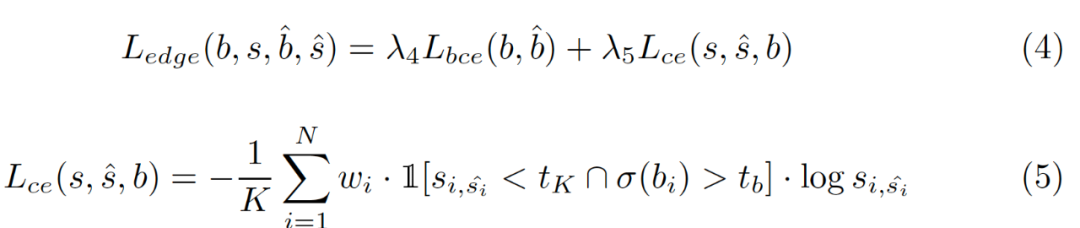
?
實驗部分
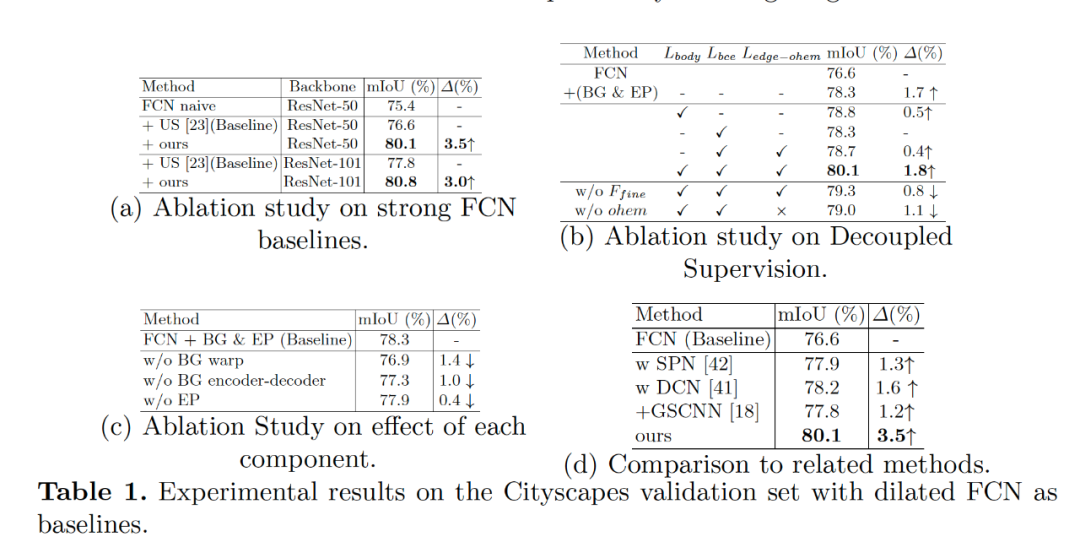
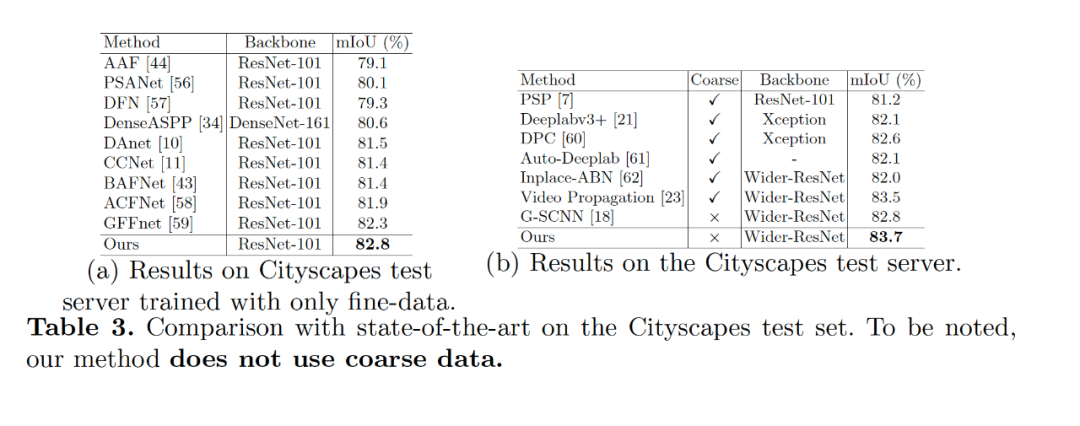
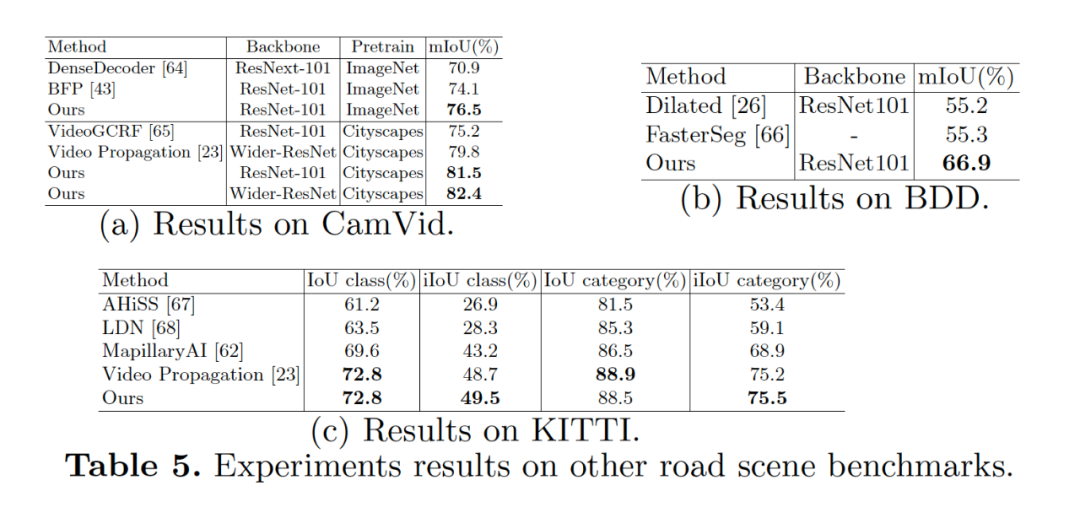
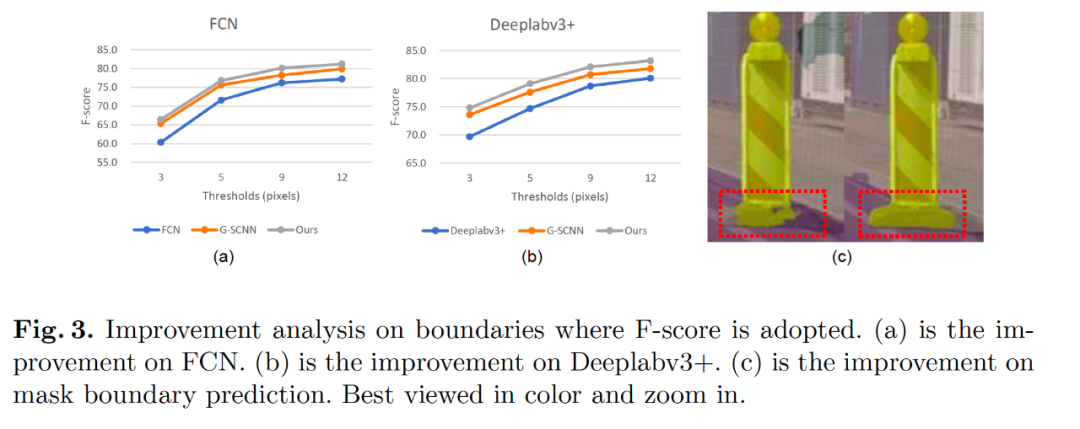
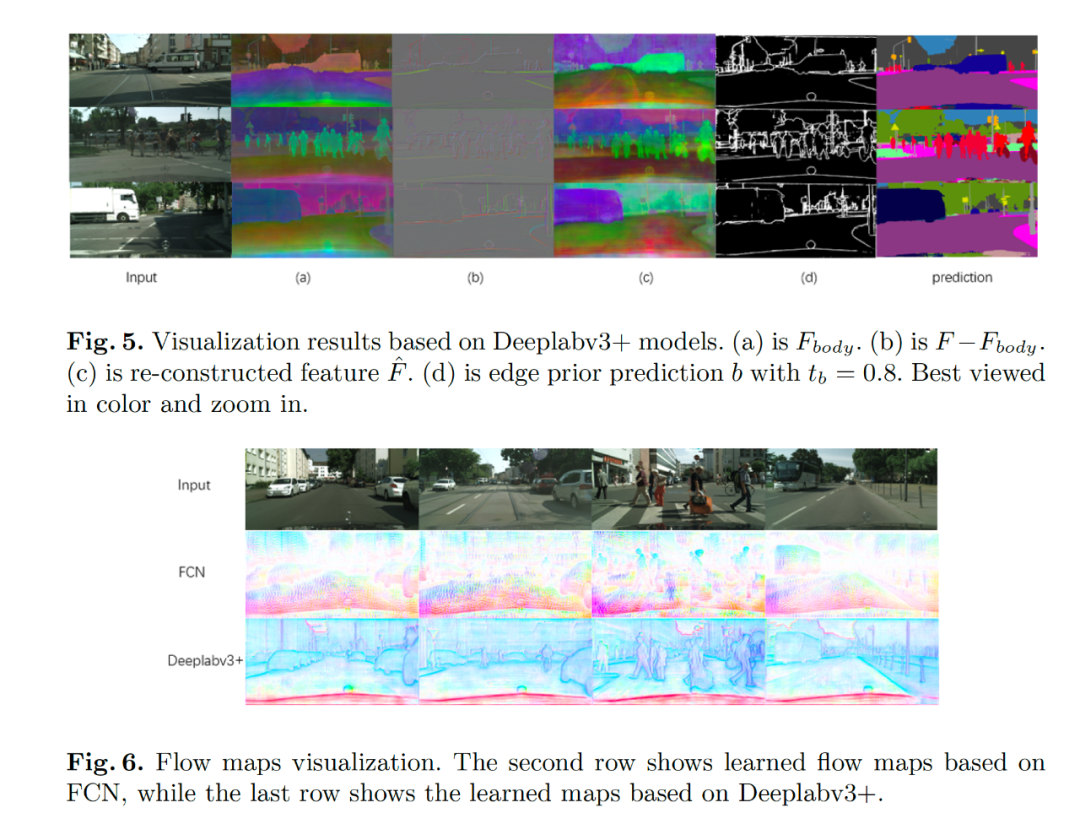
Fig3 中展示了我們分割結果的在邊緣的評測指標中也比之前最好的 G-SCNN 的結果要好。Fig5 展示了我們學習到解耦的特征表示,F(xiàn)ig6 給出了學習到的流場的可視化圖像,其中可以看到對于 FCN 的結構,流場是指向物體的內部,對于目前的 state-of-the-art 的 deeplabv3+ 模型,流場是均勻地分布在邊緣點上,原因是大部分內部區(qū)域 deeplabv3+ 已經(jīng)很一致了。
結論
在這項研究中,我們提出一個新穎的語義分割框架。我們通過把語義分割的特征進行解耦操作,進而讓每個部分單獨由不同的監(jiān)督信號進行監(jiān)督,因此我們實現(xiàn)同時提升分割物體的內部一致性和邊緣部分。并且我們的模塊十分輕量級,可以做到即插即用,可以用于優(yōu)化任何基于 FCN 的語義分割模型。我們的方法在 4 個主流的道路場景的語義分割數(shù)據(jù)集上面取得領先的效果。
往期精彩:
【原創(chuàng)首發(fā)】機器學習公式推導與代碼實現(xiàn)30講.pdf
【原創(chuàng)首發(fā)】深度學習語義分割理論與實戰(zhàn)指南.pdf

喜歡您就點個在看!
