
基于 Kafka 的實(shí)時(shí)數(shù)倉在搜索的實(shí)踐應(yīng)用
作者:vivo互聯(lián)網(wǎng)服務(wù)器團(tuán)隊(duì)-Deng jie
一、概述
Apache Kafka 發(fā)展至今,已經(jīng)是一個(gè)很成熟的消息隊(duì)列組件了,也是大數(shù)據(jù)生態(tài)圈中不可或缺的一員。Apache Kafka 社區(qū)非常的活躍,通過社區(qū)成員不斷的貢獻(xiàn)代碼和迭代項(xiàng)目,使得 Apache Kafka 功能越發(fā)豐富、性能越發(fā)穩(wěn)定,成為企業(yè)大數(shù)據(jù)技術(shù)架構(gòu)解決方案中重要的一環(huán)。
Apache Kafka 作為一個(gè)熱門消息隊(duì)列中間件,具備高效可靠的消息處理能力,且擁有非常廣泛的應(yīng)用領(lǐng)域。那么,今天就來聊一聊基于 Kafka 的實(shí)時(shí)數(shù)倉在搜索的實(shí)踐應(yīng)用。
二、為什么需要 Kafka
在設(shè)計(jì)大數(shù)據(jù)技術(shù)架構(gòu)之前,通常會(huì)做一些技術(shù)調(diào)研。我們會(huì)去思考一下為什么需要 Kafka?怎么判斷選擇的 Kafka 技術(shù)能否滿足當(dāng)前的技術(shù)要求?
2.1 早期的數(shù)據(jù)架構(gòu)
早期的數(shù)據(jù)類型比較簡單,業(yè)務(wù)架構(gòu)也比較簡單,就是將需要的數(shù)據(jù)存儲(chǔ)下來。比如將游戲類的數(shù)據(jù)存儲(chǔ)到數(shù)據(jù)庫(MySQL、Oracle)。但是,隨著業(yè)務(wù)的增量,存儲(chǔ)的數(shù)據(jù)類型也隨之增加了,然后我們需要使用的大數(shù)據(jù)集群,利用數(shù)據(jù)倉庫來將這些數(shù)據(jù)進(jìn)行分類存儲(chǔ),如下圖所示:
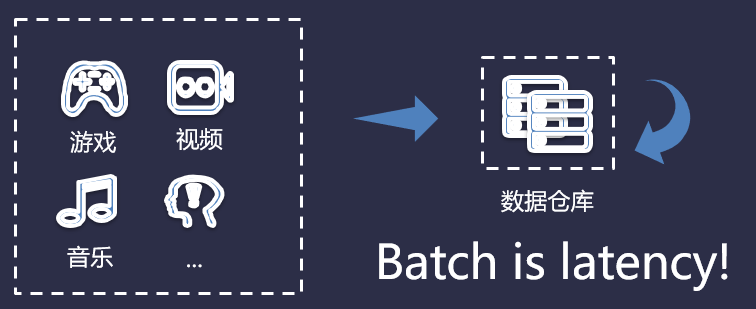
但是,數(shù)據(jù)倉庫存儲(chǔ)數(shù)據(jù)是有時(shí)延的,通常時(shí)延為T+1。而現(xiàn)在的數(shù)據(jù)服務(wù)對(duì)象對(duì)時(shí)延要求均有很高的要求,例如物聯(lián)網(wǎng)、微服務(wù)、移動(dòng)端APP等等,皆需要實(shí)時(shí)處理這些數(shù)據(jù)。
2.2?Kafka 的出現(xiàn)
Kafka 的出現(xiàn),給日益增長的復(fù)雜業(yè)務(wù),提供了新的存儲(chǔ)方案。將各種復(fù)雜的業(yè)務(wù)數(shù)據(jù)統(tǒng)一存儲(chǔ)到 Kafka 里面,然后在通過 Kafka 做數(shù)據(jù)分流。如下圖所示:
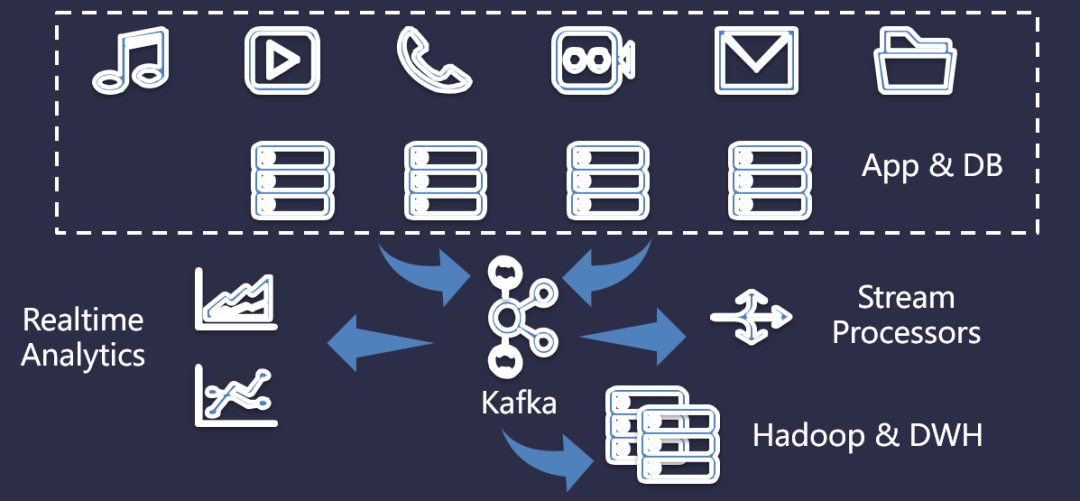
這里,可以將視頻、游戲、音樂等不同類型的數(shù)據(jù)統(tǒng)一存儲(chǔ)到 Kafka 里面,然后在通過流處理對(duì) Kafka 里面的數(shù)據(jù)做分流操作。例如,將數(shù)據(jù)存儲(chǔ)到數(shù)據(jù)倉庫、將計(jì)算的結(jié)果存儲(chǔ)到KV做實(shí)時(shí)分析等。
通常消息系統(tǒng)常見的有兩種,它們分別是:
消息隊(duì)列:隊(duì)列消費(fèi)者充當(dāng)了工作組的角色,每條消息記錄只能傳遞給一個(gè)工作進(jìn)程,從而有效的劃分工作流程;
生產(chǎn)&消費(fèi):消費(fèi)者通常是互相獨(dú)立的,每個(gè)消費(fèi)者都可以獲得每條消息的副本。
這兩種方式都是有效和實(shí)用的,通過消息隊(duì)列將工作內(nèi)容分開,用于容錯(cuò)和擴(kuò)展;生產(chǎn)和消費(fèi)能夠允許多租戶,來使得系統(tǒng)解耦。而 Apache Kafka 的優(yōu)點(diǎn)之一在于它將消息隊(duì)列、生產(chǎn)和消費(fèi)結(jié)合到了一個(gè)強(qiáng)大的消息系統(tǒng)當(dāng)中。
同時(shí),Kafka 擁有正確的消息處理特性,主要體現(xiàn)在以下幾個(gè)方面:
可擴(kuò)展性:當(dāng) Kafka 的性能(如存儲(chǔ)、吞吐等)達(dá)到瓶頸時(shí),可以通過水平擴(kuò)展來提升性能;
真實(shí)存儲(chǔ):Kafka 的數(shù)據(jù)是實(shí)時(shí)落地在磁盤上的,不會(huì)因?yàn)榧褐貑⒒蚬收隙鴣G失數(shù)據(jù);
實(shí)時(shí)處理:能夠集成主流的計(jì)算引擎(如Flink、Spark等),對(duì)數(shù)據(jù)進(jìn)行實(shí)時(shí)處理;
順序?qū)懭?/strong>:磁盤順序 I/O 讀寫,跳過磁頭“尋址”時(shí)間,提高讀寫速度;
內(nèi)存映射:操作系統(tǒng)分頁存儲(chǔ)利用內(nèi)存提升 I/O 性能,實(shí)現(xiàn)文件到內(nèi)存的映射,通過同步或者異步來控制 Flush;
零拷貝:將磁盤文件的數(shù)據(jù)復(fù)制到“頁面緩存”一次,然后將數(shù)據(jù)從“頁面緩存”直接發(fā)送到網(wǎng)絡(luò);
高效存儲(chǔ):Topic 和 Partition 拆為多個(gè)文件片段(Segment),定期清理無效文件。采用稀疏存儲(chǔ),間隔若干字節(jié)建立一條索引,防止索引文件過大。
2.3 簡單的應(yīng)用場景
這里,我們可以通過一個(gè)簡單直觀的應(yīng)用場景,來了解 Kafka 的用途。
場景:假如用戶A正在玩一款游戲,某一天用戶A喜歡上了游戲里面的一款道具,打算購買,于是在當(dāng)天 14:00 時(shí)充值了 10 元,在逛游戲商店時(shí)又喜歡上了另一款道具,于是在 14:30 時(shí)又充值了 30 元,接著在 15:00 時(shí)開始下單購買,花費(fèi)了 20 元,剩余金額為 20 元。那么,整個(gè)事件流,對(duì)應(yīng)到庫表里面的數(shù)據(jù)明細(xì)應(yīng)該是如下圖所示:

三、Kafka解決了什么問題
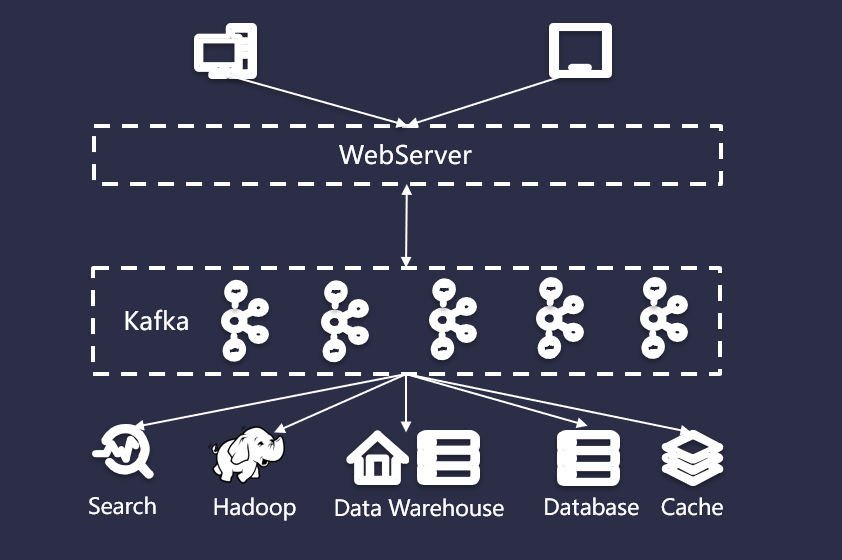
早期為響應(yīng)項(xiàng)目快速上線,在服務(wù)器或者云服務(wù)器上部署一個(gè) WebServer,為個(gè)人電腦或者移動(dòng)用戶提供訪問體驗(yàn),然后后臺(tái)在對(duì)接一個(gè)數(shù)據(jù)庫,為 Web 應(yīng)用提供數(shù)據(jù)持久化以及數(shù)據(jù)查詢,流程如下圖所示:
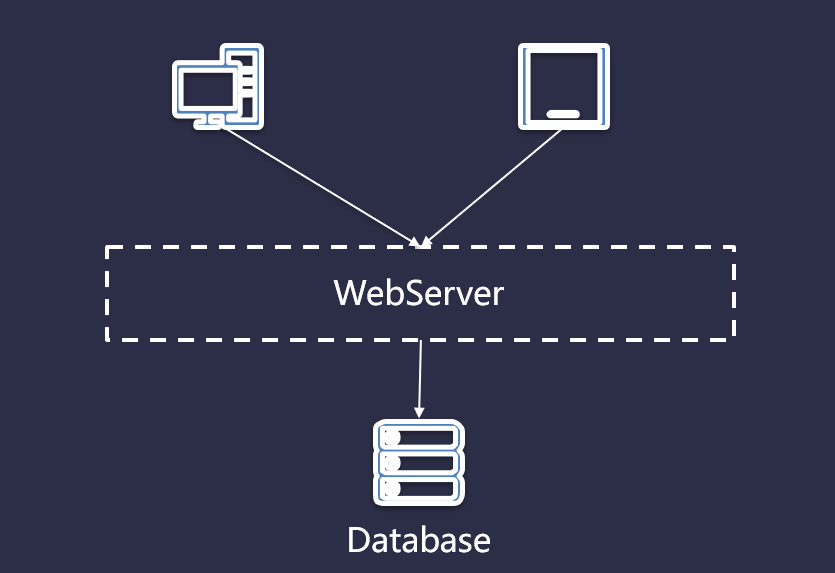
但是,隨著用戶的迅速增長,用戶所有的訪問都直接通過 SQL 數(shù)據(jù)庫使得它不堪重負(fù),數(shù)據(jù)庫的壓力也越來越大,不得不加上緩存服務(wù)以降低 SQL 數(shù)據(jù)庫的荷載。
同時(shí),為了理解用戶行為,又開始收集日志并保存到 Hadoop 這樣的大數(shù)據(jù)集群上做離線處理,并且把日志放在全文檢索系統(tǒng)(比如 ElasticSearch)中以便快速定位問題。由于需要給投資方看業(yè)務(wù)狀況,也需要把數(shù)據(jù)匯總到數(shù)據(jù)倉庫(比如 Hive)中以便提供交互式報(bào)表。此時(shí)的系統(tǒng)架構(gòu)已經(jīng)具有一定的復(fù)雜性了,將來可能還會(huì)加入實(shí)時(shí)模塊以及外部數(shù)據(jù)交互。
本質(zhì)上,這是一個(gè)數(shù)據(jù)集成問題。沒有任何一個(gè)系統(tǒng)能夠解決所有的事情,所以業(yè)務(wù)數(shù)據(jù)根據(jù)不同用途,存放在不同的系統(tǒng),比如歸檔、分析、搜索、緩存等。數(shù)據(jù)冗余本身沒有任何問題,但是不同系統(tǒng)之間太過復(fù)雜的數(shù)據(jù)同步卻是一種挑戰(zhàn)。如下圖所示:
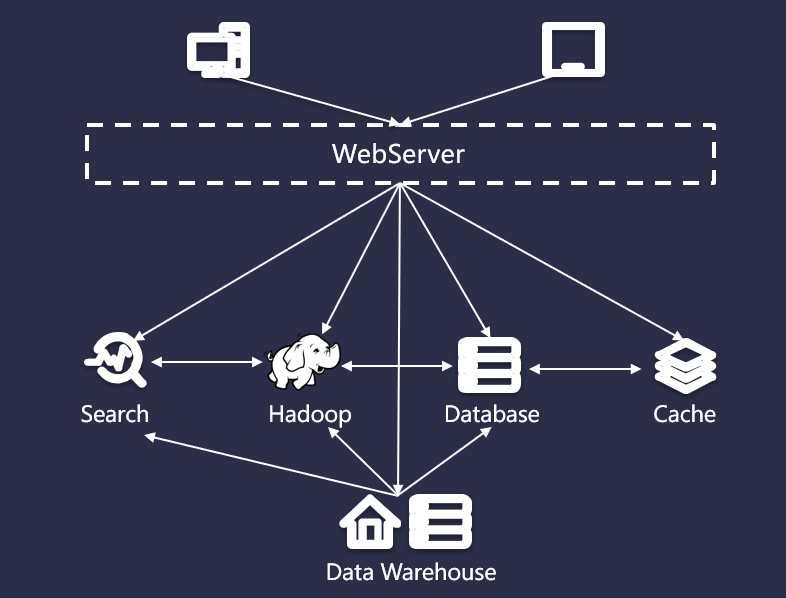
而 Kafka 可以讓合適的數(shù)據(jù)以合適的形式出現(xiàn)在合適的地方。Kafka 的做法是提供消息隊(duì)列,讓生產(chǎn)者向隊(duì)列的末尾添加數(shù)據(jù),讓多個(gè)消費(fèi)者從隊(duì)列里面依次讀取數(shù)據(jù)然后自行處理。如果說之前連接的復(fù)雜度是 O(N^2),那么現(xiàn)在復(fù)雜度降低到了 O(N),擴(kuò)展起來也方便多了,流程如下圖所示:
四、Kafka的實(shí)踐應(yīng)用
4.1 為什么需要建設(shè)實(shí)時(shí)數(shù)倉
4.1.1 目的
通常情況下,在大數(shù)據(jù)場景中,存儲(chǔ)海量數(shù)據(jù)建設(shè)數(shù)據(jù)倉庫一般都是離線數(shù)倉(時(shí)延T+1),通過定時(shí)任務(wù)每天拉取增量數(shù)據(jù),然后創(chuàng)建各個(gè)業(yè)務(wù)不同維度的數(shù)據(jù),對(duì)外提供 T+1 的數(shù)據(jù)服務(wù)。計(jì)算和數(shù)據(jù)的實(shí)時(shí)性均比較差,業(yè)務(wù)人員無法根據(jù)自己的即時(shí)性需求獲取幾分鐘之前的實(shí)時(shí)數(shù)據(jù)。數(shù)據(jù)本身的價(jià)值隨著時(shí)間的流逝會(huì)逐步減弱,因此數(shù)據(jù)產(chǎn)生后必須盡快的到達(dá)用戶的手中,實(shí)時(shí)數(shù)倉的建設(shè)需求由此而來。
4.1.2 目標(biāo)
為了適應(yīng)業(yè)務(wù)高速迭代的特點(diǎn),分析用戶行為,挖掘用戶價(jià)值,提高用戶留存,在實(shí)時(shí)數(shù)據(jù)可用性、可擴(kuò)展性、易用性、以及準(zhǔn)確性等方面提供更好的支持,因此需要建設(shè)實(shí)時(shí)數(shù)倉。主要目標(biāo)包含如下所示:
統(tǒng)一收斂數(shù)據(jù)出口:統(tǒng)一數(shù)據(jù)口徑,減少數(shù)據(jù)重復(fù)性建設(shè);
降低數(shù)據(jù)維護(hù)成本:提升數(shù)據(jù)準(zhǔn)確性、及時(shí)性,優(yōu)化數(shù)據(jù)使用體驗(yàn)和成本;
減少數(shù)據(jù)使用成本:提高數(shù)據(jù)復(fù)用率,避免實(shí)時(shí)數(shù)據(jù)重復(fù)消費(fèi)。
4.2 如何構(gòu)建實(shí)時(shí)數(shù)倉為搜索提供數(shù)據(jù)
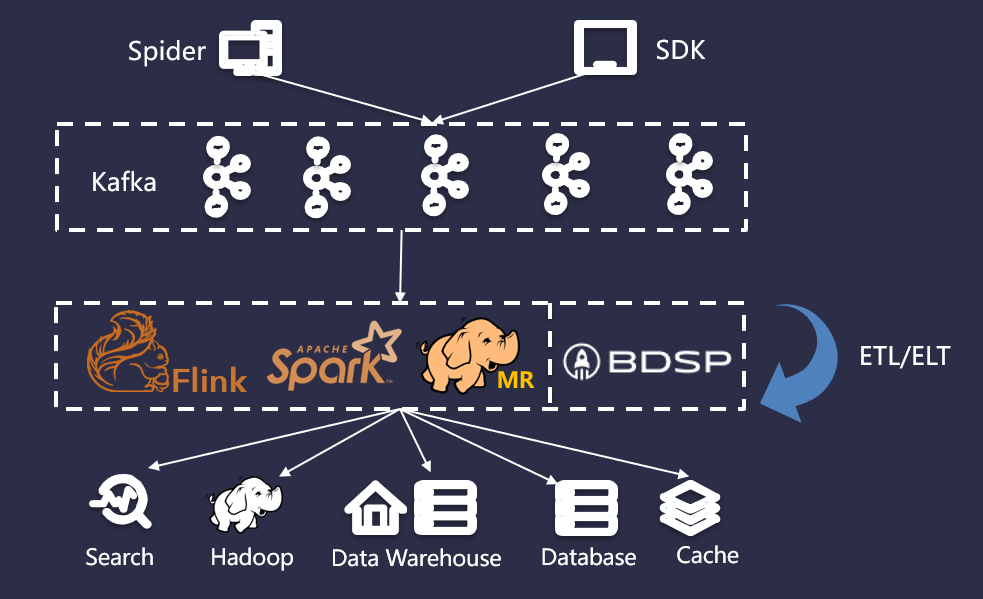
當(dāng)前實(shí)時(shí)數(shù)倉比較主流的架構(gòu)一般來說包含三個(gè)大的模塊,它們分別是消息隊(duì)列、計(jì)算引擎、以及存儲(chǔ)。結(jié)合上述對(duì) Kafka 的綜合分析,結(jié)合搜索的業(yè)務(wù)場景,引入 Kafka 作為消息隊(duì)列,復(fù)用大數(shù)據(jù)平臺(tái)(BDSP)的能力作為計(jì)算引擎和存儲(chǔ),具體架構(gòu)如下圖所示:
4.3 流處理引擎選擇
目前業(yè)界比較通用的流處理引擎主要有兩種,它們分別是Flink和Spark,那么如何選擇流處理引擎呢?我們可以對(duì)比以下特征來決定選擇哪一種流處理引擎?
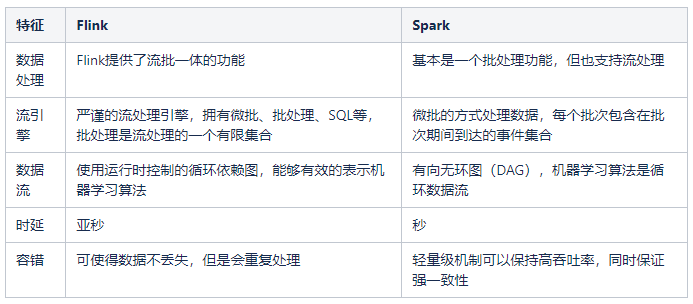
Flink作為一款開源的大數(shù)據(jù)流式計(jì)算引擎,它同時(shí)支持流批一體,引入Flink作為實(shí)時(shí)數(shù)倉建設(shè)的流引擎的主要原因如下:
高吞吐、低延時(shí);
靈活的流窗口;
輕量級(jí)容錯(cuò)機(jī)制;
流批一體
4.4 建設(shè)實(shí)時(shí)數(shù)倉遇到的問題
在建設(shè)初期,用于實(shí)時(shí)處理的 Kafka 集群規(guī)模較小,單個(gè) Topic 的數(shù)據(jù)容量非常大,不同的實(shí)時(shí)任務(wù)都會(huì)消費(fèi)同一個(gè)大數(shù)據(jù)量的 Topic,這樣會(huì)導(dǎo)致 Kafka 集群的 I/O 壓力非常的大。
因此,在使用的過程中會(huì)發(fā)現(xiàn) Kafka 的壓力非常大,經(jīng)常出現(xiàn)延時(shí)、I/O能性能告警。因此,我們采取了將大數(shù)據(jù)量的單 Topic 進(jìn)行實(shí)時(shí)分發(fā)來解決這種問題,基于 Flink 設(shè)計(jì)了如下圖所示的數(shù)據(jù)分發(fā)流程。
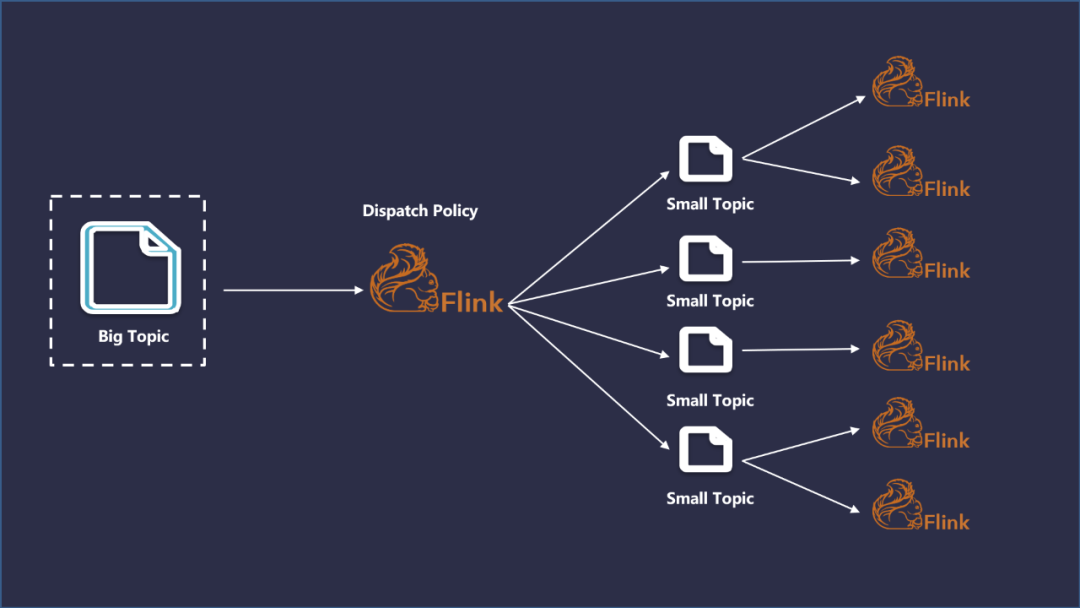
上述流程,隨著業(yè)務(wù)類型和數(shù)據(jù)量的增加,又會(huì)面臨新的問題:
數(shù)據(jù)量增加,隨著消費(fèi)任務(wù)的增加,Kafka 集群 I/O 負(fù)載大時(shí)會(huì)影響消費(fèi);
不用業(yè)務(wù)之間 Topic 的消費(fèi)沒有落地存儲(chǔ)(比如HDFS、HBase存儲(chǔ)等),會(huì)產(chǎn)生重復(fù)消費(fèi)的情況;
數(shù)據(jù)耦合度過高,遷移數(shù)據(jù)和任務(wù)難度大。
4.5 實(shí)時(shí)數(shù)倉方案進(jìn)階
目前,主流的實(shí)時(shí)數(shù)倉架構(gòu)通常有2種,它們分別是Lambda、Kappa。
4.5.1 Lambda
隨著實(shí)時(shí)性需求的提出,為了快速計(jì)算一些實(shí)時(shí)指標(biāo)(比如,實(shí)時(shí)點(diǎn)擊、曝光等),會(huì)在離線數(shù)倉大數(shù)據(jù)架構(gòu)的基礎(chǔ)上增加一個(gè)實(shí)時(shí)計(jì)算的鏈路,并對(duì)消息隊(duì)列實(shí)現(xiàn)數(shù)據(jù)來源的流失處理,通過消費(fèi)消息隊(duì)列中的數(shù)據(jù) ,用流計(jì)算引擎來實(shí)現(xiàn)指標(biāo)的增量計(jì)算,并推送到下游的數(shù)據(jù)服務(wù)中去,由下游數(shù)據(jù)服務(wù)層完成離線和實(shí)時(shí)結(jié)果的匯總。具體流程如下:
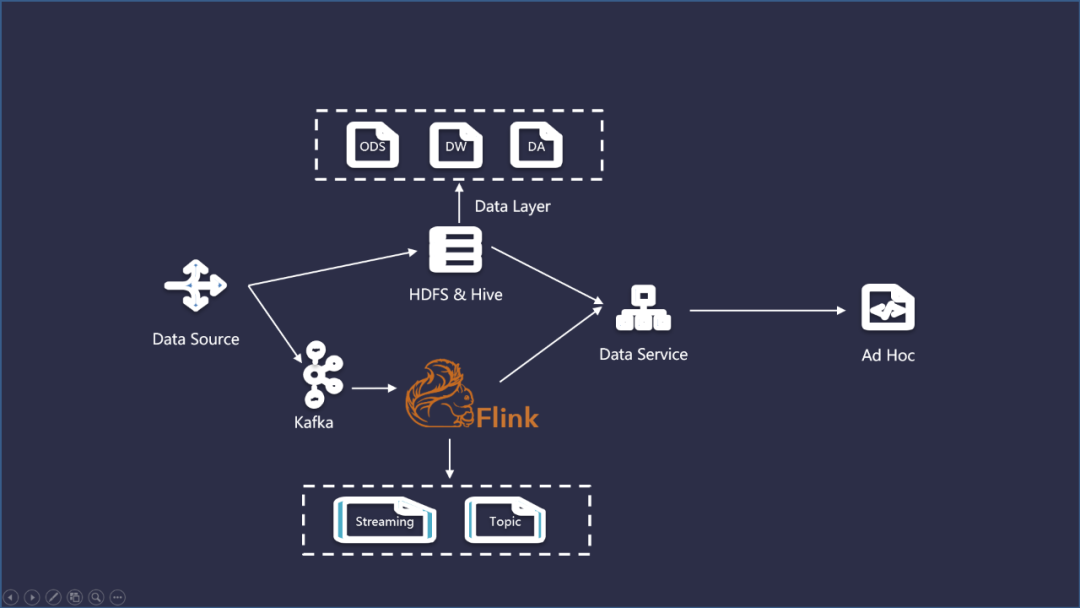
4.5.2 Kappa
Kappa架構(gòu)只關(guān)心流式計(jì)算,數(shù)據(jù)以流的方式寫入到 Kafka ,然后通過 Flink 這類實(shí)時(shí)計(jì)算引擎將計(jì)算結(jié)果存放到數(shù)據(jù)服務(wù)層以供查詢。可以看作是在Lambda架構(gòu)的基礎(chǔ)上簡化了離線數(shù)倉的部分。具體流程如下:
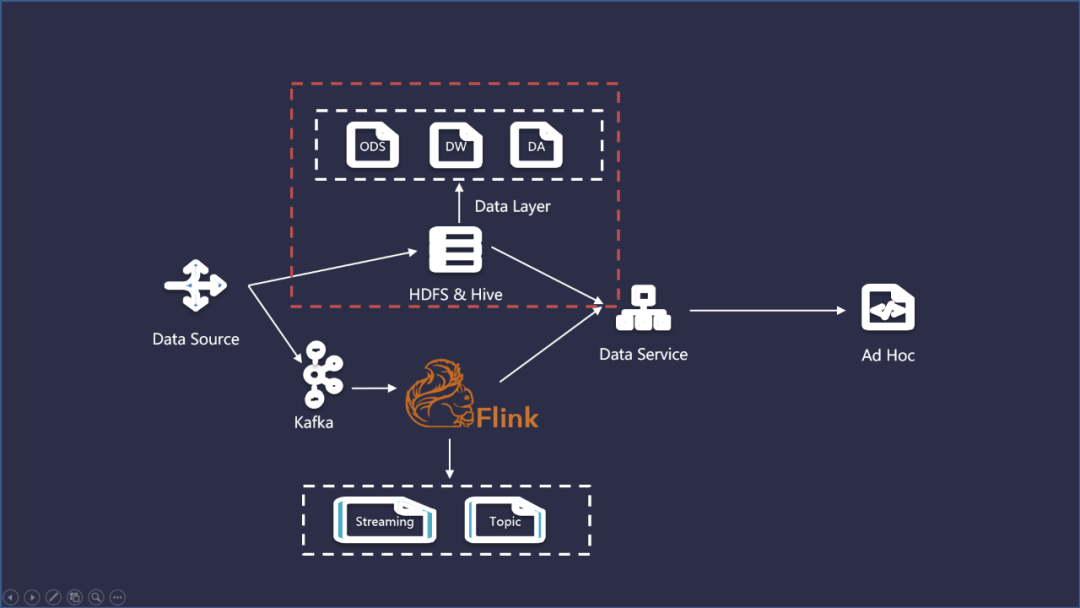
在實(shí)際建設(shè)實(shí)時(shí)數(shù)倉的過程中,我們結(jié)合這2種架構(gòu)的思想來使用。實(shí)時(shí)數(shù)倉引入了類似于離線數(shù)倉的分層理念,主要是為了提供模型的復(fù)用率,同時(shí)也要考慮易用性、一致性、以及計(jì)算的成本。
4.5.3 實(shí)時(shí)數(shù)倉分層
在進(jìn)階建設(shè)實(shí)時(shí)數(shù)倉時(shí),分層架構(gòu)的設(shè)計(jì)并不會(huì)像離線數(shù)倉那邊復(fù)雜,這是為了避免數(shù)據(jù)計(jì)算鏈路過長造成不必要的延時(shí)情況。具體流程圖如下所示:
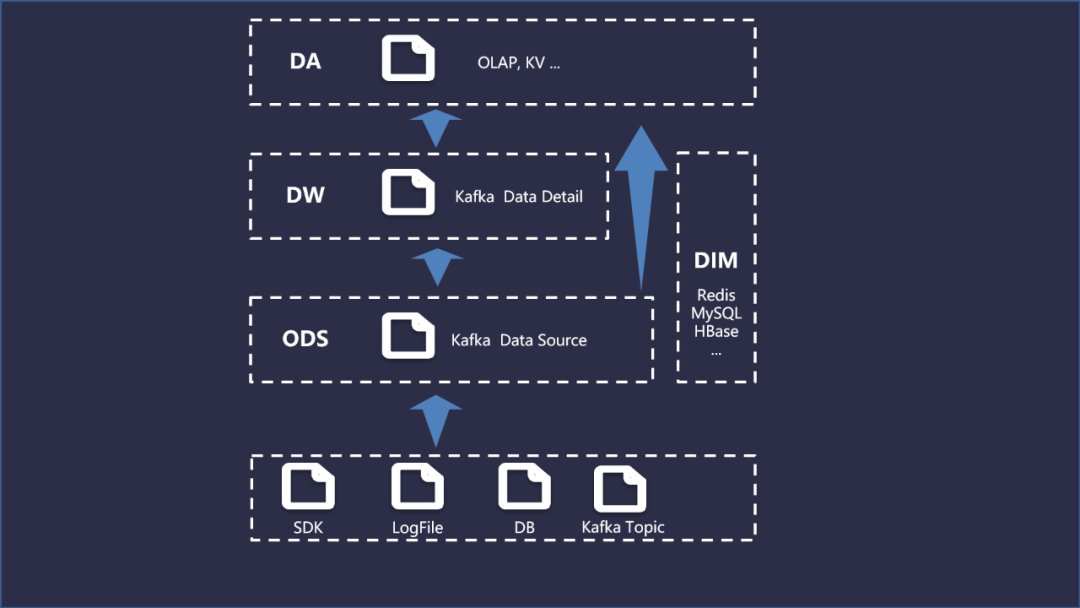
ODS層:以Kafka 作為消息隊(duì)列,將所有需要實(shí)時(shí)計(jì)算處理的數(shù)據(jù)放到對(duì)應(yīng)的 Topic 進(jìn)行處理;
DW層:通過Flink實(shí)時(shí)消費(fèi)Topic中的數(shù)據(jù),然后通過數(shù)據(jù)清理、多維度關(guān)聯(lián)(JOIN)等,將一些相同維度的業(yè)務(wù)系統(tǒng)、維表中的特征屬性進(jìn)行關(guān)聯(lián),提供數(shù)據(jù)易用性和復(fù)用性能力,最終得到實(shí)時(shí)明細(xì)數(shù)據(jù);
DIM層:用來存儲(chǔ)關(guān)聯(lián)的查詢的維度信息,存儲(chǔ)介質(zhì)可以按需選擇,比如HBase、Redis、MySQL等;
DA層:針對(duì)實(shí)時(shí)數(shù)據(jù)場景需求,進(jìn)行高度聚合匯總,服務(wù)于KV、BI等場景。OLAP分析可以使用ClickHouse,KV可以選擇HBase(若數(shù)據(jù)量較小,可以采用Redis)。
通過上面的流程,建設(shè)實(shí)時(shí)數(shù)倉分層時(shí),確保了對(duì)實(shí)時(shí)計(jì)算要求比較高的任務(wù)不會(huì)影響到BI報(bào)表、或者KV查詢。但是,會(huì)有新的問題需要解決:
Kafka 實(shí)時(shí)數(shù)據(jù)如何點(diǎn)查?
消費(fèi)任務(wù)異常時(shí)如何分析?
4.5.4 Kafka監(jiān)控
針對(duì)這些問題,我們調(diào)研和引入了Kafka 監(jiān)控系統(tǒng)——Kafka Eagle(目前改名為EFAK)。復(fù)用該監(jiān)控系統(tǒng)中比較重要的維度監(jiān)控功能。
Kafka Eagle處理能夠滿足上訴兩個(gè)維度的監(jiān)控需求之外,還提供了一些日常比較實(shí)用的功能,比如Topic記錄查看、Topic容量查看、消費(fèi)和生產(chǎn)任務(wù)的速率、消費(fèi)積壓等。我們采用了 Kafka-Eagle 來作為對(duì)實(shí)時(shí)數(shù)倉的任務(wù)監(jiān)控。Kafka-Eagle 系統(tǒng)設(shè)計(jì)架構(gòu)如下圖所示:
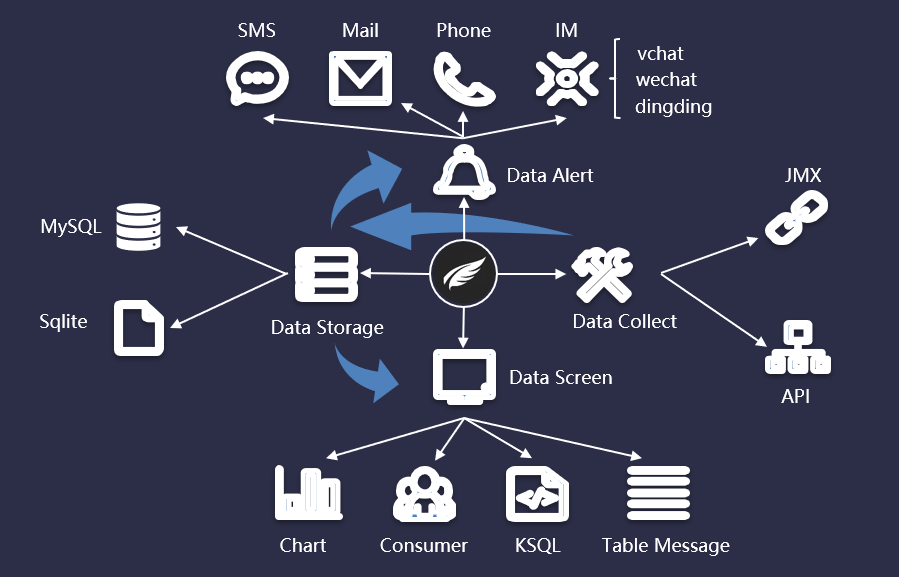
Kafka-Eagle 是一款完全開源的對(duì) Kafka 集群及應(yīng)用做全面監(jiān)控的系統(tǒng),其核心由以下幾個(gè)部分組成:
數(shù)據(jù)采集:核心數(shù)據(jù)來源 JMX 和 API 獲取;
數(shù)據(jù)存儲(chǔ):支持 MySQL 和 Sqlite 存儲(chǔ);
數(shù)據(jù)展示:消費(fèi)者應(yīng)用、圖表趨勢監(jiān)控(包括集群狀態(tài)、消費(fèi)生產(chǎn)速率、消費(fèi)積壓等)、開發(fā)的分布式 KSQL 查詢引擎,通過 KSQL 消息查詢;
數(shù)據(jù)告警:支持常用的 IM 告警(微信,釘釘,WebHook等),同時(shí)郵件、短信、電話告警也一并支持。
部分預(yù)覽截圖如下:
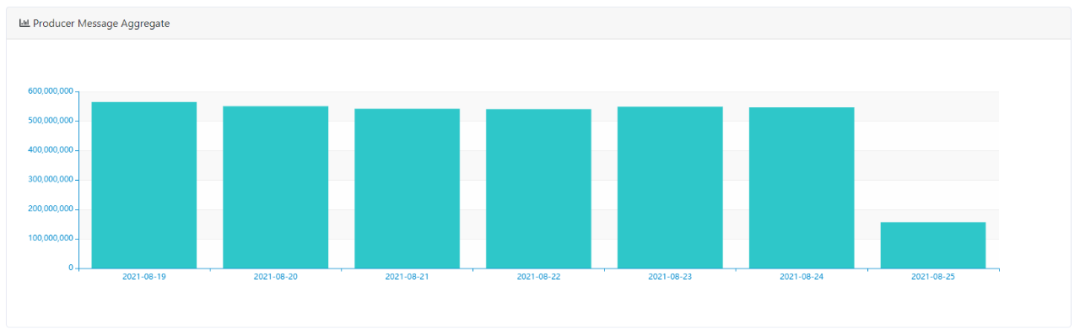
1)Topic最近7天寫入量分布
默認(rèn)展示所有Topic的每天寫入總量分布,可選擇時(shí)間維度、Topic聚合維度,來查看寫入量的分布情況,預(yù)覽截圖如下所示:
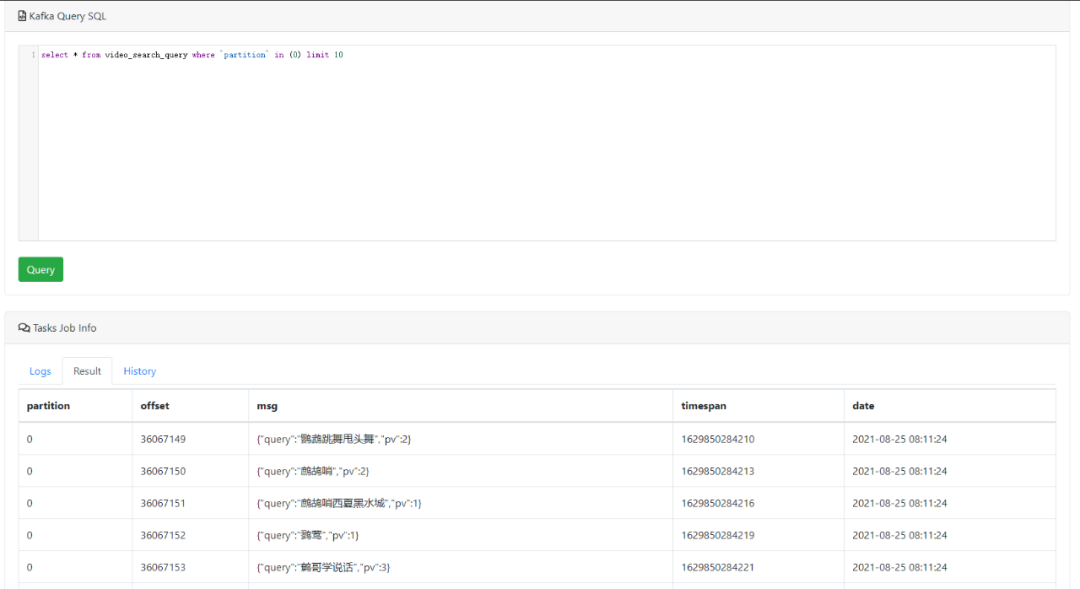
2)KSQL查詢Topic消息記錄
可以通過編寫SQL語句,來查詢(支持過濾條件)Topic中的消息記錄,預(yù)覽截圖如下所示:
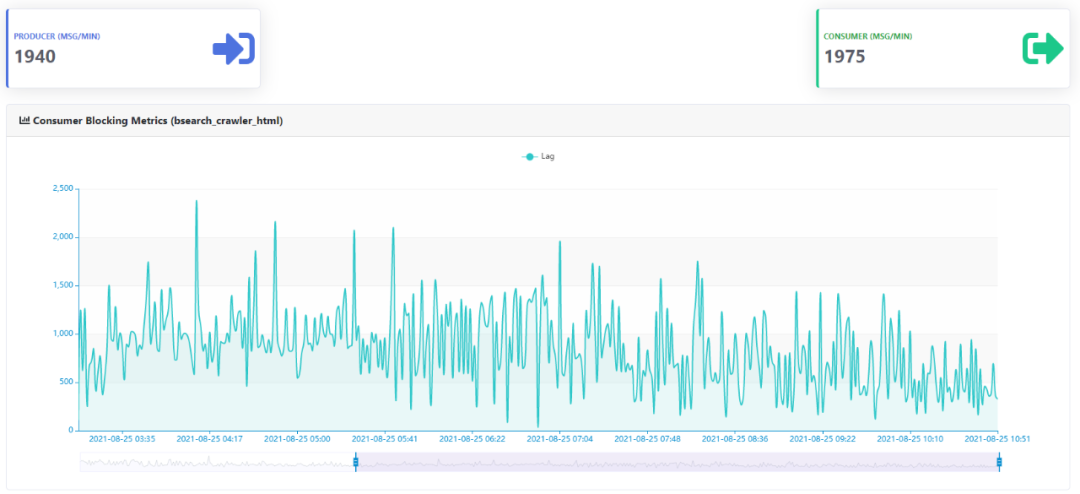
3)消費(fèi)Topic積壓詳情
可以監(jiān)控所有被消費(fèi)的Topic的消費(fèi)速率、消費(fèi)積壓等詳情,預(yù)覽截圖如下所示:
五、參考資料
1.https://kafka.apache.org/documentation/
2.http://www.kafka-eagle.org/
3.https://github.com/smartloli/kafka-eagle