
字節(jié)跳動數(shù)據(jù)湖在實時數(shù)倉中的實踐

一、實時數(shù)倉場景介紹
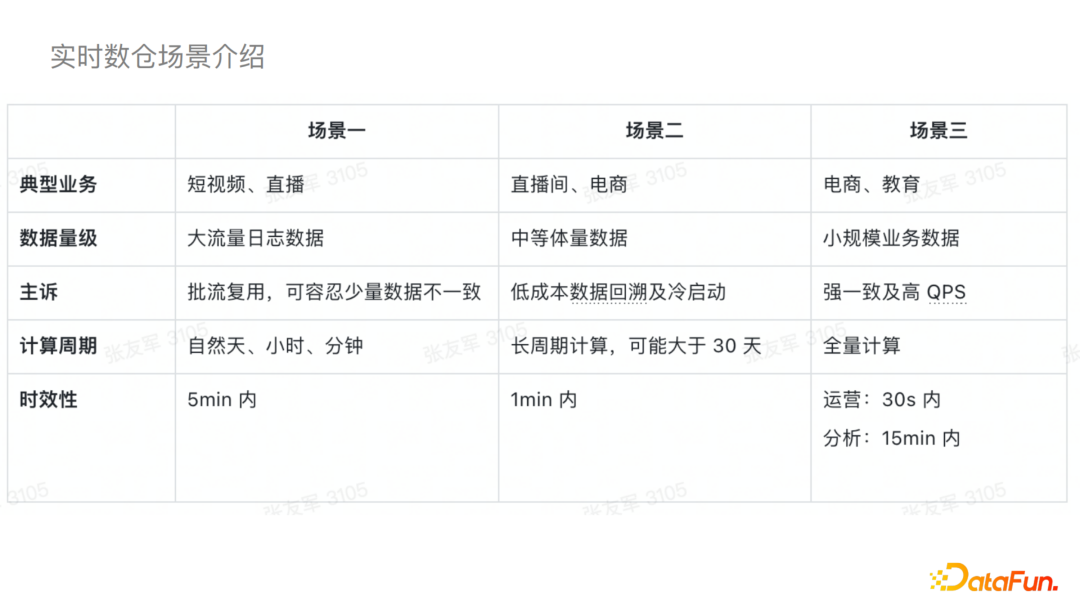
為了數(shù)據(jù)湖更好的落地,我們在落地之前與業(yè)務做了一些深入的溝通,并根據(jù)不同業(yè)務的特點主要分為了三個場景:
1)場景一典型的業(yè)務主要是短視頻和直播,它的數(shù)據(jù)量級一般都比較大,例如大流量的日志數(shù)據(jù),其計算周期一般是自然的天、小時或者分鐘級別的,實時性的要求一般是五分鐘內(nèi),主要訴求是批流的復用,可以容忍少量數(shù)據(jù)的不一致。
2)場景二一般是直播或者電商的部分場景,數(shù)據(jù)量一般是中等體量,為長周期計算,對于實時性的要求一般是一分鐘以內(nèi),主要訴求是低成本的數(shù)據(jù)回溯以及冷啟動。
3)場景三主要是電商和教育的一些場景,一般都是小規(guī)模的業(yè)務數(shù)據(jù),會對數(shù)據(jù)做全量計算,其實時性要求是秒級的,主要訴求是強一致性以及高QPS。
我們結(jié)合這些特點基于數(shù)據(jù)湖做了一些成套的解決方案,接下來我們會基于實際的一些場景和案例一一去了解。
二、實時數(shù)倉場景初探
本節(jié)我們討論的是字節(jié)實時數(shù)倉場景的初探以及遇到的問題和解決方案。
坦白地講,在最初落地時大家對數(shù)據(jù)湖能支持線上生產(chǎn)的態(tài)度都是存疑的,我們開始的方案也就比較保守。我們首先挑選一些對比現(xiàn)有解決方案,數(shù)據(jù)湖具有凸顯的優(yōu)勢的場景,針對其中的一些痛點問題嘗試小規(guī)模的落地。
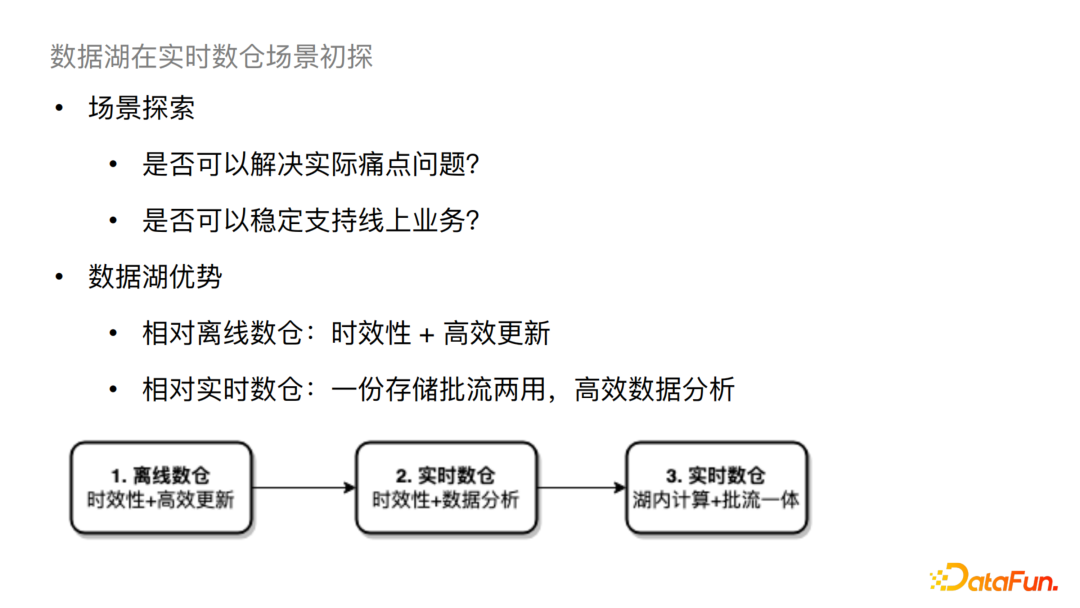
離線數(shù)倉有兩個比較大的問題:
一是時效性問題,現(xiàn)狀一般是天或小時級; 二是更新問題,例如需要更新某個小時內(nèi)的部分數(shù)據(jù),現(xiàn)狀需要將分區(qū)內(nèi)數(shù)據(jù)全部重刷,這樣的更新效率是很低的。
對于這樣的場景,數(shù)據(jù)湖兼具時效性和高效更新能力。同時相對于實時數(shù)倉來說,數(shù)據(jù)湖可以一份存儲,批流兩用,從而直接進行高效的數(shù)據(jù)分析。
基于以上對業(yè)務的分析,我們會按照以下步驟來做一線的落地。
1、基于視頻元數(shù)據(jù)的落地方案
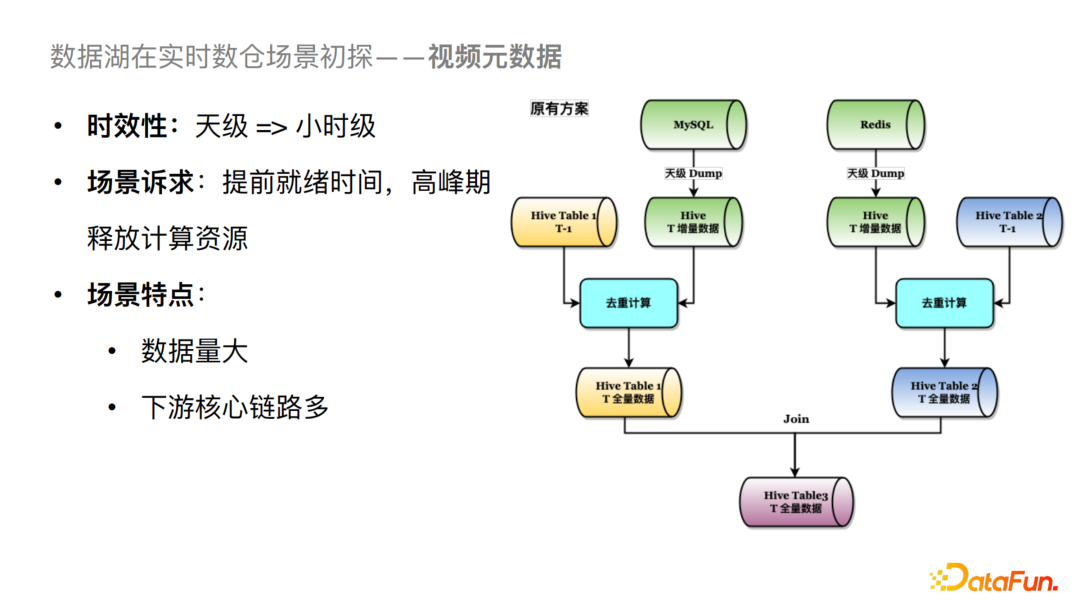
看上圖我們原有的方案有三個Hive表,Hive Table 1,2,3。對于整個鏈路來說我們會把左邊MySQL數(shù)據(jù)源的數(shù)據(jù)導到Table 1中,右邊Redis的數(shù)據(jù)導到Table 2中,然后將兩個表做Join。這里存在兩個比較大的問題:
一是高峰期的資源占用率較高,因為天級 Dump 數(shù)據(jù)量較大,且都集中在凌晨; 二是就緒時間比較長,因為存在去重邏輯,會將 T-1 天分區(qū)的數(shù)據(jù)和當天分區(qū)的數(shù)據(jù)合并去重計算后落到當天(T天)的分區(qū)。
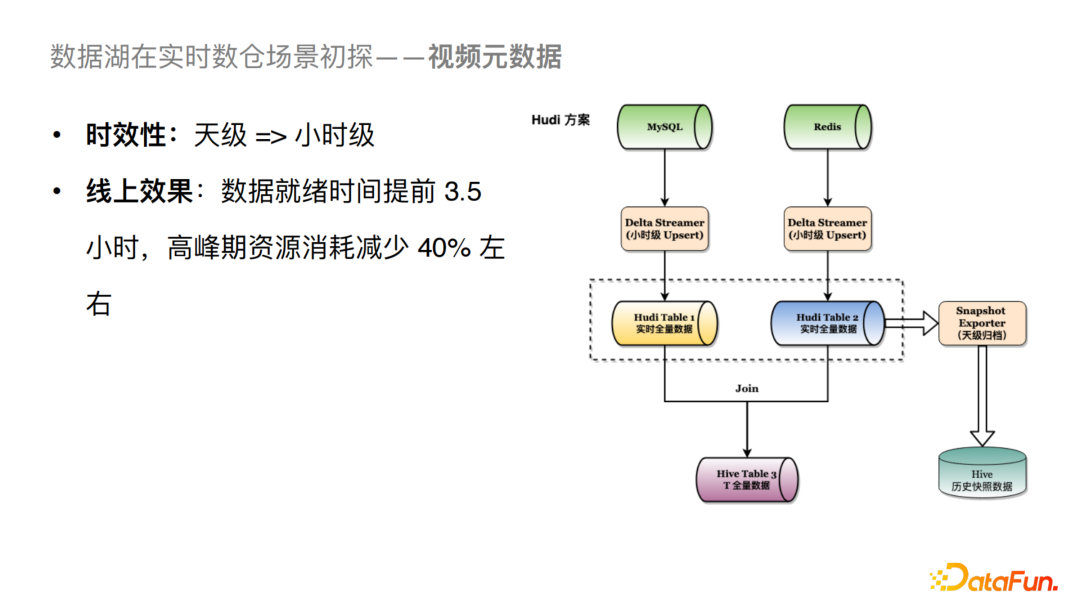
我們通過引入Hudi把天級的Dump分攤到每個小時進行Upsert。由于Hudi自身可以支持去重的邏輯,我們可以將Table 1看成一個實時的全量數(shù)據(jù),當小時級別(例如23點)的數(shù)據(jù)一旦Upsert完成之后,我們就可以直接進行下游的Join邏輯,這樣的話我們可以將數(shù)據(jù)的就緒時間提前3.5個小時左右,高峰期的資源消耗可以減少40%。
2、近實時數(shù)據(jù)校驗方案

對于實時場景來說,當實時任務進行一個比較頻繁的變更,比如優(yōu)化或者新增指標的改動,一般需要校驗實時任務的產(chǎn)出是否符合預期。我們當前的方案是會跑一個小時級別的Job,將一個小時的數(shù)據(jù)從Kafka Dump到Hive之后再校驗全量數(shù)據(jù)是否符合預期。在一些比較緊急的場景下,我們只能抽查部分數(shù)據(jù),這時候就對時效性的要求就比較高。在使用基于的Hudi 方案后,我們可以通過Flink將數(shù)據(jù)直接Upsert到Hudi表中,之后直接通過Presto查詢數(shù)據(jù)從而做到全量數(shù)據(jù)近實時的可見可測。從線上效果來看可以極大提高實時任務的開發(fā)效率,同時保證數(shù)據(jù)質(zhì)量。
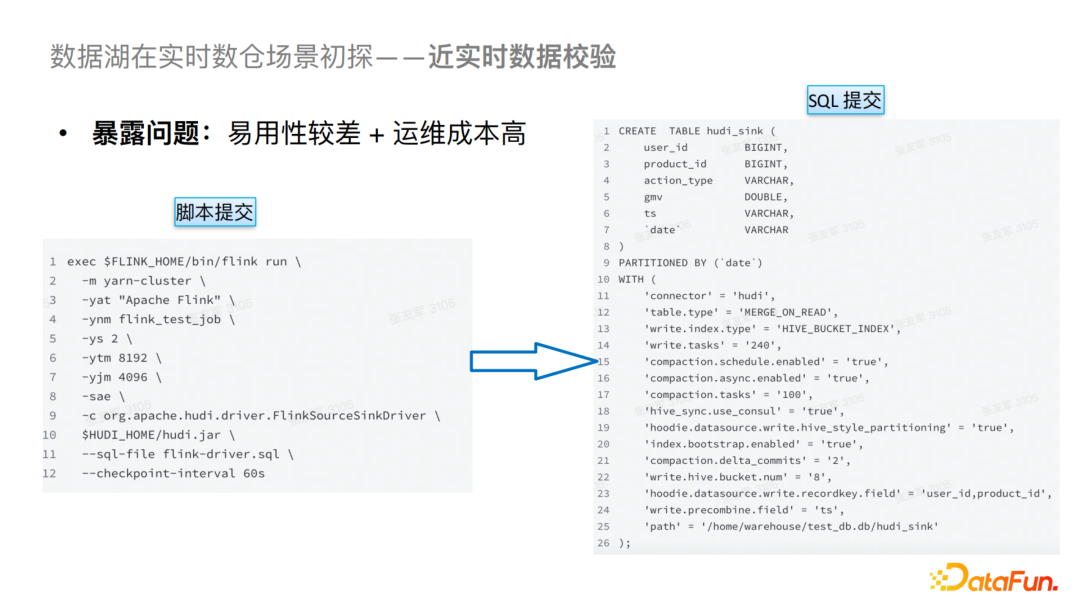
在以上探索過程中遇到了比較多的問題,第一個問題就是易用性比較差,運維成本和解釋成本比較高。對于易用性這一部分,我們起初是通過腳本來提交SQL,可以看到SQL中的參數(shù)是比較多的,并且包含DDL的Schema,這在當列數(shù)比較多的情況下是比較麻煩的,會導致易用性較差,并且對業(yè)務側(cè)來說也是不可接受的。
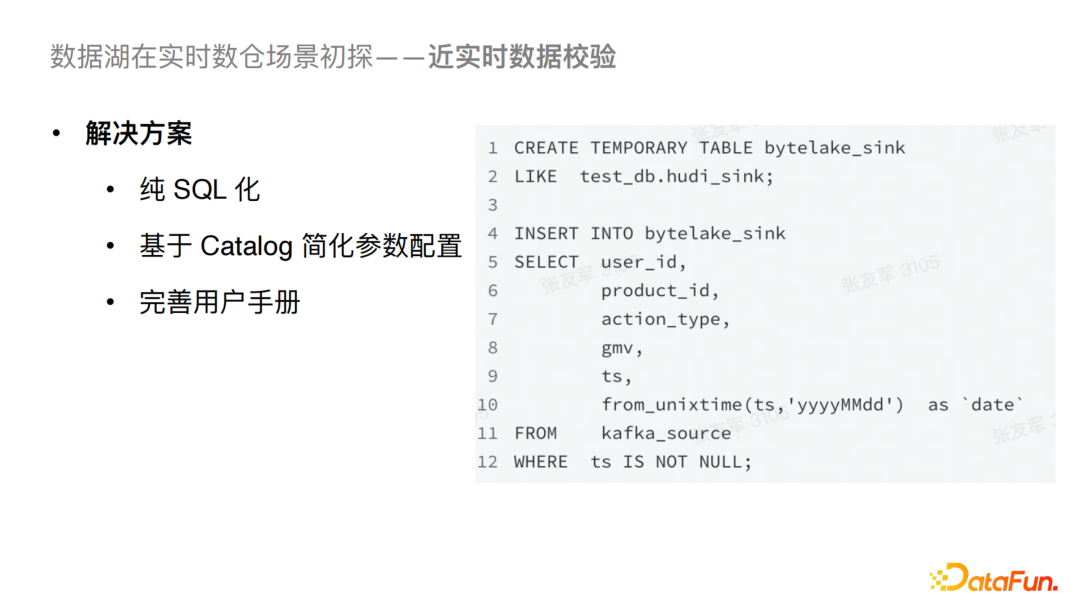
對于以上問題我們做了一個針對性的解決方案,首先我們對之前的任務提交方式替換為了純SQL化提交,并且通過接入統(tǒng)一的Catalog自動化讀取 Schema和必要參數(shù),入湖的SQL就可以簡化為如圖的形式。
三、典型場景實踐
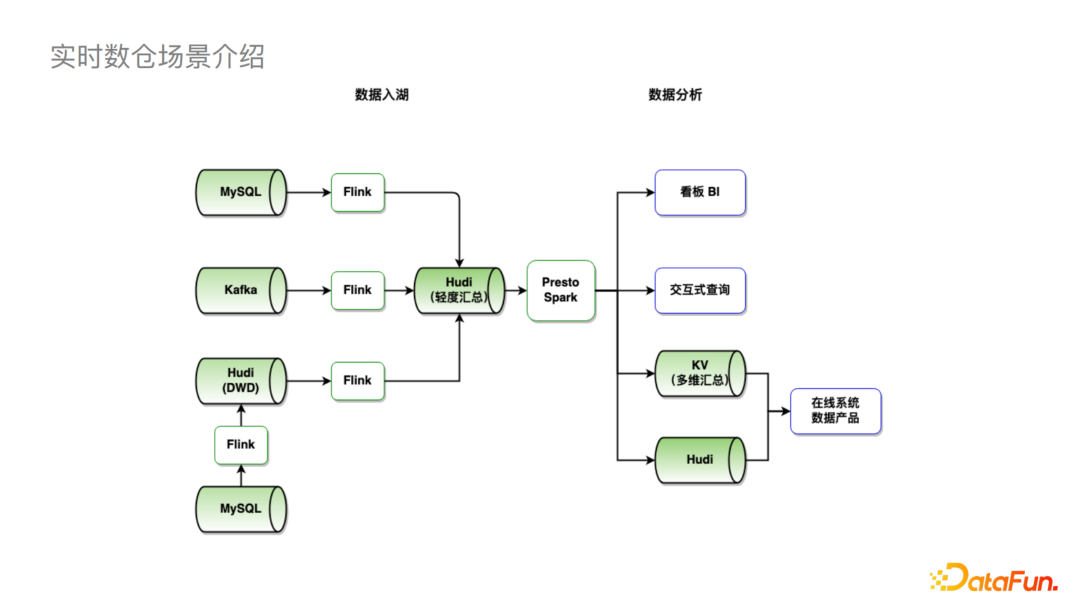
接下來讓我們看字節(jié)目前基于Hudi的實時數(shù)倉整體鏈路。
可以看到,我們支持數(shù)據(jù)的實時入湖,例如MySQL,Kafka通過Flink可以直接落到Hudi;也支持進行一定的湖內(nèi)計算,比如圖中左下將MySQL數(shù)據(jù)通過Flink導入Hudi進一步通過Flink做一些計算后再落到Hudi。在數(shù)據(jù)分析方面,我們可以使用Spark和Presto連接看板BI進行一些交互式查詢。當我們需要接到其他在線系統(tǒng),尤其是QPS較高的場景,我們會先接入到KV存儲,再接入業(yè)務系統(tǒng)。
讓我們來看具體場景。
1、實時多維匯總
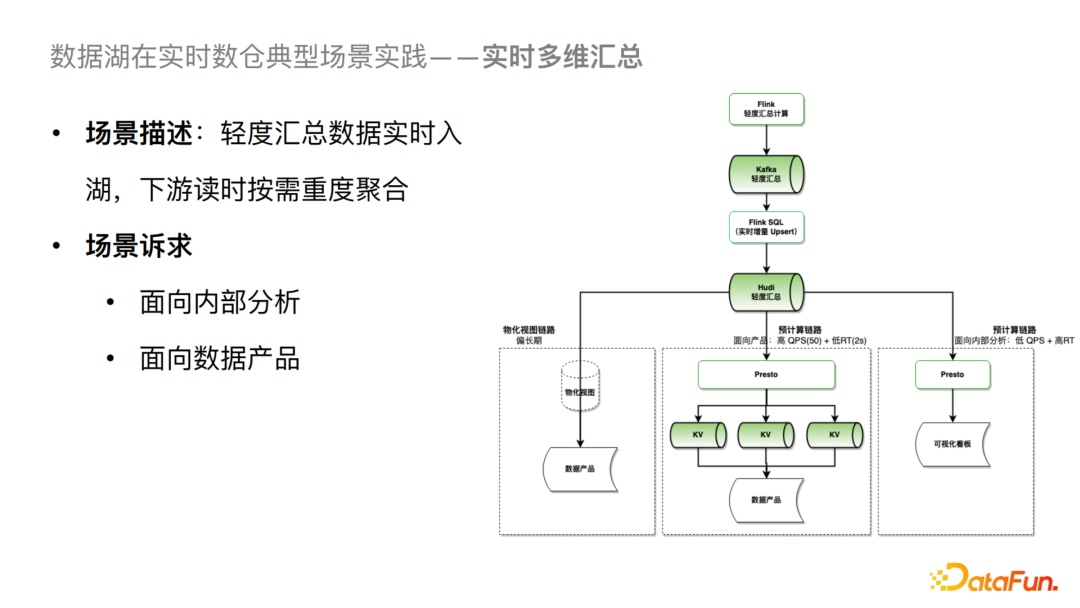
對于一個實時多維匯總的場景,我們可以把Kafka 數(shù)據(jù)增量寫入到 Hudi 的輕度匯總層中。對于分析場景,可以基于 Presto 按需進行多維度的重度匯總計算,并可以直接構(gòu)建對應的可視化看板。這個場景對QPS和延遲要求都不是很高,所以可以直接構(gòu)建,但是對于高 QPS 和低延遲訴求的數(shù)據(jù)產(chǎn)品場景,目前的一個解決方案是通過 Presto 進行多維度預計算,然后導入到 KV 系統(tǒng),進一步對接數(shù)據(jù)產(chǎn)品。從中長期來看我們會采取基于物化視圖的方式,這樣就可以進一步去簡化業(yè)務側(cè)的一些操作。

在以上鏈路中,我們也遇到了比較多的問題:
寫入穩(wěn)定性差。第一點就是Flink在入湖的過程中任務占用資源比較大,第二點是任務頻繁重啟很容易導致失敗,第三點是Compaction沒有辦法及時執(zhí)行從而影響到查詢。 更新性能差。會導致任務的反壓比較嚴重。 并發(fā)度難提升。會對Hudi Metastore Service(目前字節(jié)內(nèi)部自主研發(fā)的Hudi元數(shù)據(jù)服務,兼容Hive接口,準備貢獻到社區(qū))穩(wěn)定性產(chǎn)生比較大的影響。 查詢性能比較差。有十分鐘的延遲甚至經(jīng)常查詢失敗。
面對這些問題,我接下來簡單介紹一下針對性的一些解決方案:
1)寫入穩(wěn)定性治理
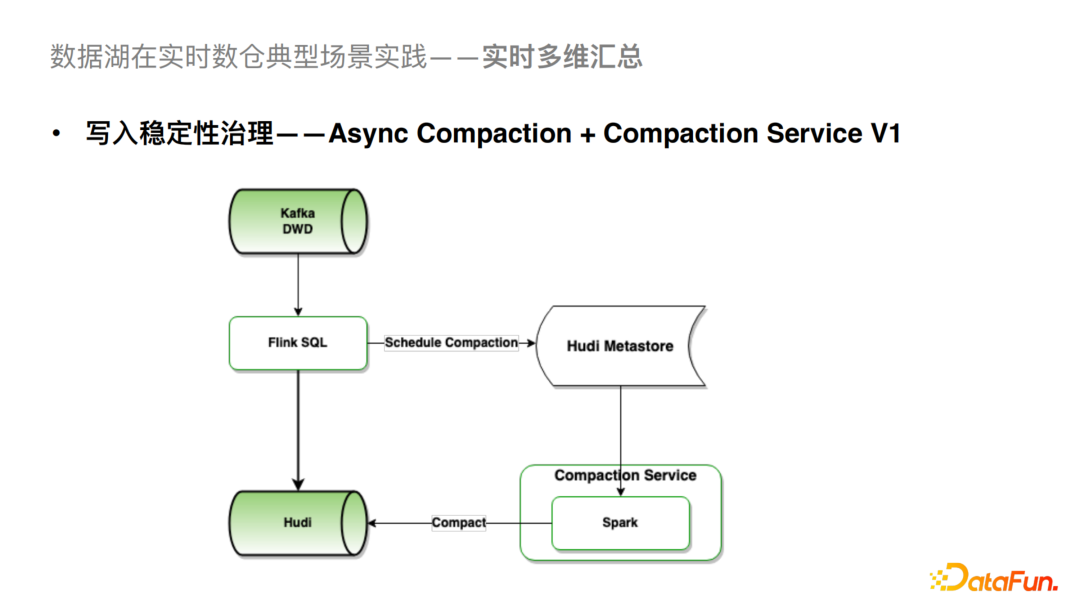
這一塊我們通過異步的Compaction + Compaction Service的方案去解決這個問題。我們之前Flink入湖默認是在Flink內(nèi)部去做Compaction,發(fā)現(xiàn)這一步是暴露以上一系列問題的關鍵。經(jīng)過優(yōu)化,F(xiàn)link入湖任務只負責增量數(shù)據(jù)的寫入,以及 Schedule Compaction邏輯,而Compaction執(zhí)行則由Compaction Service負責。具體而言,Compaction Service 會從Hudi Metastore異步拉取Pending Compaction Plan,并提交Spark批任務完成實際的Compact。Compaction執(zhí)行任務與Flink寫入任務完全異步隔離,從而對穩(wěn)定性有較大提升。
2)高效更新索引
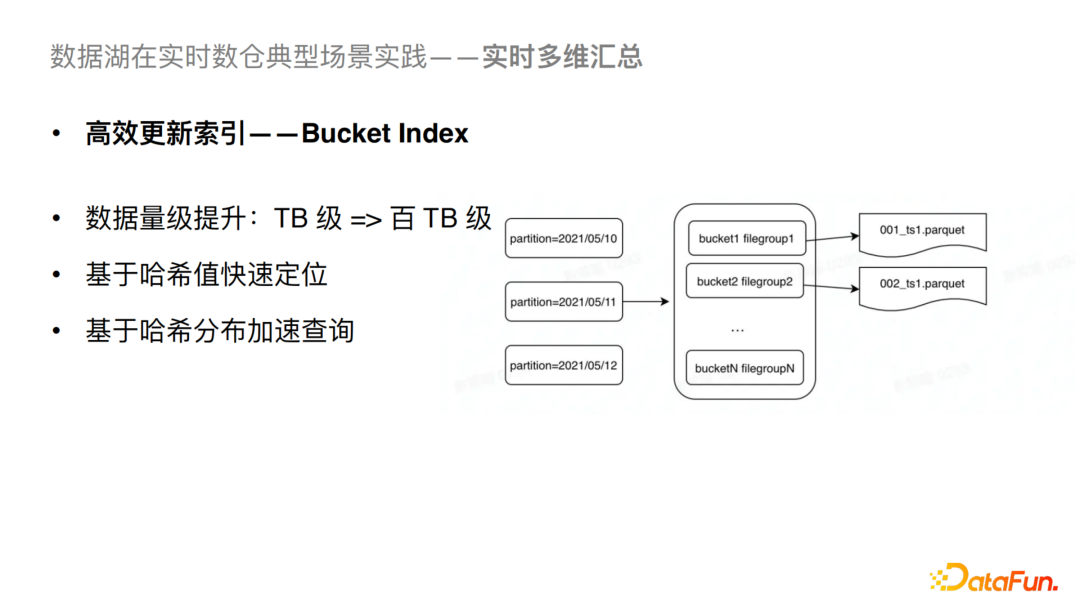
支持數(shù)據(jù)量級的大幅提升。簡單來說,我們可以基于哈希計算快速定位目標文件,提升寫入性能;同時可以進行哈希過濾,從而也可以進行查詢分析側(cè)的優(yōu)化。
3)請求模型的優(yōu)化
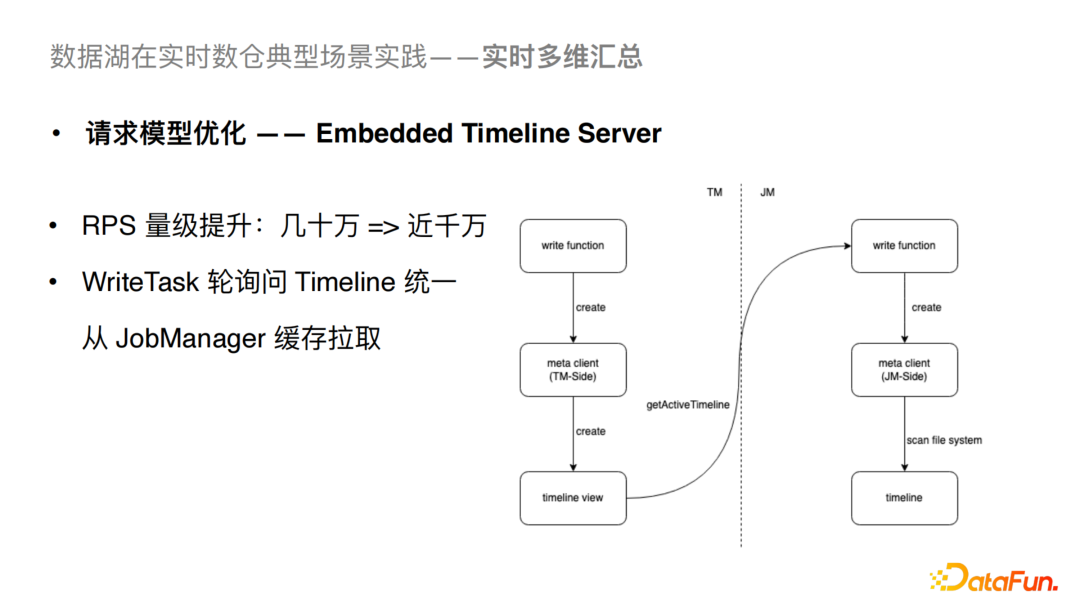
當前的Hudi社區(qū)版的WriteTask 會輪詢Timeline,導致持續(xù)訪問Hudi Metastore,從而造成拓展能力受限的問題。我們將WriteTask的輪詢請求從Hudi Metastore轉(zhuǎn)移到了對JobManager緩存的拉取,這樣就能大幅降低對Hudi Metastore的影響。經(jīng)過這個優(yōu)化可以讓我們從幾十萬量級的RPS(Request Per Sec)提升到近千萬的量級。
接下來我們來講一下查詢相關的優(yōu)化。
4)MergeOnRead列裁剪
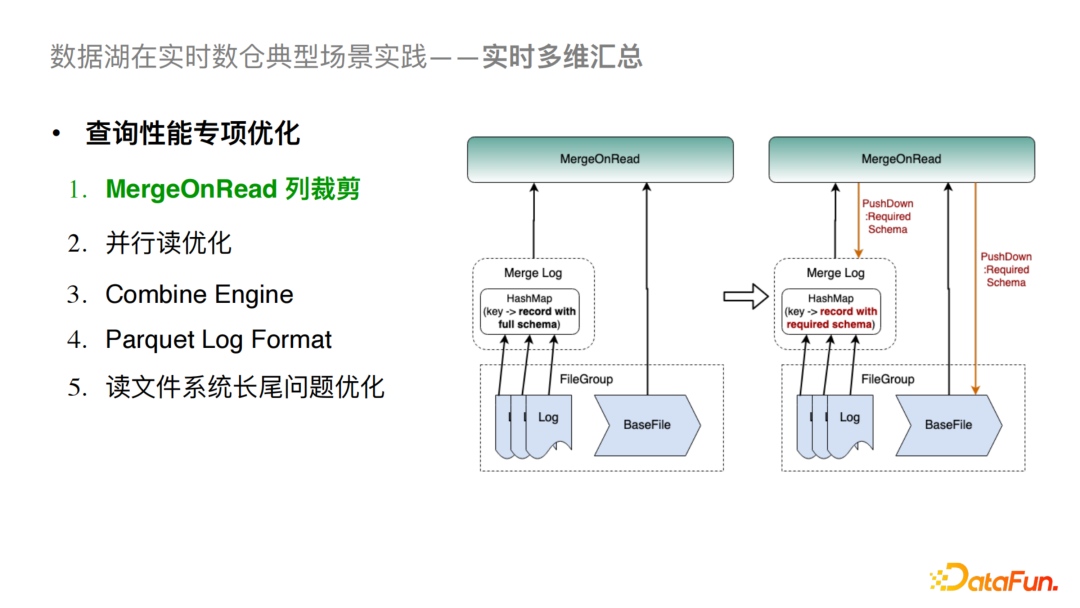
對于原生的MergeOnRead來說,我們會在全量讀取LogFile和BaseFile之后做合并,這在只查詢部分列的時候會造成性能損耗,尤其是列比較多的情況。我們所做的優(yōu)化是把列的讀取下推到Scan層,同時在進行l(wèi)og文件合并時,會使用map結(jié)構(gòu)存儲K,V(K是主鍵,V是行記錄),之后對行記錄做列裁剪,最后再進行Log Merge的操作。這樣會對序列化和反序列化開銷以及內(nèi)存使用率都有極大降低。
5)并行讀優(yōu)化
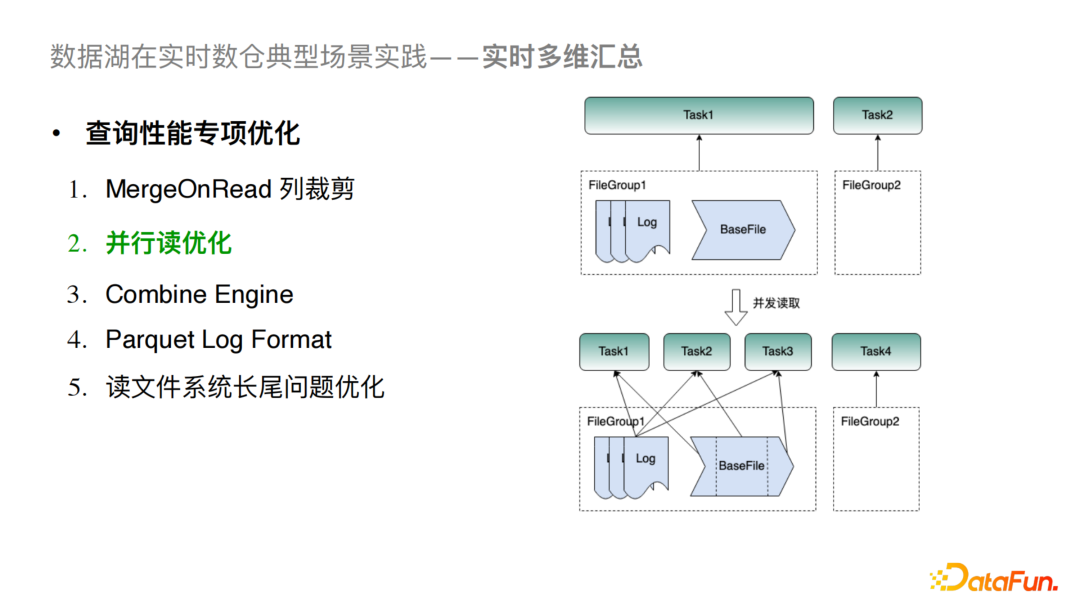
一般引擎層在讀Hudi時,一個Filegroup只對應一個Task,這樣當單個 FileGroup 數(shù)據(jù)量較大時就極易造成性能瓶頸。我們對此的優(yōu)化方案是對BaseFile進行切分,每個切分的文件對應一個Task從而提高讀并行度。
6)Combine Engine
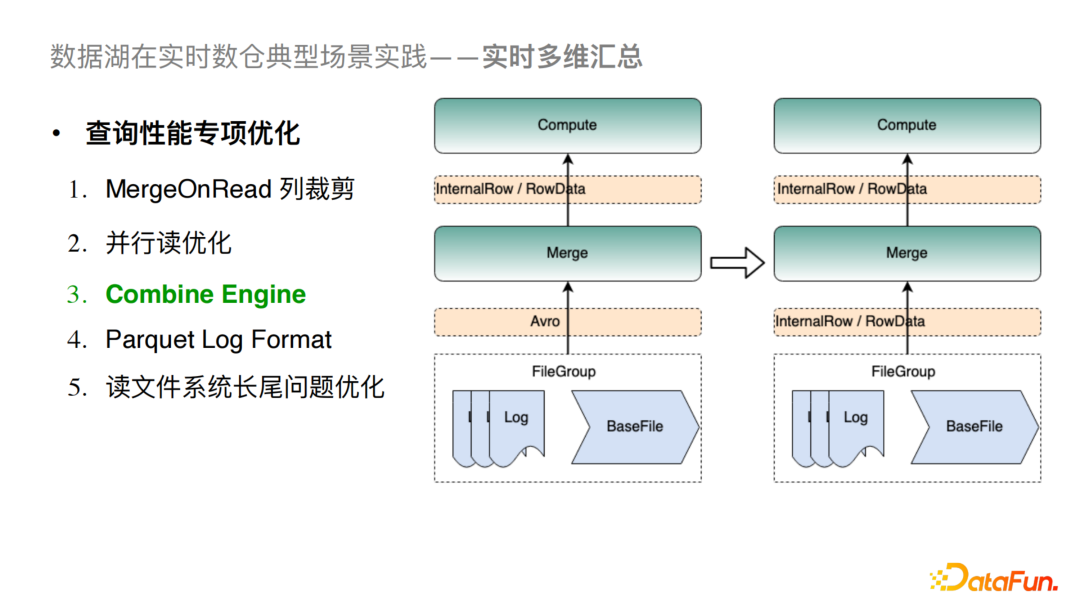
Hudi社區(qū)版目前在內(nèi)存中對數(shù)據(jù)的合并和傳輸?shù)膶崿F(xiàn)完全是基于Avro格式,這會造成與具體引擎對接時有大量的序列化與反序列化計算,從而導致比較大的性能問題。對于這個問題我們與社區(qū)合作做了Combine Engine的優(yōu)化,具體做法就是將接口深入到了引擎層的數(shù)據(jù)結(jié)構(gòu)。例如在讀取FileGroup時我們直接讀取的就是Spark的InternalRow或是Flink的RowData,從而盡量減少對Avro格式的依賴。這樣的優(yōu)化可以極大地提高MergeOnRead和Compaction的性能。
2、實時數(shù)據(jù)分析
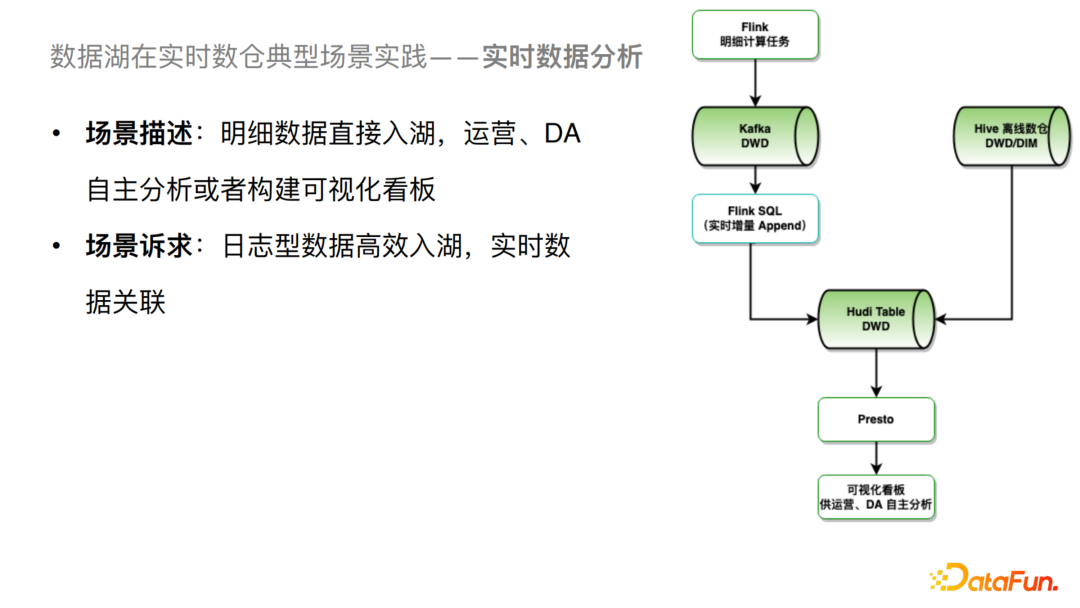
這個場景我們可以把明細數(shù)據(jù)直接通過Flink導入到Hudi中,還會根據(jù)DIM表做一個寬表的處理從而落到Hudi表。這個場景的訴求主要有兩點,一個是日志型數(shù)據(jù)的高效入湖,另一個是實時數(shù)據(jù)的關聯(lián)。對于這兩個場景的訴求,我們針對性的進行了一些優(yōu)化。
1)日志型數(shù)據(jù)高效入湖
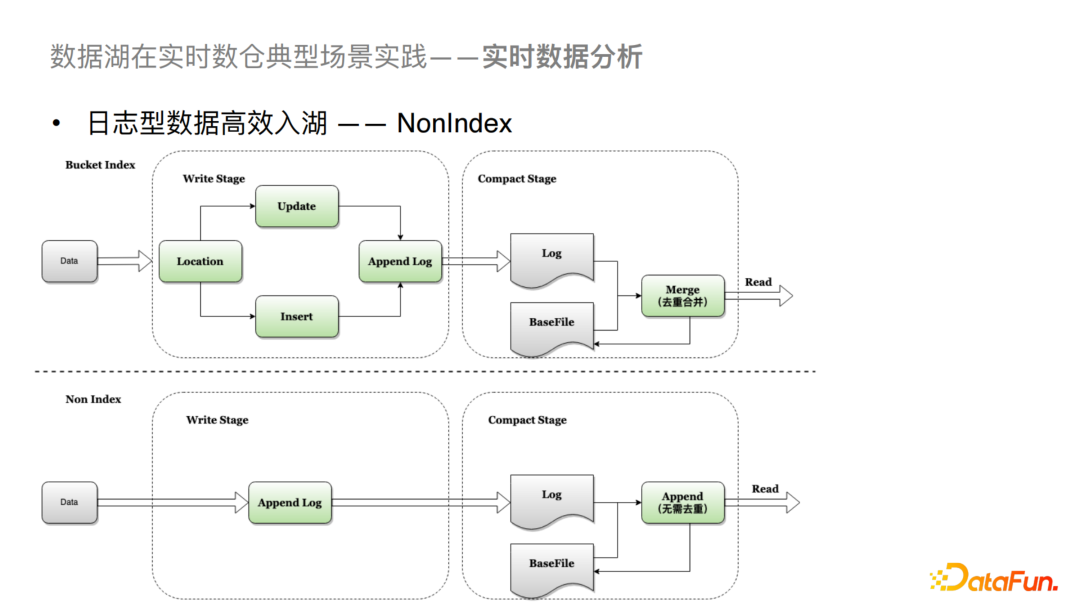
對于日志型數(shù)據(jù),我們支持了NonIndex的索引。Hudi社區(qū)版主要支持是基于有主鍵的索引,比如Bloom Filter或者是我們給社區(qū)提供的Bucket Index。生成基于主鍵的索引方式主要會有兩個步驟,第一個步驟是數(shù)據(jù)在寫進來的時候會先對數(shù)據(jù)做定位,查詢是否有歷史數(shù)據(jù)存在,如果有的話就Update,沒有的話就Insert,之后會定位到對應的文件把數(shù)據(jù)Append到Log中。然后在Merge或者在Compaction的過程中要在內(nèi)存中做合并與去重處理,這兩個操作也是比較耗時的。對于NonIndex來說,是不存在主鍵的概念的,所以支持的也是沒有主鍵的日志型數(shù)據(jù)入湖。這樣對于日志型數(shù)據(jù)在寫入時可以直接Append到Log File中,在合并的過程中,我們可以不做去重處理,直接將增量數(shù)據(jù)數(shù)據(jù)Append到Base File中。這樣就對入湖的效率有了很大的提升。
2)實時數(shù)據(jù)關聯(lián)

針對目前實時Join出現(xiàn)的一系列問題,我們基于Hudi支持了存儲層的關聯(lián)。對Hudi來說不同的流可以完成其所對應列的寫入,并在Merge的時候做拼接,這樣對于外界查詢來說就是一個完整的寬表。具體來說,在實時數(shù)據(jù)寫入的過程中有一個比較大的問題是怎么處理多個流的寫入沖突問題。我們主要是基于Hudi Metastore來做沖突檢測。
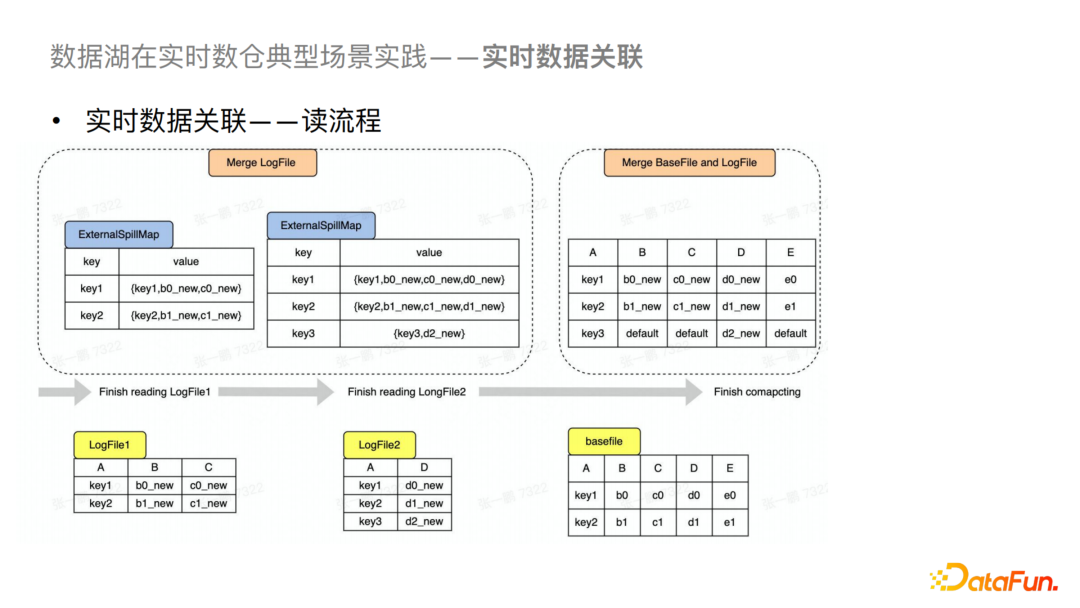
對于讀的流程,我們會先將多個LogFile讀入內(nèi)存進行Merge,然后再與BaseFile進行最終Merge,最后輸出查詢結(jié)果,Merge和Compaction都會使用到這個優(yōu)化。
四、未來規(guī)劃
1、彈性可擴展的索引系統(tǒng)
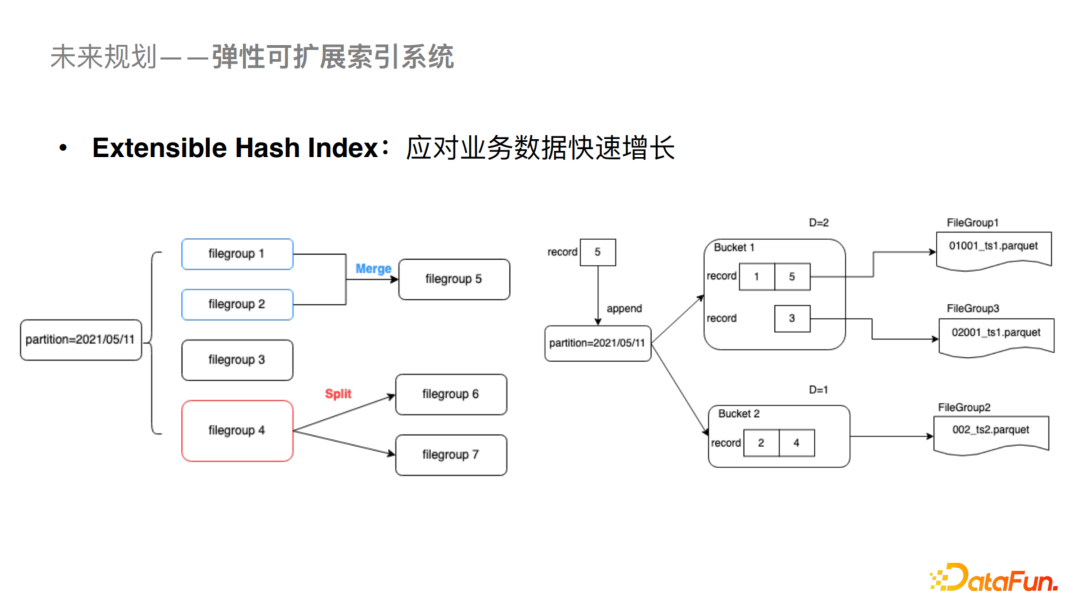
我們剛剛介紹了Bucket Index支持大數(shù)據(jù)量場景下的更新,Bucket Index也可以對數(shù)據(jù)進行分桶存儲,但是對于桶數(shù)的計算是需要根據(jù)當前數(shù)據(jù)量的大小進行評估的,如果后續(xù)需要re-hash的話成本也會比較高。在這里我們預計通過建立Extensible Hash Index來提高哈希索引的可擴展能力。
2、自適應的表優(yōu)化服務
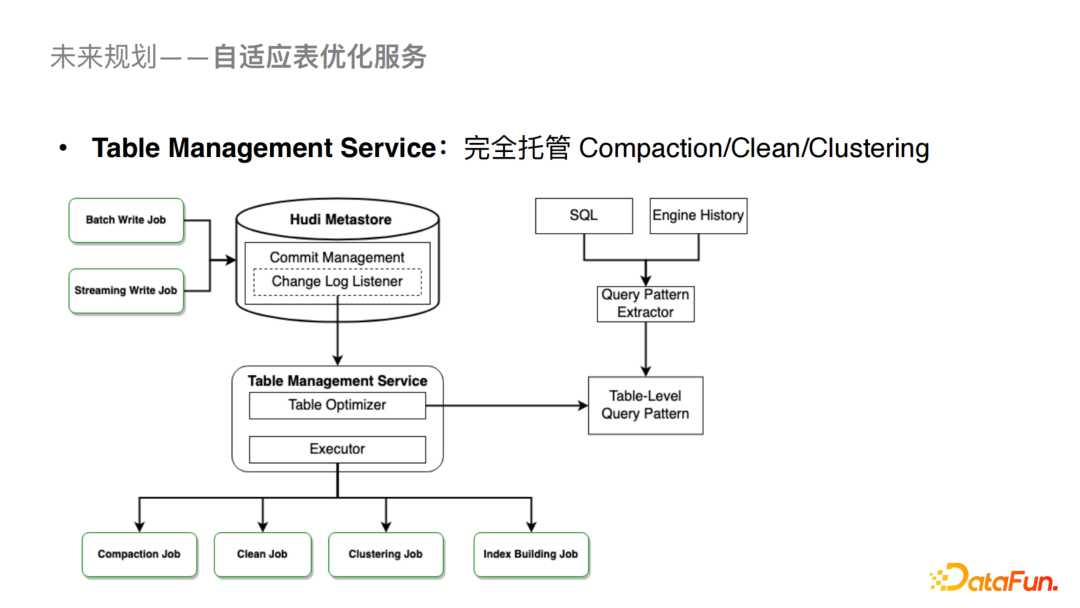
為了降低用戶的理解和使用成本,我們會與社區(qū)深度合作推出Table Management Service來托管Compaction,Clean,Clustering以及Index Building的作業(yè)。這樣對用戶來說相關的優(yōu)化都是透明的,從而降低用戶的使用成本。
3、元數(shù)據(jù)服務增強

目前我們內(nèi)部已經(jīng)使用Hudi Metastore穩(wěn)定支持了一些線上業(yè)務,但是也有更多需求隨之而來,預計增強的元數(shù)據(jù)服務如下:
Schema Evolution:支持業(yè)務對Hudi Schema變更的訴求。 Concurrency Control:在Hudi Metastore中支持批流并發(fā)寫入。
4、批流一體
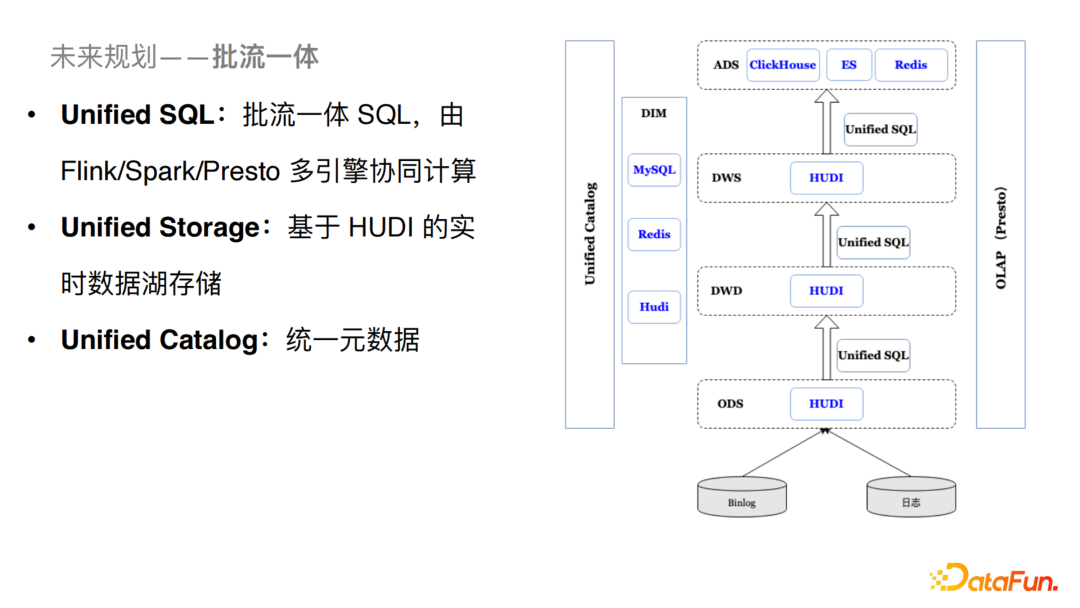
對于流批一體處理,我們的規(guī)劃如下:
Unified SQL:做到批流統(tǒng)一的SQL層,Runtime由Flink/Spark/Presto多引擎協(xié)同計算。 Unified Storage:基于Hudi的實時數(shù)據(jù)湖存儲,由Hudi來做統(tǒng)一的存儲。 Unified Catalog:統(tǒng)一元數(shù)據(jù)的構(gòu)建以及接入。
