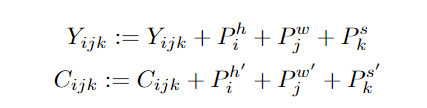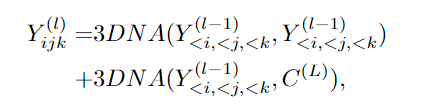↓↓↓點擊關注,回復資料,10個G的驚喜
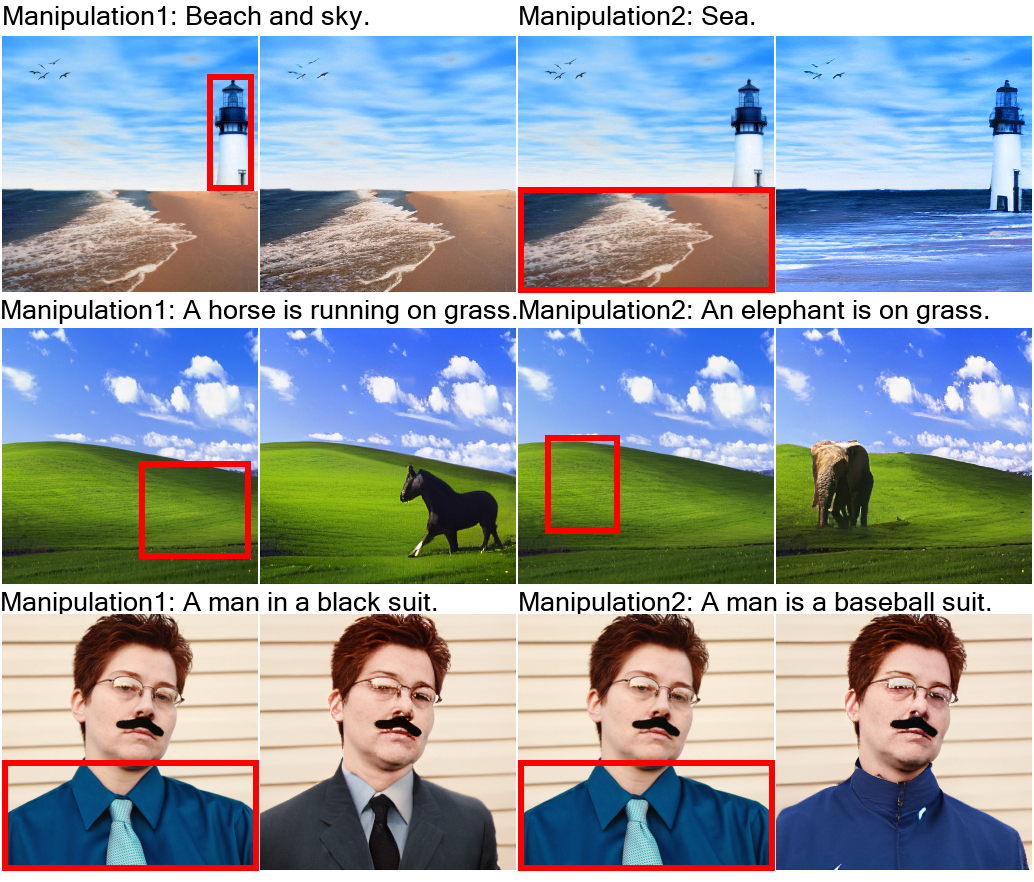
在幾年前,要說 AI 能直接用一段文字描述生成清晰的圖像,那可真是天方夜譚。結果現(xiàn)在,Transformer 的出現(xiàn)徹底帶火了「多模態(tài)」這一領域。更夸張的是,竟然有 AI 已經(jīng)可以用文字描述去生成一段視頻了,看上去還挺像模像樣的。這個 AI 不僅看文字描述可以生成視頻,給它幾幅草圖,一樣能「腦補」出視頻來!答案是微軟亞洲研究院 + 北京大學強強聯(lián)合的研究團隊!前腳剛推出取得了 40 多個新 SOTA 的 Florence「佛羅倫薩」吊打 CLIP,橫掃 40 多個 SOTA。后腳就跟著放出 NüWA「女媧」對標 DALL-E。今年 1 月,OpenAI 官宣了 120 億參數(shù)的 GPT-3 變體 DALL-E。論文地址:https://arxiv.org/pdf/2102.12092.pdfDALL-E 會同時接收文本和圖像作為單一數(shù)據(jù)流,其中包含多達 1280 個 token,并使用最大似然估計來進行訓練,以一個接一個地生成所有的 token。這個訓練過程讓 DALL-E 不僅可以從頭開始生成圖像,而且還可以重新生成現(xiàn)有圖像的任何矩形區(qū)域,與文本提示內(nèi)容基本一致。從文本「一個穿著芭蕾舞裙遛狗的蘿卜寶寶」生成的圖像示例同時,DALL-E 也有能力對生成的圖像中的物體進行操作和重新排列,從而創(chuàng)造出一些根本不存在的東西,比如一個「一個長頸鹿烏龜」:這次,MSRA 和北大聯(lián)合團隊提出的統(tǒng)一多模態(tài)預訓練模型 ——NüWA(女媧),則可以為各種視覺合成任務生成新的或編輯現(xiàn)有的圖像和視頻數(shù)據(jù)。論文地址:https://arxiv.org/pdf/2111.12417.pdfGitHub 地址:https://github.com/microsoft/NUWA為了在不同場景下同時覆蓋語言、圖像和視頻,團隊設計了一個三維變換器編碼器 - 解碼器框架,它不僅可以處理作為三維數(shù)據(jù)的視頻,還可以適應分別作為一維和二維數(shù)據(jù)的文本和圖像。此外,論文還提出了一個 3D 鄰近注意(3DNA)機制,以考慮視覺數(shù)據(jù)的性質(zhì)并降低計算的復雜性。在 8 個下游任務中,NüWA 在文本到圖像生成、文本到視頻生成、視頻預測等方面取得了新的 SOTA。其中,在文本到圖像生成中的表現(xiàn)直接超越 DALL-E。同時,NüWA 在文本引導的圖像和視頻編輯任務中顯示出優(yōu)秀的 zero-shot 能力。草圖轉圖像(SKetch-to-Image,S2I)
圖像補全(Image Completion,I2I)
用文字指示修改圖像(Text-Guided Image Manipulation,TI2I)
視頻預測(Video Prediction,V2V)
草圖轉視頻(Sketch-to-Video,S2V)
用文字指示修改視頻(Text-Guided Video Manipulation,TV2V)
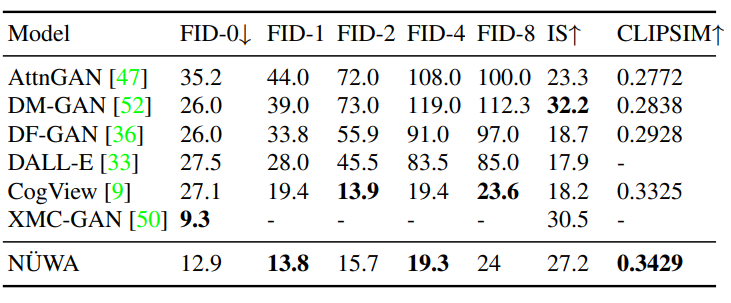
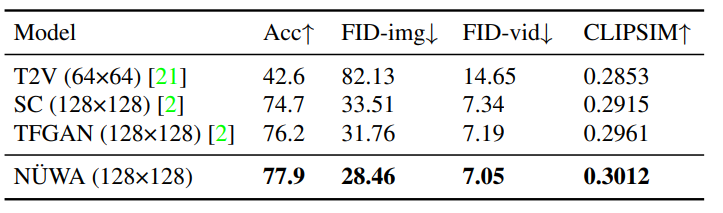
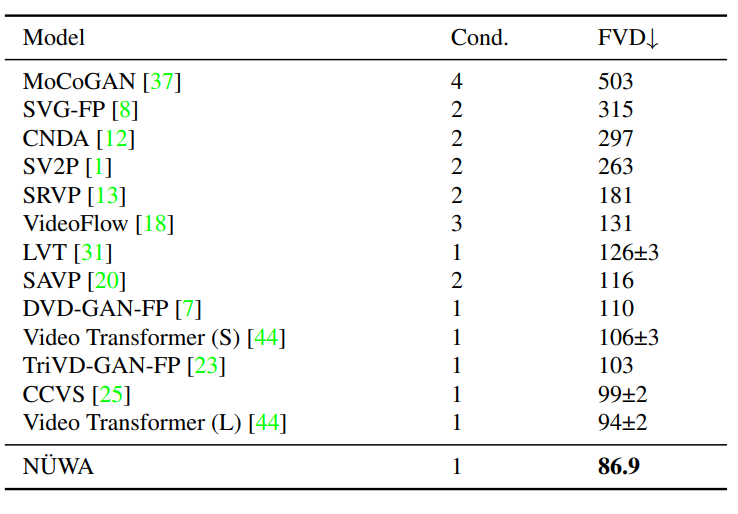
NüWA 模型的整體架構包含一個支持多種條件的 adaptive 編碼器和一個預訓練的解碼器,能夠同時使圖像和視頻的信息。對于圖像補全、視頻預測、圖像處理和視頻處理任務,將輸入的部分圖像或視頻直接送入解碼器即可。模型支持所有文本、圖像、視頻輸入,并將他們統(tǒng)一視作 token 輸入,所以可以定義一個統(tǒng)一的向量表示 X,維度包括高度 h、寬度 w,時間軸上的 token 數(shù)量 s,每個 token 的維度 d。文本天然就是離散的,所以使用小寫后的 byte pair encoding (BPE)來分詞,最終的維度為 1×1×s×d 中。因為文本沒有空間維度,所以高度和寬度都為 1。圖像輸入是連續(xù)的像素。每個圖像輸入的高度為 h、寬度為 w 和通道數(shù)為 c。使用 VQ-VAE 訓練一個編碼把原始連續(xù)像素轉換為離散的 token,訓練后 B [z] 的維度為 h×w×1×d 作為圖像的表示,其中 1 代表圖像沒有時序維度。視頻可以被視為圖像的一種時序展開,最近一些研究如 VideoGPT 和 VideoGen 將 VQ-VAE 編碼器中的卷積從 2D 擴展到 3D,并能夠訓練一種針對視頻輸入的特殊表征。?但這種方法無法使圖像和視頻的表示統(tǒng)一起來。研究人員證明了僅使用 2D VQ-GAN 就能夠編碼視頻中的每一幀,并且能生成時序一致的視頻,結果表示維度為 h×w×s×d,其中 s 代表視頻的幀數(shù)。對于圖像素描(image sketch)來說,可以將其視為具有特殊通道的圖像。H×W 的圖像分割矩陣中每個值代表像素的類別,如果以 one-hot 編碼后維度為 H×W×C,其中 c 是分割類別的數(shù)目。通過對圖像素描進行額外的 VQ-GAN 訓練,最終得到圖像 embedding 表示維度為 h×w×1×d。同樣地,對于視頻草圖的 embedding 維度為 h×w×s×d。基于統(tǒng)一的 3D 表示,文中還提出一種新的注意力機制 3D Nearby Self-Attention (3DNA)?,能夠同時支持 self-attention 和 cross-attention。3DNA 考慮了完整的鄰近信息,并為每個 token 動態(tài)生成三維鄰近注意塊。注意力矩陣還顯示出 3DNA 的關注部分(藍色)比三維塊稀疏注意力和三維軸稀疏注意力更平滑。基于 3DNA,文中還引入了 3D encoder-decoder,能夠在條件矩陣 Y 為 h'×w'×s'×d^{in} 的情況下,生成 h×w×s×d^{out} 的目標矩陣 C,其中 Y 和 C 由三個不同的詞典分別考慮高度,寬度和時序維度。然后將條件 C 和一個堆疊的 3DNA 層輸入到編碼器中來建模自注意力的交互。解碼器也是由 3DNA 層堆疊得到,能夠同時計算生成結果的 self-attention 和生成結果與條件之間的 cross-attention。最終的訓練包含了三個目標任務 Text-to-Image(T2I), Video Prediction (V2V)?和 Text-to-Video(T2V),所以目標函數(shù)包含三部分。對于 T2I 和 T2V 任務,C^text 表示文本條件。對于 V2V 任務,由于沒有文本輸入,所以 c 為一個常量,單詞 None 的 3D 表示,θ 表示模型參數(shù)。作者使用 FID-k 和 Inception Score(IS)來分別評估質(zhì)量和種類,并使用結合了 CLIP 模型來計算語義相似度的 CLIPSIM 指標。公平起見,所有的模型都使用 256×256 的分辨率,每個文本會生成 60 張圖像,并通過 CLIP 選擇最好的一張。可以看到,NüWA 以 12.9 的 FID-0 和 0.3429 的 CLIPSIM 成績,明顯地優(yōu)于 CogView。在 MSCOCO(256×256)數(shù)據(jù)集上與 SOTA 的定量比較盡管 XMC-GAN 的 FID 分數(shù)為 9.3,但與 XMC-GAN 的論文中完全相同的樣本相比,NüWA 生成的圖像更加真實。特別是在右下角的那個例子中,男孩的臉更清晰,氣球也是正確的。在 MSCOCO(256×256)數(shù)據(jù)集上與 SOTA 的定性比較作者在 Kinetics 數(shù)據(jù)集上與現(xiàn)有的 SOTA 進行了比較,其中,在 FID-img 和 FID-vid 指標上評估視覺質(zhì)量,在生成視頻的標簽準確性上評估語義一致性。顯然,NüWA 在上述所有指標上都取得了 SOTA。在 Kinetics 數(shù)據(jù)集上與 SOTA 的定量比較此外,對于生成未見過的文本來說,NüWA 在定性比較中顯示出了強大的 zero-shot 能力,如「在游泳池打高爾夫球」以及「在海上跑步」。在 Kinetics 數(shù)據(jù)集上與 SOTA 的定性比較作者定性地比較了 NüWA 的 zero-shot 圖像補全能力。在只有塔的上半部分的情況下,與 Taming Transformers 相比,NüWA 在對塔的下半部分進行補全時,展現(xiàn)出更豐富的想象力,自主添加了建筑、湖泊、鮮花、草地、樹木、山脈等等。以 zero-shot 方式與現(xiàn)有 SOTA 進行定性比較作者在 BAIR 數(shù)據(jù)集上進行了定量比較,其中,Cond. 表示預測未來幀的幀數(shù)。為了進行公平的比較,所有的模型都使用 64×64 的分辨率。盡管只給了一幀作為條件(Cond.),NüWA 仍將 FVD 的 SOTA 得分從 94±2 推至 86.9。在 BAIR(64×64)數(shù)據(jù)集上與 SOTA 的定量比較通過定性比較在 MSCOCO 上的表現(xiàn)可以看到,與 Taming-Transformers 和 SPADE 相比,NüWA 生成的圖像種類更多,有的甚至連窗戶上的反射也清晰可見。在 MSCOCO 數(shù)據(jù)集上與 SOTA 的定性比較作者以 zero-shot 的方式對 NüWA 和現(xiàn)有 SOTA 進行了定性的比較。與 Paint By Word 相比,NüWA 表現(xiàn)出了很強的編輯能力,在不改變圖像其他部分的情況下,產(chǎn)生了高質(zhì)量的結果。這得益于通過對各種視覺任務進行多任務預訓練而學到的真實世界的視覺模式。比如在第三個例子中,由 NüWA 生成的藍色卡車更加逼真,而且后方的建筑物也沒有產(chǎn)生奇怪的變化。另一個優(yōu)點是 NüWA 的推理速度,只需要 50 秒就能生成一幅圖像,而 Paint By Words 在推理過程中需要額外的訓練,并需要大約 300 秒才能收斂。以 zero-shot 方式與現(xiàn)有 SOTA 進行定性比較文章提出了一種統(tǒng)一的預訓練模型 NüWA,這個女媧不光能補天,也能造圖,可以為 8 個視覺合成任務生成新的或操作現(xiàn)有的圖像和視頻。還提出了一個通用的 3D encoder-decoder 框架,能夠同時覆蓋文本、圖像和視頻。能同時考慮空間和時序維度的 3D nearby-sparse attention 機制。這也是邁向人工智能平臺的重要一步,能夠讓計算機擁有視覺,并輔助內(nèi)容創(chuàng)作者生成一些人類想象力以外的事。
參考資料:
https://arxiv.org/abs/2111.12417
https://github.com/microsoft/NUWA