
MySQL 索引優(yōu)化全攻略(文末送書)
你知道的越多,不知道的就越多,業(yè)余的像一棵小草!
你來,我們一起精進(jìn)!你不來,我和你的競(jìng)爭(zhēng)對(duì)手一起精進(jìn)!
編輯:業(yè)余草
來源:juejin.cn/post/7161964571853815822
推薦:https://www.xttblog.com/?p=5357
自律才能自由

每一次寫博客我都會(huì)對(duì)技術(shù)都會(huì)有更深入的理解。積少成多,潛移默化的提升。我也希望各位網(wǎng)友能自己搞一個(gè)百天計(jì)劃,試試連續(xù)百天的看我博客,能有多少成長(zhǎng)!
前言
SQL 寫不好,加班肯定少不了。日常工作中 SQL 是必不可少的一項(xiàng)技術(shù),但是很多人不會(huì)過多的去關(guān)注SQL 問題,一是數(shù)據(jù)量小;二是沒有意識(shí)到索引的重要性。本文主要是整理 SQL 失效場(chǎng)景,如果里面的細(xì)節(jié)你都知道,那你一定是學(xué)習(xí)能力比較好的人。膜拜!寫完這篇文章,我感覺自己之前知道的真的是 “目錄”,沒有明白其中的內(nèi)容,如果你能跟著節(jié)奏看完文章,一定會(huì)有收獲。至少我寫完感覺思維通透很多,以后百分之九十的 SQl 索引問題和面試這方面問題都能拿捏。
文章概要
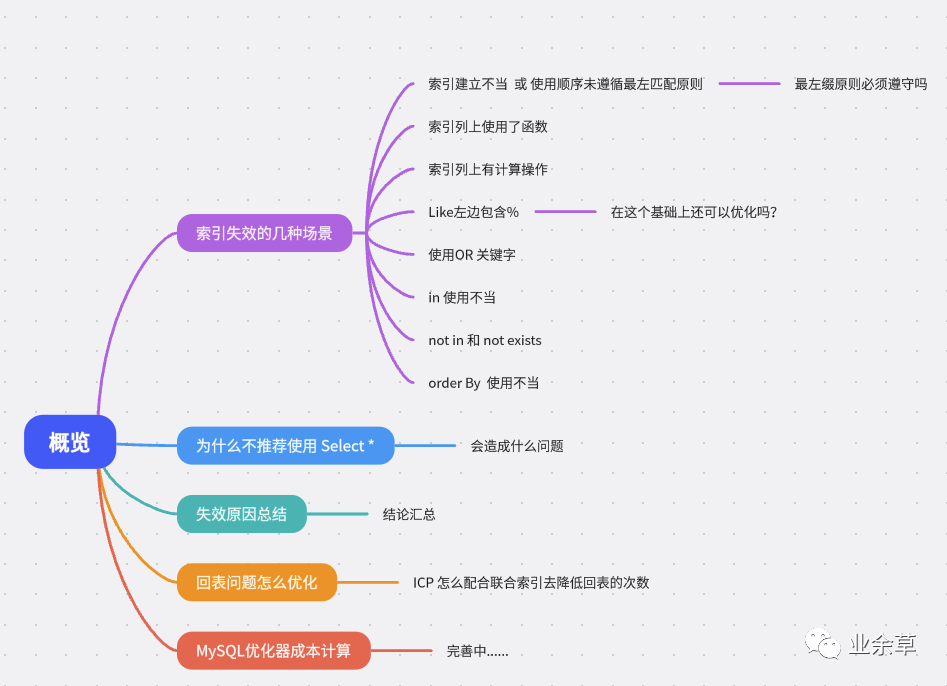
基礎(chǔ)數(shù)據(jù)準(zhǔn)備
準(zhǔn)備一個(gè)數(shù)據(jù)表作為 數(shù)據(jù)演示 這里面一共 創(chuàng)建了三個(gè)索引
聯(lián)合索引 sname,s_code,address主鍵索引 id普通索引 height
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for student
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`sname` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`s_code` int(100) NULL DEFAULT NULL,
`address` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`height` double NULL DEFAULT NULL,
`classid` int(11) NULL DEFAULT NULL,
`create_time` datetime(0) NOT NULL ON UPDATE CURRENT_TIMESTAMP(0),
PRIMARY KEY (`id`) USING BTREE,
INDEX `普通索引`(`height`) USING BTREE,
INDEX `聯(lián)合索引`(`sname`, `s_code`, `address`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (1, '學(xué)生1', 1, '上海', 170, 1, '2022-11-02 20:44:14');
INSERT INTO `student` VALUES (2, '學(xué)生2', 2, '北京', 180, 2, '2022-11-02 20:44:16');
INSERT INTO `student` VALUES (3, '變成派大星', 3, '京東', 185, 3, '2022-11-02 20:44:19');
INSERT INTO `student` VALUES (4, '學(xué)生4', 4, '聯(lián)通', 190, 4, '2022-11-02 20:44:25');
問題思考
上面的 SQL 我們已經(jīng)創(chuàng)建好基本的數(shù)據(jù)。在驗(yàn)證之前,先帶著幾個(gè)問題。
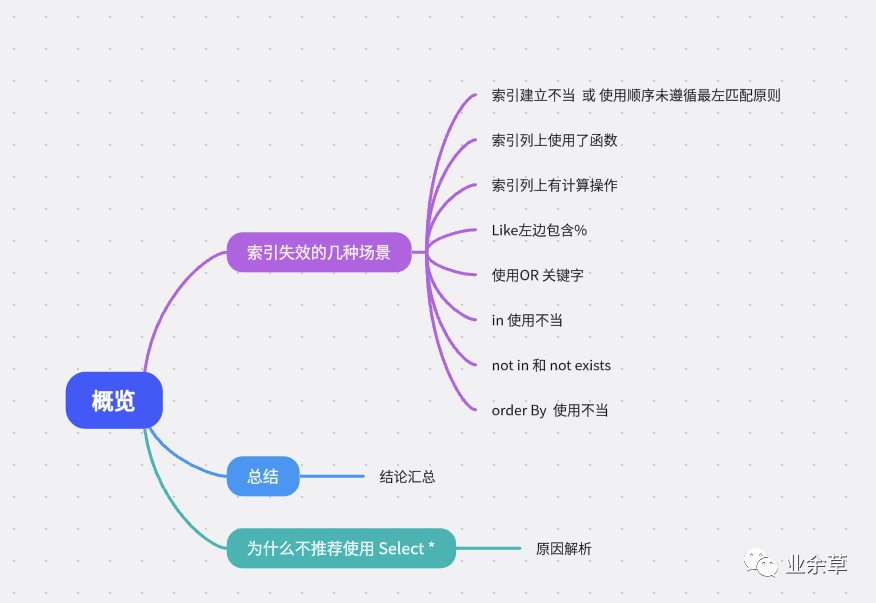
我們先從上往下進(jìn)行驗(yàn)證。
最左匹配原則
很多人很早之前可能就聽說過數(shù)據(jù)庫(kù)的最左匹配原則,但是多數(shù)人對(duì)最左匹配原則的局限性在于它們對(duì)最左匹配原則的描述就像一些數(shù)學(xué)定義一樣,往往都是列出 123 點(diǎn),滿足這 123 點(diǎn)就能匹配上索引,否則就不能。
最左匹配原則就是指在聯(lián)合索引中,如果你的 SQL 語句中用到了聯(lián)合索引中的最左邊的索引,那么這條 SQL 語句就可以利用這個(gè)聯(lián)合索引去進(jìn)行匹配,我們上面建立了聯(lián)合索引就可以用來測(cè)試最左匹配原則 sname, s_code, address。
請(qǐng)看下面 SQL 語句,請(qǐng)進(jìn)行思考,是否會(huì)走索引?
-- 聯(lián)合索引 sname,s_code,address
1、select create_time from student where sname = "變成派大星" -- 會(huì)走索引嗎?
2、select create_time from student where s_code = 1 -- 會(huì)走索引嗎?
3、select create_time from student where address = "上海" -- 會(huì)走索引嗎?
4、select create_time from student where address = "上海" and s_code = 1 -- 會(huì)走索引嗎?
5、select create_time from student where address = "上海" and sname = "變成派大星" -- 會(huì)走索引嗎?
6、select create_time from student where sname = "變成派大星" and address = "上海" -- 會(huì)走索引嗎?
7、select create_time from student where sname = "變成派大星" and s_code = 1 and address = "上海" -- 會(huì)走索引嗎?
憑你的經(jīng)驗(yàn),哪些會(huì)使用到索引呢?可以先思考一下,在心中記下數(shù)字。

「走索引例子」
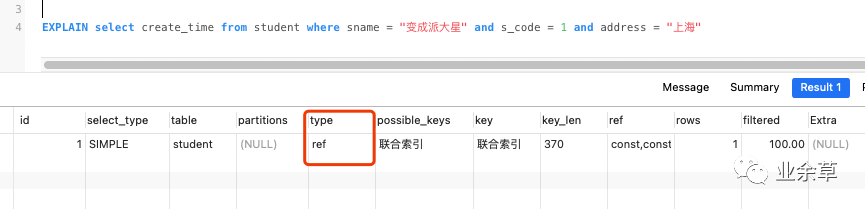
EXPLAIN select create_time from student where sname = "變成派大星" -- 會(huì)走索引嗎?

「未走索引例子」
EXPLAIN select create_time from student where address = "上海" and s_code = 1 -- 會(huì)走索引嗎?
走的全表掃描 rows = 4。

如果不知道EXPLAIN 是什么的,或者看不懂分析出來的數(shù)據(jù)的話,建議去看看我其他的文章。
如果你內(nèi)心的答案沒有全部說對(duì),那就繼續(xù)接著往下看。
最左匹配原則顧名思義:最左優(yōu)先,以最左邊的為起點(diǎn)任何連續(xù)的索引都能匹配上。「同時(shí)遇到范圍查詢(>、<、between、like)就會(huì)停止匹配」。
例如:s_code = 2如果建立(sname, s_code)順序的索引,是匹配不到(sname, s_code)索引的。
但是如果查詢條件是sname = "變成派大星" and s_code = 2或者a=1(又或者是s_code = 2 and sname = "變成派大星")就可以,「因?yàn)閮?yōu)化器會(huì)自動(dòng)調(diào)整sname, s_code的順序」。再比如sname = "變成派大星" and s_code > 1 and address = "上海"。address是用不到索引的,因?yàn)?s_code 字段是一個(gè)范圍查詢,它之后的字段會(huì)停止匹配。
不帶范圍查詢,索引使用類型。
帶范圍使用類型。

ref 和 range 的含義,級(jí)別還是相差很多的。

思考
為什么左鏈接一定要遵循最左綴原則呢?
驗(yàn)證
看過一個(gè)比較好玩的回答
?你可以認(rèn)為聯(lián)合索引是闖關(guān)游戲的設(shè)計(jì)
?
例如你這個(gè)聯(lián)合索引是 state/city/zipCode
那么 state 就是第一關(guān),city 是第二關(guān),zipCode 就是第三關(guān)
你必須匹配了第一關(guān),才能匹配第二關(guān),匹配了第一關(guān)和第二關(guān),才能匹配第三關(guān)
這樣描述不算完全準(zhǔn)確 但是確實(shí)是這種思想
要想理解聯(lián)合索引的最左匹配原則,先來理解下索引的底層原理。索引的底層是一顆 B+ 樹,那么聯(lián)合索引的底層也就是一顆 B+ 樹,只不過聯(lián)合索引的B+樹節(jié)點(diǎn)中存儲(chǔ)的是鍵值。由于構(gòu)建一棵 B+ 樹只能根據(jù)一個(gè)值來確定索引關(guān)系,所以數(shù)據(jù)庫(kù)依賴聯(lián)合索引最左的字段來構(gòu)建,文字比較抽象,我們看一下。
加入我們建立 A,B 聯(lián)合索引 他們?cè)诘讓觾?chǔ)存是什么樣子呢?
橙色代表字段 A 淺綠色 代表字段B
圖解:
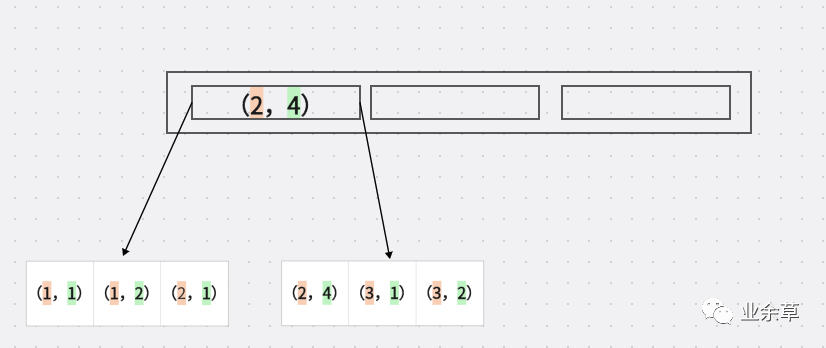
我們可以看出幾個(gè)特點(diǎn)
A 是有順序的 1,1,2,2,3,4 B 是沒有順序的 1,2,1,4,1,2 這個(gè)是散列的 如果A是等值的時(shí)候 B是有序的 例如 (1,1),(1,2) 這里的B有序的 (2,1),(2,4) B 也是有序的
這里應(yīng)該就能看出,如果沒有 A 的支持,B 的索引是散列的,不是連續(xù)的。
再細(xì)致一點(diǎn),我們重新創(chuàng)建一個(gè)表。
DROP TABLE IF EXISTS `leftaffix`;
CREATE TABLE `leftaffix` (
`a` int(11) NOT NULL AUTO_INCREMENT,
`b` int(11) NULL DEFAULT NULL,
`c` int(11) NULL DEFAULT NULL,
`d` int(11) NULL DEFAULT NULL,
`e` varchar(11) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`a`) USING BTREE,
INDEX `聯(lián)合索引`(`b`, `c`, `d`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of leftaffix
-- ----------------------------
INSERT INTO `leftaffix` VALUES (1, 1, 1, 1, '1');
INSERT INTO `leftaffix` VALUES (2, 2, 2, 2, '2');
INSERT INTO `leftaffix` VALUES (3, 3, 2, 2, '3');
INSERT INTO `leftaffix` VALUES (4, 3, 1, 1, '4');
INSERT INTO `leftaffix` VALUES (5, 2, 3, 5, '5');
INSERT INTO `leftaffix` VALUES (6, 6, 4, 4, '6');
INSERT INTO `leftaffix` VALUES (7, 8, 8, 8, '7');
SET FOREIGN_KEY_CHECKS = 1;
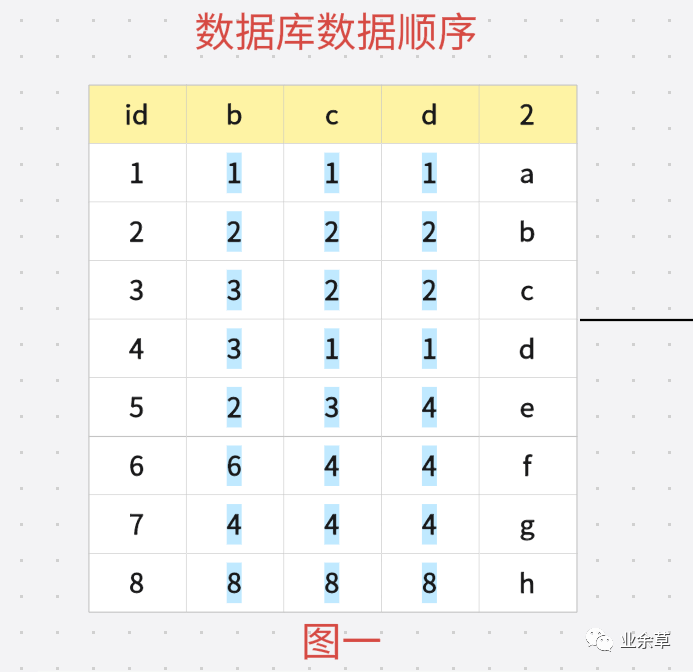
?在創(chuàng)建索引樹的時(shí)候會(huì)對(duì)數(shù)據(jù)進(jìn)行排序,根據(jù)最左綴原則,會(huì)先通過 B 進(jìn)行排序。也就是,如果出現(xiàn)值相同就根據(jù) C 排序,如果 C 相同就根據(jù) D 排序,排好順序之后就是如下圖:
?
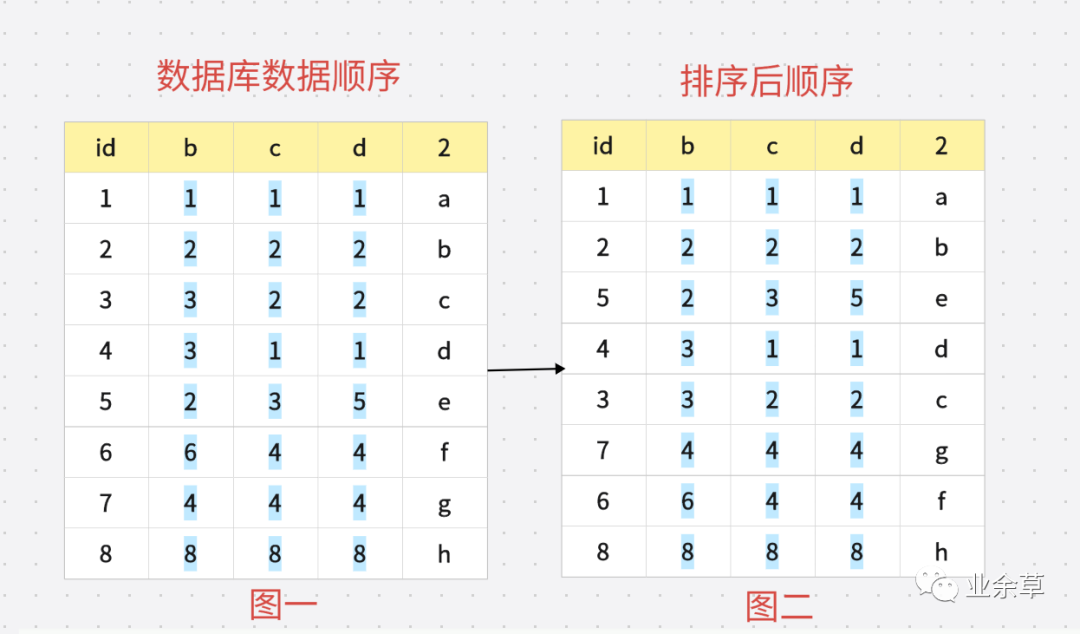
?索引的生成就會(huì)根據(jù)圖二的順序進(jìn)行生成 我們看一下 生成后的樹狀數(shù)據(jù)是什么樣子
?
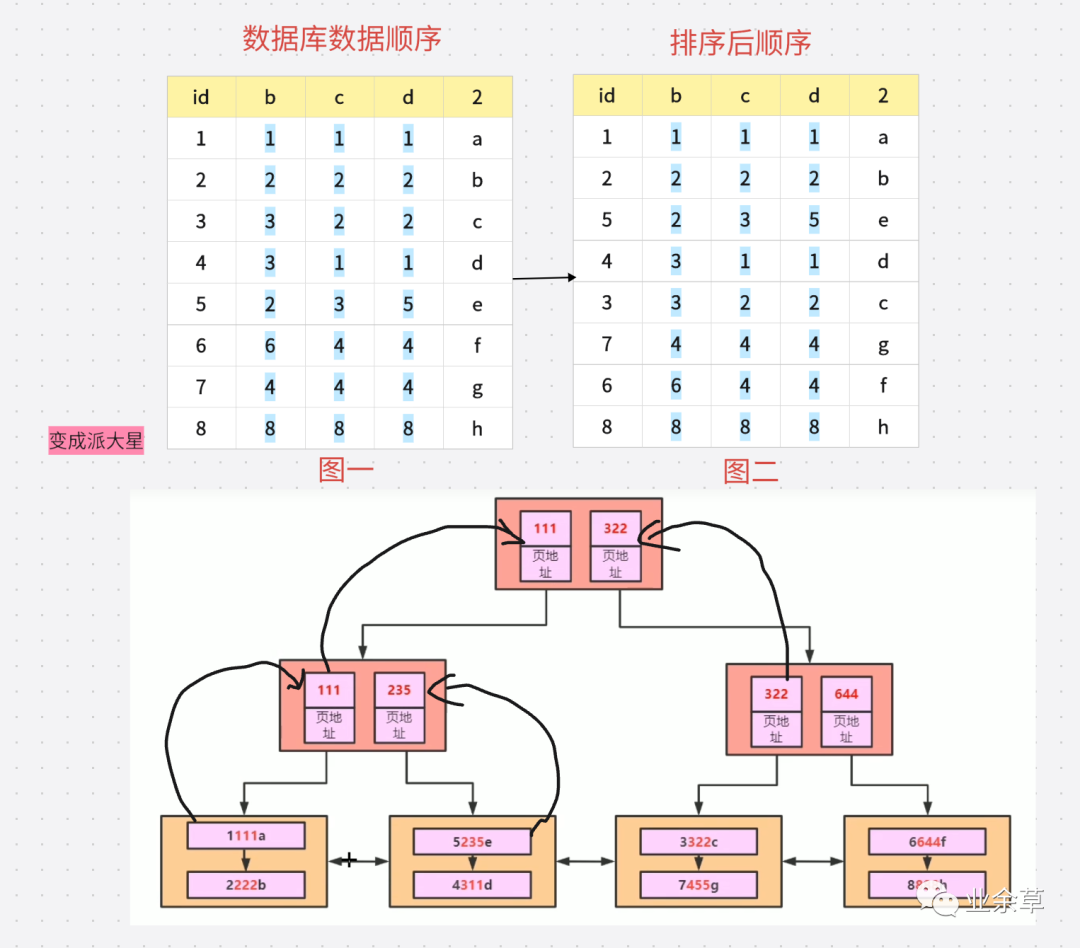
?解釋一些這個(gè)樹狀圖,首先根據(jù)圖二的排序。我們知道順序是 1111a 2222b,所以,在第三層,我們可以看到 1111a 在第一層。2222b 在第二層。因?yàn)?111 < 222,所以 111 進(jìn)入第二層,然后得出第一層
?

簡(jiǎn)化一下就是這個(gè)樣子。
但是這種順序是相對(duì)的。這是因?yàn)?MySQL 創(chuàng)建聯(lián)合索引的規(guī)則是首先會(huì)對(duì)聯(lián)合索引的最左邊第一個(gè)字段排序,在第一個(gè)字段的排序基礎(chǔ)上,然后在對(duì)第二個(gè)字段進(jìn)行排序。所以 B=2 這種查詢條件沒有辦法利用索引。
看到這里還可以明白一個(gè)道理,為什么我們建立索引的時(shí)候不推薦建立在經(jīng)常改變的字段,因?yàn)檫@樣的話我們的索引結(jié)構(gòu)就要跟著你的改變而改動(dòng),所以很消耗性能。
補(bǔ)充
最左綴原則可以通過跳躍掃描的方式打破,簡(jiǎn)單整理一下這方面的知識(shí)。
這個(gè)是在 8.0 進(jìn)行的優(yōu)化
MySQL8.0版本開始增加了索引跳躍掃描的功能,當(dāng)?shù)谝涣兴饕奈ㄒ恢递^少時(shí),即使 where 條件沒有第一列索引,查詢的時(shí)候也可以用到聯(lián)合索引。比如我們使用的聯(lián)合索引是 bcd 但是 b 中字段比較少 我們?cè)谑褂寐?lián)合索引的時(shí)候沒有使用 b 但是依然可以使用聯(lián)合索引。「MySQL聯(lián)合索引有時(shí)候遵循最左前綴匹配原則,有時(shí)候不遵循。」
小總結(jié)
前提:如果創(chuàng)建 b,c,d 聯(lián)合索引面。
如果 我where 后面的條件是 c = 1 and d = 1為什么不能走索引呢 如果沒有b的話 你查詢的值相當(dāng)于*11我們都知道*是所有的意思也就是我能匹配到所有的數(shù)據(jù)如果 我 where 后面是 b = 1 and d =1為什么會(huì)走索引呢?你等于查詢的數(shù)據(jù)是1*1我可以通過前面 1 進(jìn)行索引匹配 所以就可以走索引最左綴匹配原則的最重要的就是 第一個(gè)字段
我們接著看下一個(gè)失效場(chǎng)景。
select *
思考
這里是我之前的一個(gè)思維誤區(qū)select *不會(huì)導(dǎo)致索引失效。之前測(cè)試發(fā)現(xiàn)失效是因?yàn)?where 后面的查詢范圍過大,導(dǎo)致索引失效。并不是Select *引起的,但是為什么不推薦使用select *。
解釋
增加查詢分析器解析成本。 增減字段容易與 resultMap 配置不一致。 無用字段增加網(wǎng)絡(luò) 消耗,尤其是 text 類型的字段。
在阿里的開發(fā)手冊(cè)中,大面的概括了上面幾點(diǎn)。
在使用Select *索引使用正常。

雖然走了索引但是,也不推薦這種寫法。為什么呢?
首先我們?cè)谏弦粋€(gè)驗(yàn)證中創(chuàng)建了聯(lián)合索引,我們使用 B=1 會(huì)走索引。但是,與直接查詢索引字段不同,使用SELECT *獲取了不需要的數(shù)據(jù),則首先通過輔助索引過濾數(shù)據(jù),然后再通過聚集索引獲取所有的列,這就多了一次 b+ 樹查詢,速度必然會(huì)慢很多,減少使用select *就是降低回表帶來的損耗。
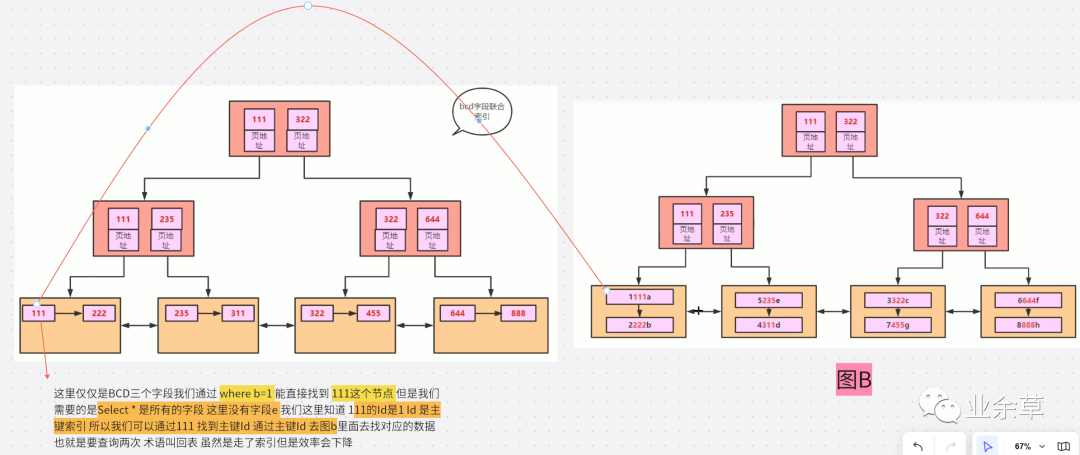
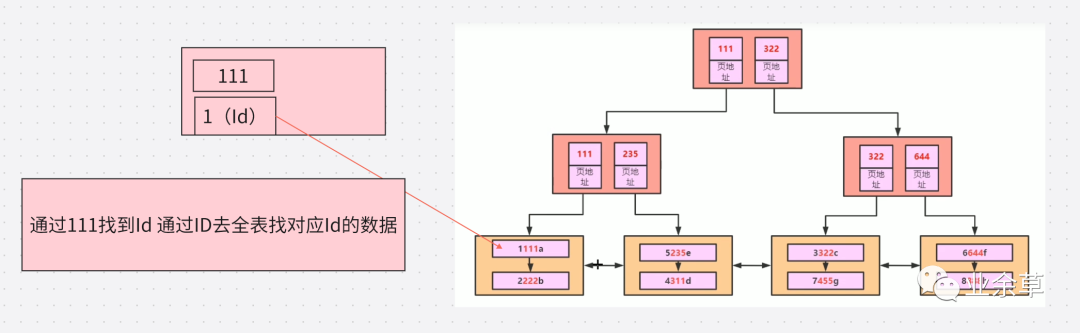
也就是Select *在一些情況下是會(huì)走索引的,如果不走索引就是 where 查詢范圍過大,導(dǎo)致 MySQL 最優(yōu)選擇全表掃描了。并不是Select *的問題。

上圖就是索引失效的情況。
范圍查找也不是一定會(huì)索引失效,下面的情況就會(huì)索引生效,就是級(jí)別低,生效的原因是因?yàn)榭s小了范圍。

小總結(jié)
select * 會(huì)走索引
范圍查找有概率索引失效但是在特定的情況下會(huì)生效,范圍小就會(huì)使用,也可以理解為,返回結(jié)果集小就會(huì)使用索引
mysql 中連接查詢的原理是先對(duì)驅(qū)動(dòng)表進(jìn)行查詢操作,然后再用從驅(qū)動(dòng)表得到的數(shù)據(jù)作為條件,逐條的到被驅(qū)動(dòng)表進(jìn)行查詢。
每次驅(qū)動(dòng)表加載一條數(shù)據(jù)到內(nèi)存中,然后被驅(qū)動(dòng)表所有的數(shù)據(jù)都需要往內(nèi)存中加載一遍進(jìn)行比較。效率很低,所以 mysql 中可以指定一個(gè)緩沖池的大小,緩沖池大的話可以同時(shí)加載多條驅(qū)動(dòng)表的數(shù)據(jù)進(jìn)行比較,放的數(shù)據(jù)條數(shù)越多性能 io 操作就越少,性能也就越好。所以,如果此時(shí)使用
select *放一些無用的列,只會(huì)白白的占用緩沖空間。浪費(fèi)本可以提高性能的機(jī)會(huì)。按照評(píng)論區(qū)老哥的說法
select *不是造成索引失效的直接原因 大部分原因是 where 后邊條件的問題,但是還是盡量少去使用select *多少還是會(huì)有影響的。
使用函數(shù)
使用在 Select 后面使用函數(shù)可以使用索引,但是下面這種做法就不能。


因?yàn)樗饕4娴氖撬饕侄蔚脑贾担皇墙?jīng)過函數(shù)計(jì)算后的值,自然就沒辦法走索引了。
不過,從 MySQL 8.0 開始,索引特性增加了函數(shù)索引,即可以針對(duì)函數(shù)計(jì)算后的值建立一個(gè)索引,也就是說該索引的值是函數(shù)計(jì)算后的值,所以就可以通過掃描索引來查詢數(shù)據(jù)。
這種寫法我沒使用過,感覺情況比較少,也比較容易注意到這種寫法。
計(jì)算操作
這個(gè)情況和上面一樣,之所以會(huì)導(dǎo)致索引失效是因?yàn)楦淖兞怂饕瓉淼闹担跇渲姓也坏綄?duì)應(yīng)的數(shù)據(jù)只能全表掃描。

因?yàn)樗饕4娴氖撬饕侄蔚脑贾担皇?code style="overflow-wrap: break-word;margin-right: 2px;margin-left: 2px;font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(53, 148, 247);background: rgba(59, 170, 250, 0.1);padding-right: 2px;padding-left: 2px;border-radius: 2px;height: 21px;line-height: 22px;">b - 1表達(dá)式計(jì)算后的值,所以無法走索引,只能通過把索引字段的取值都取出來,然后依次進(jìn)行表達(dá)式的計(jì)算來進(jìn)行條件判斷,因此采用的就是全表掃描的方式。
下面這種計(jì)算方式就會(huì)使用索引。

Java 比較熟悉的可能會(huì)有點(diǎn)疑問,這種對(duì)索引進(jìn)行簡(jiǎn)單的表達(dá)式計(jì)算,在代碼特殊處理下,應(yīng)該是可以做到索引掃描的,比方將b - 1 = 6變成b = 6 - 1。是的,是能夠?qū)崿F(xiàn),但是 MySQL 還是偷了這個(gè)懶,沒有實(shí)現(xiàn)。
小總結(jié)
總而言之,只要是影響到索引列的值,索引就是失效。
Like %
這個(gè)真的是難受哦,因?yàn)榻?jīng)常使用這個(gè),所以還是要小心點(diǎn),在看為什么失效之前,我們先看一下Like %的解釋。
「%百分號(hào)通配符:」 表示任何字符出現(xiàn)任意次數(shù)(可以是0次)。 「_下劃線通配符:」 表示只能匹配單個(gè)字符,不能多也不能少,就是一個(gè)字符。 「like操作符:」 LIKE 作用是指示 mysql 后面的搜索模式是利用通配符而不是直接相等匹配進(jìn)行比較。
「注意:」 如果在使用 like 操作符時(shí),后面的沒有使用通用匹配符效果是和=一致的。
SELECT * FROM products WHERE products.prod_name like '1000';
匹配包含"Li"的記錄(包括記錄"Li") :
SELECT* FROM products WHERE products.prod_name like '%Li%';
匹配以"Li"結(jié)尾的記錄(包括記錄"Li",不包括記錄"Li ",也就是 Li 后面有空格的記錄,這里需要注意)
SELECT * FROM products WHERE products.prod_name like '%Li';
在左不走,在右走。
右: 雖然走,但是索引級(jí)別比較低主要是模糊查詢,范圍比較大,所以索引級(jí)別就比較低。

左: 這個(gè)范圍非常大 所以沒有使用索引的必要了 這個(gè)可能不是很好優(yōu)化 還好不是一直拼接上面的

小總結(jié)
索引的時(shí)候和查詢范圍關(guān)系也很大,范圍過大造成索引沒有意義從而失效的情況也不少。
使用Or導(dǎo)致索引失效
這個(gè)原因就更簡(jiǎn)單了。
在 WHERE 子句中,如果在 OR 前的條件列是索引列,而在 OR 后的條件列不是索引列,那么索引會(huì)失效 舉個(gè)例子,比如下面的查詢語句,b 是主鍵,e 是普通列,從執(zhí)行計(jì)劃的結(jié)果看,是走了全表掃描。

優(yōu)化
這個(gè)的優(yōu)化方式就是,在 Or 的時(shí)候兩邊都加上索引。
就會(huì)使用索引,避免全表掃描。

in使用不當(dāng)
首先使用 In 不是一定會(huì)造成全表掃描的。「IN肯定會(huì)走索引,但是當(dāng)IN的取值范圍較大時(shí)會(huì)導(dǎo)致索引失效,走全表掃描」


in 在結(jié)果集,大于 30% 的時(shí)候索引失效。
not in 和 In的失效場(chǎng)景相同
order By

這一個(gè)主要是 Mysql 自身優(yōu)化的問題,我們都知道 Order By 是排序。那就代表我需要對(duì)數(shù)據(jù)進(jìn)行排序,如果我走索引,索引是排好序的。但是我需要回表,消耗時(shí)間。另一種,我直接全表掃描排序。不用回表。也就是:
走索引 + 回表 不走索引 直接全表掃描
Mysql 認(rèn)為直接全表掃面的速度比。回表的速度快所以就直接走索引了,在 Order By 的情況下,走全表掃描反而是更好的選擇。
子查詢會(huì)走索引嗎
答案是會(huì),但是使用不好就不會(huì)。
大總結(jié)
減少回表優(yōu)化思路
「這個(gè)對(duì)于 SQL 有研究的人可能是比較了解的但是對(duì)于工作時(shí)長(zhǎng)不久的會(huì)比較陌生的詞語。但是這個(gè)是非常有意思,且重要的」
在這個(gè)索引問題上面還有一個(gè)細(xì)節(jié)的東西,其中印象比較深刻的是回表會(huì)造成效率下降,但是在我們?nèi)粘9ぷ髦惺潜容^常用單列索引,聯(lián)合索引對(duì)于新手來說不是很常用,但是單列索引在一些情況下肯定不是最優(yōu)解。例如like %問題,會(huì)造成索引問題,近期了解到一個(gè) ICP 知識(shí)。我之前都沒有關(guān)注過,不知道大家對(duì)這個(gè)了解多少,我這里就進(jìn)行一些整理。
首先我們 ICP 全稱是 Index Condition Pushdown,中文可以說成是索引下推。主要的作用解決數(shù)據(jù)查詢回表的問題,但是前提是和聯(lián)合索引進(jìn)行使用。才能發(fā)揮出來功效,接下來不了解的小伙伴可以認(rèn)真看一下這一點(diǎn),個(gè)人感覺還是比較有意思的東西。
回表問題
上面其實(shí)對(duì)于回表查詢沒有過多的解釋,就再提一什么是回表查詢。
回表查詢一般發(fā)生在非主鍵索引上面,需要進(jìn)行兩次樹查詢,所以效率會(huì)有所折扣。我們要想解決這個(gè)行為就可以使用,聯(lián)合索引去優(yōu)化。
ICP 索引下推
這個(gè)是在 MySQL 5.6 之后提供的特性,這個(gè)如果面試中問到,我們平常面試的時(shí)候。面試官都有喜歡問什么版本,增加了什么。如果問你 MySQL 5.6 之后增加什么優(yōu)化,不知道大家都能說出什么。這個(gè)就是一個(gè)很加分點(diǎn),你能說明白什么是索引下推。面試官會(huì)對(duì)你增加好感,至少說明你還是有點(diǎn)東西在身上的 不啰嗦了。開始研究:
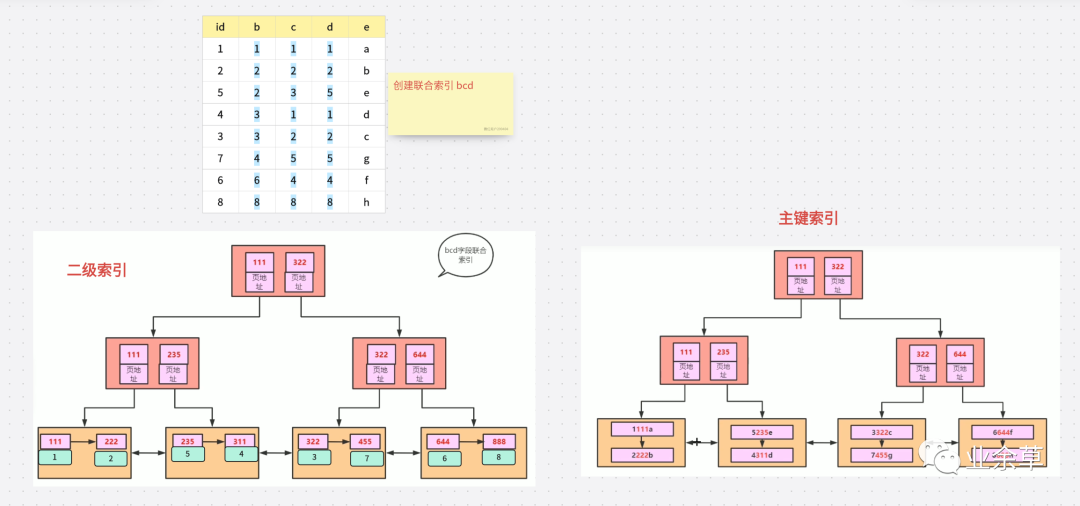
我們先看一下 5.6 之前和 5.6 之后,查詢流程會(huì)有什么變化。
假設(shè),我我們需要查詢select * from table1 where b like '3%' and c = 3。
「5.6 之前」
先通過聯(lián)合索引查詢到開頭為 3 的數(shù)據(jù),然后拿到主鍵(上圖中青色塊為主鍵) 然后通過主鍵去主鍵索引里面去回表查詢,二級(jí)索引里面查詢出來幾個(gè) 3 開頭的就回表幾次
「5.6 之后」
先通過 二級(jí)索引 查詢到開頭為 3 的數(shù)據(jù) 然后 再找到 c = 3 的數(shù)據(jù)進(jìn)行過濾 之后拿到主鍵 通過主鍵進(jìn)行回表查詢
上面都會(huì)進(jìn)行回表查詢,但是 5.6 之前沒有完全去利用二級(jí)緩存進(jìn)行數(shù)據(jù)過濾。如果 3 開頭的數(shù)據(jù)非常多,那就要一直回表,但是 5.6 之后去利用后續(xù)索引字段進(jìn)行查詢。
怎么說呢,就是為什么索引下推要和聯(lián)合索引進(jìn)行使用,普通索引沒有索引下推就是充分利用聯(lián)合索引的字段進(jìn)行過濾,盡量減少需要回表的數(shù)據(jù),來增加查詢效率,感覺思路是很簡(jiǎn)單的。
對(duì)于 Innodb 引擎的 ICP 只適合二級(jí)索引。
小細(xì)節(jié):
索引下推除了依賴,聯(lián)合索引之外,還不能在子查詢下面進(jìn)行使用,存儲(chǔ)函數(shù)也不能使用。
怎么查看是否使用索引下推

看這個(gè)你可能有點(diǎn)印象但是,理論上不是很明白,但是我現(xiàn)在是明白了。還有很多知識(shí)點(diǎn)要補(bǔ)充,慢慢寫。
正在整理 優(yōu)化器成本計(jì)算的知識(shí) MySQl 怎么去選擇索引的使用,這個(gè)寫完,以后面試直接不擔(dān)心索引問題了,不過需要費(fèi)點(diǎn)時(shí)間寫。
如果你是直接跳到這里 看看文章有多長(zhǎng) 建議收藏如果你一步步看到這里 感覺有點(diǎn)幫助 贊贊來一個(gè)如果感覺文章有問題 建議評(píng)論區(qū)指出 會(huì)修正
下面進(jìn)入送書環(huán)節(jié):
《Linux從入門到精通》本書從Linux的概念說起,由淺入深地介紹如何使用Linux命令進(jìn)行日常操作與管理。每章都附有實(shí)戰(zhàn)案例,方便回顧所學(xué)內(nèi)容與生產(chǎn)工作中的實(shí)用技巧。讀者不但可以系統(tǒng)地學(xué)習(xí)Linux的基礎(chǔ)操作,而且能對(duì)Linux上的運(yùn)維、開發(fā)有更為深入的理解。
本書共10章,涵蓋的主要內(nèi)容有Linux系統(tǒng)選擇與安裝、Linux入門命令與文件管理、Linux用戶與權(quán)限、磁盤掛載與擴(kuò)展、進(jìn)程管理與性能監(jiān)控、網(wǎng)絡(luò)通信與安全等。
本書內(nèi)容通俗易懂,案例豐富,實(shí)用性強(qiáng),特別適合Linux的入門讀者和進(jìn)階讀者閱讀,也適合經(jīng)常與Linux系統(tǒng)打交道的開發(fā)、測(cè)試、運(yùn)維崗位的IT從業(yè)者閱讀。另外,本書也適合作為相關(guān)培訓(xùn)機(jī)構(gòu)的教材使用。