
Mysql 索引使用規(guī)則和設計優(yōu)化
鏈接:tbwork.org/2017/05/31/mysql-index-mechanism/
大部分情況下,尤其是記錄數(shù)量較少的情況下Mysql總是能正常運轉的很好,但不可避免的,隨著數(shù)據(jù)庫記錄數(shù)的增長以及SQL語句越來越復雜,總會有一些實際效果與數(shù)據(jù)庫或SQL設計人員理解相違背的情況,這就需要開發(fā)者對Mysql的原理和存在的問題有一個基本的認識。本文主要探討了Mysql索引的使用和相關知識,這些知識并不復雜,不需要專業(yè)的數(shù)據(jù)庫學習經(jīng)驗就能搞明白,理解了這些可以幫助開發(fā)人員更好的進行數(shù)據(jù)庫索引設計和SQL查詢語句的編寫。
1. Mysql 是如何使用索引的
Primary Key、Unique index和FullText)都通過B樹來存儲和實現(xiàn)。也有一些例外:空間數(shù)據(jù)類型使用的索引是基于R-樹的;內(nèi)存表還支持哈希索引;InnoDB為Fulltext索引使用了逆轉鏈表[1]。本文不打算去贅述B樹的原理和創(chuàng)建過程,有興趣的可以點擊B樹了解。假設現(xiàn)在索引已經(jīng)創(chuàng)建完畢了,那么Mysql是如何查找到我們需要的數(shù)據(jù)的呢?下面我們就MyISAM和Innodb兩種不同的存儲引擎做討論。關于MyISAM和Innodb我們需要知道的有:MyISAM不支持事務,而Innodb支持。 MyISAM索引和數(shù)據(jù)的存儲是分開的(不同的文件),索引中最終檢索到的是數(shù)據(jù)的物理地址偏移量。而InnoDB中,索引段和數(shù)據(jù)段在同一個文件中的不同段,查到索引后可以直接取出數(shù)據(jù)。 MyISAM是非聚集索引,而Innodb則是聚集索引。
所謂聚集索引是指索引和數(shù)據(jù)的邏輯排列順序與實際物理存儲順序一致,新華字典就是典型的聚集索引,字(葉子索引)和釋意(數(shù)據(jù))靠在一起,且按一定順序排列的。而“非聚集索引”則相反,索引單獨放在一塊區(qū)域,并且葉子節(jié)點存放的是數(shù)據(jù)的地址偏移量。
1.1 MyISAM存儲引擎
?
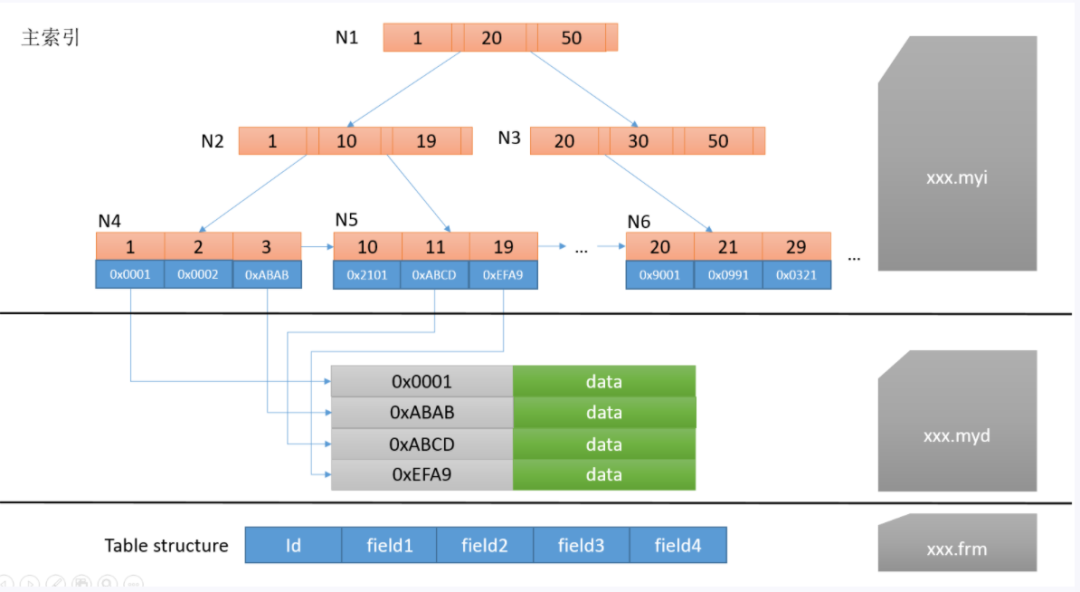
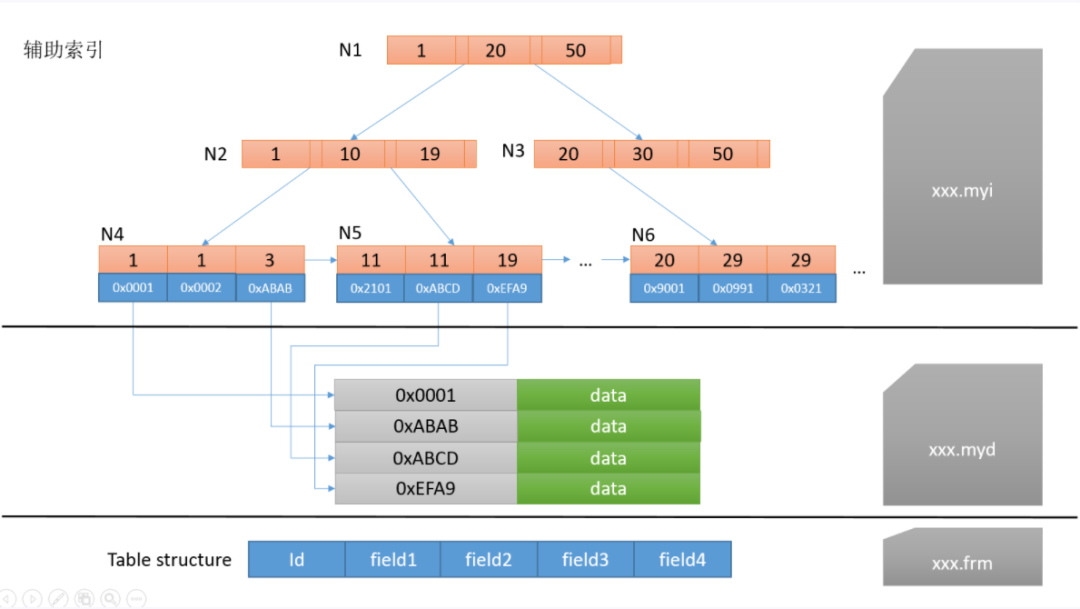
主索引是指主鍵索引,鍵值不可能重復;輔助索引則是普通索引,鍵值可能重復。
select * from table_name where id = 3
其中id為主鍵,那么首先檢索的是索引,索引中經(jīng)過2層查找,找到了索引為3的節(jié)點,值為0xABAB,代表了從.myd文件中偏移量為0xABAB的地方開始讀取一行的數(shù)據(jù)。輔助索引對應普通索引,存在相同的鍵值。
1.2 Innodb存儲引擎?
???在Innodb中,索引分葉子節(jié)點和非葉子節(jié)點,非葉子節(jié)點就像新華字典的目錄,單獨存放在索引段中,葉子節(jié)點則是順序排列的,在數(shù)據(jù)段中。Innodb的數(shù)據(jù)文件可以按照表來切分(只需要開啟innodb_file_per_table),切分后存放在xxx.ibd中,默認不切分,存放在xxx.ibdata中。假設有以下語句
select * from table_name where id = 3
其中id為主鍵,那么首先檢索的是索引段,索引段中查找下個索引范圍是通過地址偏移隨機訪問來實現(xiàn)的(這個步驟還是高效的),查找到對應葉子索引節(jié)點后,需要順序的遍歷和檢索該葉子節(jié)點找到對應的索引值對應的節(jié)點(這個步驟是遍歷,比較耗時),就可以立馬讀出數(shù)據(jù)了。
Innodb的表存儲結構由段、簇(區(qū))、頁組成,一個段由若干簇組成,一個簇默認有64頁,每頁16KB。
1.3 Mysql索引選取規(guī)則
尋找可能的(可選)索引:根據(jù)用戶的WHERE條件,查看每個字段是否匹配某個索引,如果匹配,就把這個索引加入待選列表中。所謂字段匹配索引有兩種情況:1)某個查詢字段上建立了 單列索引;2)某個查詢字段按照最左匹配原則(下文有詳細描述)匹配了某個組合索引,即為該組合索引的第一列。3)某幾個查詢字段按照最左匹配原則匹配了某個組合索引。可選索引列表可使用EXPLAIN查看(possible keys)[3]。待選列表如果為空,GOTO 3。索引擇優(yōu)算法:Mysql的索引擇優(yōu)算法很復雜,一般來說有這幾個影響因素:1)索引對應的掃描行數(shù),在沒有Order by的情況下,一般掃描行數(shù)少的索引會被選擇;2)查詢語句中有Order By或者group by時,如果不使用Order By后的字段做索引的話,filesort(對應索引排序,索引排序很快,而filesort則需要對結果集進行實時排序,所以很慢)會被使用,這時候Mysql給filesort的負權重很高,很容易導致Mysql放棄最優(yōu)索引(哪怕該索引估計掃描行數(shù)比實際使用的索引對應的掃描行數(shù)小很多),轉而使用Order By之后的索引字段。我們在生產(chǎn)中遇到過這樣的情況,部分文獻也有記載[6];3)Limit 限定也會影響索引的使用,甚至Limit后的值也會影響索引的使用(有時候確實會令人費解);4)話不能說滿,官網(wǎng)文檔寫的實在含糊,所以這里不敢打包票沒有其他影響因素了。如果優(yōu)選的掃描索引不為空,GOTO 4。 如果沒找到可用索引的話,再考察查詢字段,也就是 Select之后Where之前的那些字段。尋找查詢字段所匹配的索引,并得到一個可用索引結果集。根據(jù)最小估算掃描行數(shù)優(yōu)先原則,可以得到最優(yōu)的索引。如果可用索引結果集仍然為空,那么就會使用全表掃描(Full table scan)。如果根據(jù)最終選擇的索引估算出的掃描行數(shù)占據(jù)了表的很大一部分比例,那么Mysql優(yōu)化器可能會放棄使用該索引,而退化為使用全表掃描。這是因為使用索引在有些情況下并不高效,比如索引出來的數(shù)據(jù)量很大,需要頻繁的改變 文件讀取指針去獲取數(shù)據(jù)塊,可能效果還不如從頭到位把整個表都掃描一邊,也省去了去查找索引和頻繁重定向讀取指針(尤其在磁盤存儲器[4]上)帶來的開銷。如果到這步Mysql搜索優(yōu)化器仍然決定用某個索引,那么就會在實際查詢時使用該索引了。這個索引也是
EXPLAIN分析語句結果集中key的值。
關于 使用索引隨機讀取大量記錄和順序讀取大量記錄之間的取舍問題,本文并沒有去研究Mysql在優(yōu)化的時候是否考慮到了存儲器的類型,比如是磁盤還是SSD,對于SSD這種高效隨機存儲器來說,頻繁重定向讀取指針幾乎不耗時。如果沒有考慮到,而只是給這種頻繁讀取操作預設了一個成本常量(消耗的時間)參與估算的話,可能優(yōu)化結果并不恰當。
1.4 何時會全表掃描
1.目標數(shù)據(jù)表太小了,再去查找索引( key lookup)太麻煩了(有點殺雞焉用牛刀的即視感)。這通常發(fā)生在10行都不到的數(shù)據(jù)表,并且每行很短的情況。(注:10這個數(shù)字不可靠,這里只是感性的說了個數(shù)字,可能小幾十行的數(shù)據(jù)仍然會觸發(fā)全表掃描。)2.查詢條件中的字段(WHERE后)沒有匹配到索引的情況。(也不是說匹配不到就一定會全表掃描,見下文 默認索引選擇算法)3.查詢條件中的字段與某個常量比較時(就比如 where age > 8),并且使用這個常量值與對應索引篩選出的記錄數(shù)占了總數(shù)的大部分。優(yōu)化器認為掃這么大的數(shù)據(jù)還不如掃全表了,所以選擇了掃描全表。大部分怎么定義恐怕只有Mysql開發(fā)者才知道,官網(wǎng)也并沒有給出具體數(shù)值。4.查詢語句匹配到的索引對應的基數(shù)太小(對應 SHOW INDEX FROM table_name結果中的Cardinality?),并且此時又有其他列上的查詢條件(比如:select * from user where user_status > 0 and username =’tommy’)。所謂基數(shù)就是表中某列所有值的取值種數(shù),比如一張表有5行,某一列對應的值分別為:1,2,3,3,2。那么該列基數(shù)就是3,因為一共有三種取值:1,2,3。基數(shù)小,意味著該索引中每個索引值對應的目標記錄數(shù)很大,在這個索引值對應的記錄數(shù)中再去一個個的檢查其他列上的條件是否滿足,整個過程總體的查找速度還未必有全表掃描來得快。
經(jīng)測試,第3點當且僅當比較符號為 非等于時才生效。如果使用了等于號,那么只要該列有匹配的索引,一定會命中,哪怕基數(shù)為1。所以當查詢條件中有基數(shù)小的列時,某個索引值的條件只是從等于號改成小于號,就可能從使用索引退化到掃描全表。查看某個SQL語句是否使用某個索引靠譜的做法只有一個——使用Explain語句分析SQL。
文件讀取指針帶來的開銷,所以還不如使用全表掃描。第4個場景可能有點難懂,所以舉一個例子來說明。比如一張表Animal有以下數(shù)據(jù):我們在category上創(chuàng)建了一個索引,然后我們使用以下SQl語句進行查找:
Select * from Animal where category > 1 and name = "asaf"這時候category對應的索引數(shù)據(jù)會如下所示:
2. 多列索引(組合索引)
組合索引(其實就是同時在多個列上創(chuàng)建索引)。一個索引最大可以包含16個列。對于某些數(shù)據(jù)類型的列來說,你還可以對其前綴進行索引([前綴索引(https://dev.mysql.com/doc/refman/5.7/en/column-indexes.html#column-indexes-prefix)])[2]。當查詢條件匹配了索引中的所有列、第一列、前二列、前三列等時,Mysql就會使用這個多列索引,如果我們在定義索引的時候就安排好列的順序,一個單獨的組合索引總是可以加快好幾種查詢。換句話說,定義好一個組合索引,只要某個查詢用到了里面的某些字段,很可能會命中這個索引[2]。2.1 組合索引的數(shù)據(jù)構成
組合索引的索引值構成又是啥樣的呢,我們可以把多列索引(組合索引、混合索引)的索引數(shù)據(jù)當作一個排序好的數(shù)組, 索引數(shù)據(jù)的每一行就是由這些索引列對應的值組合起來的字符串[2]。比如對于index (a, b, c)來說, 數(shù)據(jù)庫中有數(shù)據(jù):那么索引數(shù)據(jù)就會像一樣:
注意:這是官方文檔上打的一個比方。實際查詢條件可能是”>、<、<=”這樣的范圍比較符號,需要對每一列作比較,所以不會真正的連接成一個字符串,這里只是一個形象的比喻,告知大家 組合索引和普通索引在數(shù)據(jù)構成上其實沒啥區(qū)別。
2.2 組合索引的一種替代方案
哈希列,哈希列的值計算自其他的某幾列。如果哈系列很短,唯一性好,并且加了索引,那么它將比直接使用組合索引快得多。在Mysql中,使用這個哈希列很簡單,比如[2]:SELECT * FROM tbl_nameWHERE hash_col=MD5(CONCAT(val1,val2))AND col1=val1 AND col2=val2;
很顯然,這種方法只適用于精確匹配的情況,如果用到了范圍比較符號(>,<,>=等),那就無法使用了。
2.3 組合索引的命中規(guī)則——最左匹配原則
下面我們再來看看哪些查詢會使用到我們定義的組合索引。假設一張表的定義如下:
CREATE TABLE test (id INT NOT NULL,last_name CHAR(30) NOT NULL,first_name CHAR(30) NOT NULL,PRIMARY KEY (id),INDEX name (last_name,first_name));
name索引是一個建立在last_name和first_name上的索引。這個索引會被那些為last_name和first_name字段指定了已知范圍的查詢所使用,當然了,他也會被只指定了last_name的查詢所使用,因為只指定last_name的情況恰好符合了**最左索引匹配原則**。我們舉些例子來說明下,name索引會在以下查詢語句被使用到:SELECT * FROM test WHERE last_name='Widenius';SELECT * FROM testWHERE last_name='Widenius' AND first_name='Michael';SELECT * FROM testWHERE last_name='Widenius'AND (first_name='Michael' OR first_name='Monty');SELECT * FROM testWHERE last_name='Widenius'AND first_name >='M' AND first_name < 'N';
如果一個表有一個組合索引,那么任何符合
**最左匹配原則**的查詢條件都會觸發(fā)優(yōu)化器使用該索引進行數(shù)據(jù)查找。比如,有一個三列的組合索引(col1, col2, col3),那么當查詢:where col1=xxx?、where col1=xxx and col2=xxx、where col1=xxx and col2=xxx and col3=xxx時,都會觸發(fā)該索引。
最左匹配原則——在對查詢條件中的字段進行組合索引的匹配時,只考慮匹配其前N個字段,比如前一個(第一個)、前2個、前3個字段等。其他情況視為未匹配。
1. SELECT * FROM tbl_name WHERE col1=val1;2. SELECT * FROM tbl_name WHERE col1=val1 AND col2=val2;3. SELECT * FROM tbl_name WHERE col2=val2;4. SELECT * FROM tbl_name WHERE col2=val2 AND col3=val3;
?(col1, col2, col3)上創(chuàng)建了索引,那么只有1和2語句命中了該索引。后面兩條語句則不會命中,因為他們不滿足**最左匹配原則**。然而打臉的是實際情況中我們在Mysql中做實驗的時候,會發(fā)現(xiàn)3,4也命中了該索引。這是因為觸發(fā)了默認索引選擇算法選取索引。當Mysql沒找到適合的索引,準備退化到全表掃描前,會使用一個默認索引選擇算法。Mysql認為只要能找到這樣一個索引,總會比全表掃描好一點。**? 默認索引選擇算法**——當查詢語句的搜索條件沒有命中任何索引時,Mysql索引優(yōu)化器會考量查詢語句中的目標字段(select后面,where前面的部分),目標字段除去主鍵外,如果恰好是某個索引(包括組合索引)對應列的子集,那么該索引也會被使用。如果滿足的索引有多個,將會使用索引記錄數(shù)最少的索引。這個算法在[3]中得到了旁證。
col4,索引就不會被命中。name索引:SELECT * FROM test WHERE first_name='Michael';SELECT * FROM testWHERE last_name='Widenius' OR first_name='Michael';
Explain命令進行執(zhí)行分析時,上述語句的分析結果可能提示使用了該索引。還是因為觸發(fā)了默認索引選擇算法。3. 索引設計建議
索引不是定義的越多越好,對于查詢條件比較多的情況,避免為每個字段創(chuàng)建索引,只需要創(chuàng)建一個聯(lián)合索引即可。創(chuàng)建聯(lián)合索引時,把可能存在單列查詢的那一列放前面。比如業(yè)務需求要求以下幾種查詢: 這時候,組合索引應該建成為:
這時候上述三種查詢都會使用到該索引。創(chuàng)建聯(lián)合索引時,值差異化大的列放在前面,而不是那些取值種類很少的列。比如 用戶名和用戶狀態(tài)兩列,創(chuàng)建索引的順序應當是index(用戶名、用戶狀態(tài)),而不是index(用戶狀態(tài)、用戶名)。如果把基數(shù)很小的用戶狀態(tài)放在第一個,那么如果恰好查詢語句條件是“用戶名=某個值 AND 用戶狀態(tài)>某個值”時,Mysql索引優(yōu)化器很可能根據(jù)用戶狀態(tài)得出要掃描的行數(shù)太多,退化為全表掃描,而后面的精確匹配用戶名的條件就沒用上了。由于Mysql索引優(yōu)化器的存在,有時候會出現(xiàn)很多意向不到不使用索引的情況。所以每次寫無法確定使用哪個索引的Sql語句時(尤其是WHERE條件后是>,<等范圍選擇時),一定要多用EXPLAIN語句進行分析。 可以認為Mysql在執(zhí)行SQL語句時,一個表只可能使用一個索引(開啟了Index Merge的情況除外)。新人在建表的時候總是會忽略這個事實,從而為很多列單獨建立了索引,認為這樣會更快。 Mysql索引優(yōu)化規(guī)則是一個官網(wǎng)都沒說清的問題,在復雜SQL的情況下不可避免的會產(chǎn)生一些事與愿違的情況(已知的影響因素1.1中有提到),導致Mysql很蠢的使用了不該使用的索引(這種情況的確會存在[6],這也佐證了Mysql的執(zhí)行計劃是估算出來的,并不總是靠譜)。實際使用中發(fā)現(xiàn)索引使用錯誤的情況,可以使用Force Index/Use Index等引導Mysql搜索優(yōu)化器使用某個索引,這里有一些可選的解決方案有興趣的也可以看看[6]。
參考文獻:
[1]. How MySQL Uses Indexes. https://dev.mysql.com/doc/refman/5.7/en/optimization-indexes.html
[2]. Multiple-Column Indexes, https://dev.mysql.com/doc/refman/5.7/en/multiple-column-indexes.html
[3]. EXPLAIN Output Format. https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain_key
[4]. 磁盤存儲器. http://www.baike.com/wiki/%E7%A3%81%E7%9B%98%E5%AD%98%E5%82%A8%E5%99%A8
[5]. Avoiding Full Table Scans. https://dev.mysql.com/doc/refman/5.7/en/table-scan-avoidance.html
[6]. 7 ways to convince MySQL to use the right index. http://code.openark.org/blog/mysql/7-ways-to-convince-mysql-to-use-the-right-index
? 開發(fā)者全社區(qū)?