
請(qǐng)謹(jǐn)慎使用預(yù)訓(xùn)練的深度學(xué)習(xí)模型
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

預(yù)訓(xùn)練模型用起來(lái)非常容易,但是你是否忽略了可能影響模型性能的細(xì)節(jié)呢?
你運(yùn)行過(guò)多少次下面的代碼:
import torchvision.models as models
inception = models.inception_v3(pretrained=True)
或者是這個(gè)
from keras.applications.inception_v3 import InceptionV3
base_model = InceptionV3(weights='imagenet', include_top=False)
看起來(lái)使用這些預(yù)訓(xùn)練的模型已經(jīng)成為行業(yè)最佳實(shí)踐的新標(biāo)準(zhǔn)。畢竟,有一個(gè)經(jīng)過(guò)大量數(shù)據(jù)和計(jì)算訓(xùn)練的模型,你為什么不利用呢?
利用預(yù)訓(xùn)練的模型有幾個(gè)重要的好處:
合并超級(jí)簡(jiǎn)單
快速實(shí)現(xiàn)穩(wěn)定(相同或更好)的模型性能
不需要太多的標(biāo)簽數(shù)據(jù)
遷移學(xué)習(xí)、預(yù)測(cè)和特征提取的通用用例
NLP領(lǐng)域的進(jìn)步也鼓勵(lì)使用預(yù)訓(xùn)練的語(yǔ)言模型,如GPT和GPT-2、AllenNLP的ELMo、谷歌的BERT、Sebastian Ruder和Jeremy Howard的ULMFiT。
利用預(yù)訓(xùn)練模型的一種常見(jiàn)技術(shù)是特征提取,在此過(guò)程中檢索由預(yù)訓(xùn)練模型生成的中間表示,并將這些表示用作新模型的輸入。通常假定這些最終的全連接層得到的是信息與解決新任務(wù)相關(guān)的。
每個(gè)人都參與其中
每一個(gè)主流框架,如Tensorflow,Keras,PyTorch,MXNet等,都提供了預(yù)先訓(xùn)練好的模型,如Inception V3,ResNet,AlexNet等,帶有權(quán)重:
Keras Applications
PyTorch torchvision.models
Tensorflow Official Models?(and now?TensorFlow Hubs)
MXNet Model Zoo
Fast.ai Applications

很簡(jiǎn)單,是不是?
但是,這些benchmarks可以復(fù)現(xiàn)嗎? ?
這篇文章的靈感來(lái)自Curtis Northcutt,他是麻省理工學(xué)院計(jì)算機(jī)科學(xué)博士研究生。他的文章‘Towards Reproducibility: Benchmarking Keras and PyTorch’ 提出了幾個(gè)有趣的觀點(diǎn):
resnet結(jié)構(gòu)在PyTorch中執(zhí)行得更好,?inception結(jié)構(gòu)在Keras中執(zhí)行得更好在Keras應(yīng)用程序上不能復(fù)現(xiàn)Keras Applications上的已發(fā)布的基準(zhǔn)測(cè)試,即使完全復(fù)制示例代碼也是如此。事實(shí)上,他們報(bào)告的準(zhǔn)確率(截至2019年2月)通常高于實(shí)際的準(zhǔn)確率。
當(dāng)部署在服務(wù)器上或與其他Keras模型按順序運(yùn)行時(shí),一些預(yù)先訓(xùn)練好的Keras模型會(huì)產(chǎn)生不一致或較低的精度。
使用batch normalization的Keras模型可能不可靠。對(duì)于某些模型,前向傳遞計(jì)算(假定梯度為off)仍然會(huì)導(dǎo)致在推理時(shí)權(quán)重發(fā)生變化。
你可能會(huì)想:這怎么可能?這些不是相同的模型嗎?如果在相同的條件下訓(xùn)練,它們不應(yīng)該有相同的性能嗎?
并不是只有你這么想,Curtis的文章也在Twitter上引發(fā)了一些反應(yīng):
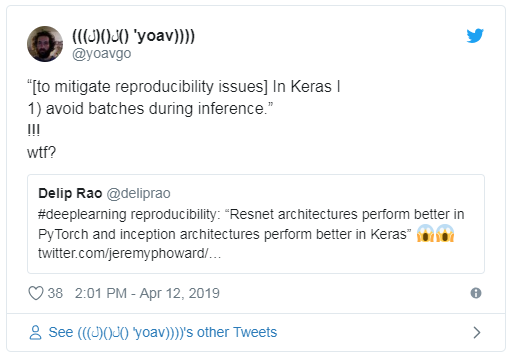
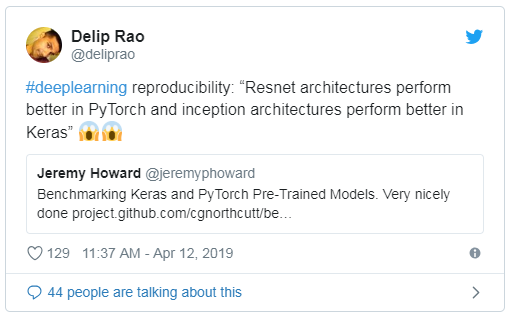
關(guān)于這些差異的原因有一些有趣的見(jiàn)解:

了解(并信任)這些基準(zhǔn)測(cè)試非常重要,因?yàn)樗鼈冊(cè)试S你根據(jù)要使用的框架做出明智的決策,并且通常用作研究和實(shí)現(xiàn)的基線。
那么,當(dāng)你利用這些預(yù)先訓(xùn)練好的模型時(shí),需要注意什么呢?
使用預(yù)訓(xùn)練模型的注意事項(xiàng)
1、你的任務(wù)有多相似?你的數(shù)據(jù)有多相似?
對(duì)于你的新x射線數(shù)據(jù)集,你使用Keras Xception模型,你是不是期望0.945的驗(yàn)證精度?首先,你需要檢查你的數(shù)據(jù)與模型所訓(xùn)練的原始數(shù)據(jù)集(在本例中為ImageNet)有多相似。你還需要知道特征是從何處(網(wǎng)絡(luò)的底部、中部或頂部)遷移的,因?yàn)槿蝿?wù)相似性會(huì)影響模型性能。
閱讀CS231n?—?Transfer Learning?and ‘How transferable are features in deep neural networks?’
2、你如何預(yù)處理數(shù)據(jù)?
你的模型的預(yù)處理應(yīng)該與原始模型相同。幾乎所有的torchvision模型都使用相同的預(yù)處理值。對(duì)于Keras模型,你應(yīng)該始終為相應(yīng)的模型級(jí)模塊使用 preprocess_input函數(shù)。例如:
# VGG16
keras.applications.vgg16.preprocess_input
# InceptionV3
keras.applications.inception_v3.preprocess_input
#ResNet50
keras.applications.resnet50.preprocess_input
3、你的backend是什么?
有一些關(guān)于HackerNews的傳言稱,將Keras的后端從Tensorflow更改為CNTK (Microsoft Cognitive toolkit)提高了性能。由于Keras是一個(gè)模型級(jí)庫(kù),它不處理諸如張量積、卷積等較低級(jí)別的操作,所以它依賴于其他張量操作框架,比如TensorFlow后端和Theano后端。
Max Woolf提供了一個(gè)優(yōu)秀的基準(zhǔn)測(cè)試項(xiàng)目,發(fā)現(xiàn)CNTK和Tensorflow之間的準(zhǔn)確性是相同的,但CNTK在LSTMs和多層感知(MLPs)方面更快,而Tensorflow在CNNs和embeddings方面更快。
Woolf的文章是2017年發(fā)表的,所以如果能得到一個(gè)更新的比較結(jié)果,其中還包括Theano和MXNet作為后端,那將是非常有趣的(盡管Theano現(xiàn)在已經(jīng)被廢棄了)。
還有一些人聲稱,Theano的某些版本可能會(huì)忽略你的種子。
4、你的硬件是什么?
你使用的是Amazon EC2 NVIDIA Tesla K80還是Google的NVIDIA Tesla P100?甚至可能是TPU???看看這些不同的pretrained模型的有用的基準(zhǔn)參考資料。
Apache MXNet’s?GluonNLP 0.6:Closing the Gap in Reproducible Research with BERT
Caleb Robinson’s ‘How to reproduce ImageNet validation results’ (and of course, again, Curtis’?benchmarking post)
DL Bench
Stanford DAWNBench
TensorFlow’s performance benchmarks
5、你的學(xué)習(xí)率是什么?
在實(shí)踐中,你應(yīng)該保持預(yù)訓(xùn)練的參數(shù)不變(即,使用預(yù)訓(xùn)練好的模型作為特征提取器),或者用一個(gè)相當(dāng)小的學(xué)習(xí)率來(lái)調(diào)整它們,以便不忘記原始模型中的所有內(nèi)容。
6、在使用batch normalization或dropout等優(yōu)化時(shí),特別是在訓(xùn)練模式和推理模式之間,有什么不同嗎?
正如Curtis的帖子所說(shuō):
使用batch normalization的Keras模型可能不可靠。對(duì)于某些模型,前向傳遞計(jì)算(假定梯度為off)仍然會(huì)導(dǎo)致在推斷時(shí)權(quán)重發(fā)生變化。
但是為什么會(huì)這樣呢?
Expedia的首席數(shù)據(jù)科學(xué)家Vasilis Vryniotis首先發(fā)現(xiàn)了Keras中的凍結(jié)batch normalization層的問(wèn)題。
Keras當(dāng)前實(shí)現(xiàn)的問(wèn)題是,當(dāng)凍結(jié)批處理規(guī)范化(BN)層時(shí),它在訓(xùn)練期間還是會(huì)繼續(xù)使用mini-batch的統(tǒng)計(jì)信息。我認(rèn)為當(dāng)BN被凍結(jié)時(shí),更好的方法是使用它在訓(xùn)練中學(xué)習(xí)到的移動(dòng)平均值和方差。為什么?由于同樣的原因,在凍結(jié)層時(shí)不應(yīng)該更新mini-batch的統(tǒng)計(jì)數(shù)據(jù):它可能導(dǎo)致較差的結(jié)果,因?yàn)橄乱粚記](méi)有得到適當(dāng)?shù)挠?xùn)練。
Vasilis還引用了這樣的例子,當(dāng)Keras模型從訓(xùn)練模式切換到測(cè)試模式時(shí),這種差異導(dǎo)致模型性能顯著下降(從100%下降到50%)。
好消息!?
小白學(xué)視覺(jué)知識(shí)星球
開(kāi)始面向外開(kāi)放啦??????
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺(jué)、目標(biāo)跟蹤、生物視覺(jué)、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目52講 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測(cè)、車道線檢測(cè)、車輛計(jì)數(shù)、添加眼線、車牌識(shí)別、字符識(shí)別、情緒檢測(cè)、文本內(nèi)容提取、面部識(shí)別等31個(gè)視覺(jué)實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺(jué)。 下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個(gè)基于OpenCV實(shí)現(xiàn)20個(gè)實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。 交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~