
CVPR2020 | PV-RCNN: 3D目標(biāo)檢測
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)
本文轉(zhuǎn)載自知乎,僅用于學(xué)術(shù)分享。如有侵權(quán),請(qǐng)聯(lián)系刪除。原文鏈接:
https://zhuanlan.zhihu.com/p/148942116
本文簡單介紹一下我們關(guān)于點(diǎn)云3D物體檢測方向的最新算法:PV-RCNN (Point-Voxel Feature Set Abstraction for 3D Object Detection)。
我們的算法在僅使用LiDAR傳感器的setting下,在自動(dòng)駕駛領(lǐng)域Waymo Open Challenge點(diǎn)云挑戰(zhàn)賽中取得了(所有不限傳感器算法榜單)三項(xiàng)亞軍、Lidar單模態(tài)算法三項(xiàng)第一的成績,以及在KITTI Benchmark上保持總榜第一的成績超過半年。
(順帶聊一下我對(duì)現(xiàn)在LiDAR點(diǎn)云3D檢測方向的一些看法)
論文鏈接 (代碼鏈接在最后):https://arxiv.org/abs/1912.13192

?
我們先看看PV-RCNN 3D檢測框架的性能如何。說到底,做high-level的,大多數(shù)還得硬碰硬 (不然難免故事吹的天花亂墜,一跑AP只有0.5。。
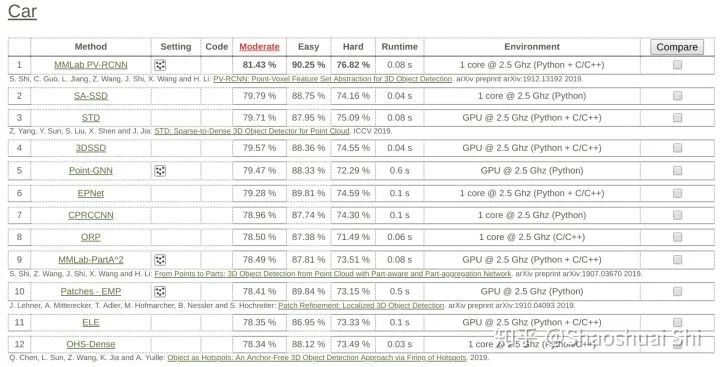
1. 到目前為止,3D檢測算法上競爭最激烈的莫過于KITTI榜單了(近兩年每次DDL都能涌現(xiàn)很多新方法。。
我們是去年11月提交的PV-RCNN結(jié)果,大幅領(lǐng)先之前的SoTA算法,且保持第一大半年一直到現(xiàn)在(最近出現(xiàn)很多新方法,估計(jì)也該被別人擠下去了。。
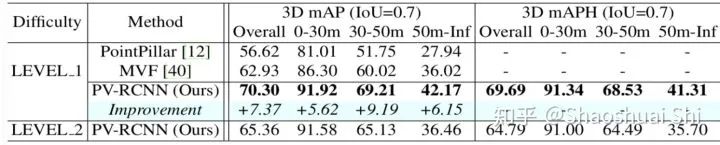
2. 除了KITTI以外,自動(dòng)駕駛業(yè)界巨頭Waymo也在去年release了超大的點(diǎn)云數(shù)據(jù)集Waymo Open Dataset。據(jù)我們所知,除了Waymo/Google以外,我們應(yīng)該是最早在Waymo數(shù)據(jù)集訓(xùn)練+測試的論文(之一),同樣大幅領(lǐng)先了Waymo論文的算法:
3. 此外,Waymo還于CVPR2020舉辦了點(diǎn)云3D物體檢測等比賽,因?yàn)槲覀儎偤糜腥ツ晖陡錚V-RCNN時(shí)準(zhǔn)備的各種現(xiàn)成Waymo代碼(以及覬覦其豐厚的獎(jiǎng)金233),所以就直接跑了一下。由于實(shí)驗(yàn)室機(jī)器有限,我們并沒有太多資源(與時(shí)間)投入到比賽中,我們提交的方法基本就是裸的論文原版PV-RCNN+一些簡單trick,在僅使用LiDAR點(diǎn)云作為輸入的情況下,我們最終取得了3D Detection、3D Tracking、Domain Adaptation三項(xiàng)比賽中單模態(tài)算法三項(xiàng)第一,所有(不限傳感器)算法三項(xiàng)第二。
在KITTI/Waymo上的出色性能,證明了我們PV-RCNN 3D檢測框架的有效性,接下來簡單介紹一些我們是怎么做的,以及為什么要這么做。
點(diǎn)云數(shù)據(jù)的稀疏性與不規(guī)則性,以及如何從點(diǎn)云數(shù)據(jù)中提取特征
眾所周知,相比圖像,點(diǎn)云數(shù)據(jù)的不規(guī)則性和稀疏性需要我們設(shè)計(jì)更特殊的網(wǎng)絡(luò)結(jié)構(gòu)去點(diǎn)云中提取特征。我們一般采用下面兩種方式提取點(diǎn)云特征,一個(gè)是PointNet++[1]中提出的point-based Set Abstraction?(以及各種魔改版本SA),另一個(gè)是轉(zhuǎn)化為規(guī)則voxel以后的voxel-based Sparse Convolution [2]。
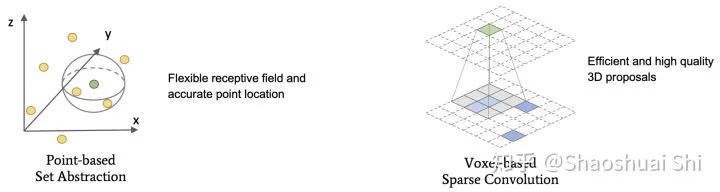
這兩種方式各有各的優(yōu)點(diǎn):
(1) SA在原始點(diǎn)云上做,保留了準(zhǔn)確的位置信息,且通過自定義球的半徑使得感受野更為靈活。
(2) Sparse conv在voxel上做,速度往往更快,并且在自動(dòng)駕駛場景下結(jié)合anchor可以產(chǎn)生更高質(zhì)量的3D Proposal (室內(nèi)場景一般來講通過PointRCNN[3]中提出的anchor-free策略提Proposal更為高效且直觀)。
?
為了綜合利用上面兩種特征提取操作各自的優(yōu)勢,我們就在考慮怎么能將這兩種點(diǎn)云特征提取算法深度結(jié)合到一個(gè)網(wǎng)絡(luò)中,提升網(wǎng)絡(luò)的結(jié)構(gòu)多樣性以及表征能力。從另一個(gè)方面講,我們之前一直專注于二階段的高性能3D網(wǎng)絡(luò)檢測框架(PointRCNN[3], PartA2-Net[4]),經(jīng)驗(yàn)告訴我們,在point上進(jìn)行3D RoI pooling比BEV map上效果更好(保留更精細(xì)的特征)。所以,怎么得到表征能力更強(qiáng)的point-wise特征,也是我們需要做的。
因此,我們接著考慮,怎么能將整個(gè)場景編碼到少量的keypoint上,用這些point-wise的keypoint特征來做第二階段的RoIPooling,也就是將其作為橋梁,來連接檢測框架的兩個(gè)階段。
然后我們就自然而然的關(guān)注到了Set Abstraction這個(gè)操作上了。在Set Abstraction的原本設(shè)計(jì)中,球中心的點(diǎn)是從整個(gè)點(diǎn)云中采樣出來的,其與周圍的點(diǎn)同宗同源,中心點(diǎn)的特征即通過球內(nèi)周圍點(diǎn)的特征聚合而來。然而,我們發(fā)現(xiàn),其實(shí)球中心點(diǎn)無需與周圍的點(diǎn)同宗同源,球中心點(diǎn)是可以任意給定的。所以,Set Abstraction本身就可以作為一個(gè)很好的操作,來結(jié)合上面兩種點(diǎn)云特征提取操作(球中心與周圍點(diǎn)可以分別來自于point與voxel)。
?
有了上面的思路,還需要一些具體實(shí)現(xiàn)的設(shè)計(jì)。簡單來講:
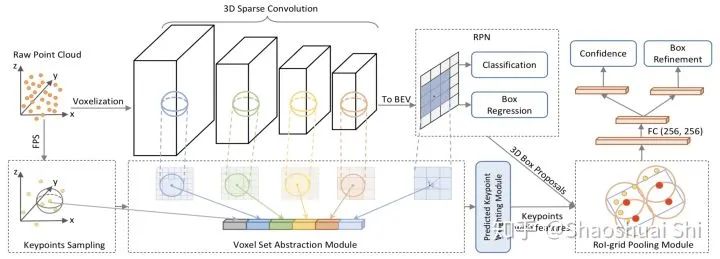
(1) 我們提出了Voxel Set Abstraction操作,將Sparse Convolution主干網(wǎng)絡(luò)中多個(gè)scale的sparse voxel及其特征投影回原始3D空間,然后將少量的keypoint (從點(diǎn)云中sample而來) 作為球中心,在每個(gè)scale上去聚合周圍的voxel-wise的特征。這個(gè)過程實(shí)際上結(jié)合了point-based和voxel-based兩種點(diǎn)云特征提取的結(jié)構(gòu),同時(shí)將整個(gè)場景的multi-scale的信息聚合到了少量的關(guān)鍵點(diǎn)特征中,以便下一步的RoI-pooling。
(2) 我們提出了Predicted Keypoint Weighting模塊,通過從3D標(biāo)注框中獲取的免費(fèi)點(diǎn)云分割標(biāo)注,來更加凸顯前景關(guān)鍵點(diǎn)的特征,削弱背景關(guān)鍵點(diǎn)的特征。
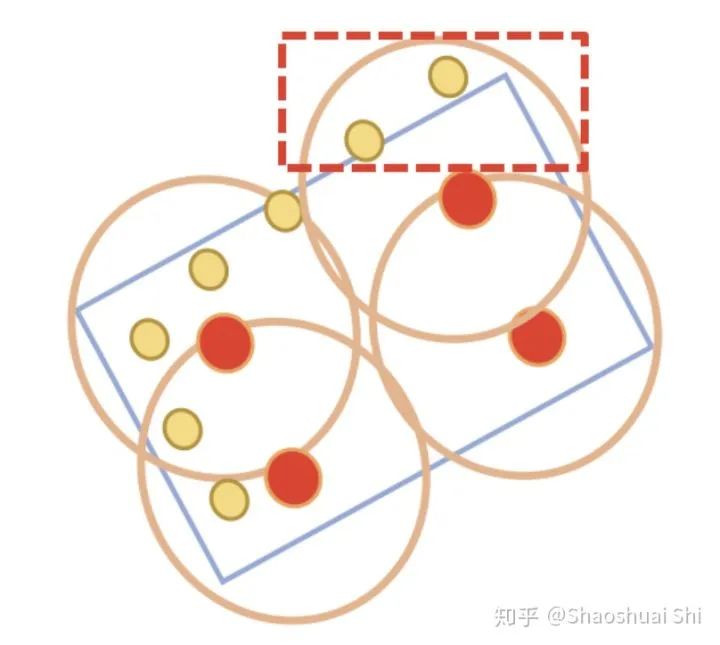
(3) 進(jìn)一步,我們設(shè)計(jì)了更強(qiáng)的點(diǎn)云3D RoI Pooling操作,也就是我們提出的RoI-grid Pooling: 與前面不同,這次我們在每個(gè)RoI里面均勻的sample一些grid point,然后將grid point當(dāng)做球中心,去聚合周圍的keypoint的特征。這樣做的好處有兩個(gè):
(1) 球半徑靈活,甚至可以包括proposal框外圍的關(guān)鍵點(diǎn),從而獲取更多有效特征。
(2) 球互相覆蓋,每個(gè)keypoint可以被多個(gè)grid point使用,從而得到更緊密的RoI特征表達(dá)。另一方面,這其實(shí)也是另一個(gè)point (keypoint)與voxel (grid point)特征交互的過程。
通過Voxel-to-keypoint與keypoint-to-grid這兩個(gè)point-voxel特征交互的過程,顯著增強(qiáng)了PV-RCNN的結(jié)構(gòu)多樣性,使其可以從點(diǎn)云數(shù)據(jù)中學(xué)習(xí)更多樣性的特征,來提升最終的3D檢測性能。
?
前段時(shí)間我們r(jià)elease了一個(gè)通用3D檢測代碼庫,PCDet:https://github.com/sshaoshuai/PCDet
最近我們正在重新整理PCDet代碼庫,方便更好的進(jìn)行排列組合,同時(shí)包含更多的model與dataset。我們的PV-RCNN代碼也將于近期整合到PCDet中,敬請(qǐng)關(guān)注。
?
最后簡單聊一下我覺得點(diǎn)云3D檢測還有哪些方向可以試一下。隨著越來越多優(yōu)秀的人涌入做基于點(diǎn)云的3D物體檢測,以及越來越多的開源codebase和數(shù)據(jù)集(KITTI, NuScenes, Waymo等),3D物體檢測的性能在短短兩三年間已經(jīng)被提升了好幾個(gè)檔次。
從目前的情況來看,由于多sensor的同步等問題,純LiDAR的3D檢測算法受到追捧,且達(dá)到了媲美多sensor甚至更強(qiáng)的性能。但我們都知道點(diǎn)云3D物體檢測算法最大的應(yīng)用場景就是自動(dòng)駕駛,其對(duì)可靠性要求很高。而LiDAR捕獲的點(diǎn)云場景包含更多的幾何信息,其語義信息遠(yuǎn)不如圖像,這使得純LiDAR感知算法經(jīng)常出現(xiàn)奇怪的誤檢,且由于點(diǎn)云的稀疏性導(dǎo)致純LiDAR檢測器能識(shí)別的類別有限。所以多模態(tài)的LiDAR+RGB結(jié)合的檢測算法從長遠(yuǎn)來看還是有很大的發(fā)展空間的。
而大部分人之所以醉心于純LiDAR 3D物體檢測,是因?yàn)榛贚iDAR+RGB的3D物體檢測算法面臨一些問題:
(1) 比如LiDAR點(diǎn)云和RGB圖像是來自于不同view的場景表征,如何融合兩者的特征?融合了特征又如何做檢測?之前也有一些方法探索了這個(gè)問題,但還沒看到比較優(yōu)雅的解決方案。
(2) 另一個(gè)問題是純LiDAR的3D物體感知可以做各種各樣的數(shù)據(jù)增強(qiáng),比如將一個(gè)場景中的GT "copy"到另一個(gè)場景。而如果結(jié)合RGB圖像,"copy"的GT在RGB圖像上的特征如何處理,也是一個(gè)難解的問題。
另一方面,隨著Waymo等大規(guī)模的點(diǎn)云數(shù)據(jù)集的發(fā)布(Waymo Open Dataset的每個(gè)scene的檢測范圍已經(jīng)比最早的KITTI大了近4倍),以及自動(dòng)駕駛車上的時(shí)延需求,我們期待出現(xiàn)更高效的3D物體檢測框架。同時(shí)隨著LiDAR傳感器的發(fā)展,如何更高效的檢測更大范圍的點(diǎn)云場景(更密的點(diǎn)+更大的范圍),也是一個(gè)值得探索的方向。
本文僅做學(xué)術(shù)分享,如有侵權(quán),請(qǐng)聯(lián)系刪文。