
單目3D目標檢測之入門
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

來源:古月居
一、單目3D目標檢測
1. 3D目標檢測領域有哪些任務和方法?
為了更直觀,我畫了一個思維導圖,點擊鏈接后,注意需要切換一下思維導圖狀態(tài)。

在3D目標檢測領域,根據輸入信息的不同,大致可分為三類方法。
Point Cloud-based Methods (基于點云來做)
Multimodal Fusion-based Methods(點云和圖像的融合)
Monocular/Stereo Image-based Methods(單目/立體圖像的方法)
首先,基于點云的經典方法,比如VoxelNet(2018年)、PointPillars(2019年)、PointRCNN(2019年)等。
這類方法都是直接在點云數據上進行特征的提取和RPN操作,將2D目標檢測中的網絡結構和思想遷移到3D點云中。
點云和圖像的融合方法是當前3D目標檢測的主流。比較經典的算法有,2018年的MV3D、Frustum PointNets、2019年的Pseudo-LiDAR、2020年的PointPainting等算法。
這里的Pseudo-LiDAR(也叫為激光雷達)這篇文章對后來的單目3D目標檢測領域的發(fā)展起到了促進的作用。
這里使用了雙目圖像來生成深度圖,根據深度圖得到點云數據,再進行目標檢測任務。
Stereo Image-based方法中,主要是基于雙目圖像的3D目標檢測,這一領域我不太了解,以后再做補充。
單目3D目標檢測我是2021年剛接觸的,比較出色的單目3D檢測方法主要有:Mono3D PLiDAR、AutoShape、MonoRCNN、CaDDN等。
而在單目3D目標檢測領域,又可細分為三類方法。關于單目3D目標檢測的分類翻譯自CaDNN這篇文章
直接法(Direct Methods)
所謂直接法就是直接從圖像中估計出3D檢測框,也無需預測中間的3D場景表示[9,52,4,32]。
更進一步的說就是,直接法可以結合2D圖像平面和3D空間的幾何關系來輔助檢測[53,12,40,3]。
例如,可以在圖像平面上估計出某對象的關鍵點,以幫助使用已知幾何結構構建3D box[33,29]。[M3D-RPN][M3D-RPN: monocular 3D region proposal network for object detection. ICCV, 2019.][3]
引入深度感知卷積,它按行劃分輸入并學習每個區(qū)域的no-shared kernels,以學習3D空間中位于相關區(qū)域的特定特征。
可以對場景中的物體進行形狀估計,從而理解三維物體的幾何形狀。
形狀估計可以從3D CAD模型的標記頂點中被監(jiān)督[5,24],或從LiDAR掃描[22],或直接從輸入數據以自我監(jiān)督的方式[2]。
直接法的缺點是檢測框直接從2D圖像中生成,沒有產生明確的深度信息,相對于其它方法,定位性能較差。
基于深度的方法(Depth-Based Methods)
該方法先利用深度估計網絡結構來估計出圖像的像素級深度圖,再將該深度圖作為輸入用于3D目標檢測任務,[論文][Deep ordinal regression network for monocular depth estimation. CVPR, 2018.]。
將估計的深度圖與原圖像結合,再執(zhí)行3D檢測任務的論文有許多[38,64,36,13]。
深度圖可以轉換成3D點云,這種方法被稱為偽激光雷達(Pseudo-LiDAR)[59],或者直接使用[61,65],或者結合圖像信息[62,37]來生成3D目標檢測結果。
基于深度的方法在訓練階段將深度估計從三維目標檢測任務中分離,導致還需要學習用于三維檢測任務的次佳的深度地圖。
如何理解上邊這句話呢?**對于屬于感興趣的目標的像素,應該優(yōu)先考慮獲取精確的深度信息,而對于背景像素則不那么重要,如果深度估計和目標檢測是獨立訓練的,則無法捕捉到這一屬性。
**所以將深度估計和目標檢測任務融合成一個網絡,效果會不會更好呢?
基于網格的方法(Grid-Based Methods)
基于網格的方法通過預測BEV網格表示(BEV grid representation)[48,55],來避免估計用做3D 檢測框架輸入的原始深度值。
具體來說,OFT[48]通過將體素投射到圖像平面和采樣圖像特征來填充體素網格,并將其轉換為BEV表示。
多個體素可以投影到同一圖像特征上,導致特征沿著投影射線重復出現,降低了檢測精度。
2. 什么是單目3D目標檢測?

推薦參考博客:
單目3D目標檢測論文筆記 3D Bounding Box Estimation - 知乎
ICCV 2021 | 悉尼大學&商湯提出GUPNet:單目3D目標檢測新網絡
3.發(fā)展情況
Kitti的3D目標檢測排行中,Car類第一的為SFD,Moderate中達到了84.76%,但是Setting中沒有激光點云的符號。排第7的BtcDet使用了該符號,所示直接處理點云的方法至少達到了82%多的AP。

點云和圖像融合的方法,在Car類的Easy和Moderate類中的AP,其實跟直接處理點云方法的AP差別不是很明顯。
雙目或者說是立體視覺3D目標檢測的方法的AP大概在53%左右。
單目3D目標檢測的AP在16%多吧。

(更新時間,2021年11月12日)
如果要查找更加詳細的論文和模型精度、建議直接看KITTI關于3D目標檢測的榜單:The KITTI Vision Benchmark Suite (cvlibs.net)

這里還有一個純單目3D目標檢測的榜單(包含代碼和論文):
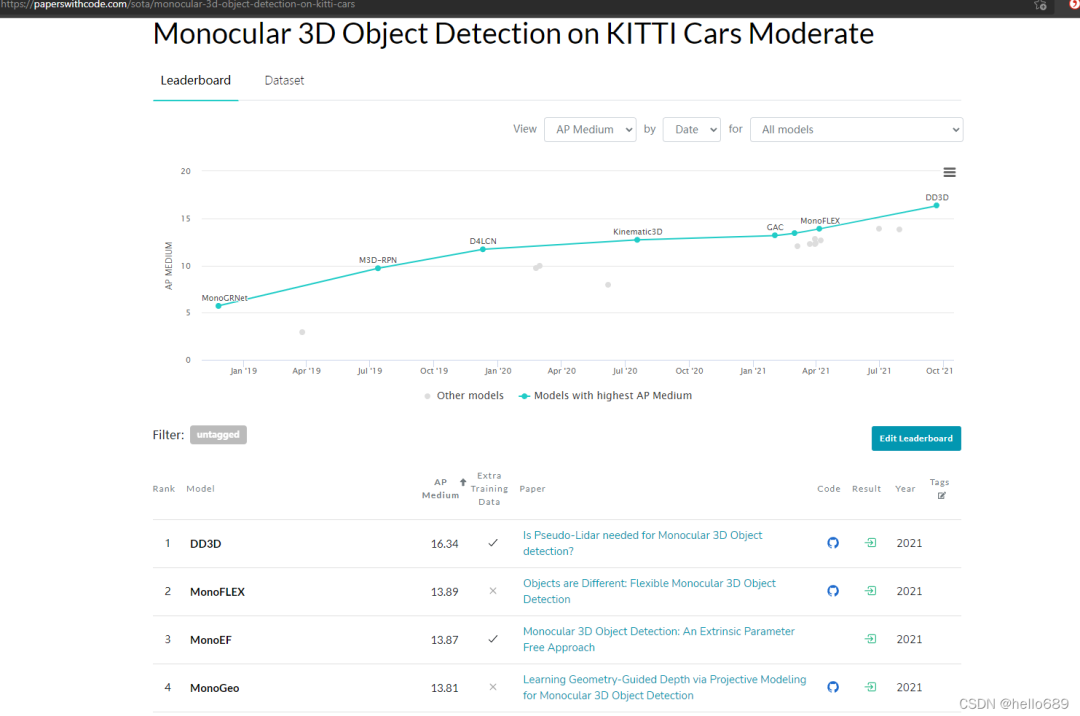
4. 為什么要做單目的3D目標檢測?
為何最近單目3D目標檢測也成為了一個小熱點領域?起因可能是因為:
偽激光雷達技術的提出(pseudo-LiDAR),利用圖像模擬出雷達點云圖像;
單目深度估計的逐漸發(fā)展;
純點云,圖像2D,多傳感器融合檢測的研究逐漸成熟,或者說快要達到天花板了。
從傳感這個角度來說,
主動獲取深度信息:如激光雷達、RGB-D相機
價格昂貴,有效的距離小,并且線數再多的激光雷達獲取的點云也是稀疏的,缺乏紋理信息的。況且激光雷達貴,一輛自動駕駛汽車裝幾個激光雷達、后期怎么維護保養(yǎng),工業(yè)界最看重的是成本問題!!
再說說雙目相機:
誤差較大,要求時間同步,體積較大(基線安裝有要求,如果壞了一個,那就等于報廢)
再說說單目相機:
價格親民
體積小,功耗低;
貼近實際應用需求。
并且,單目3D目標檢測也不一定只能用于自動駕駛呀!只要設備上有攝像頭,有3D檢測的任務。
這里推薦大家一個單目深度估計的小應用場景:https://roxanneluo.github.io/Consistent-Video-Depth-Estimation/;單目3D檢測最重要的一環(huán)就是單目深度估計,而單目深度估計在AR領域是廣泛應用滴。
比如AR虛擬試衣間,或者京東淘寶上的一些AR試鞋,你拿手機攝像頭對著自己腳,鞋自動覆蓋到你腳上,這一塊用到的應該是目標檢測或者語義分割吧。
二、應用場景
推薦點擊在線試鞋,體驗一下AR技術吧。
單目3D目標檢測的具體應用。我隨后會單獨整理在一篇博客中。
三、相關論文
3D目標檢測綜述:
Deep Learning for 3D Point Clouds: A Survey----2020年
3D Object Detection for Autonomous Driving: A Survey—2021年
更多的文獻可查看知乎上的這篇文章:單目3D視覺目標檢測論文總結 - 知乎 (zhihu.com),總結了100多篇單目3D目標檢測領域的文章。
本專欄下,我將會持續(xù)不斷的更新我讀的一些論文和代碼運行工作。
CaDDN:論文閱讀??代碼調試
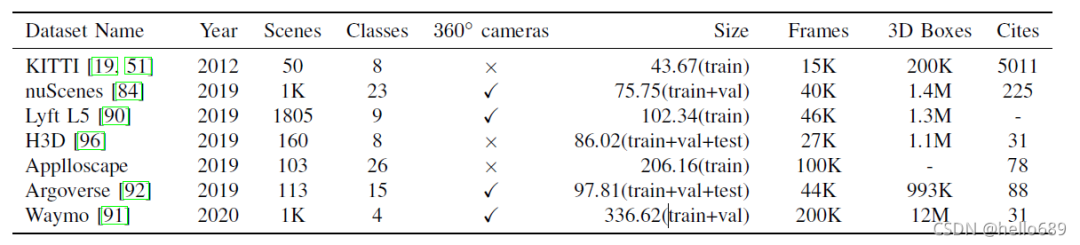
四、相關數據集
這里只列出比較常用的幾個數據集的名字。數據集的詳細說明在這篇博客中。
KITTI Dataset
Waymo Open
NuScenes Dataset
Cityscapes
Lyft L5
H3D
Applloscape
Argoverse
五、自動駕駛領域的相關企業(yè)
百度華為地平線,小鵬蔚來特斯拉。還挺押韻滴!
國外:Waymo、Cruise、Nuro、Argo;
國內:百度、華為、AutoX、圖森未來、Pony(小馬智行)、Weride(文遠知行)、Didi(滴滴)、Momenta、縱目科技、智加科技、小鵬、蔚來、理想、嬴徹科技、魔視智能。
每個公司詳細介紹:
國內:百度、華為、AutoX、圖森未來、Pony(小馬智行)、Weride(文遠知行)、Didi(滴滴)、Momenta、縱目科技、智加科技、小鵬、蔚來、理想、嬴徹科技、魔視智能。
每個公司詳細介紹,我將單獨整理在一篇博客中,包括公司的背景、薪資情況、主要發(fā)展方向。
版權聲明:本文為CSDN博主「hello689」的原創(chuàng)文章,遵循CC 4.0 BY-SA版權協(xié)議,轉載請附上原文出處鏈接及本聲明。
原文鏈接:
https://blog.csdn.net/jiachang98/article/details/121432839
下載1:OpenCV-Contrib擴展模塊中文版教程
在「小白學視覺」公眾號后臺回復:擴展模塊中文教程,即可下載全網第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標跟蹤、生物視覺、超分辨率處理等二十多章內容。
下載2:Python視覺實戰(zhàn)項目52講
在「小白學視覺」公眾號后臺回復:Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數、添加眼線、車牌識別、字符識別、情緒檢測、文本內容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學校計算機視覺。
下載3:OpenCV實戰(zhàn)項目20講
在「小白學視覺」公眾號后臺回復:OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現20個實戰(zhàn)項目,實現OpenCV學習進階。
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據研究方向邀請進入相關微信群。請勿在群內發(fā)送廣告,否則會請出群,謝謝理解~