
MEA:視覺無監(jiān)督訓練新范式
 點藍色字關注“機器學習算法工程師”
點藍色字關注“機器學習算法工程師”
設為星標,干貨直達!
近日,F(xiàn)AIR的最新論文Masked Autoencoders Are Scalable Vision Learners(何愷明一作)提出了一種更簡單有效的用于ViT無監(jiān)督訓練的方法MAE,并在ImageNet-1K數(shù)據(jù)集上的top-1 acc達到新的SOTA:87.8%(無額外訓練數(shù)據(jù))。自從ViT火了之后,一些研究者就開始嘗試研究ViT的無監(jiān)督學習,比如Mocov3用對比學習的方法無監(jiān)督訓練ViT,此外也有一些研究開始借鑒BERT中的MLM(masked language modeling)方法,比如BEiT提出了用于圖像的無監(jiān)督學習方法:MIM(masked image modeling)。無疑,MAE方法也落在MIM的范疇,但整個論文會給人更震撼之感,因為MEA方法更簡單有效。
NLP領域的BERT提出的預訓練方法本質上也是一種masked autoencoding:去除數(shù)據(jù)的一部分然后學習恢復。這種masked autoencoding方法也很早就在圖像領域應用,比如Stacked Denoising Autoencoders。但是NLP領域已經在BERT之后采用這種方法在無監(jiān)督學習上取得非常大的進展,比如目前已經可以訓練超過1000億參數(shù)的大模型,但是圖像領域卻遠遠落后,而且目前主流的無監(jiān)督訓練還是對比學習。那么究竟是什么造成了masked autoencoding方法在NLP和CV上的差異呢?MEA論文從三個方面做了分析,這也是MEA方法的立意:
圖像的主流模型是CNN,而NLP的主流模型是transformer,CNN和transformer的架構不同導致NLP的BERT很難直接遷移到CV。但是vision transformer的出現(xiàn)已經解決這個問題; 圖像和文本的信息密度不同,文本是高語義的人工創(chuàng)造的符號,而圖像是一種自然信號,兩者采用masked autoencoding建模任務難度就不一樣,從句子中預測丟失的詞本身就是一種復雜的語言理解任務,但是圖像存在很大的信息冗余,一個丟失的圖像塊很容易利用周邊的圖像區(qū)域進行恢復; 用于重建的decoder在圖像和文本任務發(fā)揮的角色有區(qū)別,從句子中預測單詞屬于高語義任務,encoder和decoder的gap小,所以BERT的decoder部分微不足道(只需要一個MLP),而對圖像重建像素屬于低語義任務(相比圖像分類),encoder需要發(fā)揮更大作用:將高語義的中間表征恢復成低語義的像素值。
基于這三個的分析,論文提出了一種用于圖像領域(ViT模型)的更簡單有效的無監(jiān)督訓練方法:MAE(masked autoencoder),隨機mask掉部分patchs然后進行重建,其整體架構如下所示。MAE采用encoder-decoder結構(分析3,需要單獨的decoder),但屬于非對稱結構,一方面decoder采用比encoder更輕量級設計,另外一方面encoder只處理一部分patchs(visible patchs,除了masked patchs之外的patchs),而encoder處理所有的patchs。一個很重要的點,MEA采用很高的masking ratio(比如75%甚至更高),這契合分析2,這樣構建的學習任務大大降低了信息冗余,也使得encoder能學習到更高級的特征。由于encoder只處理visible patchs,所以很高的masking ratio可以大大降低計算量。
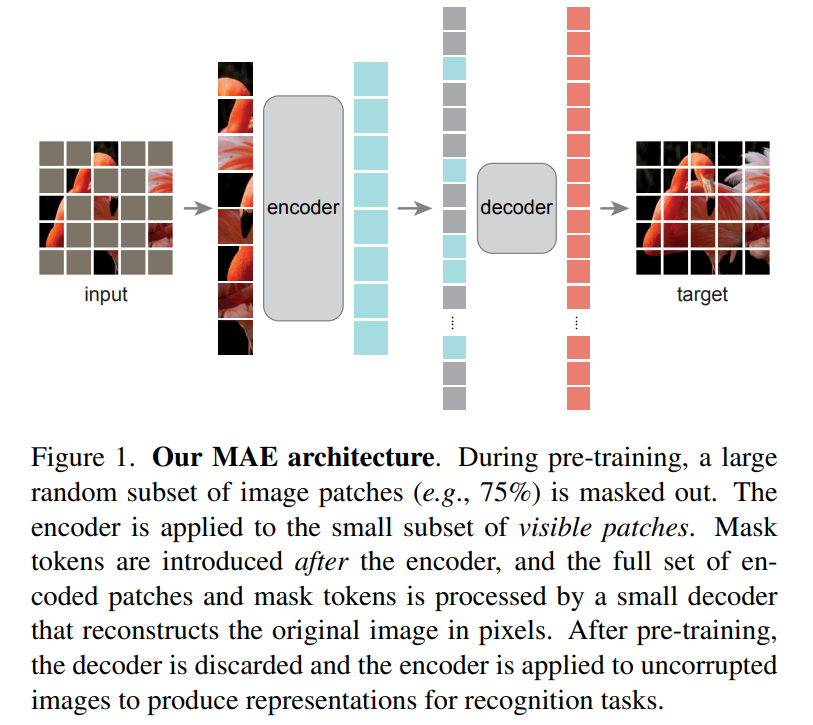
MEA采用的masking策略是簡單的隨機mask:基于均勻分布從圖像的patchs隨機抽樣一部分patchs進行mask。每個被mask的patch采用mask token來替代,mask token是一個共享且可學習的向量。MEA的encoder采用ViT模型,只處理visible patchs,visible patchs通過linear projection得到patch embedding輸入到ViT的transformer blocks進行處理;而decoder是一個輕量級模塊,主體包含幾個transformer blocks,而最后一層是一個linear層(輸出是和一個patch像素數(shù)一致),用來直接預測masked patch的像素值。decoder的輸入是所有的tokens:encoded visible patchs和mask tokens,它們要加上對應的positional embeddings。訓練的loss采用簡單的MSE:計算預測像素值和原始像素值的均方誤差,不過loss只計算masked patchs。MEA的實現(xiàn)非常簡單:首先對輸入的patch進行l(wèi)inear projection得到patch embeddings,并加上positional embeddings(采用sine-cosine版本);然后對tokens列表進行random shuffle,根據(jù)masking ratio去掉列表中后面的一部分tokens,然后送入encoder中,這里注意ViT中需要一個class token來做圖像分類,所以這里的輸入也要增加一個dummy token(如果最后分類采用global avg pooling就不需要這個);encoder處理后,在tokens列表后面補足mask tokens,然后通過unshuffle來恢復tokens列表中tokens的原始位置,然后再加上positional embeddings(mask tokens本身并無位置信息,所以還要此操作)送入decoder中進行處理。
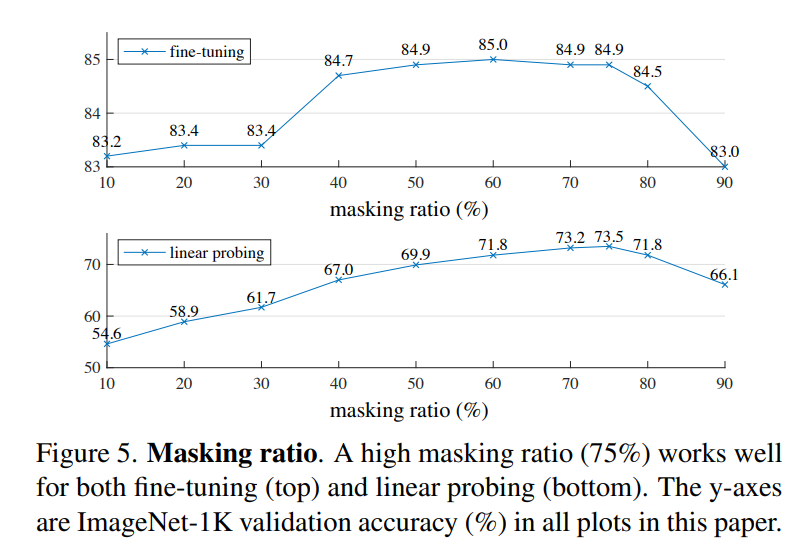
論文選擇ViT-Large(ViT-L/16)作為encoder在ImageNet-1K上實驗,首先進行無監(jiān)督預訓練,然后進行監(jiān)督訓練以評估encoder的表征能力,包括常用linear probing和finetune兩個實驗結果。下表是baseline MEA方法的實驗結果,可以看到經過MEA預訓練后finetune的效果要超過直接從頭訓練(84.9 vs 82.5):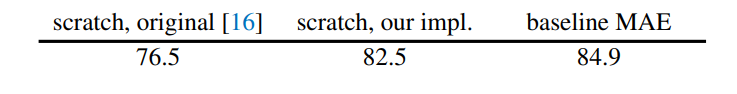 更重要的是,論文做了MEA各個部分的不同設置對比實驗,這些實驗能夠揭示MEA更多的特性。首先是masking ratio,從下圖可以看到,最優(yōu)的設置是75%的masking ratio,此時linear probing和finetune效果最好,這比之前的研究要高很多,比如BEiT的masking ratio是40%。另外也可以看到linear probing和finetune的表現(xiàn)不一樣,linear probing效果隨著masking ratio的增加逐漸提高直至一個峰值后出現(xiàn)下降,而finetune效果在不同making ratio下差異小,masking ratio在40%~80%范圍內均能表現(xiàn)較好。
更重要的是,論文做了MEA各個部分的不同設置對比實驗,這些實驗能夠揭示MEA更多的特性。首先是masking ratio,從下圖可以看到,最優(yōu)的設置是75%的masking ratio,此時linear probing和finetune效果最好,這比之前的研究要高很多,比如BEiT的masking ratio是40%。另外也可以看到linear probing和finetune的表現(xiàn)不一樣,linear probing效果隨著masking ratio的增加逐漸提高直至一個峰值后出現(xiàn)下降,而finetune效果在不同making ratio下差異小,masking ratio在40%~80%范圍內均能表現(xiàn)較好。
 這么高的masking ratio,模型到底能學習到什么?這里采用預訓練好的模型在驗證集進行重建,效果如下所示,可以看到decoder重建出來的圖像還是比較讓人驚艷的(95%的masking ratio竟然也能work!),這或許說明模型已經學習到比較好的特征。
這么高的masking ratio,模型到底能學習到什么?這里采用預訓練好的模型在驗證集進行重建,效果如下所示,可以看到decoder重建出來的圖像還是比較讓人驚艷的(95%的masking ratio竟然也能work!),這或許說明模型已經學習到比較好的特征。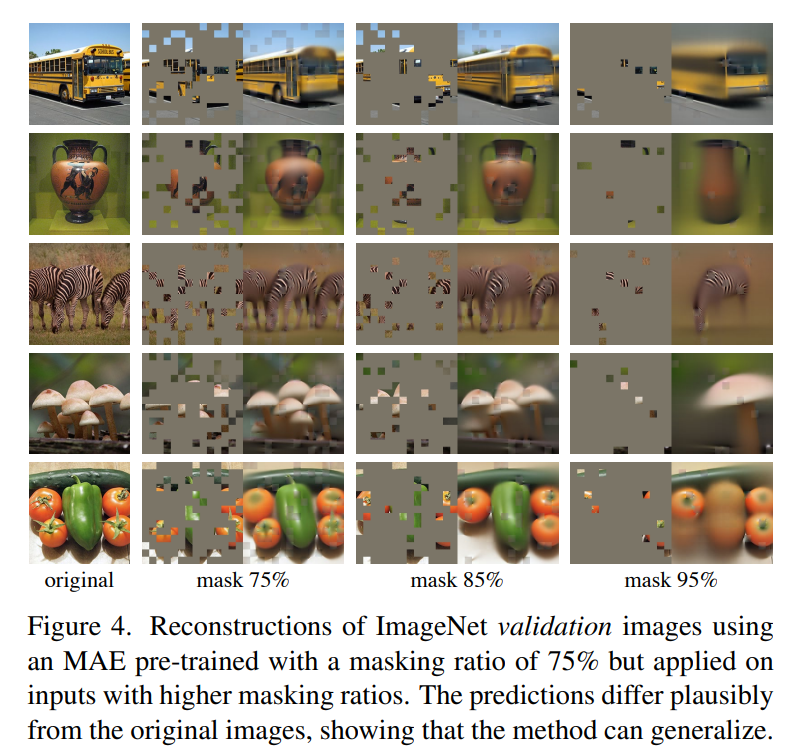 第二個是encoder的設計,這里主要探討decoder的深度(transformer blocks數(shù)量)和寬度(channels數(shù)量)對效果的影響,實驗結果如下表所示。首先,要想得到比較好的linear probing效果,就需要一個比較深的decoder,這不難理解,前面說過重建圖像和圖像識別兩個任務的gap較大,如果decoder比較深,那么decoder就有足夠的容量學習到重建能力,這樣encoder可以更專注于提取特征。但是不同的深度對finetune效果影響較小,只用一個transformer block就可以work。相比之下,網絡寬度對linear probing影響比網絡深度要小一點。論文選擇的默認設置是:8個blocks,width為512,一個token的FLOPs只有encoder的9%。
第二個是encoder的設計,這里主要探討decoder的深度(transformer blocks數(shù)量)和寬度(channels數(shù)量)對效果的影響,實驗結果如下表所示。首先,要想得到比較好的linear probing效果,就需要一個比較深的decoder,這不難理解,前面說過重建圖像和圖像識別兩個任務的gap較大,如果decoder比較深,那么decoder就有足夠的容量學習到重建能力,這樣encoder可以更專注于提取特征。但是不同的深度對finetune效果影響較小,只用一個transformer block就可以work。相比之下,網絡寬度對linear probing影響比網絡深度要小一點。論文選擇的默認設置是:8個blocks,width為512,一個token的FLOPs只有encoder的9%。 第三個是mask token,這里探討的是encoder是否處理mask tokens帶來的影響,從對比實驗來看,encoder不處理mask tokens不僅效果更好而且訓練更高效,首先linear probing的效果差異非常大,如果encoder也處理mask tokens,此時linear probing的效果較差,這主要是訓練和測試的不一致帶來的,因為測試時都是正常的圖像,但經過finetune后也能得到較好的效果。最重要的是,不處理mask tokens模型的FLOPs大大降低(3.3x),而且訓練也能加速2.8倍,這里也可以看到采用較小的decoder可以進一步加速訓練。
第三個是mask token,這里探討的是encoder是否處理mask tokens帶來的影響,從對比實驗來看,encoder不處理mask tokens不僅效果更好而且訓練更高效,首先linear probing的效果差異非常大,如果encoder也處理mask tokens,此時linear probing的效果較差,這主要是訓練和測試的不一致帶來的,因為測試時都是正常的圖像,但經過finetune后也能得到較好的效果。最重要的是,不處理mask tokens模型的FLOPs大大降低(3.3x),而且訓練也能加速2.8倍,這里也可以看到采用較小的decoder可以進一步加速訓練。
第四個是探討不同的重建目標對效果的影響,從對比實驗看,如果對像素值做歸一化處理(用patch所有像素點的mean和std),效果有一定提升,采用PCA處理效果無提升。這里也實驗了BEiT采用的dVAE tokenizer,此時訓練loss是交叉熵,從效果上看比baseline有一定提升(finetune有提升,但是linear probing下降),但不如歸一化處理的結果。注意的是dVAE tokenizer需要非常大的數(shù)據(jù)來單獨訓練,這是非常不方便的。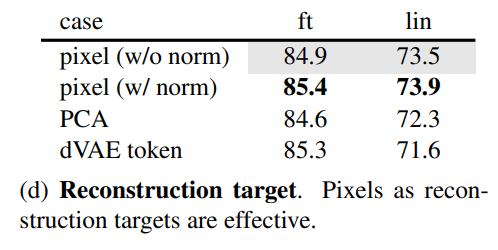 第五個是數(shù)據(jù)增強的影響,這里讓人驚奇的是MEA在無數(shù)據(jù)增強下(center crop)依然可以表現(xiàn)出好的效果,如果采用random crop(固定size或隨機size)+random horizontal flipping(其實也屬于輕量級)效果有微弱的提升,但加上color jit效果反而有所下降。相比之下,對比學習往往需要非常heavy的數(shù)據(jù)增強。這差異的背后主要是因為MEA采用的random mask patch已經起到了數(shù)據(jù)增強的效果。
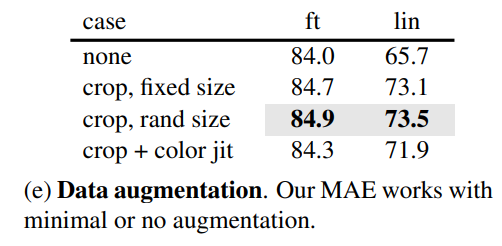
第五個是數(shù)據(jù)增強的影響,這里讓人驚奇的是MEA在無數(shù)據(jù)增強下(center crop)依然可以表現(xiàn)出好的效果,如果采用random crop(固定size或隨機size)+random horizontal flipping(其實也屬于輕量級)效果有微弱的提升,但加上color jit效果反而有所下降。相比之下,對比學習往往需要非常heavy的數(shù)據(jù)增強。這差異的背后主要是因為MEA采用的random mask patch已經起到了數(shù)據(jù)增強的效果。
 第六個是mask sampling策略的影響,相比BEiT采用的block-wise或grid-wise方式,random sampling效果最好。
第六個是mask sampling策略的影響,相比BEiT采用的block-wise或grid-wise方式,random sampling效果最好。
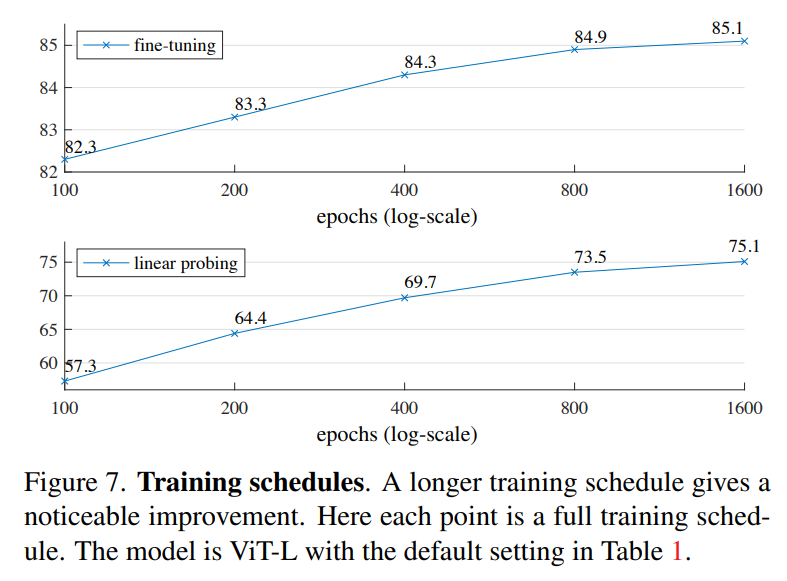
另外,論文也發(fā)現(xiàn)MEA和對比學習方法在training schedule上也存在差異,之前的實驗都是基于800 epoch的訓練時長,而實驗發(fā)現(xiàn)訓練到更長的epoch(1600 epoch+),模型的linear probing性能依然還在上升,而MoCoV3在300 epoch后就飽和了。不過,MEA在75%的masking ratio下每個epoch其實只相當于見了25%的數(shù)據(jù),而對比學習往往學習two-crop和multi-crop,每個epoch見到的數(shù)據(jù)在200%以上,這也意味著MEA可以訓練更多的epoch。雖然MEA訓練更長,但是由于其特殊的設置,基于ViT-L的MEA訓練1600 epoch的時長比MoCoV3訓練300 epoch還要短(31h vs 36h)。
MEA與其它無監(jiān)督方法的對比如下所示,可以看到在同樣條件下MEA要比BEiT更好,而且也超過有監(jiān)督訓練,其中ViT-H在448大小finetune后在ImageNet上達到了87.8%的top1 acc。不過MEA的效果還是比谷歌采用JFT300M訓練的ViT要差一些,這說明訓練數(shù)據(jù)量可能是一個瓶頸。 同時,論文也對比了MEA訓練的encoder在下游任務(檢測和分割)的遷移能力,同等條件下,MEA均能超過有監(jiān)督訓練或者其它無監(jiān)督訓練方法:
同時,論文也對比了MEA訓練的encoder在下游任務(檢測和分割)的遷移能力,同等條件下,MEA均能超過有監(jiān)督訓練或者其它無監(jiān)督訓練方法:
論文最后還有一個額外的部分,那就是對linear probing評估方式的討論。從前面的實驗我們看到,雖然MEA訓練的encoder在finetune下能取得比較SOTA的結果,但是其linear probing和finetune效果存在不小的差異,單從linear probing效果來看,MEA并不比MoCoV3要好(ViT-L:73.5 vs 77.6)。雖然linear probing一直是無監(jiān)督訓練的最常用的評估方法,但是它追求的是encoder提取特征的線性可分能力,這不并能成為唯一的一個評價指標,而且linear probing也不能很好地和下游任務遷移能力關聯(lián)起來。所以論文額外做了partial fine-tuning的實驗,這里可以看到如果僅對encoder的最后一個block進行finetune的話,MAE就能達到和MoCoV3一樣的效果,如果finetune更多的blocks,MAE就會超過MoCoV3。這說明雖然MAE得到的特征線性可分能力差了點,但是它其實是更強的非線性特征。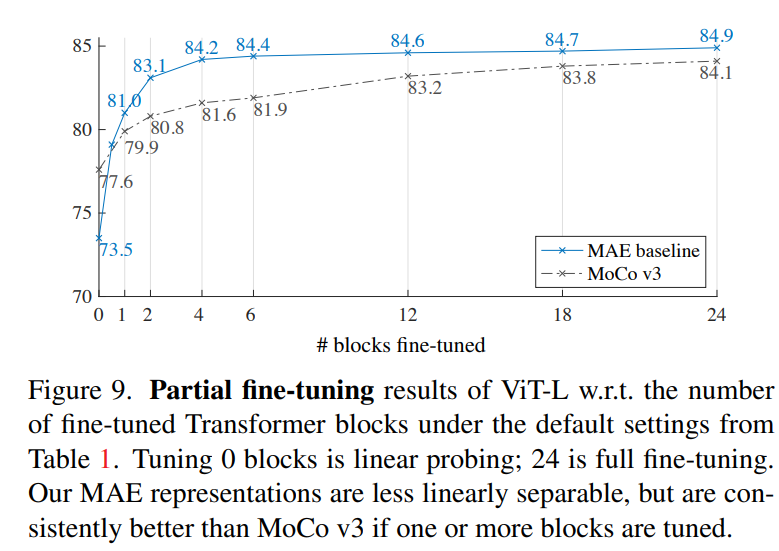
最后談一點自己對MEA的認識:首先MEA并不是第一個基于MIM方法做無監(jiān)督訓練,之前微軟的BEiT基于MIM也取得了很好的效果,還有MST和iBOT等工作。但是MEA讓人看起來更簡單有效,比如BEiT需要單獨訓練的tokenizer,而其它的一些工作往往引入了對比學習的類似設計。對于MEA的成功,我覺得是一些突破常規(guī)的設計,比如很高的masking ratio,這是很難想象會work的,但MEA卻證明了這是成功的關鍵。
參考
Mocov3: An Empirical Study of Training Self-Supervised Vision Transformers DINO: Emerging Properties in Self-Supervised Vision Transformers MST: Masked Self-Supervised Transformer for Visual Representation BEiT: BERT Pre-Training of Image Transformers EsViT: Efficient Self-supervised Vision Transformers for Representation Learning Image BERT Pre-training with Online Tokenizer Masked Autoencoders Are Scalable Vision Learners
推薦閱讀
PyTorch1.10發(fā)布:ZeroRedundancyOptimizer和Join
谷歌AI用30億數(shù)據(jù)訓練了一個20億參數(shù)Vision Transformer模型,在ImageNet上達到新的SOTA!
"未來"的經典之作ViT:transformer is all you need!
PVT:可用于密集任務backbone的金字塔視覺transformer!
漲點神器FixRes:兩次超越ImageNet數(shù)據(jù)集上的SOTA
不妨試試MoCo,來替換ImageNet上pretrain模型!
機器學習算法工程師
? ??? ? ? ? ? ? ? ? ? ? ????????? ??一個用心的公眾號
