本文為論文,建議閱讀5分鐘
我們提出了統(tǒng)一自監(jiān)督視覺預(yù)訓練(UniVIP)
論文標題:UniVIP: A Unified Framework for Self-Supervised Visual Pre-training
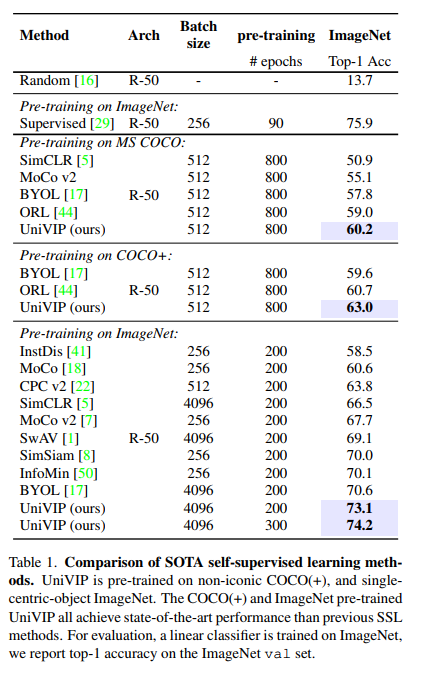
論文鏈接:https://arxiv.org/abs/2203.06965作者單位:中國科學院自動化研究所 & 商湯科技 & 南洋理工大學自監(jiān)督學習 (SSL) 有望利用大量未標記的數(shù)據(jù)。然而,流行的 SSL 方法的成功僅限于像 ImageNet 中的單中心對象圖像,并且忽略了場景和實例之間的相關(guān)性,以及場景中實例的語義差異。為了解決上述問題,我們提出了統(tǒng)一自監(jiān)督視覺預(yù)訓練(UniVIP),這是一種新穎的自監(jiān)督框架,用于在單中心對象或非標志性數(shù)據(jù)集上學習通用視覺表示。該框架考慮了三個層次的表示學習:1)場景-場景的相似性,2)場景-實例的相關(guān)性,3)實例的判別。在學習過程中,我們采用最優(yōu)傳輸算法來自動測量實例的區(qū)分度。大量實驗表明,在非標志性 COCO 上預(yù)訓練的 UniVIP 在圖像分類、半監(jiān)督學習、對象檢測和分割等各種下游任務(wù)上實現(xiàn)了最先進的傳輸性能。此外,我們的方法還可以利用 ImageNet 等單中心對象數(shù)據(jù)集,并且在線性探測中使用相同的預(yù)訓練 epoch 時比 BYOL 高 2.5%,并且在 COCO 數(shù)據(jù)集上超越了當前的自監(jiān)督對象檢測方法,證明了它的普遍性和潛在性能。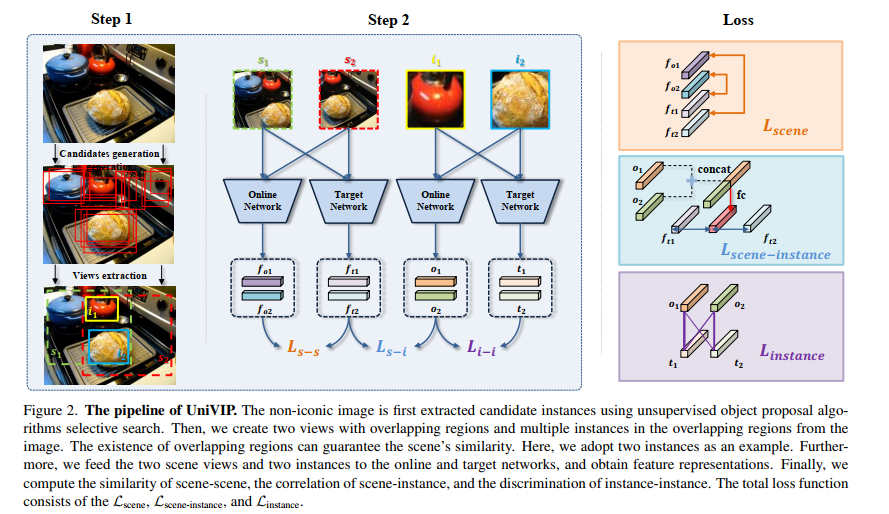


 下載APP
下載APP