
用Python爬取Bilibili上二次元妹子的視頻

一直想爬取BiliBili的視頻,無奈一直沒有去研究一下。
最近,在旭哥的指點(diǎn)之下,用了Fiddler抓包,抓到了一直期待的視頻包,完成了下載。
下面寫一下我做這個(gè)爬蟲的過程。
# 相關(guān)依賴? :Fiddler+Python3 + Requests
下面看一下我做這個(gè)爬蟲的具體步驟:
1. 進(jìn)入某個(gè)具體視頻的頁面抓取視頻包測試。
進(jìn)入這個(gè)頁面:https://www.bilibili.com/video/av26019104,如下圖所示。點(diǎn)擊播放按鈕。
可以看到Fiddler已經(jīng)抓到了很多包。別著急,現(xiàn)在還沒有視頻包出現(xiàn)。由于需要時(shí)間下載,所以具體視頻包會過一會才能彈出來。
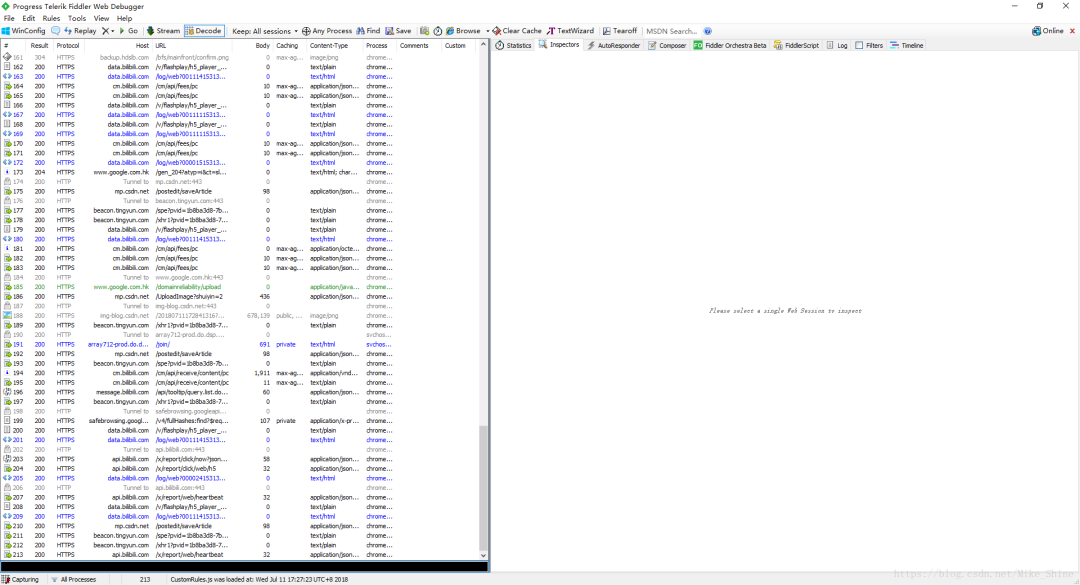
過大概一兩分鐘,就會看到這個(gè)包,如下圖。可以清楚的看到這個(gè)是Flv形式的視頻流的包,看這個(gè)包的大小也可以看出來,是相當(dāng)?shù)拇蟆?/span>
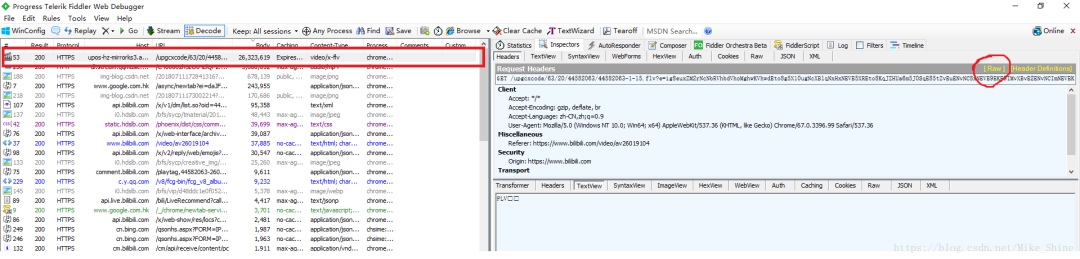
下面分析一下這個(gè)包的具體參數(shù)。點(diǎn)擊上圖紅色圈圈那個(gè)“Raw",會彈出下面這個(gè)窗口
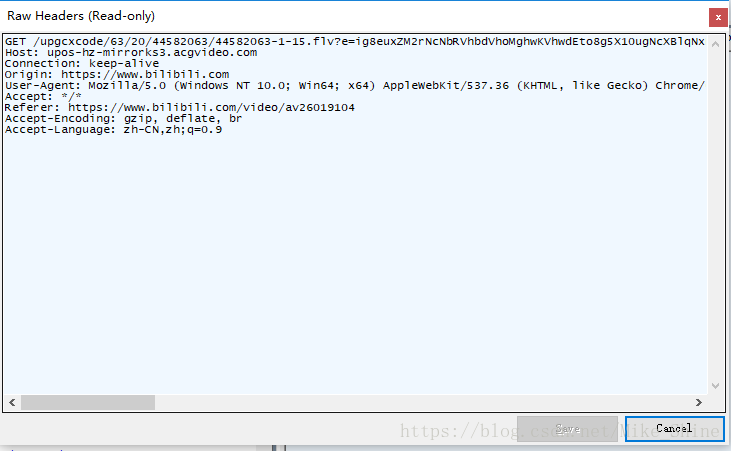
可以看到是一個(gè)Get請求,請求的url和Headers都很清楚。
這時(shí)候就可以實(shí)驗(yàn)一下,來寫一小段代碼測試一下是否可以通過requests.get()方法來下載視頻。
#######################################################################import?requestswith?open("D:\video\bilibili.mp4")?as?f:f.write(requests.get(url,?headers?=?headers,?verify?=?False).content)???????#這里的Verify=False是跳過證書認(rèn)證??print("下載完成") #?這里只是寫了核心部分,headers和url沒有寫,直接copy過來就好了,#?注意Url前面要加Host.???真正的請求地址是http://主機(jī)Host地址/upgcx.......############################################################################
可以看到如果你運(yùn)行這段代碼,已經(jīng)可以把視頻下載到了本地。
這里你可以多試幾個(gè)視頻,可能會發(fā)現(xiàn),有些視頻按照抓包得到的Headers,請求之后只能Get到一部分視頻,比如視頻8M,你Get到只有2M。你去看一下Headers就會發(fā)現(xiàn),他多了一個(gè)Range參數(shù)。把這個(gè)刪除掉,就可以下載了。
經(jīng)過我的實(shí)驗(yàn),所有視頻請求的Headers格式都可以統(tǒng)一為下圖這樣。里面有2個(gè)參數(shù)哈。
1.host,主機(jī)名,就是從你爬出來的URL中正則出來的host
2. 視頻標(biāo)號。
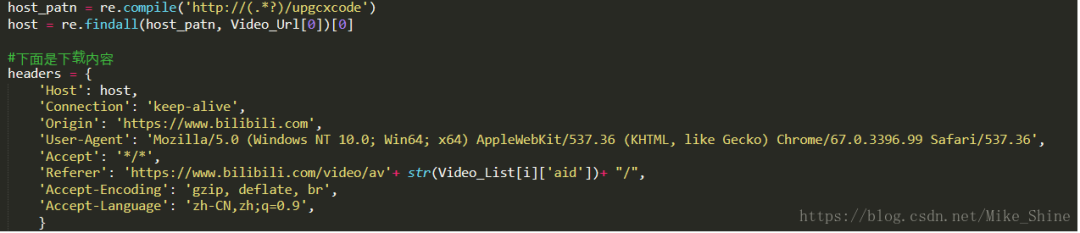
2. 獲取請求Headers參數(shù)和請求源URL:
要找URL,可以看一下URL中的內(nèi)容,里面的hfa=xxxxxxxx和hfb=xxxxxxx應(yīng)該是加密的?這可怎么辦。這時(shí)候用Fiddler,從抓來的包里搜索一下這兩個(gè)參數(shù),肯定藏在某個(gè)包里。用CTRL + F 輸入hfa 搜索。可以看到包含HFA關(guān)鍵字的包都被找出來了。
進(jìn)去一看,其實(shí)包含在網(wǎng)頁源代碼的包,也就是說URL中的參數(shù)包含在網(wǎng)頁源代碼里。
回到最初的那個(gè)視頻頁面,看一下網(wǎng)頁源代碼。搜索一下URL。
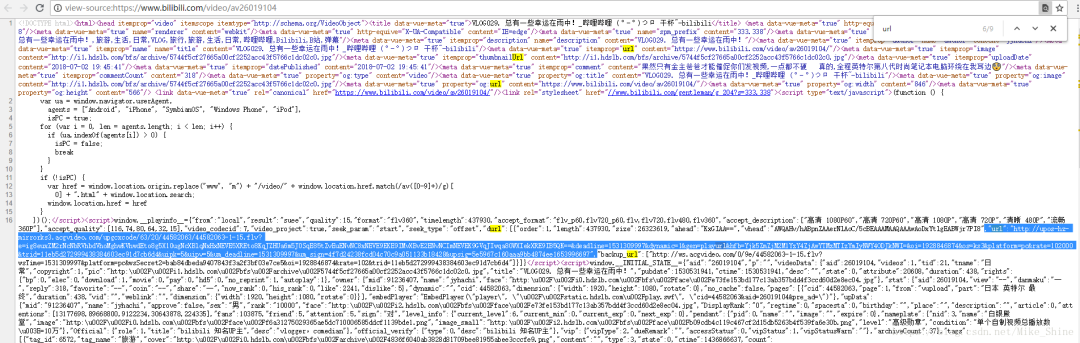
驚喜的發(fā)現(xiàn),其實(shí)整個(gè)URL都在網(wǎng)頁源碼里。這豈不是太簡單了。
不過需要注意的是,這個(gè)URL中含有的hfa等加密部分是會動態(tài)變化的。所以在最終腳本的代碼結(jié)構(gòu)中,需要拿一個(gè)URL,及時(shí)用來做get請求。下載完成之后再拿下一個(gè)URL。
我之前就犯過這樣的錯(cuò),由于URL過期,導(dǎo)致部分視頻下載不到。
3. 從UP主的主頁爬取所有視頻的信息(視頻編號,標(biāo)題)。
在之前的實(shí)驗(yàn)之上,現(xiàn)在只要有視頻編號,我們就可以下載到對應(yīng)的視頻了。所以接下來要做的工作就是從Up主的主頁來獲取所有的視頻信息。
訪問某個(gè)Up主的主頁
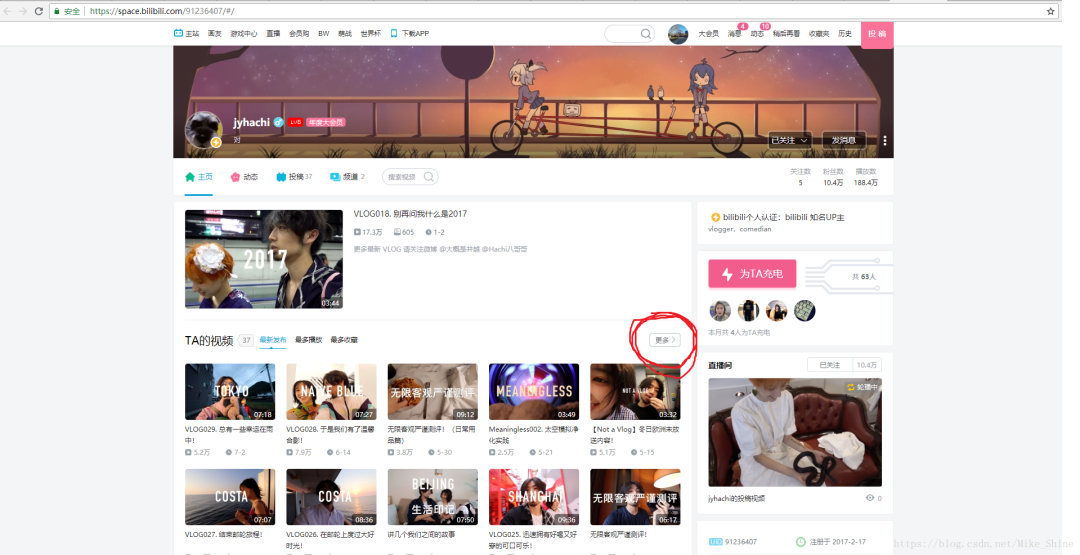
點(diǎn)擊圈圈的更多,可以進(jìn)入所有視頻的頁面。
這時(shí)候看Filddler抓包的結(jié)果,看到這個(gè)json包,里面包含了本頁所有視頻的信息。
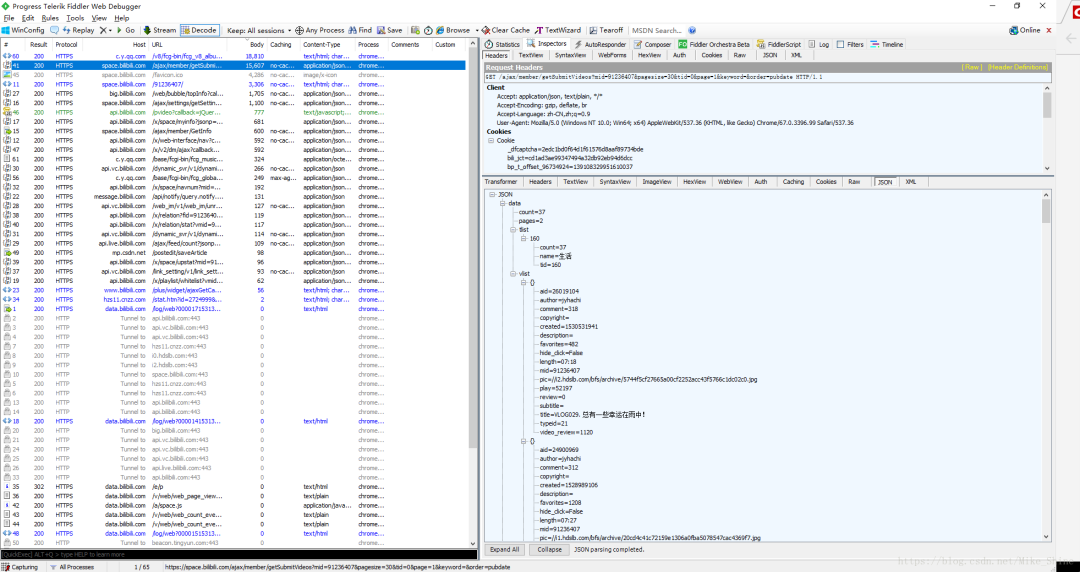
同樣,看一下包頭。如下圖
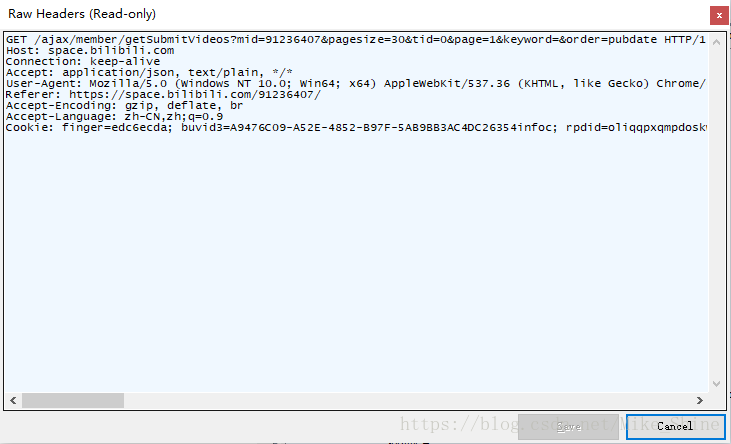
也做一下實(shí)驗(yàn),可以發(fā)現(xiàn)Cookie是不必須的參數(shù)。
同之前下載視頻的Get方法,同樣可以Get到這個(gè)Json包。然后就可以把內(nèi)容通過Json解析的語句拿出來。
這里我并沒有做翻頁的工作,而是直接請求了100個(gè)視頻。想做翻頁的同學(xué),加一點(diǎn)代碼就好了。
評論
圖片
表情