
【NLP】從頭開(kāi)始學(xué)詞向量的預(yù)訓(xùn)練
? 磐創(chuàng)AI分享??
? 磐創(chuàng)AI分享??
作者 | ARAVIND PAI?
編譯 | VK?
來(lái)源 | Analytics Vidhya
概述
理解預(yù)訓(xùn)練詞嵌入的重要性
了解兩種流行的預(yù)訓(xùn)練詞嵌入類(lèi)型:Word2Vec和GloVe
預(yù)訓(xùn)練詞嵌入與從頭學(xué)習(xí)嵌入的性能比較
介紹
我們?nèi)绾巫寵C(jī)器理解文本數(shù)據(jù)?我們知道機(jī)器非常擅長(zhǎng)處理和處理數(shù)字?jǐn)?shù)據(jù),但如果我們向它們提供原始文本數(shù)據(jù),它們是不能理解的。
這個(gè)想法是創(chuàng)建一個(gè)詞匯的表示,捕捉它們的含義、語(yǔ)義關(guān)系和它們所使用的不同類(lèi)型的上下文。這就是詞嵌入的想法,將文本用數(shù)字表示。
預(yù)訓(xùn)練詞嵌入是當(dāng)今自然語(yǔ)言處理(NLP)領(lǐng)域中的一個(gè)重要組成部分。
但是,問(wèn)題仍然存在——預(yù)訓(xùn)練的單詞嵌入是否為我們的NLP模型提供了額外的優(yōu)勢(shì)?這是一個(gè)重要的問(wèn)題,你應(yīng)該知道答案。
因此在本文中,我將闡明預(yù)訓(xùn)練詞嵌入的重要性。對(duì)于一個(gè)情感分析問(wèn)題,我們還將比較預(yù)訓(xùn)練詞嵌入和從頭學(xué)習(xí)嵌入的性能。
目錄
什么是預(yù)訓(xùn)練詞嵌入?
為什么我們需要預(yù)訓(xùn)練的詞嵌入?
預(yù)訓(xùn)練詞嵌入的不同模型?
谷歌的Word2vec
斯坦福的GloVe
案例研究:從頭開(kāi)始學(xué)習(xí)嵌入與預(yù)訓(xùn)練詞嵌入
什么是預(yù)訓(xùn)練詞嵌入?
讓我們直接回答一個(gè)大問(wèn)題——預(yù)訓(xùn)練詞嵌入到底是什么?
?預(yù)訓(xùn)練詞嵌入是在一個(gè)任務(wù)中學(xué)習(xí)到的詞嵌入,它可以用于解決另一個(gè)任務(wù)。
?
這些嵌入在大型數(shù)據(jù)集上進(jìn)行訓(xùn)練,保存,然后用于解決其他任務(wù)。這就是為什么預(yù)訓(xùn)練詞嵌入是遷移學(xué)習(xí)的一種形式。
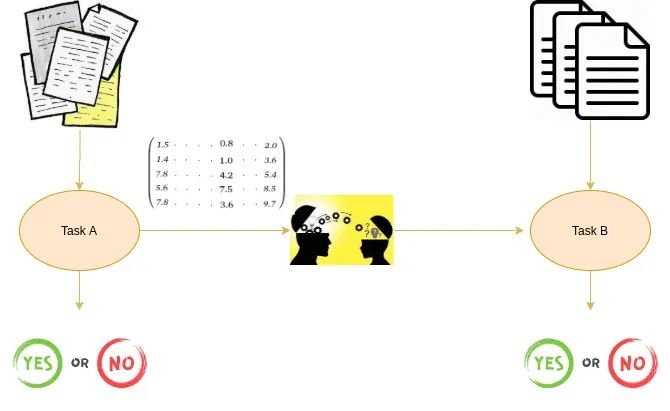
遷移學(xué)習(xí),顧名思義,就是把一項(xiàng)任務(wù)的學(xué)習(xí)成果轉(zhuǎn)移到另一項(xiàng)任務(wù)上。學(xué)習(xí)既可以是權(quán)重,也可以是嵌入。在我們這里,學(xué)習(xí)的是嵌入。因此,這個(gè)概念被稱(chēng)為預(yù)訓(xùn)練詞嵌入。在權(quán)重的情況下,這個(gè)概念被稱(chēng)為預(yù)訓(xùn)練模型。
但是,為什么我們首先需要預(yù)訓(xùn)練詞嵌入呢?為什么我們不能從零開(kāi)始學(xué)習(xí)我們自己的嵌入呢?我將在下一節(jié)回答這些問(wèn)題。
為什么我們需要預(yù)訓(xùn)練詞嵌入?
預(yù)訓(xùn)練詞嵌入在大數(shù)據(jù)集上訓(xùn)練時(shí)捕獲單詞的語(yǔ)義和句法意義。它們能夠提高自然語(yǔ)言處理(NLP)模型的性能。這些單詞嵌入在競(jìng)賽數(shù)據(jù)中很有用,當(dāng)然,在現(xiàn)實(shí)世界的問(wèn)題中也很有用。
但是為什么我們不學(xué)習(xí)我們自己的嵌入呢?好吧,從零開(kāi)始學(xué)習(xí)單詞嵌入是一個(gè)具有挑戰(zhàn)性的問(wèn)題,主要有兩個(gè)原因:
訓(xùn)練數(shù)據(jù)稀疏
大量可訓(xùn)練參數(shù)
訓(xùn)練數(shù)據(jù)稀疏
不這樣做的主要原因之一是訓(xùn)練數(shù)據(jù)稀少。大多數(shù)現(xiàn)實(shí)世界的問(wèn)題都包含一個(gè)包含大量稀有單詞的數(shù)據(jù)集。從這些數(shù)據(jù)集中學(xué)習(xí)到的嵌入無(wú)法得到單詞的正確表示。
為了實(shí)現(xiàn)這一點(diǎn),數(shù)據(jù)集必須包含豐富的詞匯表。
大量可訓(xùn)練參數(shù)
其次,從零開(kāi)始學(xué)習(xí)嵌入時(shí),可訓(xùn)練參數(shù)的數(shù)量增加。這會(huì)導(dǎo)致訓(xùn)練過(guò)程變慢。從零開(kāi)始學(xué)習(xí)嵌入也可能會(huì)使你對(duì)單詞的表示方式處于不清楚的狀態(tài)。
因此,解決上述問(wèn)題的方法是預(yù)訓(xùn)練詞嵌入。讓我們?cè)谙乱还?jié)討論不同的預(yù)訓(xùn)練詞嵌入。
預(yù)訓(xùn)練詞嵌入的不同模型
我將把嵌入大致分為兩類(lèi):?jiǎn)卧~級(jí)嵌入和字符級(jí)嵌入。ELMo和Flair嵌入是字符級(jí)嵌入的示例。在本文中,我們將介紹兩種流行的單詞級(jí)預(yù)訓(xùn)練詞嵌入:
谷歌的Word2vec
斯坦福的GloVe
讓我們了解一下Word2Vec和GloVe的工作原理。
谷歌的Word2vec
Word2Vec是Google開(kāi)發(fā)的最流行的預(yù)訓(xùn)練詞嵌入工具之一。Word2Vec是在Google新聞數(shù)據(jù)集(約1000億字)上訓(xùn)練的。它有幾個(gè)用例,如推薦引擎、單詞相似度和不同的文本分類(lèi)問(wèn)題。
Word2Vec的架構(gòu)非常簡(jiǎn)單。它是一個(gè)只有一個(gè)隱藏層的前饋神經(jīng)網(wǎng)絡(luò)。因此,它有時(shí)被稱(chēng)為淺層神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。
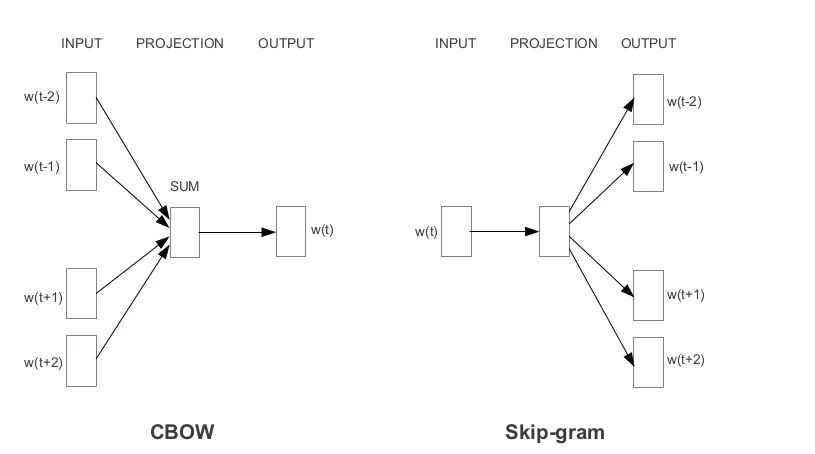
根據(jù)嵌入的學(xué)習(xí)方式,Word2Vec分為兩種方法:
連續(xù)詞袋模型(CBOW)
Skip-gram 模型
連續(xù)詞袋(CBOW)模型在給定相鄰詞的情況下學(xué)習(xí)焦點(diǎn)詞,而Skip-gram模型在給定詞的情況下學(xué)習(xí)相鄰詞。
?連續(xù)詞袋模型模型和Skip-gram 模型是相互顛倒的。
?
例如,想想這句話(huà):““I have failed at times but I never stopped trying”。假設(shè)我們想學(xué)習(xí)“failed”這個(gè)詞的嵌入。所以,這里的焦點(diǎn)詞是“failed”。
「第一步是定義上下文窗口」。上下文窗口是指出現(xiàn)在焦點(diǎn)詞左右的單詞數(shù)。出現(xiàn)在上下文窗口中的單詞稱(chēng)為相鄰單詞(或上下文)。讓我們將上下文窗口固定為2
連續(xù)詞袋模型:Input=[I,have,at,times],Output=failed
Skip-gram 模型跳:Input = failed, Output = [I, have, at, times ]
如你所見(jiàn),CBOW接受多個(gè)單詞作為輸入,并生成一個(gè)單詞作為輸出,而Skip gram接受一個(gè)單詞作為輸入,并生成多個(gè)單詞作為輸出。
因此,讓我們根據(jù)輸入和輸出定義體系結(jié)構(gòu)。但請(qǐng)記住,每個(gè)單詞作為一個(gè)one-hot向量輸入到模型中:
斯坦福的GloVe
?GloVe嵌入的基本思想是從全局統(tǒng)計(jì)中導(dǎo)出單詞之間的關(guān)系。
?
但是,統(tǒng)計(jì)數(shù)字怎么能代表意義呢?讓我解釋一下。
最簡(jiǎn)單的方法之一是看共現(xiàn)矩陣。共現(xiàn)矩陣告訴我們一對(duì)特定的詞在一起出現(xiàn)的頻率。共現(xiàn)矩陣中的每個(gè)值都是一對(duì)詞同時(shí)出現(xiàn)的計(jì)數(shù)。
例如,考慮一個(gè)語(yǔ)料庫(kù):“play cricket, I love cricket and I love football”。語(yǔ)料庫(kù)的共現(xiàn)矩陣如下所示:
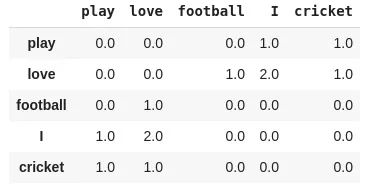
現(xiàn)在,我們可以很容易地計(jì)算出一對(duì)詞的概率。為了簡(jiǎn)單起見(jiàn),讓我們把重點(diǎn)放在“cricket”這個(gè)詞上:
p(cricket/play)=1
p(cricket/love)=0.5
接下來(lái),我們計(jì)算概率比:
p(cricket/play) / p(cricket/love) = 2
當(dāng)比率大于1時(shí),我們可以推斷板球最相關(guān)的詞是“play”,而不是“l(fā)ove”。同樣,如果比率接近1,那么這兩個(gè)詞都與板球有關(guān)。
我們可以用簡(jiǎn)單的統(tǒng)計(jì)方法得出這些詞之間的關(guān)系。這就是GLoVE預(yù)訓(xùn)練詞嵌入的想法。
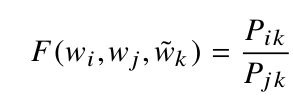
案例研究:從頭開(kāi)始學(xué)習(xí)嵌入與預(yù)訓(xùn)練詞嵌入
讓我們通過(guò)一個(gè)案例來(lái)比較從頭開(kāi)始學(xué)習(xí)我們自己的嵌入和預(yù)訓(xùn)練詞嵌入的性能。我們還將了解使用預(yù)訓(xùn)練詞嵌入是否會(huì)提高NLP模型的性能?
所以,讓我們選擇一個(gè)文本分類(lèi)問(wèn)題-電影評(píng)論的情感分析。從這里下載電影評(píng)論數(shù)據(jù)集(https://www.kaggle.com/columbine/imdb-dataset-sentiment-analysis-in-csv-format)。
將數(shù)據(jù)集加載到Jupyter:
#導(dǎo)入庫(kù)
import?pandas?as?pd
import?numpy?as?np
#讀取csv文件
train?=?pd.read_csv('Train.csv')
valid?=?pd.read_csv('Valid.csv')?????????????
#訓(xùn)練測(cè)試集分離
x_tr,?y_tr?=?train['text'].values,?train['label'].values
x_val,?y_val?=?valid['text'].values,?valid['label'].values
準(zhǔn)備數(shù)據(jù):
from?keras.preprocessing.text?import?Tokenizer
from?keras.preprocessing.sequence?import?pad_sequences
tokenizer?=?Tokenizer()
#準(zhǔn)備詞匯表
tokenizer.fit_on_texts(list(x_tr))
#將文本轉(zhuǎn)換為整數(shù)序列
x_tr_seq??=?tokenizer.texts_to_sequences(x_tr)?
x_val_seq?=?tokenizer.texts_to_sequences(x_val)
#填充以準(zhǔn)備相同長(zhǎng)度的序列
x_tr_seq??=?pad_sequences(x_tr_seq,?maxlen=100)
x_val_seq?=?pad_sequences(x_val_seq,?maxlen=100)
讓我們看一下訓(xùn)練數(shù)據(jù)中的單詞個(gè)數(shù):
size_of_vocabulary=len(tokenizer.word_index)?+?1?#+1用于填充
print(size_of_vocabulary)
「Output」: 112204
我們將構(gòu)建兩個(gè)相同架構(gòu)的不同NLP模型。第一個(gè)模型從零開(kāi)始學(xué)習(xí)嵌入,第二個(gè)模型使用預(yù)訓(xùn)練詞嵌入。
定義架構(gòu)從零開(kāi)始學(xué)習(xí)嵌入:
#深度學(xué)習(xí)庫(kù)
from?keras.models?import?*
from?keras.layers?import?*
from?keras.callbacks?import?*
model=Sequential()
#嵌入層
model.add(Embedding(size_of_vocabulary,300,input_length=100,trainable=True))?
#lstm層
model.add(LSTM(128,return_sequences=True,dropout=0.2))
#Global?Max池化
model.add(GlobalMaxPooling1D())
#Dense層
model.add(Dense(64,activation='relu'))?
model.add(Dense(1,activation='sigmoid'))?
#添加損失函數(shù)、度量、優(yōu)化器
model.compile(optimizer='adam',?loss='binary_crossentropy',metrics=["acc"])?
#添加回調(diào)
es?=?EarlyStopping(monitor='val_loss',?mode='min',?verbose=1,patience=3)??
mc=ModelCheckpoint('best_model.h5',?monitor='val_acc',?mode='max',?save_best_only=True,verbose=1)??
#輸出模型
print(model.summary())
輸出:

模型中可訓(xùn)練參數(shù)總數(shù)為33889169。其中,嵌入層貢獻(xiàn)了33661200個(gè)參數(shù)。參數(shù)太多了!
訓(xùn)練模型:
history?=?model.fit(np.array(x_tr_seq),np.array(y_tr),batch_size=128,epochs=10,validation_data=(np.array(x_val_seq),np.array(y_val)),verbose=1,callbacks=[es,mc])
評(píng)估模型的性能:
#加載最佳模型
from?keras.models?import?load_model
model?=?load_model('best_model.h5')
#評(píng)估
_,val_acc?=?model.evaluate(x_val_seq,y_val,?batch_size=128)
print(val_acc)
「輸出」:0.865
現(xiàn)在,是時(shí)候用GLoVE預(yù)訓(xùn)練的詞嵌入來(lái)構(gòu)建第二版了。讓我們把GLoVE嵌入到我們的環(huán)境中:
#?將整個(gè)嵌入加載到內(nèi)存中
embeddings_index?=?dict()
f?=?open('../input/glove6b/glove.6B.300d.txt')
for?line?in?f:
????values?=?line.split()
????word?=?values[0]
????coefs?=?np.asarray(values[1:],?dtype='float32')
????embeddings_index[word]?=?coefs
f.close()
print('Loaded?%s?word?vectors.'?%?len(embeddings_index))
輸出:Loaded 400,000 word vectors.
通過(guò)為詞匯表分配預(yù)訓(xùn)練的詞嵌入,創(chuàng)建嵌入矩陣:
#?為文檔中的單詞創(chuàng)建權(quán)重矩陣
embedding_matrix?=?np.zeros((size_of_vocabulary,?300))
for?word,?i?in?tokenizer.word_index.items():
????embedding_vector?=?embeddings_index.get(word)
????if?embedding_vector?is?not?None:
????????embedding_matrix[i]?=?embedding_vector
定義架構(gòu)-預(yù)訓(xùn)練嵌入:
model=Sequential()
#嵌入層
model.add(Embedding(size_of_vocabulary,300,weights=[embedding_matrix],input_length=100,trainable=False))?
#lstm層
model.add(LSTM(128,return_sequences=True,dropout=0.2))
#Global?Max池化
model.add(GlobalMaxPooling1D())
#Dense層
model.add(Dense(64,activation='relu'))?
model.add(Dense(1,activation='sigmoid'))?
#添加損失函數(shù)、度量、優(yōu)化器
model.compile(optimizer='adam',?loss='binary_crossentropy',metrics=["acc"])?
#添加回調(diào)
es?=?EarlyStopping(monitor='val_loss',?mode='min',?verbose=1,patience=3)??
mc=ModelCheckpoint('best_model.h5',?monitor='val_acc',?mode='max',?save_best_only=True,verbose=1)??
#輸出模型
print(model.summary())
輸出:

如你所見(jiàn),可訓(xùn)練參數(shù)的數(shù)量?jī)H為227969。與嵌入層相比,這是一個(gè)巨大的下降。
訓(xùn)練模型:
history?=?model.fit(np.array(x_tr_seq),np.array(y_tr),batch_size=128,epochs=10,validation_data=(np.array(x_val_seq),np.array(y_val)),verbose=1,callbacks=[es,mc])
評(píng)估模型的性能:
#加載最佳模型
from?keras.models?import?load_model
model?=?load_model('best_model.h5')
#評(píng)估
_,val_acc?=?model.evaluate(x_val_seq,y_val,?batch_size=128)
print(val_acc)
輸出:88.49
與從頭學(xué)習(xí)嵌入相比,使用預(yù)訓(xùn)練詞嵌入的性能有所提高。
結(jié)尾
預(yù)訓(xùn)練詞嵌入是有力的文本表示方式,因?yàn)樗鼈兺蹲絾卧~的語(yǔ)義和句法意義。
在本文中,我們了解了預(yù)訓(xùn)練詞嵌入的重要,并討論了兩種流行的預(yù)訓(xùn)練詞嵌入:Word2Vec和gloVe。
原文鏈接:https://www.analyticsvidhya.com/blog/2020/03/pretrained-word-embeddings-nlp/
看到這里,說(shuō)明你喜歡這篇文章,請(qǐng)點(diǎn)擊「在看」或順手「轉(zhuǎn)發(fā)」「點(diǎn)贊」。
往期精彩回顧
獲取一折本站知識(shí)星球優(yōu)惠券,復(fù)制鏈接直接打開(kāi):
https://t.zsxq.com/yFQV7am
本站qq群1003271085。
加入微信群請(qǐng)掃碼進(jìn)群: