
神TM的SOTA ,看完谷歌的新論文,我對AI大廠有些失望
用數(shù)萬美元 TPU 算力,實現(xiàn)在 CIFAR-10 上 0.03% 的改進,創(chuàng)造了新的 SOTA,但這一切值得嗎?
「我相信他們得到的數(shù)字是準確的,他們確實做了工作并得到了結(jié)果…… 但這樣真的好嗎?」
一名機器學習研究者的靈魂發(fā)問,今天成為了整個社區(qū)最熱門的話題。
事情要從這周四說起,谷歌研究員 Andrea Gesmundo 和谷歌 AI 負責人、大牛 Jeff Dean 的論文《An Evolutionary Approach to Dynamic Introduction of Tasks in Large-scale Multitask Learning Systems》被提交到了預印版論文平臺 arXiv 上。
Jeff Dean 等人提出了一種進化算法,可以生成大規(guī)模的多任務(wù)模型,同時也支持新任務(wù)的動態(tài)和連續(xù)添加,生成的多任務(wù)模型是稀疏激活的,并集成了基于任務(wù)的路由,該路由保證了有限的計算成本,并且隨著模型的擴展,每個任務(wù)添加的參數(shù)更少。
作者表示,其提出的新方法依賴于知識劃分技術(shù),實現(xiàn)了對災難性遺忘和其他常見缺陷(如梯度干擾和負遷移)的免疫。實驗表明,新方法可以聯(lián)合解決并在 69 個圖像分類任務(wù)上取得有競爭力的結(jié)果,例如對僅在公共數(shù)據(jù)上訓練的模型,在 CIFAR-10 上實現(xiàn)了新的業(yè)界最高識別準確度 99.43%。
 論文鏈接:https://arxiv.org/abs/2205.12755
論文鏈接:https://arxiv.org/abs/2205.12755
這看起來是 Jeff Dean 等人朝著他們近期設(shè)立的雄偉目標 pathway 通用 AI 架構(gòu)邁出的重要一步。去年,他所帶領(lǐng)的團隊提出了「下一代通用 AI 架構(gòu)」Pathways,旨在用一個架構(gòu)同時處理多項任務(wù),并且使其擁有快速學習新任務(wù)、更好地理解世界的能力。
在 5 月 12 日的谷歌 IO 大會上,皮查伊還表示研究人員用 Pathways 系統(tǒng)訓練了一個 5400 億參數(shù)的大型語言模型 PaLM,這是一個只有解碼器的密集 Transformer 模型。可以完成的任務(wù)包括自動生成代碼、解決數(shù)學問題、修復 bug,解釋笑話的梗等等。PaLM 可以區(qū)分因果關(guān)系,理解上下文中的概念組合。

PaLM 模型在數(shù)學問題上的準確率提升到了 58%,接近 60% 的 9 到 12 歲兒童解決問題的水平,又可以在沒經(jīng)過對應(yīng)語料庫訓練的情況下實現(xiàn)準確的翻譯。
而這個星期的新論文中,作者提出的 μ2Net 模型可以預訓練或隨機初始化。一次搜索出的單個任務(wù)上的最佳模型稱為活動任務(wù)。在任務(wù)的活躍階段,在活躍任務(wù)上訓練的模型群體會不斷進化——隨機突變?nèi)缓鬁y試評分,保留高分的,淘汰低分的。一個活躍階段由多代組成,其中并行采樣和訓練多批子模型。在任務(wù)活動階段結(jié)束時,僅保留其最佳評分模型作為多任務(wù)系統(tǒng)的一部分。一個任務(wù)可以被多次激活。
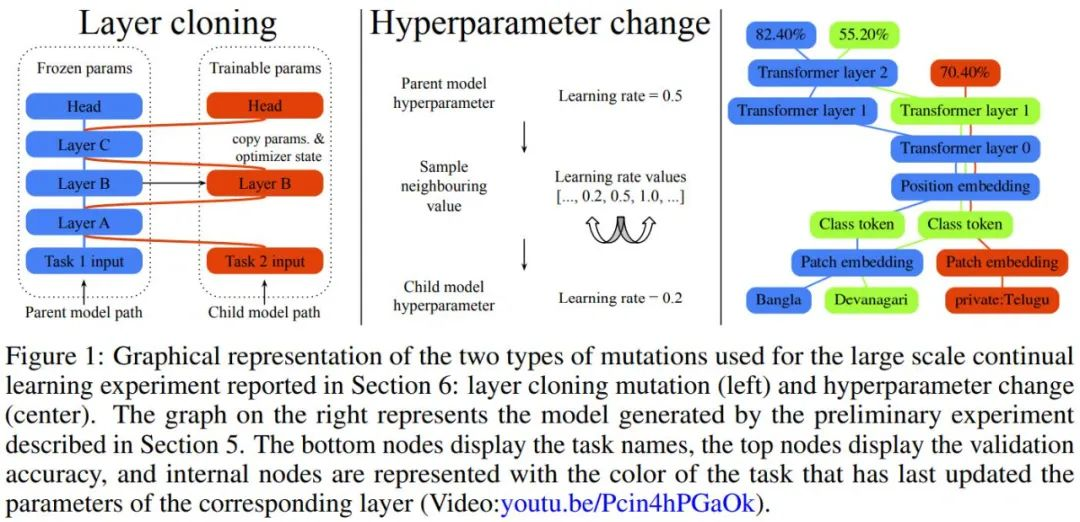
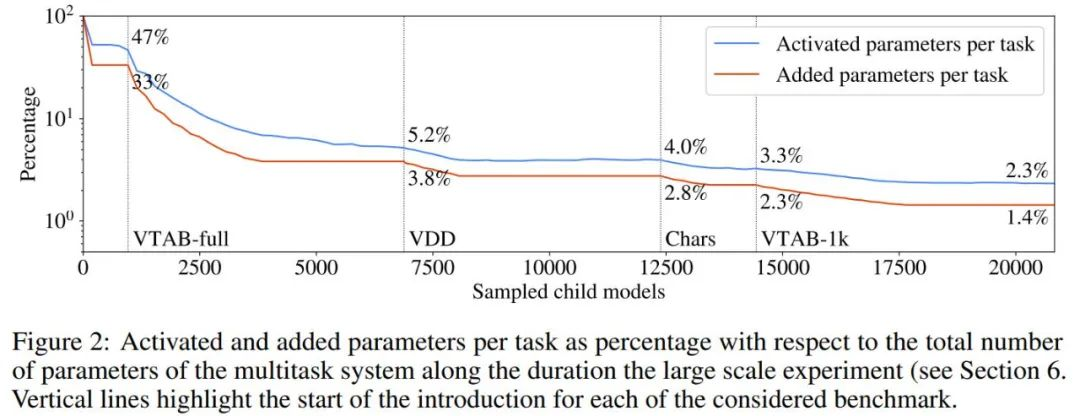
作者表示 μ2Net 可以在大型任務(wù)集上實現(xiàn)最先進的質(zhì)量,并能夠?qū)⑿氯蝿?wù)動態(tài)地引入正在運行的系統(tǒng)中。學習的任務(wù)越多,系統(tǒng)中嵌入的知識就越多。同時,隨著系統(tǒng)的增長,參數(shù)激活的稀疏性使每個任務(wù)的計算量和內(nèi)存使用量保持不變。通過實驗,每個任務(wù)的平均增加參數(shù)量減少了 38%,由此產(chǎn)生的多任務(wù)系統(tǒng)僅激活了每個任務(wù)總參數(shù)的 2.3%。
對于程序員大神 Jeff Dean,人們一直心存敬畏。該研究剛剛提交時,人們的看法還是贊賞和期待,但在更多的人仔細閱讀過論文之后,社區(qū)的風評突然發(fā)生了轉(zhuǎn)變。

昨天在 reddit 的機器學習社區(qū)上,一名 AI 研究者 MrAcurite 表達了憤怒的情緒:
我相信這些數(shù)字是準確的,并且他們確實做了工作并得到了結(jié)果。在這篇論文中,作者使用了非常復雜的進化和多任務(wù)學習算法,它有 18 頁的內(nèi)容,非常有趣,解決了一堆問題。但有兩個值得注意的地方。
首先,他們主張的突破性指標數(shù)字是 CIFAR-10 上的 99.43,而此前的 SOTA 為 99.40,所以在宏偉的計劃中向前推進了一步,「哇哦」。
其次,論文末尾有一張圖表,詳細說明了僅用于產(chǎn)生最終結(jié)果的訓練方案的 TPU 核心小時數(shù)。總計為 17,810 小時。假設(shè)你不是個在谷歌工作的人,你必須使用 3.22 美元 / 小時的按需付款。這意味著這些訓練好的模型成本為 57,348 美元。
嚴格來說,在一個足夠通用的遺傳算法上投入足夠的計算肯定最終會產(chǎn)生好的性能,所以雖然你絕對可以閱讀這篇論文并收集有關(guān)「如何使用遺傳算法,通過利用已有模型子集部分,在每個新任務(wù)上學習權(quán)重的方式來完成多任務(wù)學習」的有趣想法。
或者用人話來說,本文只是「Jeff Dean 花了足夠的錢養(yǎng)活一個四口之家五年的錢,以獲得 0.03% 在 CIFAR-10 上的改進。」
在不斷推陳出新的大廠 AI 論文中,OpenAI 無疑是最嚴重的違規(guī)者,但似乎每個人都在這樣做。你在現(xiàn)有數(shù)據(jù)和現(xiàn)有基準的現(xiàn)有問題上投入了大量的計算和少量的新想法,然后如果你的數(shù)字遠遠高于已有的 SOTA 數(shù)字,你就可以在自己簡歷上貼上一個小標簽。
這讓人如何相信你的思路不是有害的?我甚至無法驗證它們,無法將它們應(yīng)用到自己的項目中。
這真的是一個研究社區(qū)該有的樣子嗎?大量的算力掌握在少數(shù)科技巨頭的手中。我認為應(yīng)該有一個新的論文期刊,要求其中的論文在單個消費者 GPU 上 8 小時內(nèi)可以復現(xiàn)其實驗結(jié)果。
MrAcurite 發(fā)貼后,有多位研究者展開了討論,人們從各個角度附和了她的觀點。
SupportVectorMachine (認證的研究人員)表示:
我?guī)缀鯇ι疃葘W習失去了興趣,因為作為小型實驗室的從業(yè)者,基本上在計算預算方面不可能比得過科技巨頭。即使你有一個很好的理論想法,主流環(huán)境可能也存在偏見,讓它難以看到曙光。這釀成了一個不公平的競爭環(huán)境。
當然,這些大規(guī)模的研究項目并非沒有價值。像 GPT、DALL-E 等都很棒。但如果我不能在我自己的機器上復現(xiàn)這些大模型,它們對我來說的意義就不大。
gambs (認證的 PhD)回復道:
講一件真實的事,兩年前我寫了一篇關(guān)于流模型的論文,一位審稿人給出的評語是:「生成的圖像看起來不如 GAN 好」。
當時我使用的是以前發(fā)布的預訓練模型,并且沒有以任何方式對其進行修改,這篇論文旨在找到隱空間中采樣的部分,而不是提出改進模型生成圖像質(zhì)量的模型。
fmai 回復道:
作為 AI 會議的審稿人,我認為可以通過規(guī)范化幫助改變這種現(xiàn)狀。例如,我嘗試專門查看論文是否符合科學工作的要求,是否有完整的研究問題,是否有證據(jù)充分支持假設(shè)等。用所有自變量都不同的新系統(tǒng)擊敗 SOTA 模型不會創(chuàng)造任何新知識,也不是科學研究。
JanneJM 則表示:
用更大的網(wǎng)絡(luò)擊敗現(xiàn)有 SOTA 模型并不是推動該領(lǐng)域發(fā)展的唯一途徑。相反,這可能是最無趣的研究。
專注于使用小型網(wǎng)絡(luò)(用于物聯(lián)網(wǎng)設(shè)備、實時訓練等)做更多事情,不需要大量計算能力,這樣的研究不是更有趣嗎,實際用途也更大。理論結(jié)果和概念突破,無論是數(shù)學證明還是統(tǒng)計證明、新型方法等等,這些其實幾乎不需要實際計算。

預訓練大模型的興起,正讓越來越多的研究者大呼「先進模型跑不起」、「難以和科技大廠的 AI Lab 競爭」,技術(shù)的進步似乎把很多人擋在了前沿研究的門檻之外。現(xiàn)在看來,情況有著愈演愈烈的趨勢,最近一段時間,在社交網(wǎng)絡(luò)上刷屏的新研究是 OpenAI 的 DALL-E2 和谷歌的 Imagen,這些模型都需要耗費巨大的算力完成訓練。
不知在人們的呼吁過后,未來的研究風向是否會有改變。
[1]https://www.reddit.com/r/MachineLearning/comments/uyratt/d_i_dont_really_trust_papers_out_of_top_labs/
[2]https://www.reddit.com/r/MachineLearning/comments/uyfmlj/r_an_evolutionary_approach_to_dynamic/

推薦閱讀