
用20篇論文走完知識蒸餾在 2014-2020 年的技術(shù)進(jìn)展

極市導(dǎo)讀
?本文是一篇知識蒸餾方面的論文回顧總結(jié),總共涉及了20篇相關(guān)的paper。作者介紹了知識蒸餾的三種主要方法Logits(Response)-based 、Feature-based、Relation-based以及知識蒸餾的相關(guān)應(yīng)用。通過閱讀本文對知識蒸餾這一概念有更詳細(xì)的了解和掌握。>>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿
前言
最近給公司里面的同學(xué)做了一個KD的survey,趁熱把我回顧研究的一些東西記錄下來,算是回饋知乎社區(qū),一直以來,從里面汲取了很多營養(yǎng),但沒有怎么輸出優(yōu)質(zhì)內(nèi)容。
概要
Intro & Roadmap KD主要方法 Applications(NLP-BERT) QA
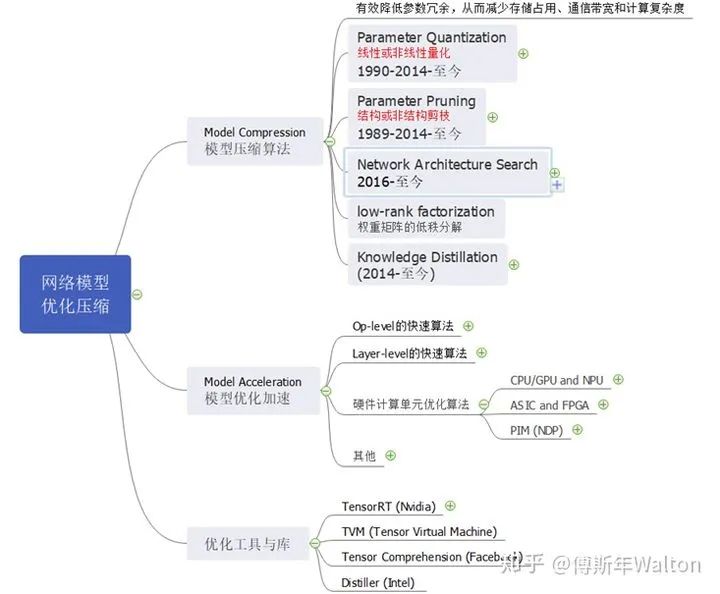
Intro & Roadmap整個模型壓縮優(yōu)化知識結(jié)構(gòu)如下所示,KD屬于模型壓縮算法的一種,從2014年發(fā)展至今。
Bucilua et al. (2006)?首次提出通過知識蒸餾壓縮模型的思想,但是沒有實際的工作闡述。之后Hilton et al. (2014)第一次正式定義Distillation,并提出相應(yīng)的訓(xùn)練方法。

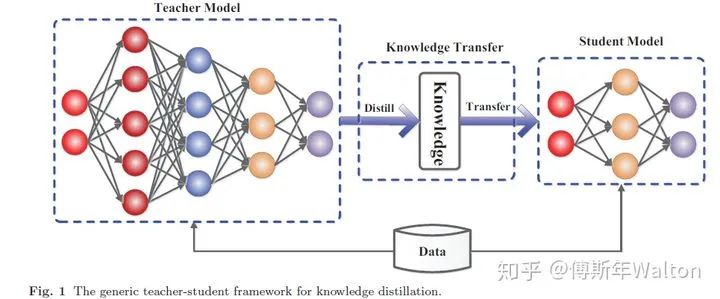
一個典型的KD框架如下圖所示,由三個part組成,Teacher model,student model 和Knowledge transfer,整個過程是在有監(jiān)督的data數(shù)據(jù)集上訓(xùn)練完成。
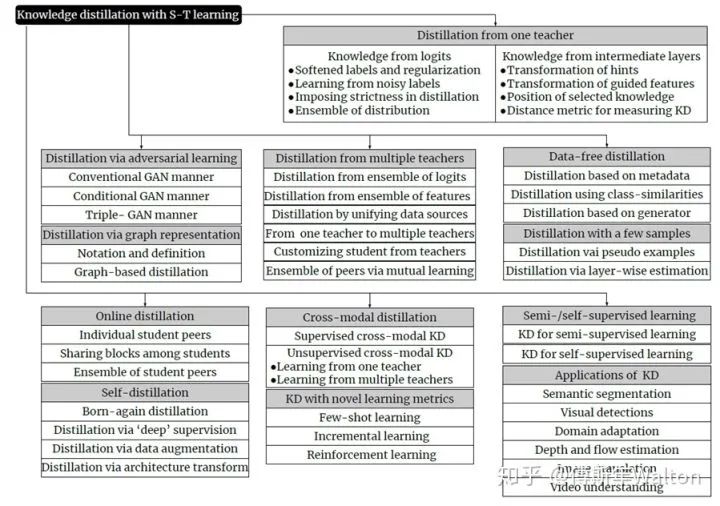
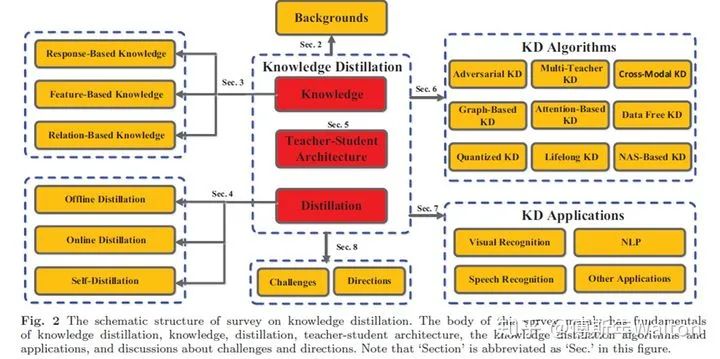
下面介紹今年的兩篇survey文章,引用他們的Roadmap圖,回顧下過去6年,研究者主要在哪些方向參與KD的研究和推進(jìn)工作。
KD主要方法
作者參考這篇文章,從Logits(Response)-based, Feature-based, 和Relation-based knowledge三種維度去介紹KD在過去6年的一些高引用paper。Logits(Response)-based knowledge從下圖直觀感受到,knowledge從teacher model的output layer學(xué)習(xí)得到;Feature-based 是從一些中間hidden layers學(xué)習(xí)knowledge;Relation-based則是學(xué)習(xí)input-hidden-output之間的關(guān)系。
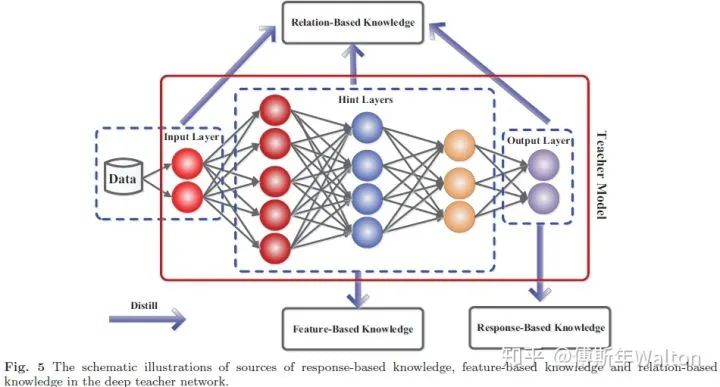
為了大家方便閱讀,先列出來三種方法主要代表paper:
1.Logits(Response)-based
Distilling the Knowledge in a Neural Network Hilton NIPS 2014 Deep mutual learning CVPR 2018 On the efficacy of knowledge distillation, ICCV 2019 Self-training with noisy student improves imagenet classification 2019 Training deep neural networks in generations: A more tolerant teacher educates better students AAAI 2019 Distillation-based training for multi-exit architectures ICCV 2019
2. Feature-based
Fitnets: Hints for thin deep nets. ICLR 2015 Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. ICLR 2017
3. Relation-based
A gift from knowledge distillation: Fast optimization, network minimization and transfer learning CVPR 2017 Similarity-preserving knowledge distillation ICCV 2019
Logits(Response)-based Knowledge
Distilling the Knowledge in a Neural Network Hilton NIPS 2014
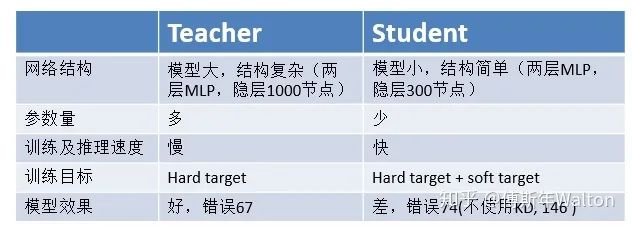
KD的開山之作,核心思想是使用softed labels去學(xué)習(xí)class distribution,具體先訓(xùn)練好一個teacher網(wǎng)絡(luò),然后將teacher的網(wǎng)的輸出結(jié)果q作為student網(wǎng)絡(luò)的目標(biāo),訓(xùn)練student網(wǎng)絡(luò),使得student網(wǎng)絡(luò)的結(jié)果p接近q。提出的新idea是softmax的變形,引入一個變量T去產(chǎn)生softed labels。soft target 與hard target區(qū)別如下圖所示。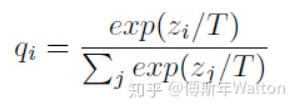

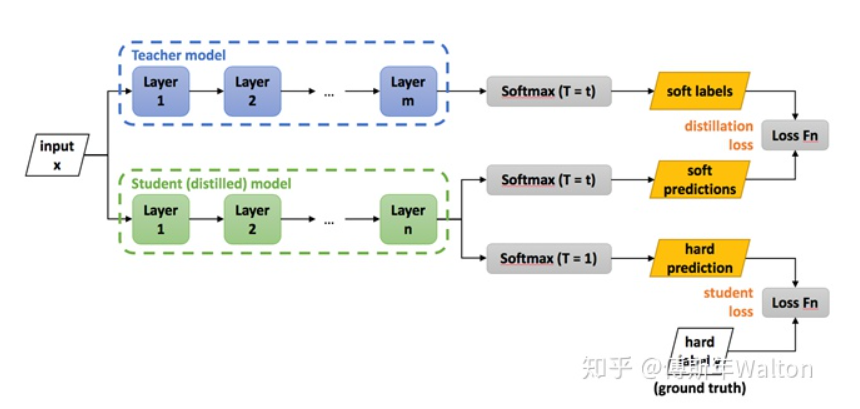
損失函數(shù)如下:
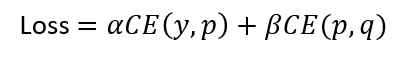
T通常設(shè)置為1,在paper中,ranging from 1 to 20。根據(jù)經(jīng)驗,student比teacher模型小很多時,T設(shè)置小一點。如果T接近于0,則最大的值會越近1,其它值會接近0,近似于onehot編碼。如果T越大,則輸出的結(jié)果的分布越平緩,相當(dāng)于平滑的一個作用,起到保留相似信息的作用。如果T等于無窮,就是一個均勻分布。默認(rèn)α +β=1 , 初始設(shè)置 α = β = 0.5,但是實驗中 α << β ,結(jié)果較好。試驗結(jié)果如下:
Deep mutual learning CVPR 2018
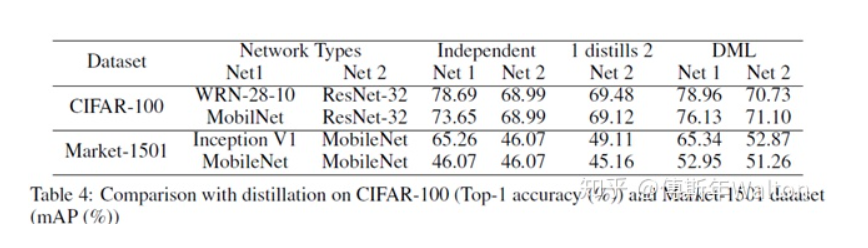
傳統(tǒng)蒸餾模型是從功能強大的大型網(wǎng)絡(luò)或集成網(wǎng)絡(luò)轉(zhuǎn)移到結(jié)構(gòu)簡單,運行快速的小型網(wǎng)絡(luò)。本文打破這種預(yù)先定義好的“強弱關(guān)系”,提出DML,即讓一組學(xué)生網(wǎng)絡(luò)在訓(xùn)練過程中相互學(xué)習(xí)、相互指導(dǎo),而不是靜態(tài)的預(yù)先定義好教師和學(xué)生之間的單向轉(zhuǎn)換通路。
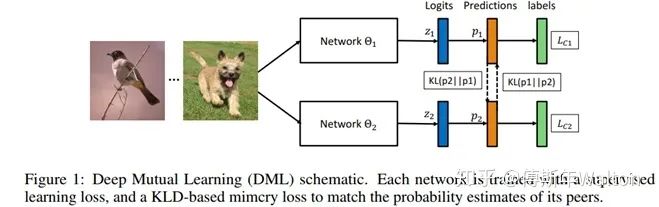
作者引入KL散度的概念來度量兩個學(xué)生網(wǎng)絡(luò)的輸出概率p1和p2。相信了解過GAN網(wǎng)絡(luò)的小伙伴對KL應(yīng)該不會陌生,KL 散度是一種衡量兩個概率分布的匹配程度的指標(biāo),兩個分布差異越大,KL散度越大。作者采用KL散度,衡量這兩個網(wǎng)絡(luò)的預(yù)測p1和p2是否匹配。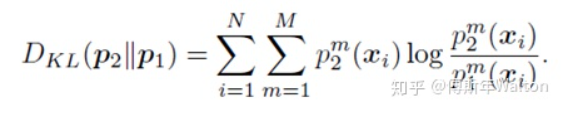 損失函數(shù)推導(dǎo):
損失函數(shù)推導(dǎo):
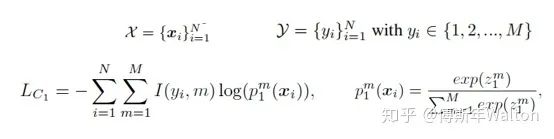
 最后訓(xùn)練的loss函數(shù)是兩個學(xué)生網(wǎng)絡(luò)分別訓(xùn)練,各自的cross-entropy Loss和KL散度Loss之和。
最后訓(xùn)練的loss函數(shù)是兩個學(xué)生網(wǎng)絡(luò)分別訓(xùn)練,各自的cross-entropy Loss和KL散度Loss之和。
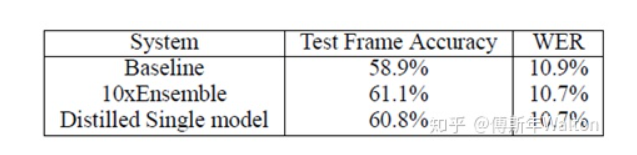
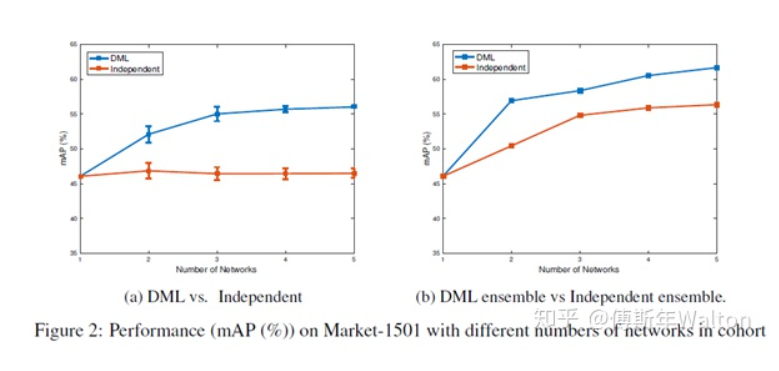
試驗結(jié)果,效果很明顯,增幅很穩(wěn)定,并且學(xué)生網(wǎng)絡(luò)越多,效果也是線性上升。
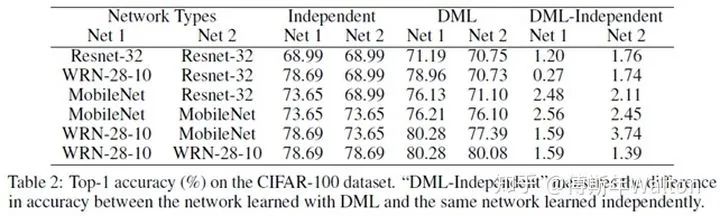
 On the efficacy of knowledge distillation, ICCV 2019
On the efficacy of knowledge distillation, ICCV 2019
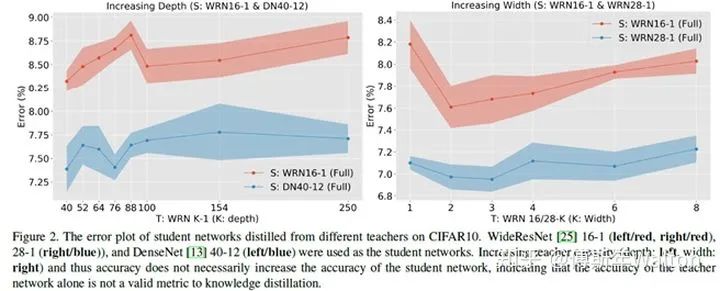
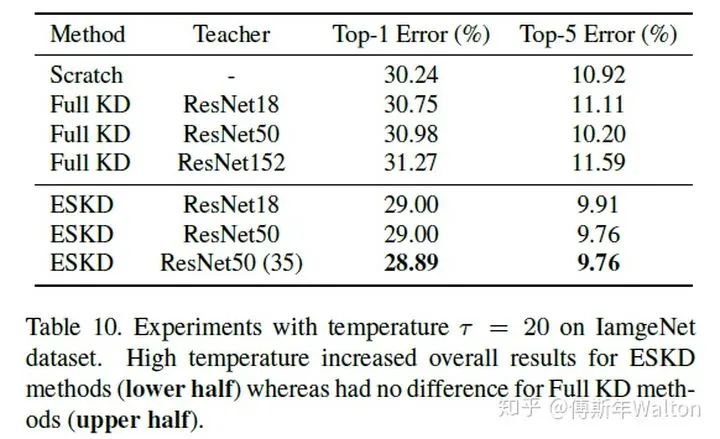
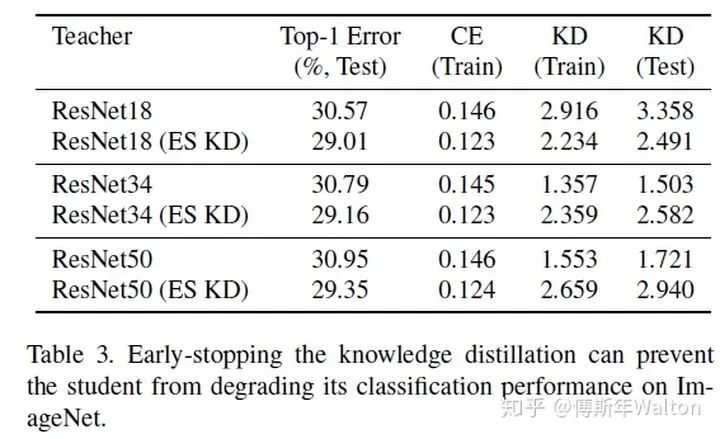
繼續(xù)使用KD softed labels, 但是聚焦regularization。作者實驗觀察到,并不是性能越好的teacher就能蒸餾出更好的student;推測是容量不匹配的原因,導(dǎo)致student模型不能夠mimic teacher,反而帶偏了主要的loss;提出一種early-stop teacher regularization進(jìn)行蒸餾,接近收斂時要提前停止蒸餾。如下圖,teacher網(wǎng)絡(luò)越深,student蒸餾效果并一定提升。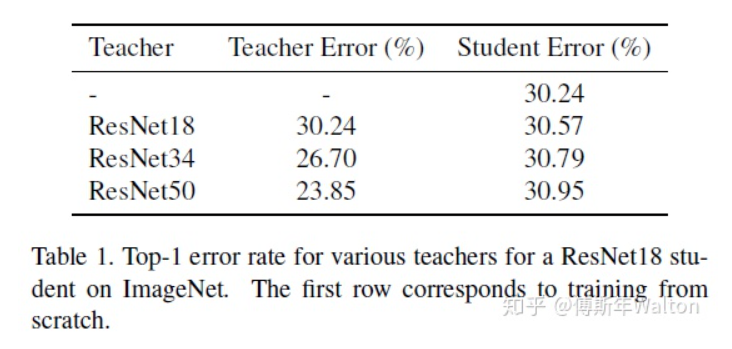
具體early-stop teacher regularization的策略作者沒有寫出來,但是可以推測到就是根據(jù)訓(xùn)練loss曲線,看是否接近收斂,如果接近收斂,則停止蒸餾。實驗結(jié)果如下:
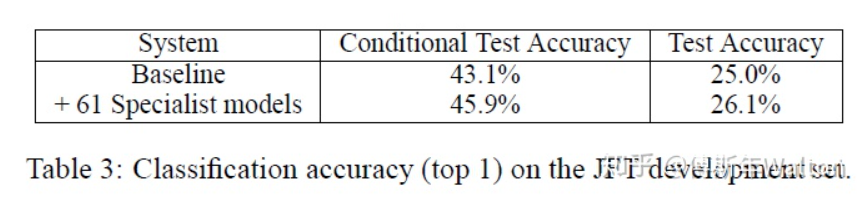
Self-training with noisy student improves imagenet classification 2019
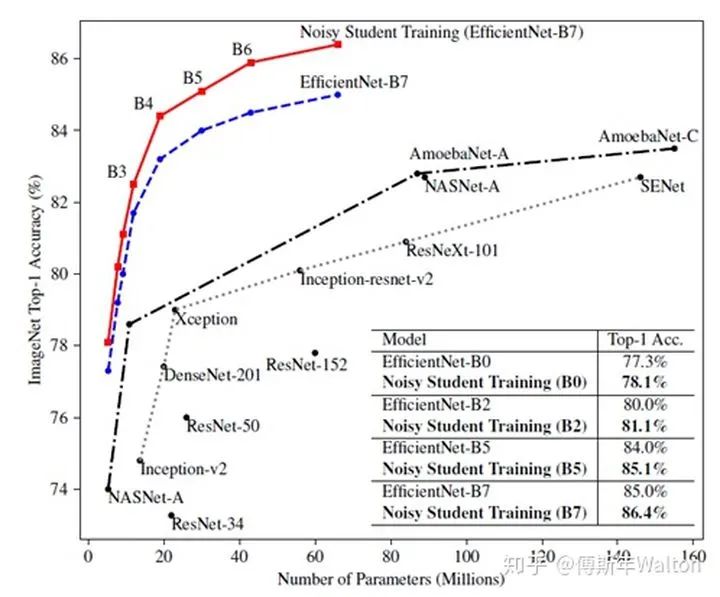
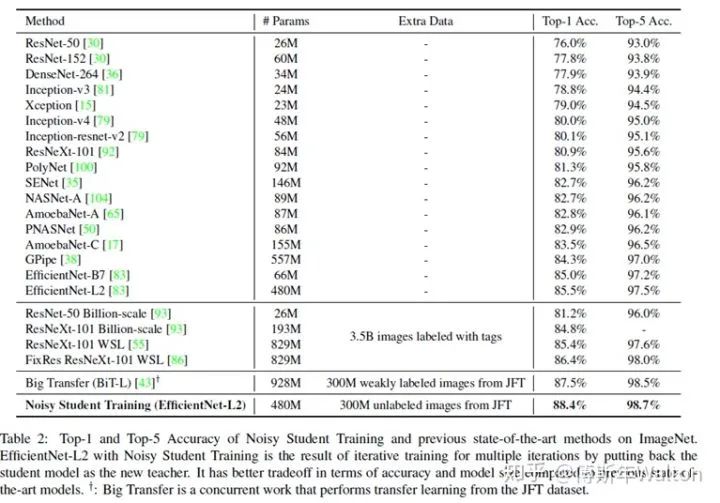
繼續(xù)使用KD softed labels, 但是聚焦data issue,通過使用更大的噪聲數(shù)據(jù)集來訓(xùn)練student模型。大致思路:
首先在ImageNet上訓(xùn)練Teacher Network
再使用訓(xùn)練好的T網(wǎng)絡(luò)(無噪音)來對另一個數(shù)據(jù)集JFT dataset生成盡可能準(zhǔn)確的偽標(biāo)簽
之后使用生成偽標(biāo)簽的數(shù)據(jù)集JFT dataset和ImageNet一起訓(xùn)練Student Network
除此之外,作者還提到一些tricks:
在Student Network訓(xùn)練中,增加了模型噪音(DropOut 0.5、隨機深度 0.8、隨機增強 震級27 ),提高魯棒性和泛化能力
數(shù)據(jù)過濾,將教師模型中置信度不高的圖片過濾,因為這通常代表著域外圖像
數(shù)據(jù)平衡,平衡不同類別的圖片數(shù)量
教師模型輸出的標(biāo)簽使用軟標(biāo)簽
實驗結(jié)果如下:
Training deep neural networks in generations: A more tolerant teacher educates better students AAAI 2019
繼續(xù)使用KD softed labels, 但是在蒸餾過程中通過增加約束來達(dá)到優(yōu)化目標(biāo),通常約束加在teacher或者student network。大致思路:作者發(fā)現(xiàn)除了ground Truth class, secondary class可以有效學(xué)習(xí)類間相似度,并且防止student network過擬合,取得好的效果。作者挑選了幾個具有最高置信度分?jǐn)?shù)的類,并假設(shè)這些類在語義上更可能與輸入圖像相似。設(shè)置了一個固定的整數(shù)K,代表每個圖像語義上合理的類的數(shù)量,包括ground Truth類。然后計算ground Truth類與其他得分最高的K-1類之間的差距。損失函數(shù)推導(dǎo):
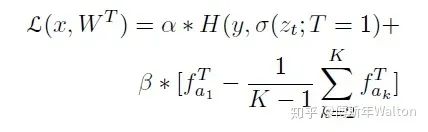
實驗結(jié)果,K越大,效果越明顯。

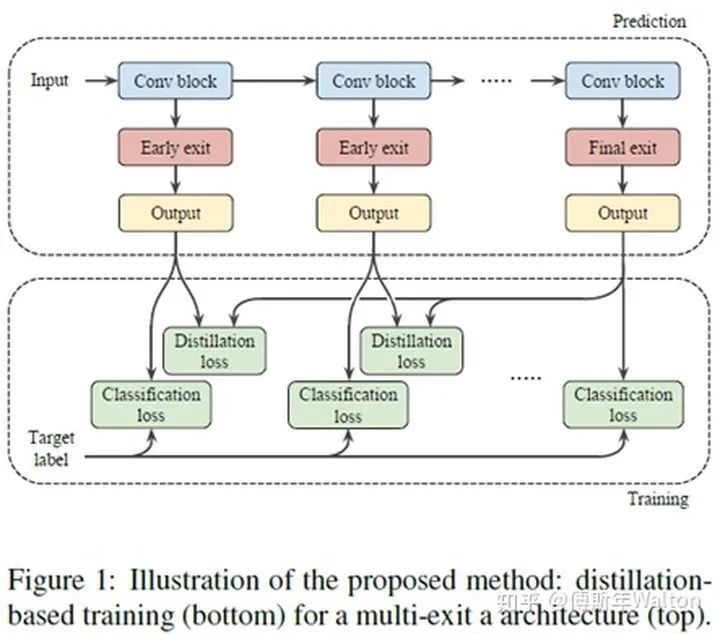
Distillation-based training for multi-exit architectures ICCV 2019
通常KD在student和teacher network網(wǎng)絡(luò)模型容量相差較大時,表現(xiàn)較差。Ensemble distribution KD方法可以很好的保證分布diversity,同時多個模型融合的結(jié)構(gòu)較好。大致思路:作者借鑒muti-exit architectures去做ensemble distribution KD,擴展提出新的損失函數(shù)。
損失函數(shù)推導(dǎo):
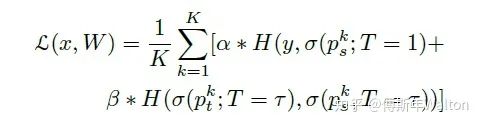
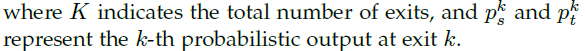
Logits(Response)-based Knowledge優(yōu)缺點總結(jié)
優(yōu)點:
1.簡單易于理解,student模型學(xué)teacher模型輸出的概率分布,相當(dāng)于給出了類別之間的相似性信息,提供了額外的監(jiān)督信號,學(xué)起來更容易。
2.對于輸出層,實現(xiàn)簡單方便
缺點:1.蒸餾效率依賴于softmax loss計算和number of class
2.對于沒有l(wèi)abel(low-level vision)的問題,無法去做
3.當(dāng)student network模型太小時,很難從teacher network distilled成功
Feature-based Knowledge
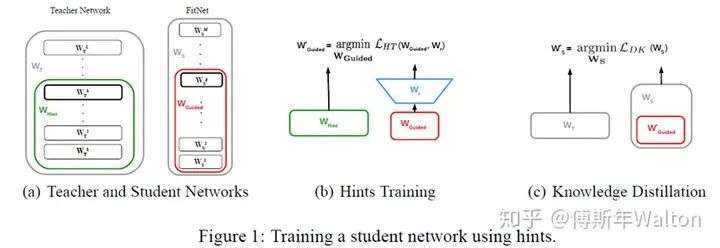
Fitnets: Hints for thin deep nets. ICLR 2015
首次提出通過intermediate feature layers學(xué)習(xí)knowledge。
大致思路:
1. 選擇teacher模型特征提取器的第N層輸出作為hint,從第一層到第N層的參數(shù)對應(yīng)圖中的Whint;
2.選擇student模型特征提取器的第M層輸出作為guided,從第一層到第M層的參數(shù)對應(yīng)圖中的WGuided,student和teacher特征圖維度可能不匹配,因此在student引入卷積層調(diào)整器,記為r,對guided的維度進(jìn)行調(diào)整;
3. 階段一訓(xùn)練,最小化特征損失函數(shù),uh表示teacher模型從第一層到第N層對應(yīng)的函數(shù),vg表示student模型從第一層到第M層對應(yīng)的函數(shù),r表示卷積層調(diào)整器,對應(yīng)的參數(shù)記為Wr。
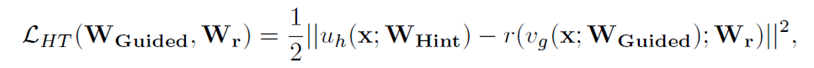
4.階段二訓(xùn)練,因為階段一沒有l(wèi)abel信息,蒸餾粒度不夠細(xì),因此論文引入階段二的訓(xùn)練,利用hinton提出的knowledge distillation對student模型進(jìn)行蒸餾
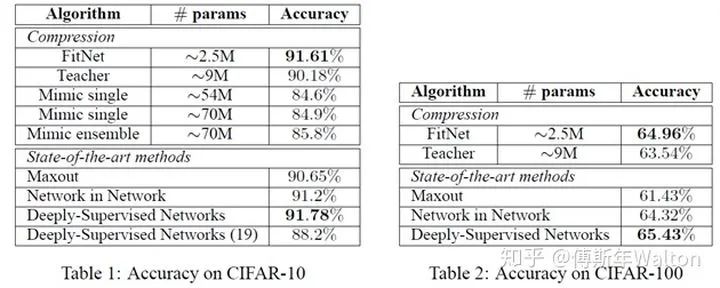
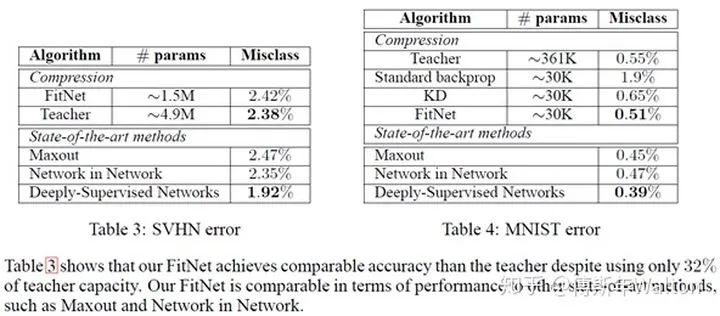
實驗結(jié)果:
 Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. ICLR 2017
Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. ICLR 2017
通過提取Teacher模型生成的注意力圖來指導(dǎo)Student模型,使Student模型生成的注意力圖與Teacher模型相似。這樣簡單模型不僅可以學(xué)到特征信息,還能夠了解如何提煉特征信息。使得Student模型生成的特征更加靈活,不局限于Teacher模型。

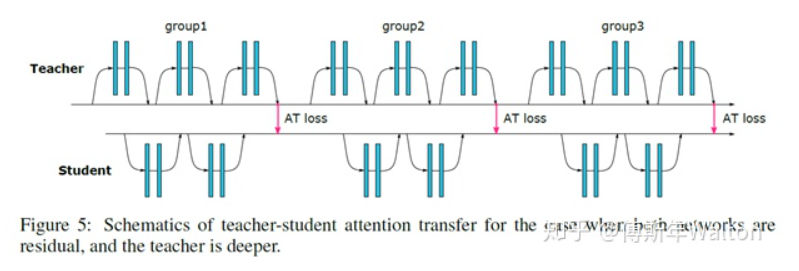 作者論文中提出兩種attention的計算方式:
作者論文中提出兩種attention的計算方式:
思路1:Activation-based attention transfer, 對卷積網(wǎng)絡(luò)隱藏層輸出的特征圖——feature map(特征 & 知識)進(jìn)行遷移(Attention transfer),讓學(xué)生網(wǎng)絡(luò)的feature map與教師網(wǎng)絡(luò)的feature map盡可能相似,步驟如下
1. 將Teacher網(wǎng)絡(luò)和Student網(wǎng)絡(luò)都分成n個part(兩者分part的數(shù)量相同),保證學(xué)生網(wǎng)絡(luò)和教師網(wǎng)絡(luò)每個part的最后一個卷積層得到的feature map的size大小相同,都是W * H(數(shù)量可以不同)
2. 為了計算loss,每個part的最后一個卷積層C個W * H的特征圖變換為1個W* H的的二維張量,為了定義這個空間注意力映射函數(shù),一個潛在假設(shè)是,隱層神經(jīng)元激活(網(wǎng)絡(luò)在預(yù)測時的結(jié)果)的絕對值可以用于指示這個神經(jīng)元的重要性,這樣我們可以計算通道維度的統(tǒng)計量, 具體而言,我們考慮如下如下三種空間注意力圖:
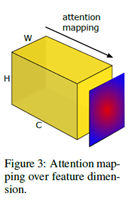

3.Loss函數(shù),paper中p=2,所以是L2 loss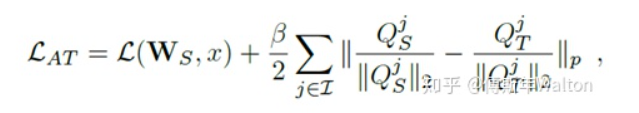
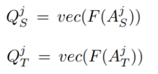
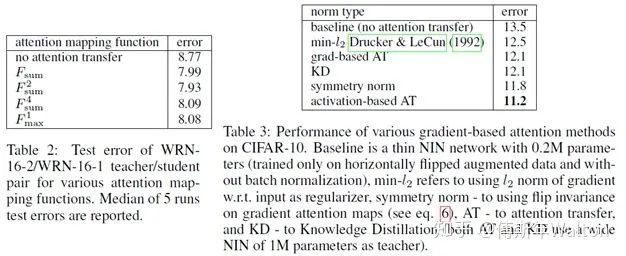
思路2:Gradient-based attention transfer,Loss對輸入X求導(dǎo),判斷損失函數(shù)對于輸入X的敏感性,pay more attnetion to值得注意的像素(梯度大的像素)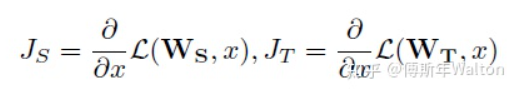
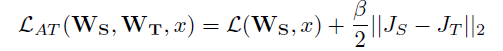
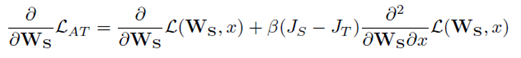
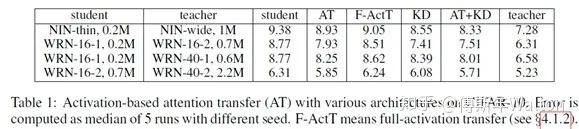
實驗結(jié)果如下:

Relation-based Knowledge
A gift from knowledge distillation: Fast optimization, network minimization and transfer learning CVPR 2017
不擬合Teacher模型的輸出,而是去擬合Teacher模型層與層之間的關(guān)系,類似于老師教學(xué)生做題,中間的結(jié)果并不重要,更應(yīng)該學(xué)習(xí)解題流程。關(guān)系通過層與層之間的內(nèi)積(點乘)來定義。
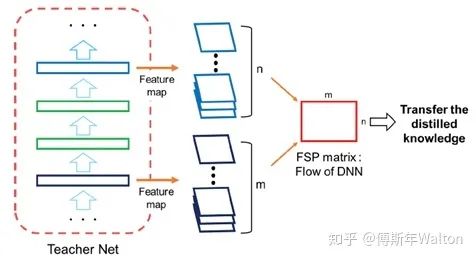
假如說甲層有 M 個輸出通道,乙層有 N 個輸出通道,就構(gòu)建一個 M*N 的矩陣來表示這兩層間的關(guān)系,其中 (i, j) 元是甲層第 i 個通道 和 乙層第 j 個通道的內(nèi)積(因此此方法需要甲乙兩層 feature map 的形狀相同)。作者使用residual module,從而避免spatial size的相同計算。如果為了保證feature map spatial size相等,可以使用zero padding。文中把這個矩陣叫 FSP (flow of solution procedure) 矩陣,其實這也是一種 Gram 矩陣,之前一篇很有名的文章 Neural Style 里也有成功的應(yīng)用:用 Gram 矩陣來描述圖像紋理,從而實現(xiàn)風(fēng)格轉(zhuǎn)換。Gram矩陣是計算每個通道i與通道j的feature map的內(nèi)積。Gram matrix的每個值都可以說是代表i通道的feature map與通道j的feature map互相關(guān)的程度。x代表輸入圖像,W代表FSP weights,F(xiàn)1/F2是產(chǎn)生的feature map,h*w代表feature map的height, width;m/n代表channel。
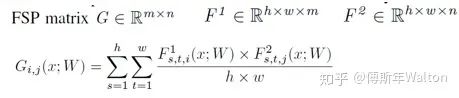
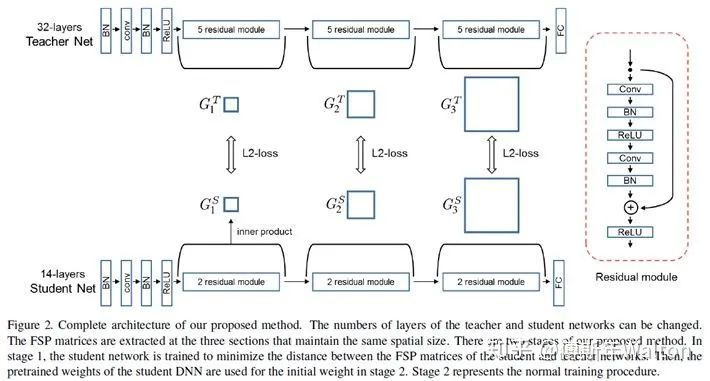
具體步驟:
1.最小化teacher模型FSP矩陣與student模型FSP矩陣之間的L2 Loss,用來初始化student模型的可訓(xùn)練參數(shù)。lamda代表不同層/點的權(quán)重系數(shù),paper里面設(shè)置為相同權(quán)重。
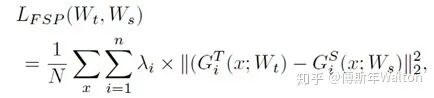
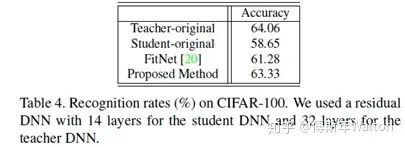
2. 在目標(biāo)任務(wù)的數(shù)據(jù)集上fine-tunestudent模型實驗結(jié)果:
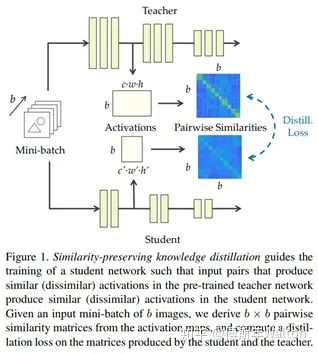
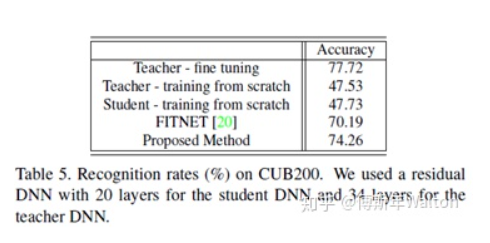 Similarity-preserving knowledge distillation ICCV 2019
Similarity-preserving knowledge distillation ICCV 2019
如果兩個輸入在老\師網(wǎng)絡(luò)中有著高度相似的激活,那么引導(dǎo)學(xué)生網(wǎng)絡(luò)趨向于對該輸入同樣產(chǎn)生高的相似激活(反之亦然)的參數(shù)組合,那將是有利的(對于學(xué)生更好的學(xué)老\師網(wǎng)絡(luò)的能力與知識)。基于這個觀察和假設(shè),本文主要思路提出了一個保留相似性損失,來促使學(xué)生網(wǎng)絡(luò)學(xué)老\師網(wǎng)絡(luò)在對于數(shù)據(jù)內(nèi)部的關(guān)系表達(dá)的知識。假設(shè)證明試驗:
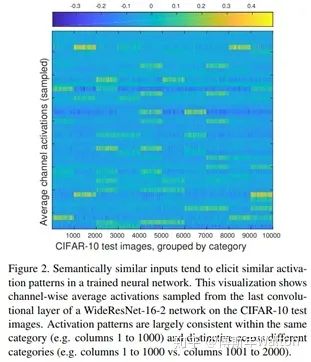
圖2這個圖指示了CIFAR-10中10000張圖片分別對應(yīng)于教師網(wǎng)絡(luò)最后一個卷積層的激活值中所有通道內(nèi)計算均值得到的矢量,整體繪制出來得到的結(jié)果。這里分成了十類,每一類對應(yīng)相鄰的1000張圖片,可見,相鄰的1000張圖片的激活情況是類似的,而不同類別之間有明顯差異。
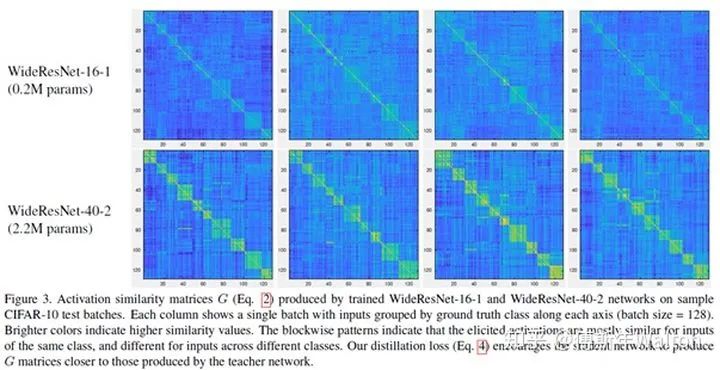
圖3中展示了對于CIFAR-10測試集上的數(shù)個batch的G矩陣可視化結(jié)果,這里的激活是從最后一個卷積層收集而來的。
? 每一列表示一個單獨的batch,兩個網(wǎng)絡(luò)都是一致的。
? 每個batch的圖像中,對于樣本的順序已經(jīng)通過其真值類別分組。一個batch包含128張圖片樣本。在兩行的G矩陣中,顯示了獨特的塊狀模式,這指示了者系網(wǎng)絡(luò)的最后一層的激活,在相同類別的時候有著相似的結(jié)果,而不同類別也有著不同的結(jié)果,也就是前者有著更大的相似性,后者相似性較小。
? 圖中每個塊大小不同,這主要是因為不同類別在每個batch中包含的樣本數(shù)不同。
? 上下對比也可以看出來,對于復(fù)雜模型(下面),塊狀模式更加明顯突出,這也反映出來,其對于捕獲數(shù)據(jù)集的語義信息有著更強的能力。
? 這樣的現(xiàn)象也在一定程度上支撐了本文的假設(shè),也反映出前面提出的相似性損失的意義與價值所在,就是促使學(xué)生網(wǎng)絡(luò)可以更好的模仿學(xué)老師模型對于數(shù)據(jù)特征中的關(guān)聯(lián)信息的學(xué)習(xí)。
保留相似性損失函數(shù)推導(dǎo):
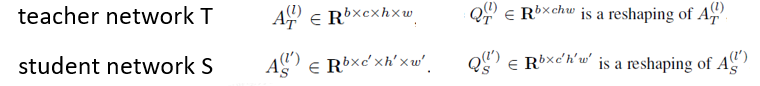

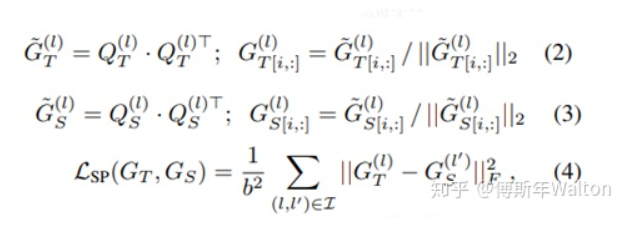
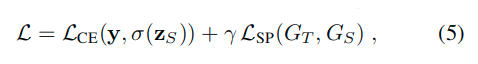
實驗結(jié)果:
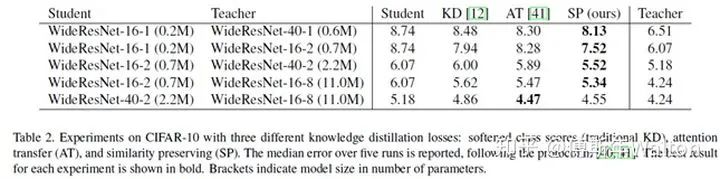
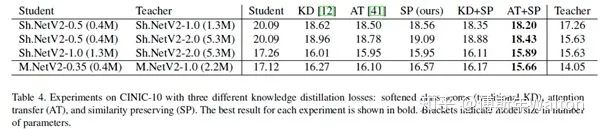
Feature/Relation-based Knowledge優(yōu)缺點總結(jié)優(yōu)點:
泛化性更好,目前SOTA的方法都是基于feature/Relation
可以處理cross domain transfer and low-level vision問題
缺點:
對于信息損失很難度量,因此很難選擇最好的方法。
大多數(shù)方法隨機選擇intermediate layers,可解釋性不夠
特征的蒸餾位置手動選擇或基于任務(wù)選擇
Applications-NLP-BERT
因為Bert本身參數(shù)量大,當(dāng)前對Bert瘦身有三個思路,分別是Distillation(蒸餾)、Quantization(量化)和Pruning(剪枝)。其中蒸餾效果最好。因此接下來,將通過三篇paper回顧下BERT蒸餾如何去做。
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter 2019
基于Transformer的預(yù)訓(xùn)練模型的趨勢就是越來越大,訓(xùn)練數(shù)據(jù)和參數(shù)量也是越來越多。
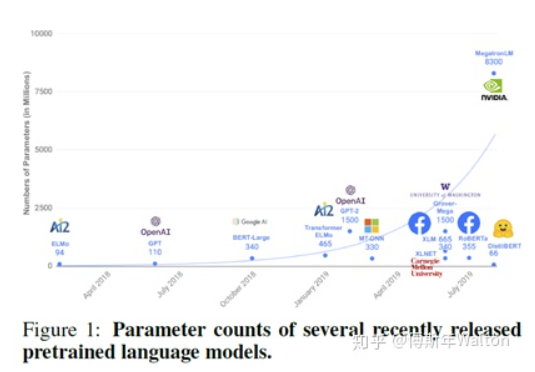 本文將介紹蒸餾方法中的DistilBert。把KD思想簡單應(yīng)用到BERT上,DistilBERT的參數(shù)大約只有BERT的40%,而速度快了60%,保證97%精度。大致思路:對BERT做forward pass,再計算Triple Loss,進(jìn)行Backward Propagation訓(xùn)練DistilBERT
本文將介紹蒸餾方法中的DistilBert。把KD思想簡單應(yīng)用到BERT上,DistilBERT的參數(shù)大約只有BERT的40%,而速度快了60%,保證97%精度。大致思路:對BERT做forward pass,再計算Triple Loss,進(jìn)行Backward Propagation訓(xùn)練DistilBERT
損失函數(shù):
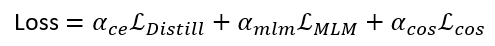
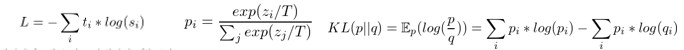
模型最后的輸出的由distillation loss 以及訓(xùn)練誤差,分別是 Mask language modeling loss 和cosine embedding loss 的線性加和組成。上面的公式主要是擬合兩個的模型輸出概率分布,理想當(dāng)然都是用cross entropy來解決,但是在看源碼的時候,我們發(fā)現(xiàn)這實現(xiàn)中用的是Kullback-Leibler loss。經(jīng)過查閱資料,發(fā)現(xiàn)其實KL距離和cross entropy其實是等價的,都是擬合兩個概率分布,使得最大似然。KL diversion 代表的是兩個分布的距離,越大 代表分布越不像,越小=0 代表兩個分布一樣。Mask language modeling loss(跟Bert 一致),首層的embedding的cosine embedding loss 。模型結(jié)構(gòu):
1. DistilBert將token-type embeddings以及pooler層去掉
2. 學(xué)生模型layer數(shù)是老師模型的一半,6層transformer encode,但是hidden dim是一致的,文章中指出學(xué)生參數(shù)初始化是直接復(fù)制老師模型的layers,具體的操作是skip的方式,例如12層的教師模型,學(xué)生模型6層,初始化用的是for teacher_idx in [0,2,4,7,9,11]。
實驗結(jié)果:
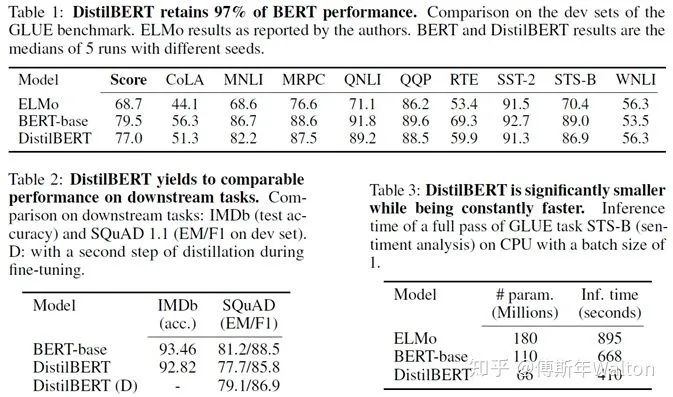
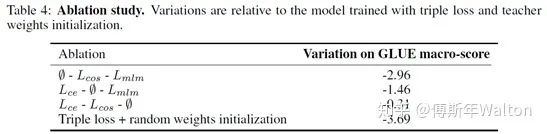
蒸餾模型的效果取決于三個方面,一個是模型大小,一個是模型效果,以及預(yù)測速度。文章中對比了distlbert以及教師模型Bert-Base,得出了結(jié)論,可以得到97%的bert的效果,大小減少了近40%,預(yù)測時間提高了60%。可以說還是非常好的。它也提出了,它的學(xué)生模型可以在iphone7上直接運行。同時,訓(xùn)練時長和機器配置相比訓(xùn)練BERT而言,明顯很有優(yōu)勢。
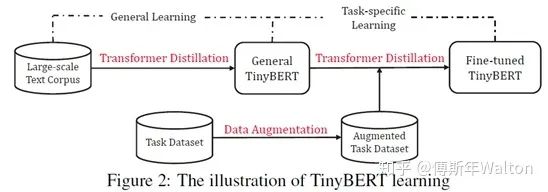
 TinyBERT: Distilling BERT for natural language understanding 2019
TinyBERT: Distilling BERT for natural language understanding 2019
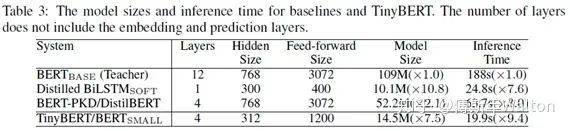
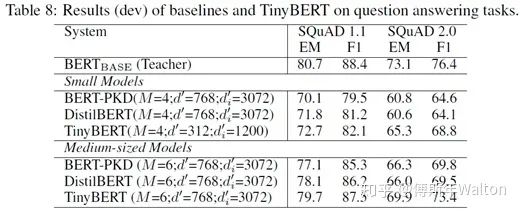
通過對Bert編碼器中的Transformer進(jìn)行壓縮,提出新的 transformer 蒸餾法,同時還提出了一種專門用于 TinyBERT的兩段式學(xué)習(xí)框架,從而分別在預(yù)訓(xùn)練和針對特定任務(wù)的具體學(xué)習(xí)階段執(zhí)行 transformer 蒸餾。這一框架確保 TinyBERT 可以獲取 teacherBERT 的通用和針對特定任務(wù)的知識。最終可以達(dá)到96% BERT base performance, 7.5x samller, 9.4x faster.
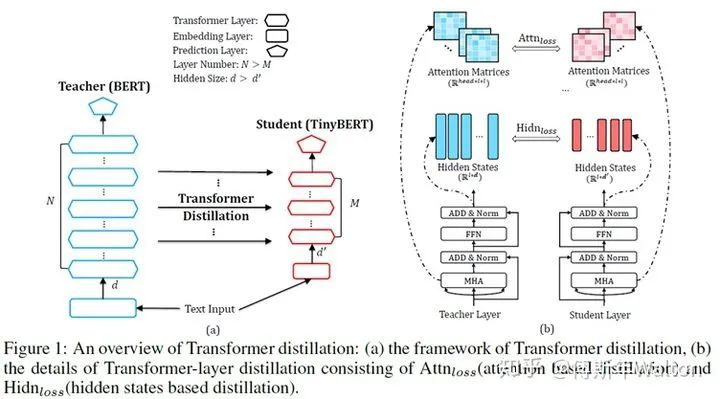
損失函數(shù)推導(dǎo):Transformer-layer Distillation
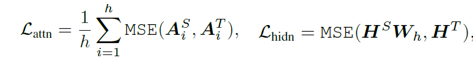
attention based distillation attention 的權(quán)重可以獲取很多的語言學(xué)的知識,所以不能夠忽視這些信息。文章中定義每一層的attention loss, 這邊的h表示的是attention heads的個數(shù)。hidden states based distillation 除了mimic attention 的權(quán)重之外,我們還需要mimic每個encoder的hidden states的輸出,Hs表示的是學(xué)生的某一個block的hidden states的output, Ht表示的是老師的對應(yīng)block的hidden states的output,為什么需要乘以Wh呢,這是因為做一個線性映射, Wh 是一個可學(xué)習(xí)的矩陣,目的是把學(xué)生模型的特定向量映射到對應(yīng)的老師模型的向量空間去,因為我們不要求兩個的維度一致。Embedding-layer Distillation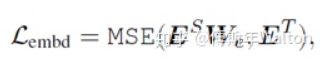 其實embedding layer的學(xué)習(xí)在distilBERT已經(jīng)提到了,它學(xué)習(xí)的是embedding的cosine距離,但是這邊提出的的方式用的是MSE,其中Es 表示的是學(xué)生的embedding,Et 表示的是老師的embedding,為什么需要乘以We呢,這是因為做一個線性映射, We 是一個可學(xué)習(xí)的矩陣,目的是把學(xué)生模型的特定向量映射到對應(yīng)的老師模型的向量空間去嗎,因為我們不要求兩個的維度一致。
其實embedding layer的學(xué)習(xí)在distilBERT已經(jīng)提到了,它學(xué)習(xí)的是embedding的cosine距離,但是這邊提出的的方式用的是MSE,其中Es 表示的是學(xué)生的embedding,Et 表示的是老師的embedding,為什么需要乘以We呢,這是因為做一個線性映射, We 是一個可學(xué)習(xí)的矩陣,目的是把學(xué)生模型的特定向量映射到對應(yīng)的老師模型的向量空間去嗎,因為我們不要求兩個的維度一致。
Prediction-Layer Distillation,最后的這個就是典型的softmax-soft loss了。
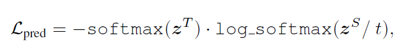
實驗結(jié)果: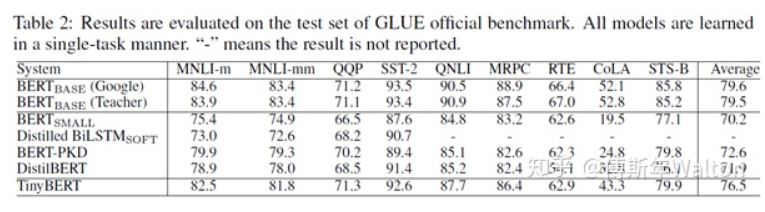
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers 2020
DistilBERT采用了soft-label distillation loss and a cosine embedding loss,并通過從兩層中選取一層來初始化老師的學(xué)生。但是,學(xué)生的每個Transformer層都必須具有與其老師相同的體系結(jié)構(gòu)。TinyBERT利用更細(xì)粒度的知識,包括Transformer網(wǎng)絡(luò)的hidden states和self-attention distributions,并將這些知識逐層轉(zhuǎn)移到學(xué)生模型中。為了進(jìn)行逐層蒸餾,TinyBERT采用統(tǒng)一函數(shù)來確定教師和學(xué)生層之間的映射,并使用參數(shù)矩陣對學(xué)生的隱藏狀態(tài)進(jìn)行線性變換。本文具體提出只蒸餾teacher網(wǎng)絡(luò)的最后一個Transformer層的self-attention模塊,就可以達(dá)到不錯的效果。與以前的方法相比,使用最后一個Transformer層的知識而不是執(zhí)行層到層的知識提純可以減輕教師模型和學(xué)生模型之間的層映射困難,并且我們的學(xué)生模型的層數(shù)可以更靈活.
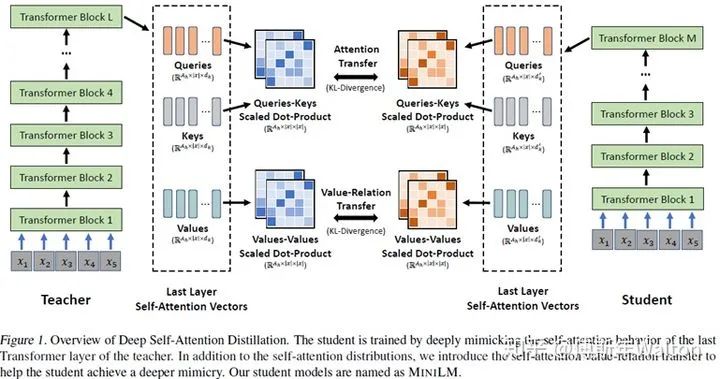
圖1整體介紹了深度自注意力知識蒸餾的方法,主要由兩種知識遷移構(gòu)成:第一種就是自注意力得分/分布遷移(Self-Attention Distribution Transfer),主要遷移自注意力得分/分布知識(Attention Scores/Distributions)。自注意力得分矩陣由Queries 和 Keys 通過點積操作得到,矩陣中每個值表示兩個詞的依賴關(guān)系。自注意力得分矩陣是自注意力模塊中至關(guān)重要的知識,我們通過相對熵(KL-Divergence)來計算大模型和小模型自注意力得分矩陣的差異。
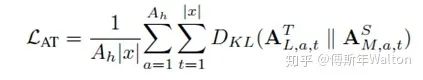
第二種,為了遷移更深層次的自注意力知識,使小模型可以更深層次地模仿大模型,我們引入了 Values 知識并將其轉(zhuǎn)換為關(guān)系矩陣進(jìn)行遷移。Values 關(guān)系矩陣(Value Relation)由 Values 向量間點積得到,可以表示 Values 詞與詞間的依賴。使用點積操作可以將大小模型不同維度的 Values 向量轉(zhuǎn)換為相同維度大小的關(guān)系矩陣,避免引入額外的隨機初始化參數(shù)對小模型的 Values 向量進(jìn)行線性變換,以使其和大模型向量具有相同的維度來進(jìn)行知識遷移。我們也通過相對熵來衡量大小模型間關(guān)系矩陣的差異。
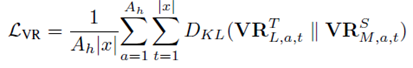
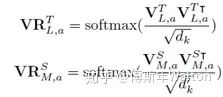

整體損失函數(shù):
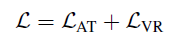
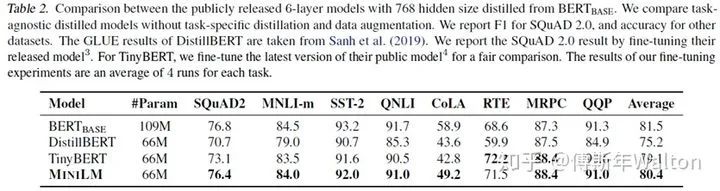
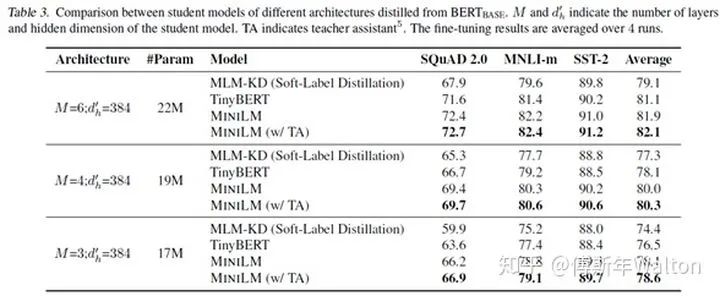
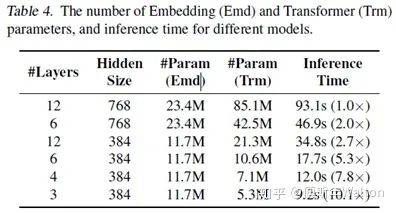
實驗結(jié)果:
QA
1. QA-Why KD works?
Explaining Knowledge Distillation by Quantifying the Knowledge. CVPR 2020
作者提出三個假設(shè),并依次證明。1.KD促使DNN更容易從數(shù)據(jù)中學(xué)習(xí)更多的視覺概念。2.KD可確保DNN更容易同時學(xué)習(xí)到各種視覺概念,在沒有KD的情況下,DNN在多個階段分階段學(xué)習(xí)不同的視覺概念。3. KD使得學(xué)習(xí)產(chǎn)生了更穩(wěn)定的優(yōu)化方向。
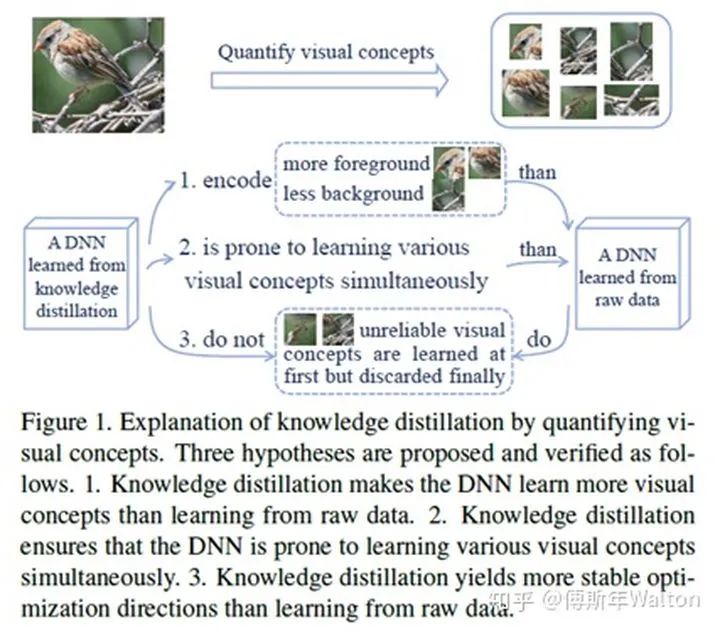
如何證明?對于第一個假設(shè),就是如何度量測試number of visual concepts;第二個假設(shè)就是度量學(xué)習(xí)不同visual concepts的速度;第三個假設(shè)就是度量學(xué)習(xí)的穩(wěn)定性。假設(shè)一證明:
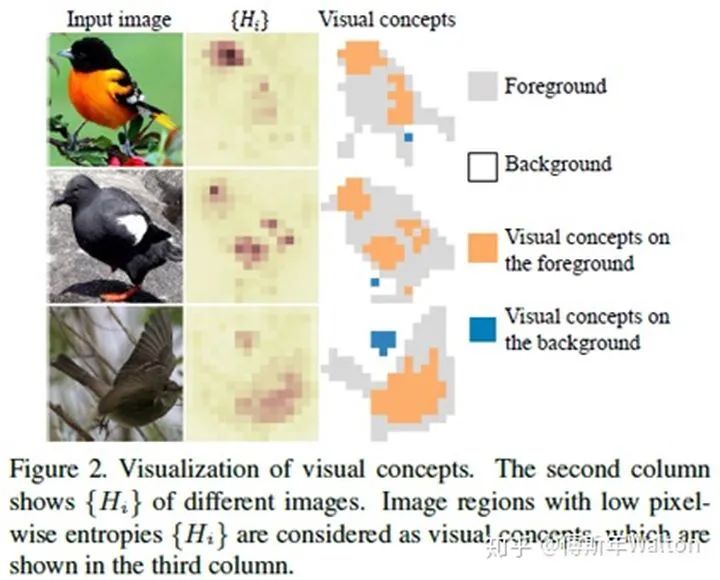
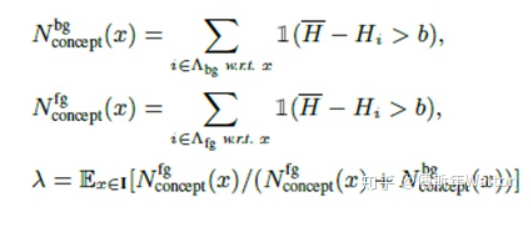
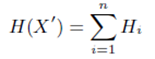
?H(x) 是整張圖的information entropy,它由每個像素點的entropy組成,? ?和?
?和? ?分別代表背景和前景上的number of visual concepts。x 是輸入圖像, 函數(shù)I代表is the indicator function。括號里面的條件滿足時,返回1;否則返回0。
?分別代表背景和前景上的number of visual concepts。x 是輸入圖像, 函數(shù)I代表is the indicator function。括號里面的條件滿足時,返回1;否則返回0。 ?代表 整個背景的平均熵值,用來測量信息的重要性。??as a baseline entropy. b是一個正實數(shù)。?
?代表 整個背景的平均熵值,用來測量信息的重要性。??as a baseline entropy. b是一個正實數(shù)。? ?該指標(biāo)用于衡量 特征的判別力。所以在訓(xùn)練結(jié)束后,如果??,??越大,??越小,證明假設(shè)一ok。具體請看最后試驗結(jié)果匯總表3。
?該指標(biāo)用于衡量 特征的判別力。所以在訓(xùn)練結(jié)束后,如果??,??越大,??越小,證明假設(shè)一ok。具體請看最后試驗結(jié)果匯總表3。
假設(shè)二證明:
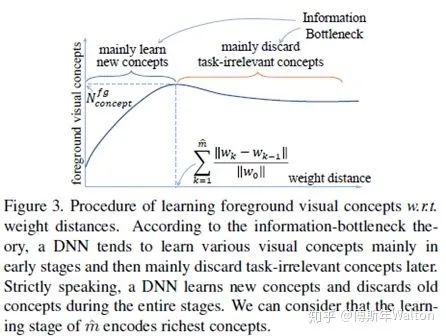
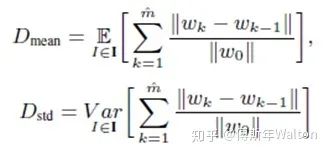
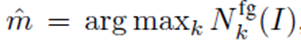
其實思路很直觀,是否前景??隨著訓(xùn)練epoch number增加而快速增加;是否不同input images的前景??增加。因此作者提出兩個參數(shù)去度量不同visual concepts的學(xué)習(xí)速度。Dmean平均值和Dstd標(biāo)準(zhǔn)差。作者首先定義了一個參數(shù)叫weight distance ,weight distance是定義 to measure the learning effect at 第幾個epoch,k代表不同的epoch number 。w0 代表初始參數(shù)wk 代表在k個epoch之后的參數(shù)。? ?代表??達(dá)到最大時的epoch number。Dmean 代表平均的weight distance,即DNN獲得的前景forground visual concepts數(shù)量,Dmean反應(yīng)了DNN學(xué)習(xí)visual concepts的速度是否快,越小越好;Dstd代表不同圖片之間的weight distance標(biāo)準(zhǔn)差,它意味著DNNs是否同時學(xué)到這些visual concepts。也是越小越好。總結(jié)下,就是越小的Dmean 和 Dstd意味著DNN學(xué)習(xí)visual concepts越快越同時。具體請看最后試驗結(jié)果匯總表3。
?代表??達(dá)到最大時的epoch number。Dmean 代表平均的weight distance,即DNN獲得的前景forground visual concepts數(shù)量,Dmean反應(yīng)了DNN學(xué)習(xí)visual concepts的速度是否快,越小越好;Dstd代表不同圖片之間的weight distance標(biāo)準(zhǔn)差,它意味著DNNs是否同時學(xué)到這些visual concepts。也是越小越好。總結(jié)下,就是越小的Dmean 和 Dstd意味著DNN學(xué)習(xí)visual concepts越快越同時。具體請看最后試驗結(jié)果匯總表3。
假設(shè)三證明:
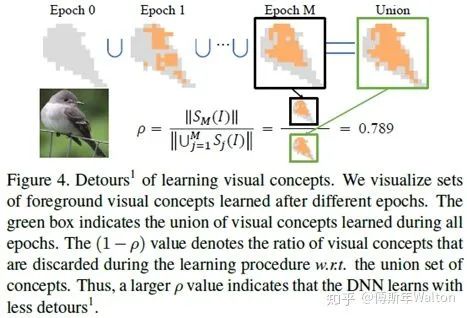
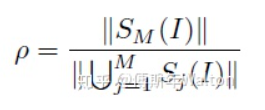
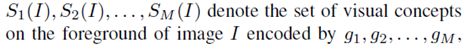
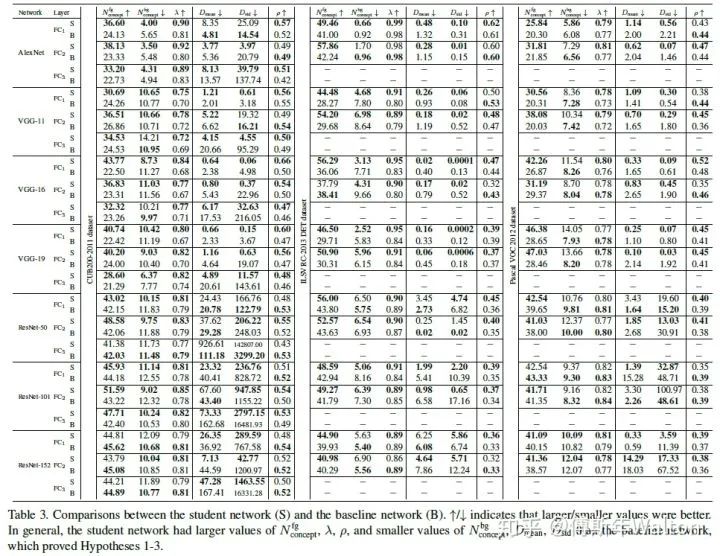
分子反應(yīng)了視覺概念的數(shù)量,最終被選作對象分類,就是圖4里面的黑框里面的東西;分母表示在學(xué)習(xí)過程中臨時學(xué)習(xí)到的視覺概念,就是圖4里面綠色框里面的東西。最終分子/分母,代表已嘗試過但最終被DNN丟棄的視覺概念集。一個高的 表示DNN少走彎路,更穩(wěn)定地優(yōu)化;反之亦然。具體請看最后試驗結(jié)果匯總表3。實驗結(jié)果:
表示DNN少走彎路,更穩(wěn)定地優(yōu)化;反之亦然。具體請看最后試驗結(jié)果匯總表3。實驗結(jié)果:
Variational information distillation for knowledge transfer. CVPR 2019
作者總結(jié)到,KD其實是最大化teacher network 和student network之間的mutual information(互信息)。通過大量的數(shù)學(xué)推導(dǎo),得出下面的公式。具體推導(dǎo)過程,讀者可以看原paper。

t代表教師網(wǎng)絡(luò)的中間層,s代表相對應(yīng)的student網(wǎng)絡(luò)的中間層,c,h,w分別對應(yīng)channel,height,width;q(t|s)是variational distribution變異分布,公式如圖所示,是一個高斯均方差分布和標(biāo)準(zhǔn)差之和。有了這個公式,可以畫出它學(xué)習(xí)過程中的variational distribution的heat map熱度圖(紅色像素代表概率越高),我們直接看圖。
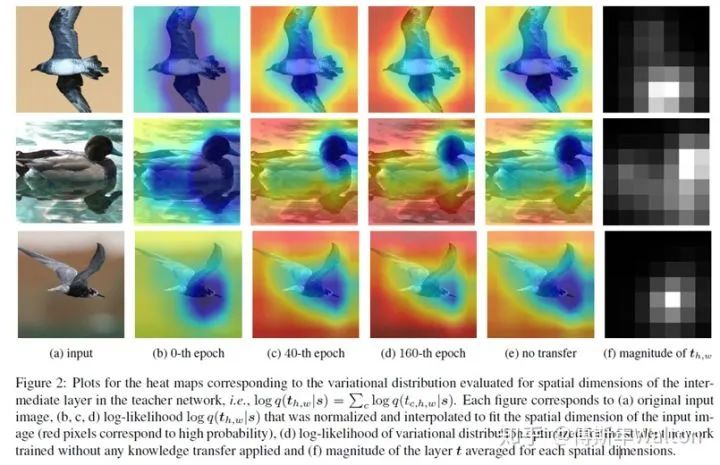
圖a是輸入圖像,圖(b,c和d)是不同訓(xùn)練epoch下的student網(wǎng)絡(luò)和teacher網(wǎng)絡(luò)variational distribution的密度heat map變化,觀察到學(xué)生網(wǎng)絡(luò)通過訓(xùn)練,根據(jù)教師網(wǎng)絡(luò)去估計中間層的密度分布;同時作為比較,作者也畫出了未經(jīng)KD訓(xùn)練的學(xué)生網(wǎng)絡(luò)和老師網(wǎng)絡(luò)的variational distribution的密度heat map變化(圖e所示)。通過e和b/c/d的相互比較,我們觀察到e無法獲得較高的variational distribution對數(shù)似然概率,這表明教師與學(xué)生網(wǎng)絡(luò)之間的相互信息較少。即作者的推斷和理論推導(dǎo)work,KD其實是最大化teacher network 和student network之間的mutual information(互信息)。
2. QA-Are bigger models better teachers?
On the efficacy of knowledge distillation. ICCV 2019

模型容量不匹配,導(dǎo)致student模型不能夠mimic teacher,反而帶偏了主要的loss;
KD losses 和accuracy不匹配,導(dǎo)致student雖然可以follow teacher, 但是并不能吸收teacher知識。
3. QA-Is a pretrained teacher important?
Deep mutual learning. CVPR 2018
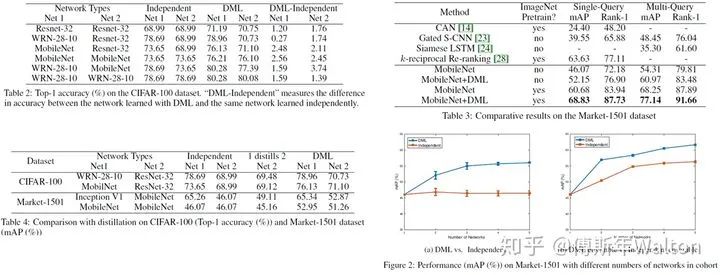
這篇paper其實兩方面辯證來看,1.假設(shè)沒有一個pretrained的teacher模型,那KD在不同的peer students中間學(xué)習(xí),也是可以獲得不錯的提高,所以pretrained的teacher其實沒有那么重要,就拿bert這種大模型來說,如果pretrain一次大模型,需要很多數(shù)據(jù),機器,時間成本去訓(xùn)練,那我們完全可以換幾個小模型去訓(xùn)練,去做蒸餾;2.如果在有pretrain的teacher前提下,那我們肯定讓teacher更好的含有知識,就拿圖像分類來說,它在imagnet上pre-train,再去fine tune其他模型,效果很明顯。
4. QA-Single teacher vs multiple teachers
Learning from multiple teacher networks. SIGKDD 2017
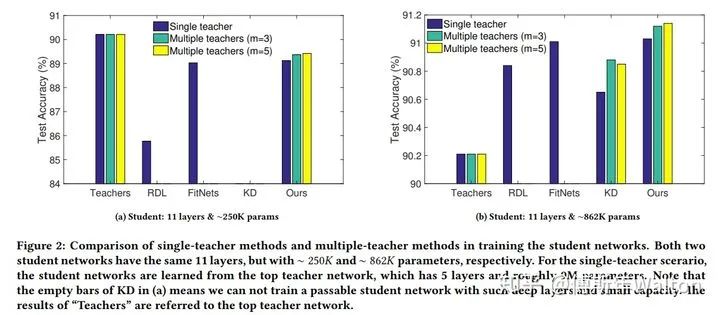
后記:20篇paper簡單回顧下KD在過去6年的發(fā)展,可以看到一些令人激動或者眼前一亮的工作。歡迎大家和我繼續(xù)交流,我們一起探索KD更多的可能性。在part2/3/4的陳述中,我沒有加paper的引用和下載鏈接,但是都列出每一篇paper的title和發(fā)表年份,讀者們感興趣自行搜索即可。
參考
Model compression??https://www.cs.cornell.edu/~caruana/compression.kdd06.pdf Distilling the Knowledge in a Neural Network??https://arxiv.org/pdf/1503.02531.pdf Knowledge Distillation: A Survey?https://arxiv.org/pdf/2006.05525.pdf
推薦閱讀
