
Redis(八):zset/zadd/zrange/zrembyscore 命令源碼解析
前面幾篇文章,我們完全領(lǐng)略了redis的string,hash,list,set數(shù)據(jù)類型的實(shí)現(xiàn)方法,相信對(duì)redis已經(jīng)不再神秘。
本篇我們將介紹redis的最后一種數(shù)據(jù)類型: zset 的相關(guān)實(shí)現(xiàn)。
本篇過(guò)后,我們對(duì)redis的各種基礎(chǔ)功能,應(yīng)該不會(huì)再有疑惑。有可能的話,我們后續(xù)將會(huì)對(duì)redis的高級(jí)功能的實(shí)現(xiàn)做解析。(如復(fù)制、哨兵模式、集群模式)
回歸本篇主題,zset。zset 又稱有序集合(sorted set),即是序版本的set。經(jīng)過(guò)上篇的介紹,大家可以看到,redis的讀取功能相當(dāng)有限,許多是基于隨機(jī)數(shù)的方式進(jìn)行讀取,其原因就是set是無(wú)序的。當(dāng)set有序之后,查詢能力就會(huì)得到極大的提升。
可以根據(jù)下標(biāo)進(jìn)行定位元素;
可以范圍查詢?cè)? 這是有序帶來(lái)的好處。
那么,我們不妨先思考一下,如何實(shí)現(xiàn)有序??jī)煞N方法:1. 根據(jù)添加順序定義,1、2、3... ; 2. 自定義排序值; 第1種方法實(shí)現(xiàn)簡(jiǎn)單,添加時(shí)復(fù)雜度小,但是功能受限;第2種方法相對(duì)自由,對(duì)于每次插入都可能涉及重排序問(wèn)題,但是查詢相對(duì)穩(wěn)定,可以不必完全受限于系統(tǒng)實(shí)現(xiàn);
同樣,我們以功能列表,到數(shù)據(jù)結(jié)構(gòu),再功能實(shí)現(xiàn)的思路,來(lái)解析redis的zset有序集合的實(shí)現(xiàn)方式吧。
零、redis zset相關(guān)操作方法
zset: Redis 有序集合是string類型元素的集合,且不允許重復(fù)的成員。每個(gè)元素都會(huì)關(guān)聯(lián)一個(gè)double類型的分?jǐn)?shù),通過(guò)分?jǐn)?shù)來(lái)為集合中的成員進(jìn)行從小到大的排序。
使用場(chǎng)景如: 保存任務(wù)隊(duì)列,該隊(duì)列由后臺(tái)定時(shí)掃描; 排行榜;
從官方手冊(cè)上查到相關(guān)使用方法如下:
1> ZADD key score1 member1 [score2 member2]
功能: 向有序集合添加一個(gè)或多個(gè)成員,或者更新已存在成員的分?jǐn)?shù)
返回值: 添加成功的元素個(gè)數(shù)(已存在的添加不成功)2> ZCARD key
功能: 獲取有序集合的成員數(shù)
返回值: 元素個(gè)數(shù)或03> ZCOUNT key min max
功能: 計(jì)算在有序集合中指定區(qū)間分?jǐn)?shù)的成員數(shù)
返回值: 區(qū)間內(nèi)的元素個(gè)數(shù)4> ZINCRBY key increment member
功能: 有序集合中對(duì)指定成員的分?jǐn)?shù)加上增量 increment
返回值: member增加后的分?jǐn)?shù)5> ZINTERSTORE destination numkeys key [key ...]
功能: 計(jì)算給定的一個(gè)或多個(gè)有序集的交集并將結(jié)果集存儲(chǔ)在新的有序集合 key 中
返回值: 交集元素個(gè)數(shù)6> ZLEXCOUNT key min max
功能: 在有序集合中計(jì)算指定字典區(qū)間內(nèi)成員數(shù)量
返回值: 區(qū)間內(nèi)的元素個(gè)數(shù)7> ZRANGE key start stop [WITHSCORES]
功能: 通過(guò)索引區(qū)間返回有序集合指定區(qū)間內(nèi)的成員
返回值: 區(qū)間內(nèi)元素列表8> ZRANGEBYLEX key min max [LIMIT offset count]
功能: 通過(guò)字典區(qū)間返回有序集合的成員
返回值: 區(qū)間內(nèi)元素列表9> ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT]
功能: 通過(guò)分?jǐn)?shù)返回有序集合指定區(qū)間內(nèi)的成員
返回值: 區(qū)間內(nèi)元素列表10> ZRANK key member
功能: 返回有序集合中指定成員的索引
返回值: member的排名或者 nil11> ZREM key member [member ...]
功能: 移除有序集合中的一個(gè)或多個(gè)成員
返回值: 成功移除的元素個(gè)數(shù)12> ZREMRANGEBYLEX key min max
功能: 移除有序集合中給定的字典區(qū)間的所有成員
返回值: 成功移除的元素個(gè)數(shù)13> ZREMRANGEBYRANK key start stop
功能: 移除有序集合中給定的排名區(qū)間的所有成員
返回值: 成功移除的元素個(gè)數(shù)14> ZREMRANGEBYSCORE key min max
功能: 移除有序集合中給定的分?jǐn)?shù)區(qū)間的所有成員
返回值: 成功移除的元素個(gè)數(shù)15> ZREVRANGE key start stop [WITHSCORES]
功能: 返回有序集中指定區(qū)間內(nèi)的成員,通過(guò)索引,分?jǐn)?shù)從高到低
返回值: 區(qū)間內(nèi)元素列表及分?jǐn)?shù)16> ZREVRANGEBYSCORE key max min [WITHSCORES]
功能: 返回有序集中指定分?jǐn)?shù)區(qū)間內(nèi)的成員,分?jǐn)?shù)從高到低排序
返回值: 區(qū)間內(nèi)元素列表及分?jǐn)?shù)17> ZREVRANK key member
功能: 返回有序集合中指定成員的排名,有序集成員按分?jǐn)?shù)值遞減(從大到小)排序
返回值: member排名或者 nil18> ZSCORE key member
功能: 返回有序集中,成員的分?jǐn)?shù)值
返回值: member分?jǐn)?shù)19> ZUNIONSTORE destination numkeys key [key ...]
功能: 計(jì)算給定的一個(gè)或多個(gè)有序集的并集,并存儲(chǔ)在新的 key 中
返回值: 存儲(chǔ)到新key的元素個(gè)數(shù)20> ZSCAN key cursor [MATCH pattern] [COUNT count]
功能: 迭代有序集合中的元素(包括元素成員和元素分值)
返回值: 元素列表21> ZPOPMAX/ZPOPMIN/BZPOPMAX/BZPOPMIN
一、zset 相關(guān)數(shù)據(jù)結(jié)構(gòu)
zset 的實(shí)現(xiàn),使用了 ziplist, zskiplist 和 dict 進(jìn)行實(shí)現(xiàn)。
/* ZSETs use a specialized version of Skiplists */typedef struct zskiplistNode {sds ele;double score;struct zskiplistNode *backward;struct zskiplistLevel {struct zskiplistNode *forward;unsigned int span;} level[];} zskiplistNode;// 跳躍鏈表typedef struct zskiplist {struct zskiplistNode *header, *tail;unsigned long length;int level;} zskiplist;// zset 主數(shù)據(jù)結(jié)構(gòu),dict + zskiplisttypedef struct zset {dict *dict;zskiplist *zsl;} zset;// zset 在合適場(chǎng)景下,將先使用 ziplist 存儲(chǔ)數(shù)據(jù)typedef struct zlentry {unsigned int prevrawlensize, prevrawlen;unsigned int lensize, len;unsigned int headersize;unsigned char encoding;unsigned char *p;} zlentry;
二、zadd 添加成員操作
從添加實(shí)現(xiàn)中,我們可以完整領(lǐng)略數(shù)據(jù)結(jié)構(gòu)的運(yùn)用。
// 用法: ZADD key score1 member1 [score2 member2]// t_zset.cvoid zaddCommand(client *c) {// zadd 的多個(gè)參數(shù)變形, 使用 flags 進(jìn)行區(qū)分復(fù)用zaddGenericCommand(c,ZADD_NONE);}void zaddGenericCommand(client *c, int flags) {static char *nanerr = "resulting score is not a number (NaN)";robj *key = c->argv[1];robj *zobj;sds ele;double score = 0, *scores = NULL, curscore = 0.0;int j, elements;int scoreidx = 0;/* The following vars are used in order to track what the command actually* did during the execution, to reply to the client and to trigger the* notification of keyspace change. */int added = 0; /* Number of new elements added. */int updated = 0; /* Number of elements with updated score. */int processed = 0; /* Number of elements processed, may remain zero withoptions like XX. *//* Parse options. At the end 'scoreidx' is set to the argument position* of the score of the first score-element pair. */// 從第三位置開(kāi)始嘗試解析特殊標(biāo)識(shí)(用法規(guī)范)// 按位與到 flags 中scoreidx = 2;while(scoreidx < c->argc) {char *opt = c->argv[scoreidx]->ptr;// NX: 不更新已存在的元素,只做添加操作if (!strcasecmp(opt,"nx")) flags |= ZADD_NX;// XX: 只做更新操作,不做添加操作else if (!strcasecmp(opt,"xx")) flags |= ZADD_XX;// CH: 將返回值從添加的新元素?cái)?shù)修改為已更改元素的總數(shù)。更改的元素是第添加的新元素以及已為其更新分?jǐn)?shù)的現(xiàn)有元素。因此,命令行中指定的具有與過(guò)去相同分?jǐn)?shù)的元素將不計(jì)算在內(nèi)。注意:通常,ZADD的返回值僅計(jì)算添加的新元素的數(shù)量。else if (!strcasecmp(opt,"ch")) flags |= ZADD_CH;// INCR: 使用指定元素增加指定分?jǐn)?shù), 與 ZINCRBY 類似,此場(chǎng)景下,只允許操作一個(gè)元素else if (!strcasecmp(opt,"incr")) flags |= ZADD_INCR;else break;scoreidx++;}/* Turn options into simple to check vars. */int incr = (flags & ZADD_INCR) != 0;int nx = (flags & ZADD_NX) != 0;int xx = (flags & ZADD_XX) != 0;int ch = (flags & ZADD_CH) != 0;/* After the options, we expect to have an even number of args, since* we expect any number of score-element pairs. */// 把特殊標(biāo)識(shí)去除后,剩下的參數(shù)列表應(yīng)該2n數(shù),即 score-element 一一配對(duì)的,否則語(yǔ)法錯(cuò)誤elements = c->argc-scoreidx;if (elements % 2) {addReply(c,shared.syntaxerr);return;}elements /= 2; /* Now this holds the number of score-element pairs. *//* Check for incompatible options. */// 互斥項(xiàng)if (nx && xx) {addReplyError(c,"XX and NX options at the same time are not compatible");return;}// 語(yǔ)法檢查,INCR 只能針對(duì)1個(gè)元素操作if (incr && elements > 1) {addReplyError(c,"INCR option supports a single increment-element pair");return;}/* Start parsing all the scores, we need to emit any syntax error* before executing additions to the sorted set, as the command should* either execute fully or nothing at all. */// 解析所有的 score 值為double類型,賦值到 scores 中scores = zmalloc(sizeof(double)*elements);for (j = 0; j < elements; j++) {if (getDoubleFromObjectOrReply(c,c->argv[scoreidx+j*2],&scores[j],NULL)!= C_OK) goto cleanup;}/* Lookup the key and create the sorted set if does not exist. */// 語(yǔ)法檢查zobj = lookupKeyWrite(c->db,key);if (zobj == NULL) {if (xx) goto reply_to_client; /* No key + XX option: nothing to do. */// 創(chuàng)建原始key對(duì)象// 默認(rèn) zset_max_ziplist_entries=OBJ_ZSET_MAX_ZIPLIST_ENTRIES: 128// 默認(rèn) zset_max_ziplist_value=OBJ_ZSET_MAX_ZIPLIST_VALUE: 64// 所以此處默認(rèn)主要是檢查 第1個(gè)member的長(zhǎng)度是大于 64if (server.zset_max_ziplist_entries == 0 ||server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr)){// 2. 通用情況使用 dict+quicklist 型的zsetzobj = createZsetObject();} else {// 1. 元素比較小的情況下創(chuàng)建 ziplist 型的 zsetzobj = createZsetZiplistObject();}// 將對(duì)象添加到db中,后續(xù)所有操作針對(duì) zobj 操作即是對(duì)db的操作 (引用傳遞)dbAdd(c->db,key,zobj);} else {if (zobj->type != OBJ_ZSET) {addReply(c,shared.wrongtypeerr);goto cleanup;}}// 一個(gè)個(gè)元素循環(huán)添加for (j = 0; j < elements; j++) {score = scores[j];ele = c->argv[scoreidx+1+j*2]->ptr;// 分當(dāng)前zobj的編碼不同進(jìn)行添加 (ziplist, skiplist)// 3. ZIPLIST 編碼下的zset添加操作if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {unsigned char *eptr;// 3.1. 查找是否存在要添加的元素 (確定添加或更新)if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {if (nx) continue;if (incr) {score += curscore;if (isnan(score)) {addReplyError(c,nanerr);goto cleanup;}}/* Remove and re-insert when score changed. */if (score != curscore) {// 3.2. 元素更新操作,先刪再插入zobj->ptr = zzlDelete(zobj->ptr,eptr);zobj->ptr = zzlInsert(zobj->ptr,ele,score);server.dirty++;updated++;}processed++;} else if (!xx) {/* Optimize: check if the element is too large or the list* becomes too long *before* executing zzlInsert. */zobj->ptr = zzlInsert(zobj->ptr,ele,score);// 5. 超過(guò)一條件后,做 ziplist->skiplist 轉(zhuǎn)換// 默認(rèn) 元素個(gè)數(shù)>128, 當(dāng)前元素>64// 這兩個(gè)判斷不會(huì)重復(fù)嗎???jī)蓚€(gè)原因: 1. 轉(zhuǎn)換函數(shù)內(nèi)部會(huì)重新判定; 2. 下一次循環(huán)時(shí)不會(huì)再走當(dāng)前邏輯;if (zzlLength(zobj->ptr) > server.zset_max_ziplist_entries)zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);if (sdslen(ele) > server.zset_max_ziplist_value)zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);server.dirty++;added++;processed++;}}// 4. skiplist 下的zset元素添加else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {zset *zs = zobj->ptr;zskiplistNode *znode;dictEntry *de;// 判斷ele是否已存在,使用hash查找,快速de = dictFind(zs->dict,ele);if (de != NULL) {if (nx) continue;curscore = *(double*)dictGetVal(de);if (incr) {score += curscore;if (isnan(score)) {addReplyError(c,nanerr);/* Don't need to check if the sorted set is empty* because we know it has at least one element. */goto cleanup;}}/* Remove and re-insert when score changes. */// 先刪再插入 skiplistif (score != curscore) {zskiplistNode *node;serverAssert(zslDelete(zs->zsl,curscore,ele,&node));znode = zslInsert(zs->zsl,score,node->ele);/* We reused the node->ele SDS string, free the node now* since zslInsert created a new one. */node->ele = NULL;zslFreeNode(node);/* Note that we did not removed the original element from* the hash table representing the sorted set, so we just* update the score. */// 更新dict中的分?jǐn)?shù)引用dictGetVal(de) = &znode->score; /* Update score ptr. */server.dirty++;updated++;}processed++;} else if (!xx) {ele = sdsdup(ele);znode = zslInsert(zs->zsl,score,ele);// 添加skiplist的同時(shí),也往 dict 中添加一份數(shù)據(jù),因?yàn)閔ash的查找永遠(yuǎn)是最快的serverAssert(dictAdd(zs->dict,ele,&znode->score) == DICT_OK);server.dirty++;added++;processed++;}} else {serverPanic("Unknown sorted set encoding");}}reply_to_client:if (incr) { /* ZINCRBY or INCR option. */if (processed)addReplyDouble(c,score);elseaddReply(c,shared.nullbulk);} else { /* ZADD. */addReplyLongLong(c,ch ? added+updated : added);}cleanup:zfree(scores);if (added || updated) {signalModifiedKey(c->db,key);notifyKeyspaceEvent(NOTIFY_ZSET,incr ? "zincr" : "zadd", key, c->db->id);}}// 1. 元素比較小的情況下創(chuàng)建 ziplist 型的 zset// object.c, 創(chuàng)建ziplist 的zsetrobj *createZsetZiplistObject(void) {unsigned char *zl = ziplistNew();robj *o = createObject(OBJ_ZSET,zl);o->encoding = OBJ_ENCODING_ZIPLIST;return o;}// 2. 創(chuàng)建通用的 zset 實(shí)例// object.crobj *createZsetObject(void) {zset *zs = zmalloc(sizeof(*zs));robj *o;// zsetDictType 稍有不同zs->dict = dictCreate(&zsetDictType,NULL);// 首次遇到 skiplist, 咱去瞅瞅是如何創(chuàng)建的zs->zsl = zslCreate();o = createObject(OBJ_ZSET,zs);o->encoding = OBJ_ENCODING_SKIPLIST;return o;}// server.c, zset創(chuàng)建時(shí)使用的dict類型,與hash有不同/* Sorted sets hash (note: a skiplist is used in addition to the hash table) */dictType zsetDictType = {dictSdsHash, /* hash function */NULL, /* key dup */NULL, /* val dup */dictSdsKeyCompare, /* key compare */NULL, /* Note: SDS string shared & freed by skiplist */NULL /* val destructor */};// 創(chuàng)建 skiplist 對(duì)象/* Create a new skiplist. */zskiplist *zslCreate(void) {int j;zskiplist *zsl;zsl = zmalloc(sizeof(*zsl));zsl->level = 1;zsl->length = 0;// 創(chuàng)建header節(jié)點(diǎn),ZSKIPLIST_MAXLEVEL 32zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);// 初始化headerfor (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {zsl->header->level[j].forward = NULL;zsl->header->level[j].span = 0;}zsl->header->backward = NULL;zsl->tail = NULL;return zsl;}/* Create a skiplist node with the specified number of levels.* The SDS string 'ele' is referenced by the node after the call. */zskiplistNode *zslCreateNode(int level, double score, sds ele) {zskiplistNode *zn =zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));zn->score = score;zn->ele = ele;return zn;}// 3. ZIPLIST 編碼下的zset添加操作// 3.1. 查找是否存在要添加的元素 (確定添加或更新)// t_zset.c, 查找指定eleunsigned char *zzlFind(unsigned char *zl, sds ele, double *score) {unsigned char *eptr = ziplistIndex(zl,0), *sptr;// 遍歷所有ziplist// 可見(jiàn),此時(shí)的ziplist并沒(méi)有表現(xiàn)出有序啊while (eptr != NULL) {// eptr 相當(dāng)于是 key// sptr 相當(dāng)于scoresptr = ziplistNext(zl,eptr);serverAssert(sptr != NULL);if (ziplistCompare(eptr,(unsigned char*)ele,sdslen(ele))) {/* Matching element, pull out score. */// 找到相應(yīng)的 key 后,解析下一值,即 scoreif (score != NULL) *score = zzlGetScore(sptr);return eptr;}/* Move to next element. */// 移動(dòng)兩次對(duì)象,才會(huì)到下一元素(因?yàn)榇鎯?chǔ)是 key-score 相鄰存儲(chǔ))eptr = ziplistNext(zl,sptr);}return NULL;}// t_zset.c, 獲取元素的scoredouble zzlGetScore(unsigned char *sptr) {unsigned char *vstr;unsigned int vlen;long long vlong;char buf[128];double score;serverAssert(sptr != NULL);serverAssert(ziplistGet(sptr,&vstr,&vlen,&vlong));// 帶小數(shù)點(diǎn)不帶小數(shù)點(diǎn)if (vstr) {memcpy(buf,vstr,vlen);buf[vlen] = '\0';// 做類型轉(zhuǎn)換score = strtod(buf,NULL);} else {score = vlong;}return score;}// 3.2. 元素更新操作,先刪再插入// t_zset.c/* Delete (element,score) pair from ziplist. Use local copy of eptr because we* don't want to modify the one given as argument. */unsigned char *zzlDelete(unsigned char *zl, unsigned char *eptr) {unsigned char *p = eptr;/* TODO: add function to ziplist API to delete N elements from offset. */zl = ziplistDelete(zl,&p);zl = ziplistDelete(zl,&p);return zl;}// 添加 ele-score 到 ziplist 中/* Insert (element,score) pair in ziplist. This function assumes the element is* not yet present in the list. */unsigned char *zzlInsert(unsigned char *zl, sds ele, double score) {unsigned char *eptr = ziplistIndex(zl,0), *sptr;double s;// 在上面查找時(shí),我們看到ziplist也是遍歷,以為是無(wú)序的ziplist// 然而實(shí)際上,插入時(shí)是維護(hù)了順序的喲while (eptr != NULL) {sptr = ziplistNext(zl,eptr);serverAssert(sptr != NULL);s = zzlGetScore(sptr);// 找到第一個(gè)比score大的位置,在其前面插入 ele-scoreif (s > score) {/* First element with score larger than score for element to be* inserted. This means we should take its spot in the list to* maintain ordering. */zl = zzlInsertAt(zl,eptr,ele,score);break;} else if (s == score) {/* Ensure lexicographical ordering for elements. */// 當(dāng)分?jǐn)?shù)相同時(shí),按字典順序排列if (zzlCompareElements(eptr,(unsigned char*)ele,sdslen(ele)) > 0) {zl = zzlInsertAt(zl,eptr,ele,score);break;}}/* Move to next element. */eptr = ziplistNext(zl,sptr);}/* Push on tail of list when it was not yet inserted. */// 以上遍歷完成都沒(méi)有找到相應(yīng)位置,說(shuō)明當(dāng)前score是最大值,將其插入尾部if (eptr == NULL)zl = zzlInsertAt(zl,NULL,ele,score);return zl;}// 在eptr的前面插入 ele-scoreunsigned char *zzlInsertAt(unsigned char *zl, unsigned char *eptr, sds ele, double score) {unsigned char *sptr;char scorebuf[128];int scorelen;size_t offset;scorelen = d2string(scorebuf,sizeof(scorebuf),score);if (eptr == NULL) {// 直接插入到尾部zl = ziplistPush(zl,(unsigned char*)ele,sdslen(ele),ZIPLIST_TAIL);zl = ziplistPush(zl,(unsigned char*)scorebuf,scorelen,ZIPLIST_TAIL);} else {/* Keep offset relative to zl, as it might be re-allocated. */offset = eptr-zl;// 直接在 eptr 位置添加 ele, 其他元素后移zl = ziplistInsert(zl,eptr,(unsigned char*)ele,sdslen(ele));eptr = zl+offset;/* Insert score after the element. */// 此時(shí)的 eptr 已經(jīng)插入ele之后的位置,后移一位后,就可以找到 score 的存儲(chǔ)位置serverAssert((sptr = ziplistNext(zl,eptr)) != NULL);zl = ziplistInsert(zl,sptr,(unsigned char*)scorebuf,scorelen);}return zl;}// 4. skiplist 下的zset元素添加// 4.1. 添加元素// t_zset.c, 添加 ele-score 到 skiplist 中/* Insert a new node in the skiplist. Assumes the element does not already* exist (up to the caller to enforce that). The skiplist takes ownership* of the passed SDS string 'ele'. */zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {// ZSKIPLIST_MAXLEVEL 32zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;unsigned int rank[ZSKIPLIST_MAXLEVEL];int i, level;serverAssert(!isnan(score));x = zsl->header;// 初始 zsl->level = 1// 從header的最高層開(kāi)始遍歷for (i = zsl->level-1; i >= 0; i--) {/* store rank that is crossed to reach the insert position */// 計(jì)算出每層可以插入的位置rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];// 當(dāng)前l(fā)evel的score小于需要添加的元素時(shí),往前推進(jìn)skiplistwhile (x->level[i].forward &&(x->level[i].forward->score < score ||(x->level[i].forward->score == score &&sdscmp(x->level[i].forward->ele,ele) < 0))){rank[i] += x->level[i].span;x = x->level[i].forward;}update[i] = x;}/* we assume the element is not already inside, since we allow duplicated* scores, reinserting the same element should never happen since the* caller of zslInsert() should test in the hash table if the element is* already inside or not. */// 得到一隨機(jī)的level, 決定要寫的節(jié)點(diǎn)數(shù)// 如果當(dāng)前的level過(guò)小,則變更level, 重新初始化大的levellevel = zslRandomLevel();if (level > zsl->level) {for (i = zsl->level; i < level; i++) {rank[i] = 0;update[i] = zsl->header;update[i]->level[i].span = zsl->length;}zsl->level = level;}// 構(gòu)建新的 skiplist 節(jié)點(diǎn),為每一層節(jié)點(diǎn)添加同樣的數(shù)據(jù)x = zslCreateNode(level,score,ele);for (i = 0; i < level; i++) {// 讓i層的節(jié)點(diǎn)與x關(guān)聯(lián)x->level[i].forward = update[i]->level[i].forward;update[i]->level[i].forward = x;/* update span covered by update[i] as x is inserted here */x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);update[i]->level[i].span = (rank[0] - rank[i]) + 1;}/* increment span for untouched levels */// 如果當(dāng)前l(fā)evel較小,則存在有的level未賦值情況,需要主動(dòng)+1for (i = level; i < zsl->level; i++) {update[i]->level[i].span++;}// 關(guān)聯(lián)好header后,設(shè)置backward指針x->backward = (update[0] == zsl->header) ? NULL : update[0];if (x->level[0].forward)x->level[0].forward->backward = x;else// 同有后繼節(jié)點(diǎn),說(shuō)明是尾節(jié)點(diǎn),賦值tailzsl->tail = x;zsl->length++;return x;}
ziplist添加沒(méi)啥好說(shuō)的,skiplist可以稍微提提,大體步驟為四步:
1. 找位置, 從最高層開(kāi)始, 判斷是否后繼節(jié)點(diǎn)小,如果小則直接在本層迭代,否則轉(zhuǎn)到下一層迭代; (每一層都要迭代至相應(yīng)的位置)
2. 計(jì)算得到一新的隨機(jī)level,用于決定當(dāng)前節(jié)點(diǎn)的層級(jí);
3. 依次對(duì)每一層與原跳表做關(guān)聯(lián);
4. 設(shè)置backward指針;(雙向鏈表)
相對(duì)說(shuō),skiplist 還是有點(diǎn)抽象,我們畫(huà)個(gè)圖來(lái)描述下上面的操作:
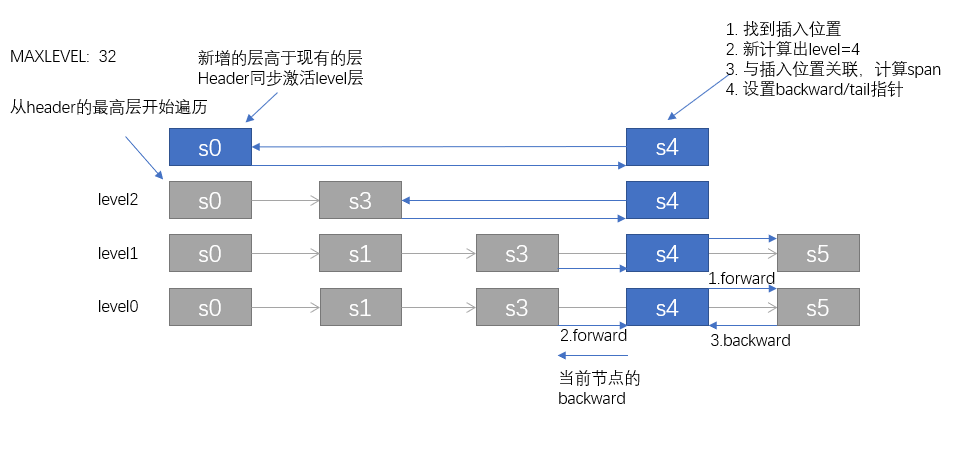
// 補(bǔ)充,我們看一下隨機(jī)level的計(jì)算算法// t_zset.c/* Returns a random level for the new skiplist node we are going to create.* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL* (both inclusive), with a powerlaw-alike distribution where higher* levels are less likely to be returned. */int zslRandomLevel(void) {int level = 1;// n次隨機(jī)值得到 level, ZSKIPLIST_P:0.25// 按隨機(jī)概率,應(yīng)該是有1/4的命中概率(如果不是呢??)while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))level += 1;return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;}
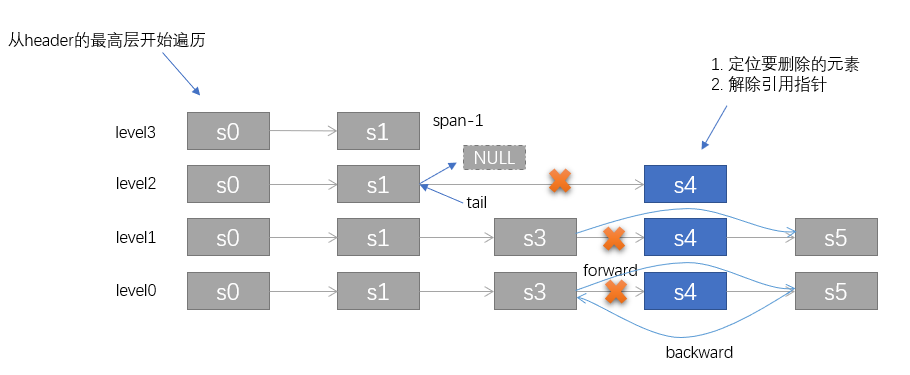
先看插入過(guò)程的目的,主要是為了先理解 skiplist 的構(gòu)造過(guò)程。而在zset的更新過(guò)程,是先刪除原節(jié)點(diǎn),再進(jìn)行插入的這么個(gè)過(guò)程。所以咱們還是有必要再來(lái)看看 skiplist 的刪除節(jié)點(diǎn)過(guò)程。
// t_zset.c, 刪除skiplist的指定節(jié)點(diǎn)/* Delete an element with matching score/element from the skiplist.* The function returns 1 if the node was found and deleted, otherwise* 0 is returned.** If 'node' is NULL the deleted node is freed by zslFreeNode(), otherwise* it is not freed (but just unlinked) and *node is set to the node pointer,* so that it is possible for the caller to reuse the node (including the* referenced SDS string at node->ele). */int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;int i;x = zsl->header;// 與添加時(shí)查找對(duì)應(yīng)位置一樣,先進(jìn)行遍歷,找到最每個(gè)層級(jí)最接近 node 的位置for (i = zsl->level-1; i >= 0; i--) {while (x->level[i].forward &&(x->level[i].forward->score < score ||(x->level[i].forward->score == score &&sdscmp(x->level[i].forward->ele,ele) < 0))){x = x->level[i].forward;}update[i] = x;}/* We may have multiple elements with the same score, what we need* is to find the element with both the right score and object. */// 進(jìn)行精確比對(duì),相同才進(jìn)行刪除x = x->level[0].forward;if (x && score == x->score && sdscmp(x->ele,ele) == 0) {// 執(zhí)行刪除動(dòng)作zslDeleteNode(zsl, x, update);if (!node)zslFreeNode(x);else*node = x;return 1;}return 0; /* not found */}// 刪除 x對(duì)應(yīng)的節(jié)點(diǎn)// update 是node的每一層級(jí)對(duì)應(yīng)的前驅(qū)節(jié)點(diǎn)/* Internal function used by zslDelete, zslDeleteByScore and zslDeleteByRank */void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {int i;for (i = 0; i < zsl->level; i++) {if (update[i]->level[i].forward == x) {update[i]->level[i].span += x->level[i].span - 1;update[i]->level[i].forward = x->level[i].forward;} else {// 不相等說(shuō)明該層不存在指向 x 的引用update[i]->level[i].span -= 1;}}// 更新第0層尾節(jié)點(diǎn)指針if (x->level[0].forward) {x->level[0].forward->backward = x->backward;} else {zsl->tail = x->backward;}// 降低 skiplist 的層級(jí),直到第一個(gè)非空的節(jié)點(diǎn)為止while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)zsl->level--;zsl->length--;}
skiplist 刪除過(guò)程的示意圖如下:
最后,我們?cè)賮?lái)看另一種情況,即zset發(fā)生編碼轉(zhuǎn)換時(shí),是如何做的。即如何從 ziplist 轉(zhuǎn)換到 skiplist 中呢?
// t_zset.c, 編碼類型轉(zhuǎn)換void zsetConvert(robj *zobj, int encoding) {zset *zs;zskiplistNode *node, *next;sds ele;double score;// 編碼相同,直接返回if (zobj->encoding == encoding) return;// ziplist -> skiplist 轉(zhuǎn)換if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {unsigned char *zl = zobj->ptr;unsigned char *eptr, *sptr;unsigned char *vstr;unsigned int vlen;long long vlong;if (encoding != OBJ_ENCODING_SKIPLIST)serverPanic("Unknown target encoding");zs = zmalloc(sizeof(*zs));zs->dict = dictCreate(&zsetDictType,NULL);zs->zsl = zslCreate();eptr = ziplistIndex(zl,0);serverAssertWithInfo(NULL,zobj,eptr != NULL);sptr = ziplistNext(zl,eptr);serverAssertWithInfo(NULL,zobj,sptr != NULL);while (eptr != NULL) {score = zzlGetScore(sptr);serverAssertWithInfo(NULL,zobj,ziplistGet(eptr,&vstr,&vlen,&vlong));if (vstr == NULL)ele = sdsfromlonglong(vlong);elseele = sdsnewlen((char*)vstr,vlen);// 依次插入 skiplist 和 dict 中即可node = zslInsert(zs->zsl,score,ele);serverAssert(dictAdd(zs->dict,ele,&node->score) == DICT_OK);// zzlNext 封裝了同時(shí)迭代 eptr 和 sptr 方法zzlNext(zl,&eptr,&sptr);}zfree(zobj->ptr);zobj->ptr = zs;zobj->encoding = OBJ_ENCODING_SKIPLIST;}// skiplist -> ziplist 逆向轉(zhuǎn)換else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {unsigned char *zl = ziplistNew();if (encoding != OBJ_ENCODING_ZIPLIST)serverPanic("Unknown target encoding");/* Approach similar to zslFree(), since we want to free the skiplist at* the same time as creating the ziplist. */zs = zobj->ptr;dictRelease(zs->dict);node = zs->zsl->header->level[0].forward;zfree(zs->zsl->header);zfree(zs->zsl);// 正向迭代轉(zhuǎn)換while (node) {zl = zzlInsertAt(zl,NULL,node->ele,node->score);next = node->level[0].forward;zslFreeNode(node);node = next;}zfree(zs);zobj->ptr = zl;zobj->encoding = OBJ_ENCODING_ZIPLIST;} else {serverPanic("Unknown sorted set encoding");}}// 基于ziplist, 同時(shí)迭代 ele-score/* Move to next entry based on the values in eptr and sptr. Both are set to* NULL when there is no next entry. */void zzlNext(unsigned char *zl, unsigned char **eptr, unsigned char **sptr) {unsigned char *_eptr, *_sptr;serverAssert(*eptr != NULL && *sptr != NULL);_eptr = ziplistNext(zl,*sptr);if (_eptr != NULL) {_sptr = ziplistNext(zl,_eptr);serverAssert(_sptr != NULL);} else {/* No next entry. */_sptr = NULL;}*eptr = _eptr;*sptr = _sptr;}
至此,整個(gè)添加過(guò)程結(jié)束。本身是不太復(fù)雜的,主要針對(duì) ziplist 和 skiplist 的分別處理(注意有逆向編碼)。但為了講清整體關(guān)系,稍顯雜亂。
三、zrange 范圍查詢
范圍查詢功能,redis提供了好幾個(gè),zrange/zrangebyscore/zrangebylex... 應(yīng)該說(shuō)查詢方式都不太一樣,不過(guò)我們也不必糾結(jié)這些,只管理會(huì)大概就行。就挑一個(gè)以 下標(biāo)進(jìn)行范圍查詢的實(shí)現(xiàn)講解下就行。
// 用法: ZRANGE key start stop [WITHSCORES]// t_zset.cvoid zrangeCommand(client *c) {zrangeGenericCommand(c,0);}void zrangeGenericCommand(client *c, int reverse) {robj *key = c->argv[1];robj *zobj;int withscores = 0;long start;long end;int llen;int rangelen;if ((getLongFromObjectOrReply(c, c->argv[2], &start, NULL) != C_OK) ||(getLongFromObjectOrReply(c, c->argv[3], &end, NULL) != C_OK)) return;if (c->argc == 5 && !strcasecmp(c->argv[4]->ptr,"withscores")) {withscores = 1;} else if (c->argc >= 5) {addReply(c,shared.syntaxerr);return;}if ((zobj = lookupKeyReadOrReply(c,key,shared.emptymultibulk)) == NULL|| checkType(c,zobj,OBJ_ZSET)) return;/* Sanitize indexes. */// 小于0,則代表反向查詢,但實(shí)際的輸出順序不是按此值運(yùn)算的(提供了 reverse 方法)llen = zsetLength(zobj);if (start < 0) start = llen+start;if (end < 0) end = llen+end;if (start < 0) start = 0;/* Invariant: start >= 0, so this test will be true when end < 0.* The range is empty when start > end or start >= length. */if (start > end || start >= llen) {addReply(c,shared.emptymultibulk);return;}if (end >= llen) end = llen-1;rangelen = (end-start)+1;/* Return the result in form of a multi-bulk reply */addReplyMultiBulkLen(c, withscores ? (rangelen*2) : rangelen);// 同樣,分 ZIPLIST 和 SKIPLIST 編碼分別實(shí)現(xiàn)if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {unsigned char *zl = zobj->ptr;unsigned char *eptr, *sptr;unsigned char *vstr;unsigned int vlen;long long vlong;// ziplist 以 ele-score 方式存儲(chǔ),所以步長(zhǎng)是 2if (reverse)eptr = ziplistIndex(zl,-2-(2*start));elseeptr = ziplistIndex(zl,2*start);serverAssertWithInfo(c,zobj,eptr != NULL);sptr = ziplistNext(zl,eptr);// 依次迭代輸出while (rangelen--) {serverAssertWithInfo(c,zobj,eptr != NULL && sptr != NULL);serverAssertWithInfo(c,zobj,ziplistGet(eptr,&vstr,&vlen,&vlong));if (vstr == NULL)addReplyBulkLongLong(c,vlong);elseaddReplyBulkCBuffer(c,vstr,vlen);if (withscores)addReplyDouble(c,zzlGetScore(sptr));// ziplist 提供正向迭代,返回迭代功能,其實(shí)就是 offset的加減問(wèn)題if (reverse)zzlPrev(zl,&eptr,&sptr);elsezzlNext(zl,&eptr,&sptr);}} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {zset *zs = zobj->ptr;zskiplist *zsl = zs->zsl;zskiplistNode *ln;sds ele;/* Check if starting point is trivial, before doing log(N) lookup. */// 反向使用 tail 迭代,否則使用header迭代if (reverse) {ln = zsl->tail;if (start > 0)// 獲取下標(biāo)元素應(yīng)該只是一個(gè)迭代循環(huán)問(wèn)題,不過(guò)還是稍微細(xì)看一下skiplist實(shí)現(xiàn)ln = zslGetElementByRank(zsl,llen-start);} else {ln = zsl->header->level[0].forward;if (start > 0)ln = zslGetElementByRank(zsl,start+1);}while(rangelen--) {serverAssertWithInfo(c,zobj,ln != NULL);ele = ln->ele;addReplyBulkCBuffer(c,ele,sdslen(ele));if (withscores)addReplyDouble(c,ln->score);// 直接正向或反向迭代即可ln = reverse ? ln->backward : ln->level[0].forward;}} else {serverPanic("Unknown sorted set encoding");}}// 根據(jù)排名查找元素/* Finds an element by its rank. The rank argument needs to be 1-based. */zskiplistNode* zslGetElementByRank(zskiplist *zsl, unsigned long rank) {zskiplistNode *x;unsigned long traversed = 0;int i;x = zsl->header;// 好像沒(méi)有相像中的簡(jiǎn)單哦// 請(qǐng)仔細(xì)品for (i = zsl->level-1; i >= 0; i--) {while (x->level[i].forward && (traversed + x->level[i].span) <= rank){// span 的作用??traversed += x->level[i].span;x = x->level[i].forward;}if (traversed == rank) {return x;}}return NULL;}
根據(jù)范圍查找元素,整體是比較簡(jiǎn)單,迭代輸出而已。只是 skiplist 的span維護(hù),得好好想想。
四、zrembyscore 根據(jù)分?jǐn)?shù)刪除元素
zrembyscore, 首先這是個(gè)刪除命令,其實(shí)它是根據(jù)分?jǐn)?shù)查詢,我們可以同時(shí)解析這兩種情況。
// t_zset.c,void zremrangebyscoreCommand(client *c) {// 幾個(gè)范圍刪除,都復(fù)用 zremrangeGenericCommand// ZRANGE_RANK/ZRANGE_SCORE/ZRANGE_LEXzremrangeGenericCommand(c,ZRANGE_SCORE);}void zremrangeGenericCommand(client *c, int rangetype) {robj *key = c->argv[1];robj *zobj;int keyremoved = 0;unsigned long deleted = 0;// score 存儲(chǔ)使用另外的數(shù)據(jù)結(jié)構(gòu)zrangespec range;zlexrangespec lexrange;long start, end, llen;/* Step 1: Parse the range. */// 解析參數(shù),除了 rank 方式的查詢,其他兩個(gè)都使用 另外的專門數(shù)據(jù)結(jié)構(gòu)存儲(chǔ)參數(shù)if (rangetype == ZRANGE_RANK) {if ((getLongFromObjectOrReply(c,c->argv[2],&start,NULL) != C_OK) ||(getLongFromObjectOrReply(c,c->argv[3],&end,NULL) != C_OK))return;} else if (rangetype == ZRANGE_SCORE) {if (zslParseRange(c->argv[2],c->argv[3],&range) != C_OK) {addReplyError(c,"min or max is not a float");return;}} else if (rangetype == ZRANGE_LEX) {if (zslParseLexRange(c->argv[2],c->argv[3],&lexrange) != C_OK) {addReplyError(c,"min or max not valid string range item");return;}}/* Step 2: Lookup & range sanity checks if needed. */if ((zobj = lookupKeyWriteOrReply(c,key,shared.czero)) == NULL ||checkType(c,zobj,OBJ_ZSET)) goto cleanup;if (rangetype == ZRANGE_RANK) {/* Sanitize indexes. */llen = zsetLength(zobj);if (start < 0) start = llen+start;if (end < 0) end = llen+end;if (start < 0) start = 0;/* Invariant: start >= 0, so this test will be true when end < 0.* The range is empty when start > end or start >= length. */if (start > end || start >= llen) {addReply(c,shared.czero);goto cleanup;}if (end >= llen) end = llen-1;}/* Step 3: Perform the range deletion operation. */if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {// 針對(duì)不同的刪除類型,使用不同的刪除方法// 所以,這段代碼的復(fù)用體現(xiàn)在哪里呢???switch(rangetype) {case ZRANGE_RANK:zobj->ptr = zzlDeleteRangeByRank(zobj->ptr,start+1,end+1,&deleted);break;case ZRANGE_SCORE:// 3.1. 我們只看 score 的刪除 --ziplistzobj->ptr = zzlDeleteRangeByScore(zobj->ptr,&range,&deleted);break;case ZRANGE_LEX:zobj->ptr = zzlDeleteRangeByLex(zobj->ptr,&lexrange,&deleted);break;}if (zzlLength(zobj->ptr) == 0) {dbDelete(c->db,key);keyremoved = 1;}} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {zset *zs = zobj->ptr;switch(rangetype) {case ZRANGE_RANK:deleted = zslDeleteRangeByRank(zs->zsl,start+1,end+1,zs->dict);break;case ZRANGE_SCORE:// 3.2. skiplist 的刪除rangeByScore 方法deleted = zslDeleteRangeByScore(zs->zsl,&range,zs->dict);break;case ZRANGE_LEX:deleted = zslDeleteRangeByLex(zs->zsl,&lexrange,zs->dict);break;}if (htNeedsResize(zs->dict)) dictResize(zs->dict);if (dictSize(zs->dict) == 0) {dbDelete(c->db,key);keyremoved = 1;}} else {serverPanic("Unknown sorted set encoding");}/* Step 4: Notifications and reply. */if (deleted) {char *event[3] = {"zremrangebyrank","zremrangebyscore","zremrangebylex"};signalModifiedKey(c->db,key);notifyKeyspaceEvent(NOTIFY_ZSET,event[rangetype],key,c->db->id);if (keyremoved)notifyKeyspaceEvent(NOTIFY_GENERIC,"del",key,c->db->id);}server.dirty += deleted;addReplyLongLong(c,deleted);cleanup:if (rangetype == ZRANGE_LEX) zslFreeLexRange(&lexrange);}// server.h, 范圍查詢參數(shù)存儲(chǔ)/* Struct to hold a inclusive/exclusive range spec by score comparison. */typedef struct {double min, max;int minex, maxex; /* are min or max exclusive? */} zrangespec;// 3.1. ziplist 的刪除range方法// t_zset.cunsigned char *zzlDeleteRangeByScore(unsigned char *zl, zrangespec *range, unsigned long *deleted) {unsigned char *eptr, *sptr;double score;unsigned long num = 0;if (deleted != NULL) *deleted = 0;// 找到首個(gè)在范圍內(nèi)的指針,進(jìn)行迭代eptr = zzlFirstInRange(zl,range);if (eptr == NULL) return zl;/* When the tail of the ziplist is deleted, eptr will point to the sentinel* byte and ziplistNext will return NULL. */while ((sptr = ziplistNext(zl,eptr)) != NULL) {score = zzlGetScore(sptr);// 肯定是比 min 大的,所以只需確認(rèn)比 max 小即可if (zslValueLteMax(score,range)) {/* Delete both the element and the score. */zl = ziplistDelete(zl,&eptr);zl = ziplistDelete(zl,&eptr);num++;} else {/* No longer in range. */break;}}if (deleted != NULL) *deleted = num;return zl;}/* Find pointer to the first element contained in the specified range.* Returns NULL when no element is contained in the range. */unsigned char *zzlFirstInRange(unsigned char *zl, zrangespec *range) {unsigned char *eptr = ziplistIndex(zl,0), *sptr;double score;/* If everything is out of range, return early. */// 比較第1個(gè)元素和最后 一個(gè)元素,即可確認(rèn)是否在范圍內(nèi)if (!zzlIsInRange(zl,range)) return NULL;while (eptr != NULL) {sptr = ziplistNext(zl,eptr);serverAssert(sptr != NULL);score = zzlGetScore(sptr);// score >= minif (zslValueGteMin(score,range)) {/* Check if score <= max. */if (zslValueLteMax(score,range))return eptr;return NULL;}/* Move to next element. */eptr = ziplistNext(zl,sptr);}return NULL;}// 檢查zl是否在range范圍內(nèi)// 檢查第1個(gè)分?jǐn)?shù)和最后一個(gè)數(shù)即可/* Returns if there is a part of the zset is in range. Should only be used* internally by zzlFirstInRange and zzlLastInRange. */int zzlIsInRange(unsigned char *zl, zrangespec *range) {unsigned char *p;double score;/* Test for ranges that will always be empty. */if (range->min > range->max ||(range->min == range->max && (range->minex || range->maxex)))return 0;p = ziplistIndex(zl,-1); /* Last score. */if (p == NULL) return 0; /* Empty sorted set */score = zzlGetScore(p);// scoreMax >= minif (!zslValueGteMin(score,range))return 0;p = ziplistIndex(zl,1); /* First score. */serverAssert(p != NULL);score = zzlGetScore(p);// scoreMin <= maxif (!zslValueLteMax(score,range))return 0;return 1;}// 3.2. 刪除 skiplist 中的range元素/* Delete all the elements with score between min and max from the skiplist.* Min and max are inclusive, so a score >= min || score <= max is deleted.* Note that this function takes the reference to the hash table view of the* sorted set, in order to remove the elements from the hash table too. */unsigned long zslDeleteRangeByScore(zskiplist *zsl, zrangespec *range, dict *dict) {zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;unsigned long removed = 0;int i;x = zsl->header;// 找出每層小于 range->min 的元素for (i = zsl->level-1; i >= 0; i--) {while (x->level[i].forward && (range->minex ?x->level[i].forward->score <= range->min :x->level[i].forward->score < range->min))x = x->level[i].forward;update[i] = x;}/* Current node is the last with score < or <= min. */x = x->level[0].forward;// 從第0層開(kāi)始,依次刪除引用,刪除元素// 同有找到符合條件的元素時(shí),一次循環(huán)也不會(huì)成立/* Delete nodes while in range. */while (x &&(range->maxex ? x->score < range->max : x->score <= range->max)){// 保留下一次迭代zskiplistNode *next = x->level[0].forward;zslDeleteNode(zsl,x,update);// 同步刪除 dict 數(shù)據(jù)dictDelete(dict,x->ele);zslFreeNode(x); /* Here is where x->ele is actually released. */removed++;x = next;}return removed;}
刪除的邏輯比較清晰,ziplist和skiplist分開(kāi)處理。大體思路相同是:找到第一個(gè)符合條件的元素,然后迭代,直到第一個(gè)不符合條件的元素為止。
set雖然從定義上與zset有很多相通之處,然而在實(shí)現(xiàn)上卻是截然不同的。由于很多東西和之前介紹的知識(shí)有重合的地方,也沒(méi)啥好特別說(shuō)的。zset 的解析差不多就到這里了。
你覺(jué)得zset還有什么有意思的實(shí)現(xiàn)呢?歡迎討論。

騰訊、阿里、滴滴后臺(tái)面試題匯總總結(jié) — (含答案)
面試:史上最全多線程面試題 !
最新阿里內(nèi)推Java后端面試題
JVM難學(xué)?那是因?yàn)槟銢](méi)認(rèn)真看完這篇文章

關(guān)注作者微信公眾號(hào) —《JAVA爛豬皮》
了解更多java后端架構(gòu)知識(shí)以及最新面試寶典

看完本文記得給作者點(diǎn)贊+在看哦~~~大家的支持,是作者源源不斷出文的動(dòng)力
作者:等你歸去來(lái)
出處:https://www.cnblogs.com/yougewe/p/12253982.html