
Batch Size 對訓(xùn)練的影響
作者 陳志遠@知乎??編輯 極市平臺 侵刪
來源 https://zhuanlan.zhihu.com/p/83626029?
面試版回答
在不考慮Batch Normalization的情況下(這種情況我們之后會在bn的文章里專門探討),先給個自己當(dāng)時回答的答案吧(相對來說學(xué)究一點):
(1) 不考慮bn的情況下,batch size的大小決定了深度學(xué)習(xí)訓(xùn)練過程中的完成每個epoch所需的時間和每次迭代(iteration)之間梯度的平滑程度。(感謝評論區(qū)的韓飛同學(xué)提醒,batchsize只能說影響完成每個epoch所需要的時間,決定也算不上吧。根本原因還是CPU,GPU算力吧。瓶頸如果在CPU,例如隨機數(shù)據(jù)增強,batch size越大有時候計算的越慢。)
對于一個大小為N的訓(xùn)練集,如果每個epoch中mini-batch的采樣方法采用最常規(guī)的N個樣本每個都采樣一次,設(shè)mini-batch大小為b,那么每個epoch所需的迭代次數(shù)(正向+反向)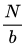 ,?因此完成每個epoch所需的時間大致也隨著迭代次數(shù)的增加而增加。
,?因此完成每個epoch所需的時間大致也隨著迭代次數(shù)的增加而增加。
由于目前主流深度學(xué)習(xí)框架處理mini-batch的反向傳播時,默認都是先將每個mini-batch中每個instance得到的loss平均化之后再反求梯度,也就是說每次反向傳播的梯度是對mini-batch中每個instance的梯度平均之后的結(jié)果,所以b的大小決定了相鄰迭代之間的梯度平滑程度,b太小,相鄰mini-batch間的差異相對過大,那么相鄰兩次迭代的梯度震蕩情況會比較嚴重,不利于收斂;b越大,相鄰mini-batch間的差異相對越小,雖然梯度震蕩情況會比較小,一定程度上利于模型收斂,但如果b極端大,相鄰mini-batch間的差異過小,相鄰兩個mini-batch的梯度沒有區(qū)別了,整個訓(xùn)練過程就是沿著一個方向蹭蹭蹭往下走,很容易陷入到局部最小值出不來。
總結(jié)下來:batch size過小,花費時間多,同時梯度震蕩嚴重,不利于收斂;batch size過大,不同batch的梯度方向沒有任何變化,容易陷入局部極小值。
(2)(存疑,只是突發(fā)奇想)如果硬件資源允許,想要追求訓(xùn)練速度使用超大batch,可以采用一次正向+多次反向的方法,避免模型陷入局部最小值。即使用超大epoch做正向傳播,在反向傳播的時候,分批次做多次反向轉(zhuǎn)播,比如將一個batch size為64的batch,一次正向傳播得到結(jié)果,instance級別求loss(先不平均),得到64個loss結(jié)果;反向傳播的過程中,分四次進行反向傳播,每次取16個instance的loss求平均,然后進行反向傳播,這樣可以做到在節(jié)約一定的訓(xùn)練時間,利用起硬件資源的優(yōu)勢的情況下,避免模型訓(xùn)練陷入局部最小值。
通俗版回答
那么我們可以把第一個問題簡化為一個小時候經(jīng)常玩的游戲:
深度學(xué)習(xí)訓(xùn)練過程:貼鼻子
訓(xùn)練樣本:負責(zé)指揮的小朋友們(觀察角度各不一樣)
模型:負責(zé)貼的小朋友
模型衡量指標:最終貼的位置和真實位置之間的距離大小

由于每個小朋友站的位置各不一樣,所以他們對鼻子位置的觀察也各不一樣。(訓(xùn)練樣本的差異性),這時候假設(shè)小明是負責(zé)貼鼻子的小朋友,小朋友A、B、C、D、E是負責(zé)指揮的同學(xué)(A, B站在圖的右邊,C,D, E站在左邊),這時候小明如果采用:
每次隨機詢問一個同學(xué),那么很容易出現(xiàn),先詢問到了A,A說向左2cm,再問C,C說向右5cm,然后B,B說向左4cm,D說向右3cm,這樣每次指揮的差異都比較大,結(jié)果調(diào)過來調(diào)過去,沒什么進步。
每次隨機詢問兩個同學(xué),每次取詢問的意見的平均,比如先問到了(A, C),A說向左2cm,C說向右5cm,那就取個均值,向右1.5cm。然后再問(B, D),這樣的話減少了極端情況(前后兩次迭代差異巨大)這種情況的發(fā)生,能更好更快的完成游戲。
每次全問一遍,然后取均值,這樣每次移動的方向都是所有人決定的均值,這樣的話,最后就是哪邊的小朋友多最終結(jié)果就被很快的拉向哪邊了。(梯度方向不變,限于極小值)
科學(xué)版回答
就用MINST做一下實驗吧(代碼主要轉(zhuǎn)自cnblogs.com/jiangnanyan):
cnblogs.com/jiangnanyan
鏈接:https://www.cnblogs.com/jiangnanyanyuchen/p/9782223.html
實驗環(huán)境:
1080ti * 1
Pytorch 0.4.1
超參數(shù):SGD(lr = 0.02, momentum=0.5)?偷懶沒有根據(jù)batch size細調(diào)
我們先創(chuàng)建一個簡單的模型:
from torch.nn import *
import torch.nn.functional as F
class SimpleModel(Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.conv1 = Conv2d(in_channels=1, out_channels=10, kernel_size=5)
self.conv2 = Conv2d(10, 20, 5)
self.conv3 = Conv2d(20, 40, 3)
self.mp = MaxPool2d(2)
self.fc = Linear(40, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = F.relu(self.mp(self.conv2(x)))
x = F.relu(self.mp(self.conv3(x)))
x = x.view(in_size, -1)
x = self.fc(x)
print(x.size())
return F.log_softmax(x, dim=1)
然后把MINST加載出來訓(xùn)練一下:
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import os
from torchvision import datasets, transforms
from simple_model import SimpleModel
os.environ['CUDA_VISIBLE_DEVICES'] = "0"
use_cuda = torch.cuda.is_available()
batch_size = 6
lr = 1e-2
# MNIST Dataset
train_dataset = datasets.MNIST(root='./data/',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.MNIST(root='./data/',
train=False,
transform=transforms.ToTensor())
# Data Loader (Input Pipeline)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
model = SimpleModel()
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.5)
if use_cuda:
model = nn.DataParallel(model).cuda()
iter_losses = []
def train(epoch):
model.train()
total_loss = 0
compution_time = 0
e_sp = time.time()
for batch_idx, (data, target) in enumerate(train_loader):
if use_cuda:
data = data.cuda()
target = target.cuda()
b_sp = time.time()
output = model(data)
loss = F.nll_loss(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
compution_time += time.time() - b_sp
# optimizer.step()
epoch_time = time.time() - e_sp
print('Train Epoch: {} \t Loss: {:.6f}\t epoch time: {:.6f} s\t epoch compution time: {:.6f} s'.format(
epoch, total_loss / len(train_loader), epoch_time, compution_time))
return total_loss / len(train_loader)
def test():
model.eval()
with torch.no_grad():
test_loss = 0
correct = 0
for data, target in test_loader:
if use_cuda:
data = data.cuda()
target = target.cuda()
output = model(data)
# sum up batch loss
test_loss += F.nll_loss(output, target).item()
# get the index of the max log-probability
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= len(test_loader)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
return test_loss, 100. * correct.item() / len(test_loader.dataset)
if __name__ == "__main__":
for epoch in range(1, 10000):
train_l = train(epoch)
val_l, val_a = test()
我們從以下指標來看一下不同batch size之間的區(qū)別:
迭代速度
感覺之前做的實驗有點不太科學(xué),重新捋了一下思路,把時間計算的代碼也放到了前面的代碼之中,有興趣的同學(xué)也可以自己做一下看看。
(表中 Epoch Time是在此batch size下完成一個epoch所需的所有時間,包括加載數(shù)據(jù)和計算的時間,Epoch Computation Time拋去了加載數(shù)據(jù)所需的時間。)
(時間確實是有偏量,上面的數(shù)據(jù)可以大體做個參考,要做科學(xué)考究的話,還是要多做幾次實驗求均值減少偏差。)
其實純粹cuda計算的角度來看,完成每個iter的時間大batch和小batch區(qū)別并不大,這可能是因為本次實驗中,反向傳播的時間消耗要比正向傳播大得多,所以batch size的大小對每個iter所需的時間影響不明顯,未來將在大一點的數(shù)據(jù)庫和更復(fù)雜的模型上做一下實驗。(因為反向的過程取決于模型的復(fù)雜度,與batchsize的大小關(guān)系不大,而正向則同時取決于模型的復(fù)雜度和batch size的大小。而本次實驗中反向的過程要比正向的過程時間消耗大得多,所以batch size的大小對完成每個iter所需的耗時影響不大。)
完成每個epoch運算的所需的全部時間主要卡在:1. load數(shù)據(jù)的時間,2. 每個epoch的iter數(shù)量。因此對于每個epoch,不管是純計算時間還是全部時間,大體上還是大batch能夠更節(jié)約時間一點,但隨著batch增大,iter次數(shù)減小,完成每個epoch的時間更取決于加載數(shù)據(jù)所需的時間,此時也不見得大batch能帶來多少的速度增益了。
梯度平滑程度
我們再來看一下不同batch size下的梯度的平滑程度,我們選取了每個batch size下前1000個iter的loss,來看一下loss的震蕩情況,結(jié)果如下圖所示:
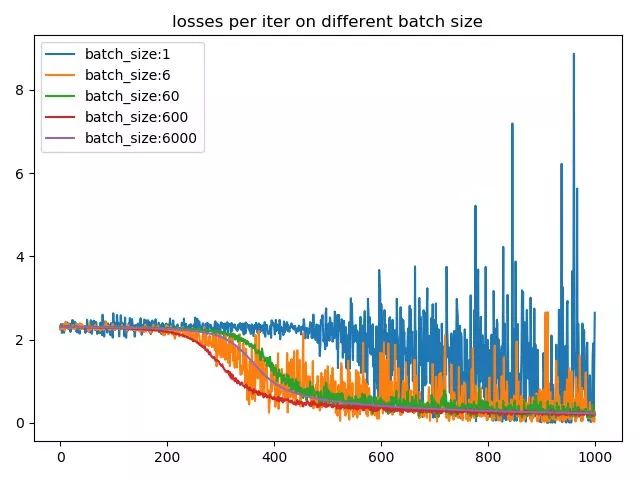
如果感覺這張圖不太好看,可以看一下這張圖:
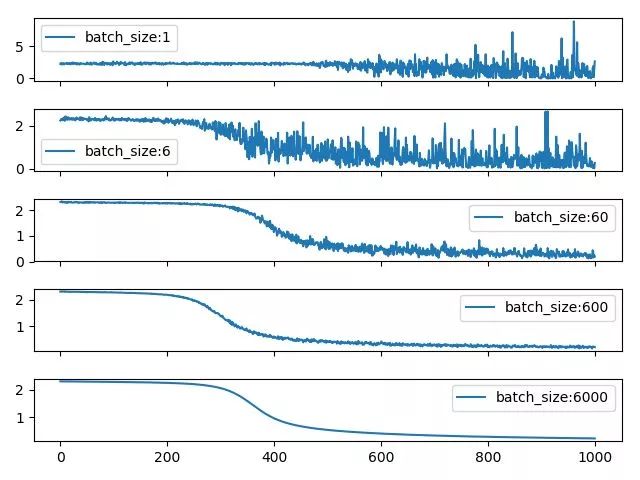
由于現(xiàn)在絕大多數(shù)的框架在進行mini-batch的反向傳播的時候,默認都是將batch中每個instance的loss平均化之后在進行反向傳播,所以相對大一點的batch size能夠防止loss震蕩的情況發(fā)生。從這兩張圖中可以看出batch size越小,相鄰iter之間的loss震蕩就越厲害,相應(yīng)的,反傳回去的梯度的變化也就越大,也就越不利于收斂。同時很有意思的一個現(xiàn)象,batch size為1的時候,loss到后期會發(fā)生爆炸,這主要是lr=0.02設(shè)置太大,所以某個異常值的出現(xiàn)會嚴重擾動到訓(xùn)練過程。這也是為什么對于較小的batchsize,要設(shè)置小lr的原因之一,避免異常值對結(jié)果造成的擾巨大擾動。而對于較大的batchsize,要設(shè)置大一點的lr的原因則是大batch每次迭代的梯度方向相對固定,大lr可以加速其收斂過程。
收斂速度
在衡量不同batch size的優(yōu)劣這一點上,我選用衡量不同batch size在同樣參數(shù)下的收斂速度快慢的方法。
下表中可以看出,在minst數(shù)據(jù)集上,從整體時間消耗上來看(考慮了加載數(shù)據(jù)所需的時間),同樣的參數(shù)策略下 (lr = 0.02, momentum=0.5 ),要模型收斂到accuracy在98左右,batchsize在 6 - 60 這個量級能夠花費最少的時間,而batchsize為1的時候,收斂不到98;batchsize過大的時候,因為模型收斂快慢取決于梯度方向和更新次數(shù),所以大batch盡管梯度方向更為穩(wěn)定,但要達到98的accuracy所需的更新次數(shù)并沒有量級上的減少,所以也就需要花費更多的時間,當(dāng)然這種情況下可以配合一些調(diào)參策略比如warmup LR,衰減LR等等之類的在一定程度上進行解決(這個先暫且按下不表),但也不會有本質(zhì)上的改善。
不過單純從計算時間上來看,大batch還是可以很明顯地節(jié)約所需的計算時間的,原因前面講過了,主要因為本次實驗中純計算時間中,反向占的時間比重遠大于正向。
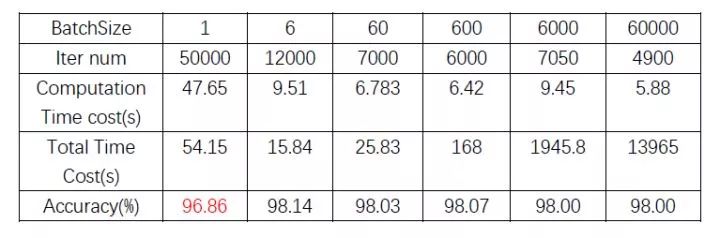
(我一直覺得直接比較不同batch size下的絕對收斂精度來衡量batch size的好壞是沒有太大意義的,因為不同的batch size要配合不同的調(diào)參策略用才能達到其最佳效果,而要想在每個batch size下都找到合適的調(diào)參策略那可太難了,所以用這種方法來決定batch size未免有點武斷。)
一次正向,多次反向
這部分在pytorch上進行了實驗,但發(fā)現(xiàn)pytorch在backward中加入retain_graph進行多次反向傳播的時候,時間消耗特別大,所以盡管采用一次正向,多次反向的方法,減少了超大batch size收斂到98的accuracy所需的iteration,但由于每個iteration時間消耗增加,所以并沒有帶來時間節(jié)省,我后續(xù)還要探究一下原因,再重新做一下實驗,然后再貼結(jié)果,給結(jié)論。
做了幾次實驗,基本失敗,一個大batch分成10份反向傳播,基本等同于lr放大10倍。大batch還是要配合著更復(fù)雜的lr策略來做,比如warmup,循環(huán)lr,lr衰減等等。
實驗的漏洞
為了保證獨立變量,我在實驗中不同batch設(shè)置了同樣的lr,然后比較收斂速度,這樣是不公平的,畢竟大batch還是要配合更大的初始lr,所以后續(xù)還要做一下實驗,固定每個batch size, 看lr的變化對不同batch size收斂素的的影響。
猜您喜歡:
附下載 |《TensorFlow 2.0 深度學(xué)習(xí)算法實戰(zhàn)》
附下載 |《計算機視覺中的數(shù)學(xué)方法》分享
《基于深度神經(jīng)網(wǎng)絡(luò)的少樣本學(xué)習(xí)綜述》